Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Soft Delete vs Hard Delete: Lerne, wie du Historie bewahrst, gebrochene Referenzen vermeidest und gleichzeitig Datenschutzanforderungen erfüllst — mit klaren Regeln.
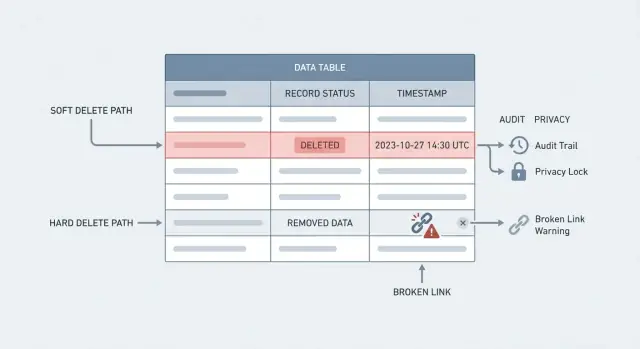
„Löschen“ kann zwei sehr unterschiedliche Dinge bedeuten. Sie zu verwechseln ist die Ursache dafür, dass Teams Historie verlieren oder Datenschutzanfragen nicht erfüllen.
Ein Hard Delete ist das, was die meisten meinen: die Zeile wird aus der Datenbank entfernt. Fragt man später danach, ist sie weg. Das ist echte Entfernung, kann aber Referenzen kaputtmachen (zum Beispiel eine Bestellung, die auf einen gelöschten Kunden zeigt), sofern man das nicht berücksichtigt.
Ein Soft Delete behält die Zeile, markiert sie aber als gelöscht, meist mit einem Feld wie deleted_at oder is_deleted. Die App behandelt sie wie verschwunden, aber die Daten sind für Reports, Support und Prüfungen weiterhin vorhanden.
Der Kompromiss bei Soft Delete vs Hard Delete ist einfach: Historie vs echte Entfernung. Soft Delete schützt die Historie und macht ein „Rückgängig“ möglich. Hard Delete reduziert, was du speicherst, was für Datenschutz, Sicherheit und rechtliche Vorgaben wichtig ist.
Löschungen betreffen mehr als nur Speicherplatz. Sie verändern, was dein Team später beantworten kann: ein Support‑Agent, der eine frühere Beschwerde nachvollziehen will, die Finanzabteilung, die Abrechnungen abgleicht, oder Compliance, die prüfen will, wer wann was geändert hat. Verschwinden Daten zu früh, verändern sich Reports, Summen passen nicht mehr und Untersuchungen werden zur Ratesache.
Ein nützliches Denkmodell:
In der Praxis könntest du ein Benutzerkonto soft löschen, damit kein Login mehr möglich ist und die Bestellhistorie intakt bleibt, und personenbezogene Felder nach einer Aufbewahrungsfrist oder nach einem verifizierten GDPR‑Recht auf Löschung hart löschen oder anonymisieren.
Kein Tool trifft diese Entscheidung für dich. Selbst wenn du mit einer No‑Code‑Plattform wie AppMaster arbeitest, besteht die eigentliche Arbeit darin, pro Tabelle zu definieren, was „gelöscht“ bedeutet, und sicherzustellen, dass jede Ansicht, jeder Report und jede API dieselbe Regel befolgt.
Die meisten Teams merken Löschungen erst, wenn etwas schiefgeht. Ein „einfaches“ Löschen kann Kontext, Historie und die Fähigkeit, Abläufe zu erklären, auslöschen.
Hard Deletes sind riskant, weil sie sich kaum rückgängig machen lassen. Jemand klickt die falsche Schaltfläche, ein automatischer Job hat einen Fehler oder ein Support‑Agent folgt dem falschen Ablauf. Ohne saubere Backups und einen klaren Wiederherstellungsprozess ist der Verlust dauerhaft und der Geschäftseinfluss zeigt sich schnell.
Gebrochene Referenzen sind die nächste Überraschung. Du löschst einen Kunden, seine Bestellungen existieren aber weiter. Nun zeigen Bestellungen auf nichts, Rechnungen können keinen Abrechnungsnamen anzeigen und ein Portal wirft Fehler beim Laden verwandter Daten. Selbst mit Fremdschlüssel‑Constraints kann die „Lösung“ schlimmer sein: Kaskadierende Löschungen können weit mehr entfernen, als du beabsichtigt hast.
Analytics und Reporting werden ebenfalls unordentlich. Wenn alte Datensätze verschwinden, ändern sich Metriken rückwirkend. Die Conversion‑Rate vom letzten Monat verschiebt sich, der Customer‑Lifetime‑Value sinkt und Trendlinien haben Lücken, die niemand erklären kann. Das Team streitet über Zahlen statt Entscheidungen zu treffen.
