Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Erfahren Sie, wie Sie Webhook‑Integrationen debuggen: Signaturen standardisieren, Wiederholungen sicher behandeln, Replay ermöglichen und durchsuchbare Ereignisprotokolle führen.
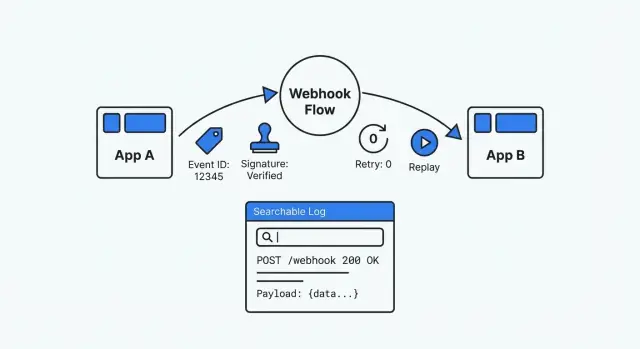
Ein Webhook ist im Grunde nur eine App, die Ihre App anruft, wenn etwas passiert. Ein Zahlungsanbieter meldet „Zahlung erfolgreich“, ein Formular‑Tool sagt „neue Einsendung“ oder ein CRM meldet „Deal aktualisiert“. Das klingt einfach — bis etwas schiefgeht und Sie merken, dass es keinen Bildschirm zum Öffnen, keine offensichtliche Historie und keine sichere Möglichkeit gibt, das Geschehene erneut abzuspielen.
Deshalb sind Webhook‑Probleme so frustrierend. Die Anfrage kommt an (oder auch nicht). Ihr System verarbeitet sie (oder scheitert). Das erste Signal ist oft ein vager Support‑Fall wie „Kunden können nicht bezahlen“ oder „der Status hat sich nicht aktualisiert“. Wenn der Provider erneut sendet, bekommen Sie möglicherweise Duplikate. Ändert sich ein Payload‑Feld, kann Ihr Parser für nur einige Accounts fehlschlagen.
Häufige Symptome:
Eine gut debuggbare Webhook‑Einrichtung ist das Gegenteil von Raten: sie ist nachvollziehbar (Sie finden jede Zustellung und was damit geschah), wiederholbar (Sie können ein vergangenes Event sicher erneut abspielen) und verifizierbar (Sie können Echtheit und Verarbeitungsergebnisse nachweisen). Wenn jemand fragt: „Was ist mit diesem Event passiert?“, sollten Sie innerhalb von Minuten mit Belegen antworten können.
Wenn Sie Apps auf einer Plattform wie AppMaster bauen, ist diese Denkweise noch wichtiger. Visuelle Logik ändert sich schnell, aber Sie brauchen trotzdem eine klare Ereignishistorie und ein sicheres Replay, damit externe Systeme niemals zur Blackbox werden.
Wenn Sie unter Druck debuggen, brauchen Sie jedes Mal die gleichen Grundlagen: ein vertrauenswürdiges, durchsuchbares und wiederabspielbares Protokoll. Ohne das wird jeder Webhook zu einem Einzelrätsel.
Definieren Sie, was ein einzelnes Webhook‑„Event“ in Ihrem System bedeutet. Behandeln Sie es wie eine Quittung: eine eingehende Anfrage = ein gespeichertetes Event, auch wenn die Verarbeitung später stattfindet.
Speichern Sie mindestens:
received_at getrennt von Zeitstempeln im Payload auf.Beispiel: Ein Zahlungsanbieter sendet „payment_succeeded“, aber Ihr Kunde wird noch als unbezahlte Position angezeigt. Wenn Ihr Ereignisprotokoll die Roh‑Anfrage enthält, können Sie die Signatur bestätigen und den genauen Betrag und die Währung sehen. Wenn außerdem die invoice_id enthalten ist, kann der Support das Event über die Rechnung finden, sehen, dass es im Status „failed“ steckt, und Engineering einen klaren Fehlergrund liefern.
