Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Erfahre, wie du Zero-Downtime-Schemaänderungen mit additiven Migrationen, sicheren Backfills und phasenweisen Rollouts durchführst, sodass ältere Clients während Releases weiter funktionieren.
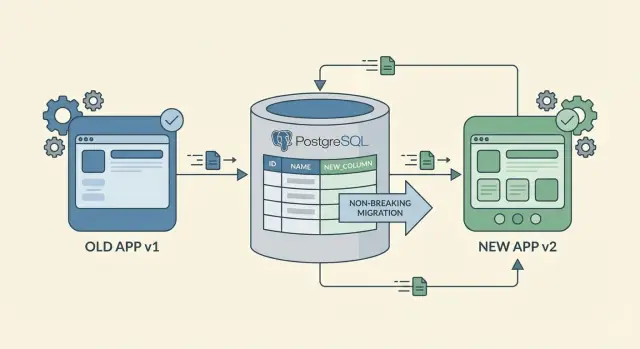
Zero-Downtime-Schemaänderungen bedeuten nicht, dass sich nichts ändert. Sie bedeuten, dass Nutzer weiterarbeiten können, während du Datenbank und App aktualisierst — ohne Ausfälle oder blockierte Workflows.
Downtime ist jeder Moment, in dem dein System nicht normal funktioniert. Das kann sich zeigen als 500-Fehler, API-Timeouts, Bildschirme, die laden, aber leere oder falsche Werte zeigen, Hintergrundjobs, die abstürzen, oder eine Datenbank, die zwar liest, aber Schreiben blockiert, weil eine lange Migration Sperren hält.
Eine Schemaänderung kann mehr kaputtmachen als die Haupt-UI. Häufige Fehlerquellen sind API-Clients, die eine alte Antwortstruktur erwarten, Hintergrundjobs, die spezifische Spalten lesen oder schreiben, Reports, die direkt auf Tabellen zugreifen, Drittanbieter-Integrationen und interne Admin-Skripte, die „gestern noch funktionierten.“
Ältere Mobil-Apps und gecachte Clients sind ein häufiges Problem, weil du sie nicht sofort aktualisieren kannst. Manche Nutzer behalten eine App-Version wochenlang. Andere haben sporadische Verbindung und senden alte Anfragen später erneut. Sogar Web-Clients können sich wie „ältere Versionen“ verhalten, wenn ein Service Worker, CDN oder Proxy-Cache veralteten Code oder Erwartungen festhält.
Das eigentliche Ziel ist nicht „eine große Migration, die schnell durchläuft.“ Es ist eine Abfolge kleiner Schritte, bei denen jeder Schritt für sich funktioniert — selbst wenn verschiedene Clients auf unterschiedlichen Versionen laufen.
Eine praktische Definition: Du solltest in beliebiger Reihenfolge neuen Code und neues Schema deployen können, und das System funktioniert weiterhin.
Dieses Mindset hilft, die klassische Falle zu vermeiden: die neue App ausrollen, die eine neue Spalte erwartet, bevor die Spalte existiert, oder eine neue Spalte hinzufügen, die alter Code nicht verarbeiten kann. Plane Änderungen so, dass sie zuerst additiv sind, rolle sie phasenweise aus und entferne alte Pfade erst, wenn du sicher bist, dass sie nicht mehr verwendet werden.
Der sicherste Weg zu Zero-Downtime-Schemaänderungen ist hinzufügen, nicht ersetzen. Neue Spalten oder Tabellen zu ergänzen bricht selten etwas, weil vorhandener Code weiterhin die alte Struktur lesen und schreiben kann.
Umbenennungen und Löschungen sind riskant. Eine Umbenennung ist effektiv „neu hinzufügen + alt entfernen“, und das Entfernen ist der Teil, bei dem ältere Clients abstürzen. Wenn du umbenennen musst, behandle es als zweistufige Änderung: Zuerst das neue Feld hinzufügen, das alte Feld eine Weile behalten und erst entfernen, wenn du sicher bist, dass nichts mehr davon abhängt.
