11 déc. 2025·8 min de lecture
Changements de schéma sans interruption : migrations additives sûres
Apprenez les changements de schéma sans interruption grâce à des migrations additives, des backfills sûrs et des déploiements par phases qui maintiennent la compatibilité avec les anciens clients.
Ce que signifie vraiment « zéro-downtime » pour les changements de schéma
Les changements de schéma sans interruption ne signifient pas que rien ne change. Ils signifient que les utilisateurs peuvent continuer à travailler pendant que vous mettez à jour la base de données et l'application, sans échecs ni flux de travail bloqués.
Le downtime, c'est tout moment où votre système cesse de se comporter normalement. Cela peut se traduire par des erreurs 500, des timeouts d'API, des écrans qui s'affichent mais montrent des valeurs vides ou erronées, des jobs en arrière-plan qui plantent, ou une base de données qui accepte les lectures mais bloque les écritures parce qu'une migration longue détient des verrous.
Un changement de schéma peut casser plus que l'interface principale. Les points de défaillance courants incluent des clients d'API qui attendent une ancienne forme de réponse, des jobs en arrière-plan qui lisent ou écrivent des colonnes spécifiques, des rapports qui interrogent les tables directement, des intégrations tierces, et des scripts admin internes qui « fonctionnaient hier ».
Les anciennes applications mobiles et les clients mis en cache posent souvent problème parce que vous ne pouvez pas les mettre à jour instantanément. Certains utilisateurs conservent une version d'app pendant des semaines. D'autres ont une connectivité intermittente et retenteront d'anciennes requêtes plus tard. Même les clients web peuvent se comporter comme des « anciennes versions » lorsqu'un service worker, un CDN ou un proxy conserve du code ou des hypothèses périmées.
L'objectif réel n'est pas « une grosse migration qui se termine vite ». C'est une suite de petites étapes où chaque étape fonctionne de manière autonome, même quand différents clients sont sur des versions différentes.
Une définition pratique : vous devriez pouvoir déployer nouveau code et nouveau schéma dans n'importe quel ordre, et le système continue de fonctionner.
Cet état d'esprit vous aide à éviter le piège classique : déployer une nouvelle app qui attend une nouvelle colonne avant que la colonne n'existe, ou déployer une nouvelle colonne que l'ancien code ne sait pas gérer. Planifiez les changements pour qu'ils soient additives d'abord, déployez-les par phases, et retirez les anciens chemins seulement après vous être assuré que rien ne les utilise.
Commencez par des changements additifs qui ne cassent pas le code existant
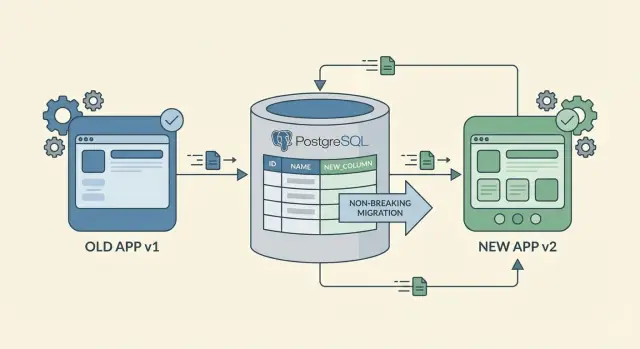
La voie la plus sûre vers le zéro-downtime est d'ajouter, pas de remplacer. Ajouter une nouvelle colonne ou une nouvelle table casse rarement quelque chose car le code existant peut continuer à lire et écrire l'ancien schéma.
Les renommages et suppressions sont les mouvements risqués. Un renommage équivaut en pratique à « ajouter + supprimer », et la partie « supprimer » est là où les anciens clients plantent. Si vous devez renommer, traitez-le en deux étapes : ajoutez d'abord le nouveau champ, conservez l'ancien pendant un certain temps, et supprimez-le seulement après avoir vérifié qu'il n'est plus utilisé.
Quand vous ajoutez des colonnes, commencez par des champs nullable. Une colonne nullable permet à l'ancien code de continuer à insérer des lignes sans connaître le nouveau champ. Si vous voulez finalement NOT NULL, ajoutez-le d'abord en nullable, backfillez, puis appliquez NOT NULL plus tard. Les valeurs par défaut peuvent aider aussi, mais attention : ajouter une valeur par défaut peut entraîner la modification de nombreuses lignes dans certaines bases, ce qui peut ralentir le changement.
