26 mars 2025·8 min de lecture
Journalisation d'audit pour outils internes : modèles clairs d'historique des modifications
Journalisation d'audit pratique pour outils internes : suivez qui a fait quoi et quand pour chaque changement CRUD, stockez des diffs en sécurité et affichez un fil d'activité admin.
Pourquoi les outils internes ont besoin de journaux d'audit (et où ils échouent souvent)
La plupart des équipes ajoutent des journaux d'audit après qu'un problème survient. Un client conteste une modification, un chiffre financier bouge, ou un auditeur demande « Qui a approuvé ceci ? ». Si vous ne commencez qu'à ce moment-là, vous essayez de reconstituer le passé à partir d'indices partiels : horodatages en base, messages Slack et conjectures.
Pour la plupart des applications internes, « suffisant pour la conformité » ne signifie pas un système médico-légal parfait. Cela signifie que vous pouvez répondre à un petit ensemble de questions rapidement et de façon cohérente : qui a fait la modification, quel enregistrement a été affecté, ce qui a changé, quand cela s'est produit, et d'où cela vient (UI, import, API, automatisation). Cette clarté est ce qui fait qu'un journal d'audit est réellement digne de confiance.
Ce qui manque le plus aux journaux d'audit n'est généralement pas la base de données, mais la couverture. L'historique a l'air correct pour des modifications simples, puis des trous apparaissent dès que le travail s'accélère. Les coupables fréquents sont les éditions en masse, les imports, les jobs planifiés, les actions admin qui contournent les écrans normaux (comme la réinitialisation de mot de passe ou le changement de rôle), et les suppressions (en particulier les suppressions définitives).
Une autre erreur fréquente est de confondre logs de debug et journaux d'audit. Les logs de debug sont faits pour les développeurs : bruyants, techniques et souvent inconsistants. Les journaux d'audit servent la responsabilité : champs cohérents, libellés clairs et format stable que vous pouvez montrer à des non-ingénieurs.
Un exemple concret : un responsable support change le plan d'un client, puis une automatisation met à jour les informations de facturation plus tard. Si vous ne consignez que « updated customer », vous ne pouvez pas savoir si une personne l'a fait, si un workflow l'a fait ou si un import a écrasé la valeur.
Les champs d'audit qui répondent à qui, quoi, quand
Une bonne journalisation commence par un but : une personne doit pouvoir lire une entrée et comprendre ce qui s'est passé sans deviner.
Qui l'a fait
Stockez un acteur clair pour chaque changement. La plupart des équipes s'arrêtent à « user id », mais les outils internes modifient souvent les données par plus d'une porte.
Incluez un type d'acteur et un identifiant d'acteur, afin de distinguer un membre du personnel, un compte de service ou une intégration externe. Si vous avez des équipes ou des locataires, stockez aussi l'id de l'organisation ou de l'espace de travail pour que les événements ne se mélangent jamais.
Ce qui s'est passé et quel enregistrement
Capturez l'action (create, update, delete, restore) plus la cible. « Cible » doit être à la fois lisible et précise : nom de table ou d'entité, id de l'enregistrement, et idéalement un petit libellé (par exemple un numéro de commande) pour une lecture rapide.
Un ensemble minimal pratique de champs :
- actor_type, actor_id (et actor_display_name si vous l'avez)
- action et target_type, target_id
- happened_at_utc (horodatage stocké en UTC)
- source (screen, endpoint, job, import) et ip_address (seulement si nécessaire)
- reason (commentaire optionnel pour les changements sensibles)
Quand cela s'est produit
Stockez l'horodatage en UTC. Toujours. Puis affichez-le dans le fuseau horaire du lecteur dans l'UI admin. Cela évite les disputes du type « deux personnes ont vu des heures différentes » lors d'une revue.
Si vous gérez des actions à haut risque comme des changements de rôle, des remboursements ou des exports de données, ajoutez un champ « reason ». Même une courte note comme « Approuvé par le manager dans le ticket 1842 » peut transformer une piste d'audit de bruit en preuve.
Choisir un modèle de données : event log vs historique versionné
Le premier choix de conception est l'endroit où réside la « vérité » de l'historique des changements. La plupart des équipes arrivent à l'un des deux modèles : un journal append-only d'événements, ou des tables d'historique versionnées par entité.
Option 1 : Event log (table d'actions append-only)
Un event log est une seule table qui enregistre chaque action comme une nouvelle ligne. Chaque ligne stocke qui l'a faite, quand, quelle entité a été touchée et une payload (souvent JSON) décrivant le changement.