Beim Hinzufügen von Spalten solltest du mit nullable-Feldern beginnen. Eine nullable-Spalte erlaubt altem Code, weiterhin Zeilen einzufügen, ohne das neue Feld zu kennen. Wenn du letztlich NOT NULL willst, füge zunächst nullable hinzu, backfille, und erzwinge NOT NULL später. Defaults können helfen, aber Vorsicht: Das Hinzufügen eines Defaults kann in manchen Datenbanken dennoch viele Zeilen berühren und die Änderung verlangsamen.
Indizes sind eine weitere „sicher, aber nicht kostenlos“-Ergänzung. Sie können Lesezugriffe beschleunigen, aber Aufbau und Pflege eines Index können Schreibeingriffe verlangsamen. Füge Indizes hinzu, wenn du genau weißt, welche Query sie nutzt, und erwäge, sie in ruhigeren Zeiten zu erstellen, wenn die DB stark belastet ist.
Eine einfache Regel für additive DB-Migrationen:
NOT NULL, unique, foreign keys) bis nach den Backfills.Behandle Zero-Downtime-Schemaänderungen als Rollout, nicht als Single-Deploy. Ziel ist, dass alte und neue App-Versionen nebeneinander laufen können, während die Datenbank schrittweise zur neuen Form übergeht.
Eine praktische Reihenfolge:
Beispiel: Du führst full_name ein, aber ältere Clients senden weiterhin first_name und last_name. Für eine Zeit kann das Backend full_name beim Schreiben aus den alten Feldern zusammenstellen, bestehende Nutzer backfillen und später standardmäßig full_name lesen, während alte Payloads weiter unterstützt werden. Erst wenn die Adoption klar ist, entfernst du die alten Felder.
Ein Backfill befüllt eine neue Spalte oder Tabelle für bestehende Reihen. Er ist oft der riskanteste Teil von Zero-Downtime-Schemaänderungen, weil er hohe DB-Last, lange Sperren und verwirrendes „halb migriertes“ Verhalten verursachen kann.
Beginne mit der Entscheidung, wie der Backfill ausgeführt wird. Bei kleinen Datensätzen kann ein einmaliges manuelles Runbook ausreichen. Bei größeren Datensätzen ist ein Background-Worker oder ein geplantes Job-System besser, das wiederholt läuft und sicher gestoppt werden kann.
Zerteile die Arbeit in Batches, damit du den Druck auf die DB kontrollierst. Aktualisiere nicht Millionen Zeilen in einer Transaktion. Ziel ist eine vorhersehbare Chunk-Größe und kurze Pausen zwischen den Batches, damit normaler Nutzertraffic flüssig bleibt.
Ein praktisches Muster:
Mach den Job restartbar. Speichere einen einfachen Fortschrittsmarker in einer eigenen Tabelle und designe den Job so, dass erneutes Ausführen Daten nicht korrumpiert. Idempotente Updates (z. B. UPDATE ... WHERE new_field IS NULL) sind hilfreich.
Validiere währenddessen. Tracke, wie viele Reihen noch das neue Feld vermissen und füge ein paar Plausibilitätschecks hinzu — z. B. keine negativen Salden, Timestamps im erwarteten Bereich, Status in einer erlaubten Menge. Stichproben helfen, echte Datensätze zu prüfen.
Entscheide, was die App tun soll, solange der Backfill unvollständig ist. Eine sichere Option sind Fallback-Reads: Wenn das neue Feld NULL ist, berechne oder lies den alten Wert. Beispiel: Du fügst preferred_language hinzu. Solange der Backfill läuft, kann die API die Sprache aus den Profil-Einstellungen zurückgeben, wenn preferred_language leer ist — und das neue Feld erst nach Abschluss verpflichtend machen.
Wenn du eine Schemaänderung ausrollst, hast du selten Kontrolle über alle Clients. Web-User aktualisieren schnell, ältere Mobile-Builds können Wochen aktiv bleiben. Deshalb sind abwärtskompatible APIs wichtig, selbst wenn die DB-Migration „sicher“ ist.