Les index sont une autre addition « sûre mais pas gratuite ». Ils peuvent accélérer les lectures, mais créer et maintenir un index peut ralentir les écritures. Ajoutez des index quand vous savez exactement quelle requête les utilisera, et envisagez de les créer pendant les heures creuses si votre base est sollicitée.
Un petit ensemble de règles pour les migrations additives :
- Ajoutez d'abord de nouvelles tables ou colonnes, laissez les anciennes en place.
- Rendez les nouveaux champs optionnels (nullable) jusqu'à ce que les données soient remplies.
- Maintenez les anciennes requêtes et payloads fonctionnels jusqu'à la mise à jour des clients.
- Différez les contraintes (
NOT NULL, unique, clés étrangères) jusqu'après les backfills.
Plan de déploiement étape par étape pour garder les anciens clients fonctionnels
Considérez les changements de schéma sans interruption comme un rollout, pas comme un seul déploiement. Le but est de laisser les anciennes et nouvelles versions de l'app fonctionner côte à côte pendant que la base de données migre progressivement vers la nouvelle forme.
Une séquence pratique :
- Ajoutez le nouveau schéma de manière compatible. Créez de nouvelles colonnes ou tables, autorisez les nulls, et évitez les contraintes strictes que l'ancien code ne peut pas satisfaire. Si un index est nécessaire, créez-le de façon à ne pas bloquer les écritures.
- Déployez des changements backend capables de parler les deux « langages ». Mettez à jour l'API pour accepter les anciennes et nouvelles requêtes. Commencez à écrire dans le nouveau champ tout en gardant l'ancien champ correct. Cette phase de « double écriture » permet la coexistence des versions.
- Backfillez les données existantes en petits lots. Remplissez la nouvelle colonne pour les anciennes lignes progressivement. Limitez la taille des lots, ajoutez des pauses si nécessaire, et suivez la progression pour pouvoir mettre en pause si la charge augmente.
- Basculez les lectures seulement après une couverture élevée. Une fois la plupart des lignes backfillées et la confiance établie, changez le backend pour préférer le nouveau champ. Gardez un fallback vers l'ancien champ pendant un certain temps.
- Retirez l'ancien champ en dernier, et seulement lorsqu'il est vraiment inutilisé. Attendez que les anciennes builds mobiles soient majoritairement obsolètes, que les logs ne montrent plus de lectures de l'ancien champ, et que vous ayez un plan de rollback propre. Ensuite, supprimez la colonne et le code associé.
Exemple : vous introduisez full_name alors que des clients plus anciens envoient encore first_name et last_name. Pendant un temps, le backend peut construire full_name à l'écriture, backfiller les utilisateurs existants, puis lire full_name par défaut tout en continuant à accepter les anciens payloads. Vous supprimez les anciens champs seulement quand l'adoption est claire.
Un backfill remplit une nouvelle colonne ou table pour les lignes existantes. C'est souvent la partie la plus risquée des changements de schéma sans interruption parce qu'il peut générer une forte charge sur la base, des verrous longs et un comportement « à moitié migré ».
Commencez par choisir comment exécuter le backfill. Pour de petits jeux de données, un runbook manuel ponctuel peut suffire. Pour de grands jeux, préférez un worker en arrière-plan ou une tâche planifiée capable de s'exécuter plusieurs fois et de s'arrêter en sécurité.
Découpez le travail en lots pour contrôler la pression sur la base. N'actualisez pas des millions de lignes dans une seule transaction. Visez une taille de chunk prévisible et une courte pause entre les lots pour que le trafic utilisateur reste fluide.
Un schéma pratique :
- Sélectionnez un petit lot (par exemple, les 1 000 lignes suivantes) en utilisant une clé indexée.
- N'actualisez que ce qui manque (évitez de réécrire des lignes déjà backfillées).
- Engagez rapidement la transaction, puis dormez brièvement.
- Enregistrez la progression (dernier ID ou timestamp traité).
- Réessayez en cas d'échec sans tout recommencer.
Rendez le job redémarrable. Stockez un simple marqueur de progression dans une table dédiée, et concevez le job pour que le relancer n'altère pas les données. Les mises à jour idempotentes (par exemple, UPDATE ... WHERE new_field IS NULL) sont vos alliées.