Ce modèle est simple à ajouter et flexible quand votre modèle de données évolue. Il se mappe aussi naturellement à un fil d'activité admin parce que le fil est essentiellement « derniers événements en premier ».
Option 2 : Historique versionné (versions par entité)
L'approche historique versionnée crée des tables d'historique par entité, comme Order_history ou User_versions, où chaque mise à jour crée un nouveau snapshot complet (ou un ensemble structuré de champs changés) avec un numéro de version.
Cela facilite les rapports point-in-time (« à quoi ressemblait cet enregistrement mardi dernier ? »). Cela peut aussi paraître plus clair pour les auditeurs, car la chronologie d'un enregistrement est autocontenue.
Une façon pratique de choisir :
- Choisissez un event log si vous voulez un seul endroit pour chercher, des feeds d'activité faciles et peu de friction quand de nouvelles entités apparaissent.
- Choisissez un historique versionné si vous avez besoin de timelines fréquentes par enregistrement, de vues point-in-time ou de diffs simples par entité.
- Si le stockage est un souci, les event logs avec diffs par champ sont généralement plus légers que des snapshots complets.
- Si le reporting est l'objectif principal, les tables de versions peuvent être plus simples à requêter que de parser des payloads d'événements.
Quel que soit votre choix, conservez les entrées d'audit immuables : pas de mises à jour, pas de suppressions. Si quelque chose est incorrect, ajoutez une nouvelle entrée qui explique la correction.
Pensez aussi à ajouter un correlation_id (ou operation id). Une action utilisateur déclenche souvent plusieurs changements (par exemple, « Désactiver l'utilisateur » met à jour l'utilisateur, révoque des sessions et annule des tâches en attente). Un correlation id partagé vous permet de grouper ces lignes en une opération lisible.
Capturer les actions CRUD de façon fiable (y compris suppressions et éditions en masse)
La fiabilité commence par une règle : chaque écriture passe par un seul chemin qui écrit aussi un événement d'audit. Si certaines mises à jour se font dans un job d'arrière-plan, un import ou un écran d'édition rapide qui contourne votre flux de sauvegarde normal, vos logs auront des trous.
Pour les créations, enregistrez l'acteur et la source (UI, API, import). Les imports sont souvent là où les équipes perdent le « qui », donc stockez une valeur explicite « performed by » même si les données viennent d'un fichier ou d'une intégration. Il est aussi utile de stocker les valeurs initiales (soit un snapshot complet, soit un petit ensemble de champs clés) pour pouvoir expliquer pourquoi un enregistrement existe.
Les mises à jour sont plus délicates. Vous pouvez consigner seulement les champs modifiés (petit, lisible et rapide), ou stocker un snapshot complet après chaque sauvegarde (simple à interroger plus tard, mais volumineux). Un compromis pratique est de stocker des diffs pour les éditions normales et de garder des snapshots seulement pour les objets sensibles (permissions, coordonnées bancaires, règles de tarification).
Les suppressions ne doivent pas effacer les preuves. Préférez une suppression logique (un flag is_deleted plus une entrée d'audit). Si vous devez impérativement faire une suppression définitive, écrivez d'abord l'événement d'audit et incluez un snapshot de l'enregistrement pour pouvoir prouver ce qui a été retiré.
Considérez la restauration comme une action à part. « Restore » n'est pas la même chose que « Update », et les séparer facilite grandement les revues et contrôles de conformité.
Pour les éditions en masse, évitez une entrée vague du type « updated 500 records ». Vous devez laisser suffisamment de détails pour répondre à « quels enregistrements ont changé ? » plus tard. Un pattern pratique est un événement parent plus des événements enfants par enregistrement :
- Événement parent : acteur, outil/écran, filtres utilisés et taille du lot
- Événement enfant par enregistrement : id de l'enregistrement, before/after (ou champs modifiés) et résultat (succès/échec)
- Optionnel : un champ reason partagé (mise à jour de politique, nettoyage, migration)
Exemple : un responsable support clôt en masse 120 tickets. L'entrée parent capture le filtre « status=open, older than 30 days » et chaque ticket obtient une entrée enfant montrant status open -> closed.
Stocker ce qui a changé sans créer un cauchemar de confidentialité ou de stockage
Construire des outils internes prêts pour l'audit
Créez un outil interne avec des journaux d'audit intégrés dans chaque flux.