Behandle neue Daten zunächst als optional. Füge neue Felder zu Requests und Responses hinzu, mache sie aber nicht am ersten Tag verpflichtend. Wenn ein älterer Client das neue Feld nicht sendet, sollte der Server die Anfrage weiterhin akzeptieren und wie zuvor verarbeiten.
Vermeide es, die Bedeutung bestehender Felder zu ändern. Ein Feld umzubenennen kann in Ordnung sein, wenn der alte Name weiterhin funktioniert. Ein Feld für eine neue Bedeutung wiederzuverwenden ist eine häufige Ursache für subtile Fehler.
Server-seitige Defaults sind dein Sicherheitsnetz. Wenn du eine neue Spalte wie preferred_language einführst, setze auf dem Server einen Default, wenn sie fehlt. Die API-Antwort kann das neue Feld enthalten, ältere Clients ignorieren es einfach.
Kompatibilitätsregeln, die die meisten Ausfälle verhindern:
Beispiel: Du fügst company_size im Signup-Flow hinzu. Das Backend kann einen Default wie „unknown“ setzen, wenn das Feld fehlt. Neue Clients senden den echten Wert, alte Clients funktionieren weiter, und Dashboards bleiben lesbar.
Wenn deine Plattform die Anwendung regeneriert, erhältst du einen sauberen Rebuild von Code und Konfiguration. Das hilft bei Zero-Downtime-Schemaänderungen, weil du kleine, additive Schritte machen und häufiger neu deployen kannst, anstatt Patches monatelang mitzuschleppen.
Der Schlüssel ist eine Quelle der Wahrheit. Wenn das DB-Schema an einer Stelle geändert wird und die Business-Logik an einer anderen, entsteht schnell Drift. Entscheide, wo Änderungen definiert werden, und behandle alles andere als generierten Output.
Klare Benennung reduziert Unfälle während phasenweiser Rollouts. Wenn du ein neues Feld einführst, mache klar, welches für alte Clients sicher ist und welches der neue Pfad ist. Ein Name wie status_v2 ist hilfreicher als status_new, weil er auch in sechs Monaten noch Sinn ergibt.
Selbst bei additiven Änderungen kann ein Rebuild versteckte Kopplungen offenlegen. Nach jedem Rebuild und Deploy re-checke eine kleine Menge kritischer Flows:
Plane die Migrationsschritte, bevor du den Editor öffnest: neues Feld hinzufügen, deployen mit Unterstützung beider Felder, backfill, Reads umschalten, dann den alten Pfad später entfernen. Diese Reihenfolge hält Schema, Logik und generierten Code zusammen, so dass Änderungen klein, prüfbar und umkehrbar bleiben.
Die meisten Ausfälle bei Zero-Downtime-Schemaänderungen entstehen nicht durch harte DB-Arbeit. Sie entstehen, wenn der Vertrag zwischen DB, API und Clients in falscher Reihenfolge geändert wird.
Häufige Fallen und sichere Alternativen:
NOT NULL erst mit einer finalen Migration.Wenn du deine App regenerierst, ist es verführerisch, Namen und Constraints auf einmal „aufzuräumen“. Widerstehe dem Drang. Cleanup ist der letzte Schritt, nicht der erste.
Eine gute Regel: Wenn sich eine Änderung nicht sicher vorwärts und rückwärts fahren lässt, ist sie noch nicht produktionsreif.
Zero-Downtime-Schemaänderungen stehen und fallen mit zwei Dingen: was du beobachtest und wie schnell du stoppen kannst.
Tracke Signale, die echten Nutzerimpact widerspiegeln, nicht nur „das Deploy ist durchgelaufen“:
Wenn du dual writes machst (schreibe sowohl in alte als auch neue Spalten/Tabellen), füge temporäres Logging hinzu, das die beiden vergleicht. Halte es schlank: logge nur bei Abweichungen, mit Record-ID und kurzem Reason-Code, und sample, wenn das Volumen hoch ist. Erinnere dich daran, dieses Logging nach der Migration zu entfernen, damit es nicht dauerhaft Lärm erzeugt.