Support und Compliance sind die wirkliche Schmerzstelle. Kunden fragen: „Warum wurde mir etwas berechnet?“ oder „Wer hat meinen Plan geändert?“ Ist der Datensatz weg, kannst du keine Zeitleiste rekonstruieren. Der Audit‑Trail, der einfache Fragen wie wer, wann und was beantworten würde, fehlt.
Gängige Fehlerquellen im Soft Delete vs Hard Delete‑Konflikt:
Soft Delete ist meist die sicherere Wahl, wenn ein Datensatz langfristigen Wert hat oder mit anderen Daten verknüpft ist. Anstatt eine Zeile zu entfernen, markierst du sie als gelöscht (z. B. deleted_at oder is_deleted) und blendest sie in normalen Ansichten aus. In der Entscheidung Soft Delete vs Hard Delete reduziert diese Grundeinstellung Überraschungen später.
Es ist besonders sinnvoll, wenn du einen Audit Trail in Datenbanken brauchst. Operative Teams müssen oft einfache Fragen beantworten wie „Wer hat diese Bestellung geändert?“ oder „Warum wurde diese Rechnung storniert?“ Löscht du zu früh hart, verlierst du Beweismittel, die für Finanzen, Support und Compliance wichtig sind.
Soft Delete macht außerdem ein Wiederherstellen möglich. Admins können ein irrtümlich geschlossenes Ticket zurückbringen, ein archiviertes Produkt wieder aktivieren oder Inhalte wiederherstellen, die fälschlich als Spam markiert wurden. Solche Wiederherstellungsabläufe sind schwer zu bieten, wenn die Daten physisch weg sind.
Beziehungen sind ein weiterer großer Grund. Hartes Löschen eines Eltern‑Datensatzes kann Fremdschlüssel verletzen oder verwirrende Lücken in Reports hinterlassen. Mit Soft Delete bleiben Joins stabil und historische Summen konsistent (tägliche Einnahmen, erfüllte Bestellungen, Antwortzeit‑Statistiken).
Soft Delete ist ein starker Standard für Geschäftsdatensätze wie Support‑Tickets, Nachrichten, Bestellungen, Rechnungen, Audit‑Logs, Aktivitätshistorie und Benutzerprofile (zumindest bis zur endgültigen Löschung).
Beispiel: Ein Support‑Agent „löscht“ eine Bestellnotiz mit einem Fehler. Mit Soft Delete verschwindet die Notiz aus der normalen UI, aber Vorgesetzte können sie bei einer Beschwerde noch prüfen, und Finanzreports bleiben erklärbar.
Soft Delete ist oft die richtige Default‑Wahl, aber es gibt Zeiten, in denen das Aufbewahren (auch verborgen) die falsche Entscheidung ist. Hard Delete bedeutet echte Entfernung des Datensatzes und ist manchmal die einzige Option, die rechtlich, sicherheits‑ oder kostenbedingt passt.
Der klarste Fall sind Datenschutz‑ und vertragliche Verpflichtungen. Wenn eine Person das GDPR‑Recht auf Löschung geltend macht oder dein Vertrag Löschung nach einer Frist verspricht, zählt „markiert als gelöscht“ oft nicht. Du musst möglicherweise die Zeile, Kopien und gespeicherte Kennungen entfernen, die auf die Person zurückführen.
Sicherheit ist ein weiterer Grund. Manche Daten sind zu sensibel, um sie zu behalten: rohe Zugriffstokens, Passwort‑Reset‑Codes, private Schlüssel, Einmalcodes oder unverschlüsselte Secrets. Diese für die Historie zu behalten, ist selten das Risiko wert.
Hard Delete kann auch aus Skalierungsgründen richtig sein. Hast du riesige Tabellen mit alten Events, Logs oder Telemetrie, dann wächst die Datenbank bei Soft Delete unbemerkt weiter und verlangsamt Abfragen. Eine geplante Bereinigung hält das System performant und die Kosten vorhersehbar.
Hard Delete ist oft passend für temporäre Daten (Caches, Sessions, Draft‑Imports), kurzlebige Sicherheitsartefakte (Reset‑Tokens, OTPs, Einladungscodes), Test/Demo‑Accounts und große historische Datensätze, bei denen nur aggregierte Statistiken benötigt werden.
Eine praktische Herangehensweise ist, „Geschäftshistorie“ von „personenbezogenen Daten“ zu trennen. Behalte z. B. Rechnungen für die Buchhaltung, lösche oder anonymisiere aber die Benutzerprofilfelder, die eine Person identifizieren.
Wenn dein Team über Soft Delete vs Hard Delete diskutiert, nutze einen einfachen Test: schafft das Beibehalten der Daten ein rechtliches oder sicherheitsrelevantes Risiko, sollte Hard Delete (oder irreversible Anonymisierung) gewinnen.