Les journaux d'audit deviennent vite du junk quand ils stockent soit trop (chaque enregistrement complet, pour toujours) soit trop peu (juste « edited user »). L'objectif est un enregistrement défendable pour la conformité et lisible par un admin.
Un défaut pratique est de stocker un diff par champ pour la plupart des mises à jour. Sauvegardez seulement les champs qui ont changé, avec les valeurs "before" et "after". Cela réduit le stockage et rend le fil d'activité facile à parcourir : « Status: Pending -> Approved » est plus clair qu'un gros blob.
Gardez des snapshots complets pour les moments importants : créations, suppressions et transitions majeures de workflow. Un snapshot est plus lourd, mais il vous protège quand quelqu'un demande « À quoi ressemblait le profil client avant sa suppression ? ».
Les données sensibles nécessitent des règles de masquage, sinon votre table d'audit devient une seconde base pleine de secrets. Règles courantes :
- Ne jamais stocker de mots de passe, tokens API ou clés privées (loggez juste « changed »)
- Masquez les données personnelles comme email/phone (conservez des valeurs partielles ou hachées)
- Pour les notes ou champs en texte libre, stockez un court aperçu et un indicateur « changed »
- Enregistrez des références (user_id, order_id) au lieu de copier des objets liés entiers
Les changements de schéma peuvent aussi casser l'historique d'audit. Si un champ est renommé ou supprimé plus tard, stockez un fallback sûr comme « unknown field » plus la clé de champ originale. Pour les champs supprimés, gardez la dernière valeur connue mais marquez-la « field removed from schema » afin que le fil reste honnête.
Enfin, rendez les entrées lisibles par des humains. Stockez des libellés d'affichage (« Assigned to ») à côté des clés brutes (« assignee_id ») et formatez les valeurs (dates, monnaies, noms d'état).
Pattern pas à pas : implémenter la journalisation dans vos flux applicatifs
Une piste d'audit fiable n'est pas une question de logger davantage. C'est utiliser un seul pattern répétable partout pour éviter des trous comme « l'import en masse n'était pas journalisé » ou « les modifications mobiles semblent anonymes ».
1) Modélisez les données d'audit une fois
Commencez dans votre modèle de données et créez un petit ensemble de tables capables de décrire n'importe quel changement.
Restez simple : une table pour l'événement, une pour les champs modifiés et un petit contexte d'acteur.
audit_event : id, entity_type, entity_id, action (create/update/delete/restore), created_at, request_idaudit_event_item : id, audit_event_id, field_name, old_value, new_valueactor_context (ou champs sur audit_event) : actor_type (user/system), actor_id, actor_email, ip, user_agent
2) Ajoutez un sous-procédé partagé « Write + Audit »
Créez un sous-processus réutilisable qui :
- Accepte le nom d'entité, l'id d'entité, l'action et les valeurs before/after.
- Écrit le changement métier dans la table principale.
- Crée un enregistrement
audit_event.
- Calcule les champs modifiés et insère les lignes
audit_event_item.
La règle est stricte : chaque chemin d'écriture doit appeler ce même sous-processus. Cela inclut les boutons UI, les endpoints API, les automatisations planifiées et les intégrations.
3) Générez acteur et horodatage côté serveur
Ne faites pas confiance au navigateur pour « qui » et « quand ». Lisez l'acteur depuis votre session d'auth, et générez les horodatages côté serveur. Si une automatisation s'exécute, définissez actor_type sur system et stockez le nom du job comme label d'acteur.
4) Testez avec un scénario concret
Choisissez un enregistrement concret (par exemple un ticket client) : créez-le, modifiez deux champs (status et assignee), supprimez-le, puis restaurez-le. Votre fil d'audit doit montrer cinq événements, avec deux items de mise à jour sous l'événement d'édition, et l'acteur et l'horodatage remplis de la même manière à chaque fois.
Construire un fil d'activité admin que l'on utilise vraiment
Couvrir chaque chemin d'écriture
Routage de l'interface, des API, des imports et des jobs via un flux unique Write + Audit.
Un journal d'audit n'est utile que si quelqu'un peut le lire rapidement lors d'une revue ou d'un incident. L'objectif du flux admin est simple : répondre à « que s'est-il passé ? » d'un coup d'œil, puis permettre de creuser sans noyer les gens dans du JSON brut.