Validez au fur et à mesure. Suivez combien de lignes sont encore manquantes, et ajoutez quelques contrôles de cohérence : pas de soldes négatifs, timestamps dans l'intervalle attendu, statut dans un ensemble autorisé. Contrôlez quelques enregistrements réels par échantillonnage.
Décidez de ce que doit faire l'app tant que le backfill est incomplet. Une option sûre est la lecture par fallback : si le nouveau champ est null, calculez ou lisez la valeur ancienne. Exemple : vous ajoutez preferred_language. Tant que le backfill n'est pas terminé, l'API peut retourner la langue existante depuis les paramètres de profil quand preferred_language est vide, et n'exiger le nouveau champ qu'après achèvement.
Règles de compatibilité API pour des versions clientes mixtes
Transformez votre déploiement en étapes
Utilisez des outils visuels pour ajouter des champs, effectuer des backfills en toute sécurité et maintenir les anciens clients opérationnels.
Quand vous publiez un changement de schéma, vous ne contrôlez rarement tous les clients. Les utilisateurs web se mettent à jour rapidement, tandis que des builds mobiles plus anciennes peuvent rester actives pendant des semaines. C'est pourquoi les API rétrocompatibles importent même si votre migration de base est « sûre ».
Considérez d'abord les nouvelles données comme optionnelles. Ajoutez de nouveaux champs aux requêtes et réponses, mais ne les rendez pas obligatoires dès le premier jour. Si un ancien client n'envoie pas le nouveau champ, le serveur doit toujours accepter la requête et se comporter comme auparavant.
Évitez de changer le sens des champs existants. Renommer un champ est faisable si vous maintenez l'ancien nom fonctionnel. Réutiliser un champ pour une nouvelle signification est source de bugs subtils.
Les valeurs par défaut côté serveur sont votre filet de sécurité. Quand vous introduisez une colonne comme preferred_language, définissez une valeur par défaut côté serveur lorsqu'elle manque. La réponse API peut inclure le nouveau champ, et les anciens clients doivent pouvoir l'ignorer.
Règles de compatibilité qui évitent la plupart des incidents :
- Ajoutez d'abord les champs en option, puis appliquez les règles plus tard après adoption.
- Gardez l'ancien comportement stable, même si vous proposez un meilleur comportement derrière un flag.
- Appliquez des valeurs par défaut côté serveur pour que les anciens clients puissent omettre les nouveaux champs.
- Supposez un trafic mixte et testez les deux chemins : « le nouveau client l'envoie » et « l'ancien client l'omets ».
- Conservez messages et codes d'erreur stables pour que la surveillance ne devienne pas bruyante.
Exemple : vous ajoutez company_size au flux d'inscription. Le backend peut définir « unknown » si le champ est absent. Les clients plus récents enverront la vraie valeur, les anciens continueront de fonctionner, et les tableaux de bord resteront lisibles.
Quand votre app se régénère : garder le schéma et la logique synchronisés
Si votre plateforme régénère l'application, vous obtenez une reconstruction propre du code et de la configuration. Cela aide pour les changements de schéma sans interruption car vous pouvez faire de petites étapes additives et redéployer souvent au lieu de conserver des correctifs pendant des mois.
La clé est une seule source de vérité. Si le schéma change à un endroit et la logique métier ailleurs, la dérive arrive vite. Décidez où les changements sont définis, et considérez tout le reste comme sortie générée.
Des noms clairs réduisent les accidents pendant les rollouts phasés. Si vous introduisez un nouveau champ, rendez évident lequel est sûr pour les anciens clients et lequel est le nouveau chemin. Par exemple, nommer une colonne status_v2 est plus sûr que status_new car cela reste compréhensible six mois plus tard.
Que retester après chaque régénération
Même quand les changements sont additifs, une reconstruction peut révéler des couplages cachés. Après chaque régénération et déploiement, revérifiez un petit ensemble de flux critiques :
- Inscription, connexion, réinitialisation de mot de passe, rafraîchissement de token.
- Actions principales de création et mise à jour (celles les plus utilisées).
- Contrôles admin et permissions.
- Paiements et webhooks (par exemple, événements Stripe).
- Notifications et messagerie (email/SMS, Telegram).
Planifiez les étapes de migration avant d'ouvrir votre éditeur : ajoutez le nouveau champ, déployez en supportant les deux champs, backfillez, basculez les lectures, puis retirez l'ancien chemin plus tard. Cette séquence maintient schéma, logique et code généré synchronisés pour que les changements restent petits, examinables et réversibles.