In AppMaster ist ein praktischer Ansatz eine Tabelle „WebhookEvent“ im Data Designer, mit einem Business Process, der den Status bei jedem abgeschlossenen Schritt aktualisiert. Das Tool ist nicht der Punkt — die konsistente Aufzeichnung ist es.
Wenn jeder Provider eine andere Payload‑Form schickt, werden Ihre Logs immer unordentlich wirken. Eine stabile Event‑„Hülle“ macht das Debuggen schneller, weil Sie immer nach denselben Feldern suchen können, selbst wenn sich die Daten ändern.
Eine nützliche Hülle enthält typischerweise:
id (eindeutige Event‑ID)type (klarer Event‑Name wie invoice.paid)created_at (wann das Event passiert ist, nicht wann Sie es erhalten haben)data (der Business‑Payload)version (z. B. v1)Hier ein einfaches Beispiel, das Sie protokollieren und so speichern können:
{
"id": "evt_01H...",
"type": "payment.failed",
"created_at": "2026-01-25T10:12:30Z",
"version": "v1",
"correlation": {"order_id": "A-10492", "customer_id": "C-883"},
"data": {"amount": 4990, "currency": "USD", "reason": "insufficient_funds"}
}
Wählen Sie einen Namensstil (snake_case oder camelCase) und bleiben Sie dabei. Seien Sie strikt bei Typen: machen Sie amount nicht manchmal zu einem String und manchmal zu einer Zahl.
Versionierung ist Ihr Sicherheitsnetz. Wenn Sie Felder ändern müssen, veröffentlichen Sie v2, während v1 weiterhin eine Zeit lang funktioniert. Das vermeidet Support‑Vorfälle und macht Upgrades leichter zu debuggen.
Signaturen verhindern, dass Ihr Webhook‑Endpoint zur offenen Tür wird. Ohne Verifikation kann jeder, der Ihre URL kennt, gefälschte Events senden, und Angreifer können versuchen, echte Requests zu manipulieren.
Das gebräuchlichste Muster ist eine HMAC‑Signatur mit einem geteilten Secret. Der Sender signiert den rohen Request‑Body (am besten) oder einen kanonischen String. Sie berechnen die HMAC neu und vergleichen. Viele Provider beinhalten einen Zeitstempel in dem, was sie signieren, damit abgefangene Requests später nicht erneut abgespielt werden können.
Eine Verifikationsroutine sollte langweilig und konsistent sein:
Machen Sie es testbar. Legen Sie die Verifikation in eine kleine Funktion und schreiben Sie Tests mit bekannten guten und schlechten Beispielen. Ein häufiger Zeitfresser ist, geparstes JSON statt roher Bytes zu signieren.
Planen Sie Secret‑Rotation von Tag eins an. Unterstützen Sie zwei aktive Secrets während der Übergangszeit: versuchen Sie zuerst das neueste, dann das vorherige.
Wenn die Verifikation fehlschlägt, protokollieren Sie genug, um zu debuggen, ohne Secrets zu leaken: Provider‑Name, Zeitstempel (und ob er zu alt war), Signatur‑Version, Request/Korrelations‑ID und einen kurzen Hash des rohen Bodys (nicht den Body selbst).
Retries sind normal. Provider wiederholen bei Timeouts, Netzwerkproblemen oder 5xx‑Antworten. Selbst wenn Ihr System die Arbeit gemacht hat, hat der Provider Ihre Bestätigung möglicherweise nicht erhalten, sodass dasselbe Event erneut ankommen kann.
Legen Sie im Voraus fest, welche Antworten „retry“ vs. „stop“ bedeuten. Viele Teams verwenden Regeln wie:
Idempotenz bedeutet, dass Sie dasselbe Event mehrfach verarbeiten können, ohne Nebenwirkungen zu wiederholen (nicht doppelt belasten, keine doppelten Bestellungen, keine doppelten E‑Mails). Behandeln Sie Webhooks als mindestens‑einmal‑Zustellung.