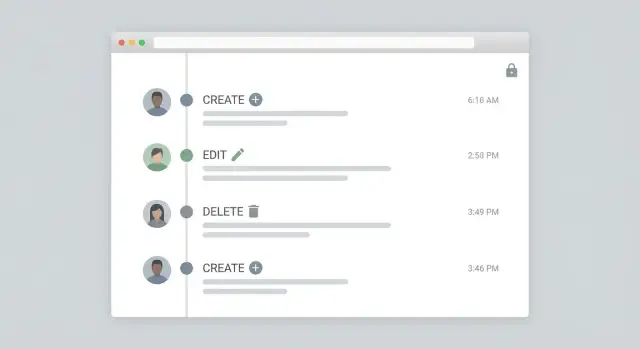
Commencez par une mise en page timeline : plus récent d'abord, une ligne par événement, et des verbes clairs comme Created, Updated, Deleted, Restored. Chaque ligne doit montrer l'acteur (personne ou système), la cible (type d'enregistrement plus un nom lisible) et le moment.
Un format de ligne pratique :
- Verb + objet : « Updated Customer : Acme Co. »
- Acteur : « Maya (Support) » ou « System : Nightly Sync »
- Heure : horodatage absolu (avec fuseau)
- Résumé du changement : « status: Pending -> Approved, limit: 5,000 -> 7,500 »
- Tags : Updated, Deleted, Integration, Job
Gardez « ce qui a changé » compact. Affichez 1 à 3 champs en ligne, puis proposez un panneau détaillé (drawer/modal) qui révèle tous les détails : valeurs before/after, source de la requête (web, mobile, API) et tout champ reason/commentaire.
Les filtres rendent le fil utile après la première semaine. Concentrez-vous sur des filtres qui correspondent à des questions réelles :
- Acteur (user ou system)
- Type d'objet (Customers, Orders, Permissions)
- Type d'action (Create/Update/Delete/Restore)
- Plage de dates
- Recherche textuelle (nom d'enregistrement ou ID)
Les liens comptent, mais seulement quand c'est permis. Si le lecteur a accès à l'enregistrement affecté, montrez une action « Voir l'enregistrement ». Sinon, affichez un placeholder sûr (par ex. « Enregistrement restreint ») tout en gardant l'entrée d'audit visible.
Rendez les actions système évidentes. Étiquetez distinctement les jobs planifiés et les intégrations pour que les admins puissent distinguer « Dana l'a supprimé » de « Nightly billing sync l'a mis à jour ».
Permissions et règles de confidentialité pour les données d'audit
Implémenter un workflow aujourd'hui
Commencez par un flux à risque élevé (approbations, facturation), puis étendez.
Les journaux d'audit sont des preuves, mais aussi des données sensibles. Traitez la journalisation comme un produit séparé dans votre app : règles d'accès claires, limites explicites et manipulation prudente des infos personnelles.
Décidez qui peut voir quoi. Une répartition courante : les admins système voient tout ; les managers de département voient les événements pour leur équipe ; les propriétaires d'enregistrement voient les événements liés aux enregistrements qu'ils peuvent déjà consulter (et rien d'autre). Si vous exposez un fil d'activité, appliquez les mêmes règles à chaque ligne, pas seulement à l'écran.
La visibilité au niveau ligne importe surtout dans les outils multi-tenant ou inter-départements. Votre table d'audit doit porter les mêmes clés de scope que les données métiers (tenant_id, department_id, project_id) pour pouvoir filtrer de façon cohérente. Exemple : un responsable support doit voir les changements des tickets de sa file, mais pas les ajustements de salaire RH, même si les deux ont lieu dans la même app.
Une politique simple qui fonctionne en pratique :
- Admin : accès complet aux audits tous locataires et départements confondus
- Manager : accès aux audits limité par department_id ou project_id
- Propriétaire d'enregistrement : accès aux audits uniquement pour les enregistrements qu'il peut voir
- Auditeur/conformité : accès en lecture seule, export autorisé, modifications bloquées
- Tout le monde : pas d'accès par défaut
La confidentialité est l'autre moitié. Stockez juste assez pour prouver ce qui s'est passé, mais évitez de transformer le log en copie de votre base. Pour les champs sensibles (SSN, notes médicales, détails de paiement), préférez la rédaction : enregistrez que le champ a changé sans stocker l'ancienne/nouvelle valeur. Vous pouvez logger « email changed » tout en masquant la valeur réelle, ou stocker une empreinte hachée pour vérification.