Construisez en pensant aux clients mixtes
Créez un backend prêt pour la production avec modélisation PostgreSQL et changements d'API compatibles versions.
La plupart des incidents pendant des migrations sans interruption ne viennent pas d'un travail « dur » sur la base. Ils résultent du changement du contrat entre la base, l'API et les clients dans le mauvais ordre.
Pièges fréquents et actions plus sûres :
- Renommer une colonne alors que l'ancien code la lit encore. Conservez l'ancienne colonne, ajoutez la nouvelle, et cartographiez les deux un moment (écrire dans les deux, ou utiliser une vue). Renommez seulement quand vous prouvez que personne ne dépend de l'ancien nom.
- Rendre un champ nullable obligatoire trop tôt. Ajoutez la colonne en nullable, déployez du code qui l'écrit partout, backfillez les anciennes lignes, puis appliquez
NOT NULL dans une migration finale.
- Backfiller dans une grosse transaction qui verrouille les tables. Backfillez par petits lots, avec limites et pauses. Suivez la progression pour pouvoir reprendre en toute sécurité.
- Basculement des lectures avant que les écritures n'alimentent les nouveaux champs. Basculez d'abord les écritures, puis backfillez, enfin basculez les lectures. Si les lectures changent avant les écritures, vous aurez des écrans vides, des totaux erronés ou des erreurs de champ manquant.
- Supprimer les anciens champs sans preuve que les anciens clients ont disparu. Conservez les anciens champs plus longtemps que vous ne le pensez. Supprimez-les seulement quand les métriques montrent que les anciennes versions sont effectivement inactives et après une fenêtre de dépréciation communiquée.
Si vous régénérez votre app, il est tentant de « nettoyer » les noms et contraintes en une seule fois. Résistez : le nettoyage est la dernière étape, pas la première.
Une bonne règle : si un changement ne peut pas être déployé en avant et reculé en toute sécurité, il n'est pas prêt pour la production.
Monitoring et plan de rollback pour des migrations par phases
Rendez le zéro-downtime routinier
Ajoutez d'abord des colonnes, basculez les lectures plus tard, et considérez le nettoyage comme une étape planifiée.
Les changements de schéma sans interruption se jouent sur deux choses : ce que vous surveillez, et la rapidité à laquelle vous pouvez arrêter.
Surveillez des signaux qui reflètent l'impact utilisateur réel, pas seulement « le déploiement est terminé » :
- Taux d'erreurs API (pics 4xx/5xx sur les endpoints mis à jour).
- Requêtes lentes (p95 ou p99 pour les tables touchées).
- Latence des écritures (durée des insert/update en pic).
- Profondeur des queues (jobs qui s'accumulent pour les backfills ou le traitement d'événements).
- Pression CPU/IO de la base de données (saut soudain après le changement).
Si vous faites de la double écriture, ajoutez un logging temporaire qui compare les deux valeurs. Gardez-le serré : loggez seulement quand les valeurs diffèrent, incluez l'ID de l'enregistrement et un court code raison, et échantillonnez si le volume est élevé. Créez un rappel pour supprimer ce logging après la migration afin qu'il ne devienne pas du bruit permanent.
Le rollback doit être réaliste. La plupart du temps, vous ne revenez pas sur le schéma. Vous revenez sur le code et laissez le schéma additif en place.
Un runbook de rollback pratique :
- Revenir à la version applicative connue comme bonne.
- Désactiver d'abord les nouvelles lectures, puis les nouvelles écritures.
- Conserver les nouvelles tables/colonnes, mais cesser de les utiliser.
- Mettre les backfills en pause jusqu'à stabilisation des métriques.
Pour les backfills, prévoyez un interrupteur d'arrêt actionnable en quelques secondes (feature flag, valeur de config, pause du job). Communiquez aussi les phases à l'avance : quand commence la double écriture, quand le backfill s'exécute, quand les lectures basculent, et ce que signifie « stop » pour que personne n'improvise sous pression.
Liste de vérification rapide avant déploiement
Juste avant de livrer un changement de schéma, arrêtez-vous et effectuez cette vérification rapide. Elle attrape de petites hypothèses qui deviennent des incidents avec des versions clientes mixtes.
- Le changement est additif, pas destructif. La migration ajoute seulement tables, colonnes ou index. Rien n'est supprimé, renommé ou rendu plus strict au point de rejeter des écritures anciennes.