Ein praktisches Muster ist, die eindeutige ID jedes eingehenden Events zusammen mit dem Ergebnis der Verarbeitung zu speichern. Bei erneutem Eintreffen:
Für interne Wiederholungen verwenden Sie Exponential‑Backoff und begrenzen die Versuche. Nach dem Limit verschieben Sie das Event in den Zustand „needs review“ mit dem letzten Fehler. In AppMaster lässt sich das sauber auf eine kleine Tabelle für Event‑IDs und Stati abbilden, plus einem Business Process, der Wiederholungen plant und wiederholte Fehler weiterleitet.
Retries sind automatisch. Replay ist intentional.
Ein Replay‑Tool verwandelt „wir denken, es wurde gesendet“ in einen wiederholbaren Test mit exakt demselben Payload. Es ist nur sicher, wenn zwei Dinge wahr sind: Idempotenz und eine Audit‑Spur. Idempotenz verhindert Doppelladungen, Doppelversand oder Doppel‑E‑Mails. Die Audit‑Spur zeigt, was wiederholt wurde, von wem und was dabei passierte.
Einzel‑Event‑Replay ist der häufige Support‑Fall: ein Kunde, ein fehlgeschlagenes Event, erneut zustellen nach einer Fehlerbehebung. Zeitbereichs‑Replay ist für Vorfälle: ein Provider‑Ausfall in einem bestimmten Fenster und Sie müssen alles nachsenden, was fehlgeschlagen ist.
Halten Sie die Auswahl einfach: filtern Sie nach Event‑Typ, Zeitraum und Status (failed, timed out oder delivered but unacknowledged) und spielen Sie ein Event oder ein Batch erneut ab.
Replay sollte mächtig, aber nicht gefährlich sein. Einige Guardrails helfen:
Nach dem Replay zeigen Sie die Ergebnisse neben dem Original‑Event: Erfolg, weiterhin fehlerhaft (mit dem neuesten Fehler) oder ignoriert (Duplikat erkannt durch Idempotenz).
Wenn ein Webhook während eines Vorfalls ausfällt, brauchen Sie binnen Minuten Antworten. Ein gutes Log erzählt eine klare Geschichte: was angekommen ist, was Sie damit gemacht haben und wo es steckenblieb.
Speichern Sie den Roh‑Request genau so, wie er ankam: Zeitstempel, Pfad, Methode, Header und roher Body. Dieser Roh‑Payload ist Ihre Ground‑Truth, wenn Anbieter Felder ändern oder Ihr Parser Daten falsch interpretiert. Maskieren Sie sensible Werte, bevor Sie sie speichern (Authorization‑Header, Tokens und personenbezogene oder Zahlungsdaten, die Sie nicht benötigen).
Rohdaten allein reichen nicht. Speichern Sie zusätzlich eine geparste, durchsuchbare Ansicht: Event‑Typ, externe Event‑ID, Kunden/Account‑Identifier, verwandte Objekt‑IDs (invoice_id, order_id) und Ihre interne Korrelations‑ID. Damit kann Support „alle Events für Kunde 8142“ finden, ohne jeden Payload zu öffnen.
Während der Verarbeitung halten Sie eine kurze Schritt‑Timeline mit konsistenter Formulierung, z. B.: „validated signature“, „mapped fields“, „checked idempotency“, „updated records“, „queued follow-ups".
Retention ist wichtig. Bewahren Sie ausreichend Historie für echte Verzögerungen und Streitfälle auf, aber horten Sie nicht unbegrenzt. Erwägen Sie, Roh‑Payloads zuerst zu löschen oder zu anonymisieren und leichte Metadaten länger aufzubewahren.
Bauen Sie den Receiver wie eine kleine Pipeline mit klaren Checkpoints. Jede Anfrage wird zu einem gespeicherten Event, jeder Verarbeitungsdurchlauf zu einem Attempt und jeder Fehler wird durchsuchbar.
Behandeln Sie das HTTP‑Endpoint nur als Intake. Machen Sie vor Ort nur das Nötigste und verschieben Sie die Verarbeitung an einen Worker, damit Timeouts nicht zu mysteriösem Verhalten führen.