Soft Delete funktioniert am besten, wenn es langweilig und vorhersehbar ist. Das Ziel ist einfach: der Datensatz bleibt in der DB, aber normale Teile der App verhalten sich so, als wäre er weg.
Du siehst drei gängige Muster: einen deleted_at‑Timestamp, ein is_deleted‑Flag oder ein Status‑Enum. Viele Teams bevorzugen deleted_at, weil es zwei Fragen auf einmal beantwortet: ist es gelöscht und wann geschah das.
Wenn du bereits mehrere Lifecycle‑Zustände hast (active, pending, suspended), kann ein Status‑Enum weiterhin funktionieren, aber halte „deleted“ getrennt von „archived“ und „deactivated“. Das sind verschiedene Dinge:
Soft Delete vs Hard Delete scheitert oft an einzigartigen Feldern wie E‑Mail, Benutzername oder Bestellnummer. Ist ein Nutzer „gelöscht“, aber seine E‑Mail noch gespeichert und eindeutig, kann sich dieselbe Person nicht neu registrieren.
Zwei übliche Lösungen: Entweder gilt die Einzigartigkeit nur für nicht‑gelöschte Zeilen, oder der Wert wird beim Löschen umgeschrieben (z. B. mit einem zufälligen Suffix). Welche Variante du wählst, hängt von Datenschutz‑ und Auditbedürfnissen ab.
Entscheide, welche Zielgruppen was sehen können. Eine gängige Regel ist: reguläre Nutzer sehen nie gelöschte Datensätze, Support/Admins können sie mit klarer Kennzeichnung sehen, und Exporte/Reports enthalten sie nur auf Anforderung.
Verlass dich nicht darauf, dass „alle daran denken, den Filter hinzuzufügen“. Lege die Regel an einer Stelle fest: in Views, Standardabfragen oder in deiner Data Access Layer. Wenn du in AppMaster baust, bedeutet das meist, den Filter in die Art zu integrieren, wie Endpunkte und Business Processes Daten abfragen, damit gelöschte Zeilen nicht versehentlich in einem neuen Screen erscheinen.
Schreibe die Bedeutungen in einer kurzen internen Notiz (oder Schema‑Kommentaren) fest. Dein zukünftiges Ich wird es danken, wenn „deleted“, „archived“ und „deactivated“ im selben Meeting auftauchen.
Löschungen brechen Apps am häufigsten über Beziehungen. Ein Datensatz steht selten allein: Nutzer haben Bestellungen, Tickets haben Kommentare, Projekte haben Dateien. Die Herausforderung bei Soft Delete vs Hard Delete ist, Referenzen konsistent zu halten und gleichzeitig das Produkt so zu gestalten, dass ein Element als „weg“ erscheint.
Fremdschlüssel schützen vor gebrochenen Referenzen, aber jede Option hat eine andere Bedeutung:
Wenn du Soft Delete verwendest, ist RESTRICT oft der sicherste Default. Die Zeile bleibt, Keys bleiben gültig und du vermeidest, dass Kinder auf nichts zeigen.
Bei Soft Delete änderst du in der Regel nicht die Fremdschlüssel. Stattdessen filterst du gelöschte Eltern in der App und in Reports heraus. Ist ein Kunde soft‑gelöscht, sollten seine Rechnungen weiterhin korrekt joinen, aber in Dropdowns oder Auswahllisten nicht angezeigt werden.
Bei Attachments, Kommentaren und Aktivitätslogs entscheide, was "Löschen" für den Nutzer bedeutet. Manche Teams behalten die Hülle, entfernen aber risikobehaftete Teile: ersetze Inhalt von Attachments durch Platzhalter, wenn Datenschutz es verlangt, markiere Kommentare als von einem gelöschten Nutzer (oder anonymisiere den Autor) und behalte Aktivitätslogs unveränderlich.
Joins und Reporting brauchen eine klare Regel: sollen gelöschte Zeilen einbezogen werden? Viele Teams pflegen zwei Standardabfragen: eine „nur aktiv“ und eine „inklusive gelöschter“, damit Support und Reporting nicht versehentlich wichtige Historie verbergen.
Eine praktische Policy nutzt oft Soft Delete für Alltagsfehler und Hard Delete für rechtliche oder datenschutz‑bedingte Anforderungen. Wenn du es als reine Entscheidung (Soft Delete vs Hard Delete) behandelst, verpasst du die Mitte: Historie eine Zeit lang behalten, dann das entfernen, was wegmuss.
Sortiere Daten in Gruppen. "Benutzerprofil" ist persönlich, "Transaktionen" sind finanzielle Aufzeichnungen, und "Logs" sind Systemhistorie. Jede Gruppe braucht eigene Regeln.