Rollback muss realistisch sein. Meistens rollst du den Code zurück, nicht das Schema. Lass additive Spalten stehen, deaktiviere neue Reads zuerst, dann neue Writes, und pausiere Backfills, bis die Metriken stabil sind.
Ein praktisches Rollback-Runbook:
Für Backfills baue einen Stop-Schalter, den du in Sekunden umlegen kannst (Feature-Flag, Config-Wert, Job-Pause). Kommuniziere außerdem die Phasen im Voraus: wann dual writes beginnen, wann Backfills laufen, wann Reads wechseln und wie ein „Stopp“ aussieht, damit niemand unter Druck improvisiert.
Kurz vor dem Shippen einer Schemaänderung halte kurz an und führe diese Prüfung durch. Sie fängt kleine Annahmen ein, die bei gemischten Client-Versionen zu Ausfällen führen.
Wenn du eine regenerierende Plattform nutzt, füge noch eine Sanity-Prüfung hinzu: Generiere und deploye einen Build aus genau dem Modell, das du migrierst, und bestätige, dass die generierte API und Business-Logik alte Datensätze noch tolerieren. Ein häufiger Fehler ist anzunehmen, das neue Schema impliziere neue verpflichtende Logik.
Schreibe außerdem zwei schnelle Aktionen auf, die du bei Problemen nach dem Deploy ausführst: was du beobachtest (Fehler, Timeouts, Backfill-Fortschritt) und was du zuerst zurückdrehst (Feature-Flag off, Backfill pausieren, Server-Release revert). Das macht „wir reagieren schnell“ zu einem echten Plan.
Du betreibst eine Order-App. Du brauchst ein neues Feld, delivery_window, das für neue Geschäftsregeln verpflichtend sein soll. Das Problem: ältere iOS- und Android-Builds sind noch in Gebrauch und senden das Feld nicht für Tage oder Wochen. Wenn die DB es sofort verpflichtend macht, fangen diese Clients an zu scheitern.
Ein sicherer Pfad:
delivery_window für alte Reihen durch eine Regel (aus Versandart ableiten oder standardmäßig „anytime“ bis der Kunde es ändert).delivery_window bevorzugt wird, aber auf den abgeleiteten Wert zurückfällt, wenn es fehlt.NOT NULL hinzufügen und den Fallback entfernen.Was Nutzer in jeder Phase erleben, bleibt unspektakulär (das ist das Ziel):
Ein einfaches Monitoring-Gate für jede Phase: Tracke den Prozentsatz neuer Bestellungen, bei denen delivery_window nicht NULL ist. Wenn dieser Wert konstant hoch bleibt (und Validierungsfehler wegen „fehlendem Feld“ nahe null liegen), ist es meist sicher, vom Backfill zum Erzwingen der Constraint überzugehen.
Ein einmaliger, sorgfältiger Rollout ist keine Strategie. Behandle Schemaänderungen als Routine: gleiche Schritte, gleiche Benennung, gleiche Freigaben. Dann bleibt auch die nächste additive Änderung unspektakulär, selbst wenn die App viel Verkehr hat und Clients auf unterschiedlichen Versionen sind.
Halte das Playbook kurz. Es sollte beantworten: Was fügen wir hinzu, wie deployen wir sicher, und wann entfernen wir die alten Teile.
Eine einfache Vorlage:
Starte mit einer risikominimalen Tabelle (ein neues optionales Statusfeld, ein Notizen-Feld) und führe das komplette Playbook durch: additive Änderung, Backfill, gemischte Clients, dann Cleanup. Diese Übung offenbart Lücken in Monitoring, Batch-Strategie und Kommunikation, bevor du ein größeres Redesign versuchst.