In der Praxis möchten Sie zwei Kerndatensätze: eine Zeile pro Webhook‑Event und eine Zeile pro Verarbeitungsversuch.
Ein solides Event‑Modell enthält: event_id, provider, received_at, signature_status, payload_hash, payload_json (oder raw payload), current_status, last_error, next_retry_at. Attempt‑Records können speichern: attempt_number, started_at, finished_at, http_status (falls zutreffend), error_code, error_text.
Sobald die Daten existieren, fügen Sie eine kleine Admin‑Seite hinzu, damit Support nach event ID, customer ID oder Zeitbereich suchen und nach Status filtern kann. Halten Sie es langweilig und schnell.
Setzen Sie Alerts auf Muster, nicht auf Einzel‑Fehler. Zum Beispiel: „Provider failed 10 times in 5 minutes“ oder „Event stuck in failed".
Wenn Sie die Senderseite kontrollieren, standardisieren Sie drei Dinge: immer eine Event‑ID mitsenden, die Payload immer auf dieselbe Weise signieren und eine Retry‑Policy in klarer Sprache veröffentlichen. Das verhindert endlose Rückfragen, wenn ein Partner sagt „wir haben gesendet“ und Ihr System nichts zeigt.
Ein gängiges Muster ist ein Stripe‑Webhook, der zwei Dinge tut: ein Order‑Record anlegt und danach eine Quittung per E‑Mail/SMS versendet. Klingt simpel, bis ein Event fehlschlägt und niemand weiß, ob der Kunde belastet, die Bestellung angelegt oder die Quittung verschickt wurde.
Ein realistisches Problem: Sie rotieren Ihr Stripe‑Signing‑Secret. Für ein paar Minuten verifiziert Ihr Endpoint noch mit dem alten Secret, so dass Stripe Events zustellt, Ihr Server sie aber mit 401/400 ablehnt. Das Dashboard zeigt „webhook failed“, während Ihre App‑Logs nur „invalid signature“ melden.
Gute Logs machen die Ursache offensichtlich. Für das fehlgeschlagene Event sollte der Datensatz eine stabile Event‑ID und genug Verifikationsdetails zeigen, um die Diskrepanz zu lokalisieren: Signatur‑Version, Signatur‑Zeitstempel, Verifikationsergebnis und ein klarer Reject‑Grund (falsches Secret vs. Zeitversatz). Während der Rotation hilft es auch zu protokollieren, welches Secret versucht wurde (z. B. „current“ vs. „previous“), nicht das rohe Secret.
Sobald das Secret korrigiert ist und sowohl „current“ als auch „previous“ für ein kurzes Fenster akzeptiert werden, müssen Sie den Rückstau bearbeiten. Ein Replay‑Tool macht daraus eine kurze Aufgabe:
Die meisten Webhook‑Probleme wirken mysteriös, weil Systeme nur den finalen Fehler aufzeichnen. Behandeln Sie jede Zustellung wie einen kleinen Incident‑Report: was angekommen ist, was Sie entschieden haben und was dann geschah.
Einige wiederkehrende Fehler sind:
Praktische Maßnahmen:
Wenn Sie AppMaster verwenden, fügen sich diese Teile natürlich in die Plattform: eine Event‑Tabelle im Data Designer, ein statusgesteuerter Business Process für Verifikation und Verarbeitung und ein Admin‑UI für Suche und Replay.
Zielen Sie auf dieselben Grundlagen bei jeder Integration:
Fehlt nur eines davon, kann eine Integration noch immer zur Blackbox werden. Wenn Sie den rohen Payload nicht speichern, können Sie nicht beweisen, was der Provider gesendet hat. Wenn Signaturfehler nicht spezifisch sind, verschwenden Sie Stunden damit, darüber zu streiten, wessen Fehler es ist.
Wenn Sie das schnell aufbauen möchten, ohne jede Komponente von Hand zu coden, kann AppMaster (appmaster.io) Ihnen helfen, das Datenmodell, Verarbeitungsabläufe und das Admin‑UI an einem Ort zusammenzustellen, während trotzdem echter Quellcode für die finale App generiert wird.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