Séparez les événements de sécurité des changements métiers. Tentatives de connexion, réinitialisations MFA, création de clés API et changements de rôle doivent aller dans un flux security_audit avec un accès plus restreint et une rétention plus longue. Les modifications métiers (mises à jour de statut, approbations, changements de workflow) peuvent vivre dans un flux d'audit général.
Quand quelqu'un demande la suppression de ses données personnelles, n'effacez pas toute la piste d'audit. Au lieu de cela :
- Supprimez ou anonymisez le profil utilisateur
- Remplacez les identifiants d'acteur dans les logs par un pseudonyme stable (par ex. « deleted-user-123 »)
- Rédigez les valeurs de champ stockées qui sont des données personnelles
- Conservez les horodatages, types d'action et références d'enregistrement pour la conformité
Un journal d'audit utile n'est pas juste « on enregistre des événements ». Pour la conformité, vous devez prouver trois choses : vous avez conservé les données suffisamment longtemps, elles n'ont pas été modifiées après coup, et vous pouvez les récupérer rapidement quand on vous les demande.
Rétention : définissez une politique que vous pouvez expliquer
Commencez par une règle simple qui correspond à votre risque. Beaucoup d'équipes choisissent 90 jours pour le dépannage quotidien, 1 à 3 ans pour la conformité interne, et plus longtemps seulement pour les enregistrements réglementés. Notez ce qui remet la pendule à zéro (souvent : le temps de l'événement) et ce qui est exclu (par exemple, les logs qui contiennent des champs qu'on ne devrait pas garder).
Si vous avez plusieurs environnements, appliquez des rétentions différentes par environnement. Les logs de production ont généralement la plus longue rétention ; les logs de test n'en ont souvent pas besoin.
Intégrité : rendre la falsification difficile
Traitez les journaux d'audit comme append-only. Ne mettez pas à jour les lignes, et n'autorisez pas les admins standards à les supprimer. Si une suppression est vraiment nécessaire (demande légale, nettoyage), consignez aussi cette action comme un événement à part.
Un pattern pratique :
- Seul le serveur écrit les événements d'audit, jamais le client
- Pas de permissions UPDATE/DELETE sur la table d'audit pour les rôles normaux
- Un rôle « break glass » séparé pour les purges rares
- Un snapshot d'export périodique stocké hors de la base principale
Les auditeurs demandent souvent CSV ou JSON. Prévoyez un export filtrable par plage de dates et type d'objet (Invoice, User, Ticket) pour ne pas interroger la DB au pire moment.
Pour la performance, indexez selon vos recherches :
- created_at (requêtes par plage de temps)
- object_type + object_id (l'historique complet d'un enregistrement)
- actor_id (qui a fait quoi)
Surveillez les échecs silencieux. Si l'écriture d'audit échoue, vous perdez des preuves et vous n'en êtes souvent pas informé. Ajoutez une alerte simple : si l'application traite des écritures mais que les événements d'audit tombent à zéro pendant une période, notifiez les propriétaires et loggez l'erreur bruyamment.
Erreurs courantes qui rendent les journaux d'audit inutiles
Passer du prototype à la production
Déployez sur votre cloud ou exportez le code source quand vous avez besoin du contrôle total.
La façon la plus rapide de perdre du temps est de collecter beaucoup de lignes qui n'aident pas à répondre aux vraies questions : qui a changé quoi, quand et d'où.
Un piège commun est de s'appuyer uniquement sur des triggers de base de données. Les triggers peuvent enregistrer qu'une ligne a changé, mais ils manquent souvent le contexte métier : quel écran l'utilisateur a utilisé, quelle requête a causé le changement, quel rôle il avait, et si c'était une édition normale ou une règle automatisée.
Erreurs qui cassent le plus souvent la conformité et l'utilisabilité au quotidien :
- Enregistrer des payloads sensibles entiers (réinitialisations de mots de passe, tokens, notes privées) au lieu d'un diff minimal et d'identifiants sûrs.
- Permettre aux gens d'éditer ou de supprimer des enregistrements d'audit « pour corriger » l'historique.
- Oublier les chemins d'écriture non-UI comme les imports CSV, intégrations et jobs en arrière-plan.
- Utiliser des noms d'action inconsistants comme « Updated », « Edit », « Change », « Modify », rendant le fil incompréhensible.
- Logger seulement l'ID de l'objet, sans le nom lisible au moment du changement (les noms changent ensuite).
Standardisez votre vocabulaire d'événements tôt (par ex. user.created, user.updated, invoice.voided, access.granted) et exigez que chaque chemin d'écriture émette un événement. Traitez les données d'audit comme write-once : si quelqu'un a fait la mauvaise modification, loggez une nouvelle action corrective plutôt que de réécrire l'historique.