- Les lectures fonctionnent avec les deux formes. Le nouveau code serveur gère à la fois « nouveau champ présent » et « nouveau champ absent » sans erreur. Les valeurs optionnelles ont des valeurs par défaut sûres.
- Les écritures restent compatibles. Les nouveaux clients peuvent envoyer les nouvelles données, les anciens clients peuvent toujours envoyer les anciens payloads et réussir. Si les deux versions doivent coexister, le serveur accepte les deux formats et produit des réponses que les anciens clients peuvent parser.
- Le backfill est sûr à arrêter et à redémarrer. Le job s'exécute par lots, redémarre sans dupliquer ni corrompre les données, et affiche un nombre mesurable de « lignes restantes ».
- Vous connaissez la date de suppression. Il y a une règle concrète pour quand il est sûr de supprimer les champs ou la logique legacy (par exemple, après X jours plus confirmation que Y% des requêtes viennent de clients mis à jour).
Si vous utilisez une plateforme qui régénère, ajoutez une vérification supplémentaire : générez et déployez une build à partir du modèle exact que vous migrez, puis confirmez que l'API et la logique générée tolèrent toujours les anciens enregistrements. Un échec courant est de supposer que le nouveau schéma implique une logique requise.
Écrivez aussi deux actions rapides à effectuer si quelque chose tourne mal après le déploiement : ce que vous surveillerez (erreurs, timeouts, progression du backfill) et ce que vous retirerez en premier (désactiver un feature flag, mettre en pause le backfill, revenir sur la release serveur). Cela transforme « on réagira vite » en un plan concret.
Exemple : ajouter un nouveau champ alors que des apps mobiles anciennes sont encore actives
Maintenez le schéma et le code alignés
Régénérez du code source propre au fur et à mesure que votre schéma évolue, sans conserver des correctifs sales.
Vous gérez une app de commandes. Vous avez besoin d'un nouveau champ, delivery_window, qui sera requis pour de nouvelles règles métier. Le problème : d'anciennes builds iOS et Android sont toujours utilisées et n'enverront pas ce champ pendant des jours ou des semaines. Si vous exigez ce champ immédiatement en base, ces clients vont échouer.
Un chemin sûr :
- Phase 1 : Ajoutez la colonne en nullable, sans contraintes. Conservez lectures et écritures inchangées.
- Phase 2 : Double écriture. Les nouveaux clients (ou le backend) écrivent le nouveau champ. Les anciens clients continuent de fonctionner car la colonne accepte null.
- Phase 3 : Backfill. Remplissez
delivery_window pour les anciennes lignes en appliquant une règle (inférer depuis la méthode d'expédition, ou mettre par défaut “anytime” jusqu'à ce que le client le modifie).
- Phase 4 : Basculez les lectures. Mettez à jour l'API et l'UI pour lire
delivery_window en priorité, mais retombez sur la valeur inférée si elle manque.
- Phase 5 : Appliquez l'obligation plus tard. Après adoption et backfill, ajoutez
NOT NULL et supprimez le fallback.
Ce que ressentent les utilisateurs à chaque phase doit rester ennuyeux (c'est l'objectif) :
- Les anciens utilisateurs mobiles peuvent toujours passer commande parce que l'API n'exclut pas les données manquantes.
- Les nouveaux utilisateurs voient le nouveau champ et leurs choix sont sauvegardés de manière cohérente.
- Support et ops voient le champ se remplir progressivement, sans trous soudains.
Un simple garde-fou de monitoring pour chaque étape : suivez le pourcentage de nouvelles commandes où delivery_window est non-null. Quand il reste constamment élevé (et que les erreurs de validation pour « champ manquant » sont proches de zéro), il est généralement sûr de passer du backfill à l'application de la contrainte.
Étapes suivantes : bâtir un playbook de migration répétable
Un rollout soigné ponctuel n'est pas une stratégie. Traitez les changements de schéma comme une routine : mêmes étapes, même nommage, mêmes validations. Ainsi le changement additif suivant restera banal, même quand l'app est sollicitée et que les clients sont à des versions différentes.
Gardez le playbook court. Il doit répondre : quoi ajouter, comment le livrer en sécurité, et quand retirer l'ancien.
Un template simple :
- Ajouter seulement (nouvelle colonne/table/index, nouveau champ API optionnel).
- Livrer du code capable de lire les deux formes.
- Backfiller par petits lots, avec un signal clair de « fini ».
- Basculer le comportement via feature flag ou config, pas un redeploy.