Eine hilfreiche Gewohnheit, um langfristiges Chaos zu vermeiden: Behandle „später entfernen“-Items wie echte Arbeit. Wenn du eine temporäre Spalte, Kompatibilitätslogik oder Dual-Write einfügst, erstelle sofort ein Cleanup-Ticket mit Eigentümer und Datum. Halte eine kleine "compatibility debt"-Notiz in den Release-Docs, damit es sichtbar bleibt.
Wenn du mit AppMaster baust, kannst du Regenerierung als Teil des Sicherheitsprozesses nutzen: Modelliere das additive Schema, aktualisiere die Business-Logik so, dass sie während der Transition alte und neue Felder unterstützt, und regeneriere, damit der Quellcode sauber bleibt, während sich Anforderungen ändern. Wenn du sehen willst, wie dieser Workflow in ein No-Code-Setup passt, das trotzdem echten Source-Code erzeugt, ist AppMaster (appmaster.io) um diesen Stil iterativer, phasenweiser Auslieferung herum gestaltet.
Das Ziel ist nicht Perfektion. Es ist Wiederholbarkeit: Jede Migration hat einen Plan, eine Messung und eine Ausstiegsrampe.
Zero-Downtime bedeutet, dass Benutzer während der Schemaänderung und dem Deployment normal weiterarbeiten können. Das umfasst das Vermeiden offensichtlicher Ausfälle, aber auch stille Fehler wie leere Bildschirme, falsche Werte, Abstürze von Jobs oder Schreibsperren durch lange Migrationen.
Weil viele Teile des Systems von der Datenbankstruktur abhängen, nicht nur die Hauptoberfläche. Hintergrundjobs, Reports, Admin-Skripte, Integrationen und ältere mobile Apps können weiterhin alte Felder erwarten oder senden, selbst wenn die Migration technisch durchgelaufen ist.
Ältere Mobile-Builds können Wochen lang im Einsatz bleiben und manche Clients senden alte Anfragen später erneut. Deine API muss für eine Weile sowohl alte als auch neue Payloads akzeptieren, damit gemischte Versionen ohne Fehler koexistieren können.
Additive Änderungen sind am sichersten, weil das alte Schema weiter existiert und vorhandener Code meist unverändert arbeitet. Umbenennungen und Löschungen sind riskant, weil sie Dinge entfernen, die ältere Clients weiterhin nutzen.
Füge die Spalte zunächst als nullable hinzu, damit alter Code weiter Zeilen einfügen kann. Backfille bestehende Zeilen in Batches und setze NOT NULL erst durch, wenn die Abdeckung hoch und neue Writes konsistent sind.
Behandle es als Rollout: Schema kompatibel hinzufügen, Code deployen, der beide Formen versteht, in kleinen Batches backfillen, Reads mit Fallback umstellen und das alte Feld erst entfernen, wenn du beweisen kannst, dass es nicht mehr genutzt wird. Jeder Schritt sollte für sich sicher sein.
Führe es in kleinen Batches mit kurzen Transaktionen aus, damit Tabellen nicht gesperrt werden und die Last nicht spike't. Mach das Job restartbar und idempotent, etwa durch Updates nur dort, wo new_field IS NULL, und protokolliere den Fortschritt.
Mache neue Felder zuerst optional und setze Server-seitige Defaults, wenn sie fehlen. Bewahre altes Verhalten, vermeide das Umdefinieren bestehender Felder und teste beide Pfade: „neuer Client sendet“ und „alter Client sendet nicht“.
Meistens rollst du die Anwendung zurück, nicht das Schema. Behalte additive Spalten/Tabellen, deaktiviere neue Reads zuerst, dann neue Writes, und pausiere Backfills, bis die Metriken stabil sind. So stellst du eine schnelle Erholung ohne Datenverlust sicher.
Beobachte Nutzer-bezogene Signale: Fehlerraten (4xx/5xx), langsame Queries (p95/p99), Schreiblatenz, Queue-Tiefe und CPU/IO der Datenbank. Wechsle nur bei stabilen Metriken und hoher Abdeckung für das neue Feld zur nächsten Phase.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