Checklist rapide et prochaines étapes
Avant de considérer le sujet clos, faites quelques vérifications rapides. Un bon journal d'audit est ennuyeux dans le meilleur sens : complet, cohérent et facile à lire quand quelque chose tourne mal.
Testez dans un environnement avec des données réalistes :
- Chaque create, update, delete, restore et édition en masse produit exactement un événement d'audit par enregistrement affecté (pas de trous, pas de doublons).
- Chaque événement inclut un acteur (user ou system), un timestamp (UTC), une action et une référence d'objet stable (type + ID).
- La vue « ce qui a changé » est lisible : noms de champs clairs, valeurs old/new affichées, et champs sensibles masqués ou résumés.
- Les admins peuvent filtrer le fil d'activité par plage, acteur, action et objet, et peuvent exporter les résultats pour des revues.
- Le log est difficile à falsifier : write-only pour la plupart des rôles, et les modifications du journal lui-même sont soit bloquées soit auditées séparément.
Si vous construisez des outils internes avec AppMaster (appmaster.io), une façon pratique de garder une bonne couverture est de faire passer les actions UI, endpoints API, imports et automatisations par le même pattern Business Process qui écrit à la fois la modification de données et l'événement d'audit. Ainsi, votre piste d'audit CRUD reste cohérente même lorsque les écrans et workflows évoluent.
Commencez petit avec un workflow important (tickets, approbations, changements de facturation), rendez le fil d'activité lisible, puis étendez jusqu'à ce que chaque chemin d'écriture émette un événement d'audit prévisible et searchable.
FAQ
Ajoutez des journaux d'audit dès que l'outil peut modifier des données réelles. Le premier litige ou la première demande d'audit arrive souvent plus tôt que prévu, et reconstituer l'historique après coup tient souvent de la conjecture.
Un journal d'audit utile doit pouvoir répondre à qui a fait la modification, quel enregistrement a été touché, ce qui a changé, quand cela s'est produit et d'où cela provient (UI, API, import ou job). Si vous ne pouvez pas répondre rapidement à l'une de ces questions, le journal ne sera pas digne de confiance.
Les logs de debug servent les développeurs : bruyants et souvent inconsistants. Les journaux d'audit servent la responsabilité : champs stables, libellés clairs et format lisible par des non-ingénieurs sur le long terme.
La couverture échoue généralement quand des modifications se produisent en dehors de l'écran d'édition normal. Les éditions en masse, imports, jobs planifiés, raccourcis admin et suppressions sont les endroits courants où on oublie d'émettre des événements d'audit.
Enregistrez un type d'acteur et un identifiant d'acteur, pas seulement un user ID. Ainsi vous pourrez distinguer clairement un membre du personnel d'un job système, d'un compte de service ou d'une intégration externe, et éviter l'ambiguïté « quelqu'un l'a fait ».
Stockez les horodatages en UTC dans la base, puis affichez-les dans le fuseau horaire du lecteur dans l'UI admin. Cela évite les disputes de fuseau horaire et rend les exports cohérents entre équipes et systèmes.
Utilisez une table d'événements append-only si vous voulez un seul endroit pour chercher et un flux d'activité simple. Utilisez des historiques versionnés par entité quand vous avez souvent besoin de vues à un instant t d'un seul enregistrement ; dans beaucoup d'applications, un journal d'événements avec diffs par champ couvre la plupart des besoins avec moins de stockage.
Privilégiez les suppressions logiques et consignez explicitement l'action de suppression. Si vous devez supprimer définitivement, écrivez d'abord l'événement d'audit et incluez un instantané ou les champs clés afin de pouvoir prouver ce qui a été supprimé par la suite.
Par défaut pratique : conservez des diffs par champ pour les mises à jour et des instantanés pour les créations et suppressions. Pour les champs sensibles, enregistrez qu'une valeur a changé sans stocker le secret lui-même, et rédigez/masquez les données personnelles pour éviter que le journal d'audit ne devienne une copie de la base de données.
Créez un seul chemin partagé « write + audit » et forcez chaque écriture à l'utiliser : actions UI, endpoints API, imports, jobs d'arrière-plan. Dans AppMaster, les équipes implémentent souvent ceci comme un Business Process réutilisable qui effectue la modification des données et écrit l'événement d'audit dans le même flux pour éviter les trous.