- Supprimer les anciens champs/endpoints seulement après une date limite et une vérification.
Commencez avec une table à faible risque (un statut optionnel, un champ notes) et exécutez le playbook de bout en bout : changement additif, backfill, clients mixés, puis nettoyage. Cet entraînement révèle les lacunes de monitoring, de batching et de communication avant une refonte majeure.
Une habitude qui empêche l'encombrement à long terme : traitez les éléments « à supprimer plus tard » comme du vrai travail. Quand vous ajoutez une colonne temporaire, du code de compatibilité ou une logique de double écriture, créez immédiatement un ticket de nettoyage avec un propriétaire et une date. Gardez une petite note de « dette de compatibilité » dans les docs de release pour qu'elle reste visible.
Si vous construisez avec AppMaster, vous pouvez considérer la régénération comme partie du processus de sécurité : modélisez le schéma additif, mettez à jour la logique métier pour gérer à la fois anciens et nouveaux champs pendant la transition, et régénérez pour que le code source reste propre au fil des évolutions. Si vous voulez voir comment ce workflow s'intègre dans une approche no-code qui produit néanmoins du code source réel, AppMaster (appmaster.io) est conçu autour de ce style de livraison itérative et phasée.
L'objectif n'est pas la perfection. C'est la répétabilité : chaque migration a un plan, une mesure et une voie de sortie.
FAQ
Le zéro-downtime signifie que les utilisateurs peuvent continuer à travailler normalement pendant que vous modifiez le schéma et déployez du code. Cela inclut d'éviter les pannes évidentes, mais aussi les cassures silencieuses comme des écrans vides, des valeurs incorrectes, des crashs de jobs ou des écritures bloquées par de longues verrous.
Parce que de nombreuses parties de votre système dépendent de la forme de la base de données, pas seulement l'interface principale. Les jobs en arrière-plan, les rapports, les scripts d'administration, les intégrations et les anciennes applications mobiles peuvent continuer à envoyer ou attendre les anciens champs longtemps après le déploiement du nouveau code.
Les anciennes versions mobiles peuvent rester actives pendant des semaines, et certains clients retentent d'anciennes requêtes plus tard. Votre API doit accepter à la fois les anciens et les nouveaux payloads pendant un moment pour que les versions mixtes coexistent sans erreurs.
Les changements additives n'effacent rien de l'ancien schéma, donc ils ne cassent généralement pas le code existant. Les renommages et suppressions sont risqués parce qu'ils retirent quelque chose que les anciens clients lisent ou écrivent, ce qui cause des crashs ou des requêtes échouées.
Ajoutez d'abord la colonne en nullable pour que l'ancien code puisse continuer à insérer des lignes. Backfillez les lignes existantes par lots, puis seulement après une couverture suffisante appliquez NOT NULL en dernier pas.
Traitez-la comme un déploiement en plusieurs étapes : ajoutez un schéma compatible, déployez du code qui prend en charge les deux versions, backfillez par petits lots, basculez les lectures avec un fallback, et supprimez l'ancien champ seulement quand vous pouvez prouver qu'il n'est plus utilisé. Chaque étape doit être sûre en elle‑même.
Exécutez-le par petits lots avec de courtes transactions pour ne pas verrouiller les tables ni provoquer de pics de charge. Rendez le job redémarrable et idempotent en ne mettant à jour que les lignes qui n'ont pas la nouvelle valeur, et suivez la progression pour pouvoir mettre en pause et reprendre en toute sécurité.
Rendez les nouveaux champs optionnels au début et appliquez des valeurs par défaut côté serveur lorsqu'ils manquent. Maintenez l'ancien comportement stable, évitez de changer le sens des champs existants, et testez les deux chemins : “le nouveau client l'envoie” et “l'ancien client l'omets”.
La plupart du temps vous revenez sur le code applicatif, pas sur le schéma. Conservez les colonnes/tables additives, désactivez d'abord les nouvelles lectures, puis les nouvelles écritures, et mettez les backfills en pause jusqu'à stabilisation des métriques pour récupérer rapidement sans perte de données.
Surveillez des signaux d'impact utilisateur : taux d'erreur API, requêtes lentes (p95/p99) sur les tables touchées, latence des écritures, profondeur des queues et pression CPU/IO sur la base de données. N'avancez que quand les métriques sont stables et que la couverture du nouveau champ est élevée, puis planifiez le nettoyage comme du vrai travail.