Ein kurzer Plan, der für die meisten Teams funktioniert:
Ein Kunde bittet um Schließung seines Kontos. Soft Delete die Nutzerzeile sofort, damit kein Login mehr möglich ist und du Referenzen nicht brichst. Anonymisiere danach personenbezogene Felder (Name, E‑Mail, Telefon), während nicht personenbezogene Transaktionsdaten für die Buchhaltung erhalten bleiben. Schließlich entfernt ein geplanter Purge‑Job alles, was nach der Frist noch personenbezogen ist.
Teams geraten nicht deswegen in Schwierigkeiten, weil sie die falsche Methode wählen, sondern weil sie sie uneinheitlich anwenden. Ein typisches Muster ist: „Soft Delete vs Hard Delete“ auf dem Papier, aber „in einer Ansicht verbergen und den Rest vergessen“ in der Praxis.
Ein häufiger Fehler: du blendest gelöschte Datensätze in der UI aus, aber sie erscheinen weiterhin über die API, CSV‑Exporte, Admin‑Tools oder Datensynchronisierungen. Nutzer merken schnell, wenn ein „gelöschter“ Kunde in einer E‑Mail‑Liste oder einer mobilen Suche auftaucht.
Reports und Suche sind eine weitere Falle. Wenn Report‑Abfragen gelöschte Zeilen nicht konsequent filtern, driftet die Statistik und Dashboards verlieren Vertrauen. Am schlimmsten sind Hintergrundjobs, die gelöschte Items erneut indexieren oder versenden, weil sie dieselben Regeln nicht angewendet haben.
Hard Deletes können auch zu weit gehen. Eine einzelne kaskadierende Löschung kann Bestellungen, Rechnungen, Nachrichten und Logs entfernen, die du für ein Audit eigentlich brauchst. Wenn du hart löschen musst, sei explizit darin, was verschwinden darf und was erhalten oder anonymisiert werden muss.
Eindeutigkeitsbeschränkungen verursachen subtile Probleme bei Soft Delete. Löscht ein Nutzer sein Konto und versucht sich mit derselben E‑Mail neu anzumelden, kann die Anmeldung fehlschlagen, wenn die alte Zeile die eindeutige E‑Mail hält. Plane das frühzeitig ein.
Compliance‑Teams fragen: kannst du beweisen, dass die Löschung passiert ist, und wann? „Wir glauben, es wurde gelöscht“ reicht in vielen Reviews nicht. Halte einen Löschzeitstempel, wer/es ausgelöst hat, und einen unveränderbaren Log‑Eintrag bereit.
Vor dem Rollout: prüfe die gesamte Oberfläche: API, Exporte, Suche, Reports und Hintergrundjobs. Überprüfe Kaskaden Tabelle für Tabelle und bestätige, dass Nutzer eindeutige Daten wie E‑Mail oder Benutzername wieder anlegen können, wenn das Teil deines Produktversprechens ist.
Bevor du dich für Soft Delete vs Hard Delete entscheidest, verifiziere das echte Verhalten deiner App, nicht nur das Schema.
Teste dann den Datenschutzpfad Ende‑zu‑Ende. Kannst du ein GDPR‑Recht auf Löschung über Kopien, Exporte, Suchindizes, Analytics‑Tabellen und Integrationen hinweg erfüllen, nicht nur in der Hauptdatenbank?
Eine praktische Validierung ist ein Einzeldurchlauf „Benutzer löschen“ in Staging, bei dem du der Datenbahn folgst.
Ein Kunde schreibt: „Bitte löschen Sie mein Konto.“ Gleichzeitig musst du Rechnungen für die Buchhaltung und Rückbuchungsprüfungen behalten. Hier wird Soft Delete vs Hard Delete praktisch: Entferne Zugang und personenbezogene Details, behalte aber Geschäftsdaten, die das Unternehmen aufbewahren muss.
Trenne „das Konto“ von „dem Abrechnungsdatensatz“. Das Konto betrifft Login und Identität. Der Abrechnungsdatensatz betrifft eine bereits erfolgte Transaktion.
Ein sauberer Ansatz:
Support‑Tickets und Nachrichten liegen oft dazwischen. Enthalten Nachrichten personenbezogene Daten, musst du möglicherweise Teile des Texts schwärzen, Anhänge entfernen und die Ticket‑Hülle (Zeitstempel, Kategorie, Ergebnis) für Qualitätszwecke behalten. Wenn dein Produkt Nachrichten versendet (E‑Mail/SMS, Telegram), entferne auch ausgehende Kennungen, damit die Person nicht erneut kontaktiert wird.
Was darf Support noch sehen? Meist Rechnungsnummern, Daten, Beträge, Status und einen Hinweis, dass der Nutzer gelöscht wurde und wann. Nicht sichtbar sein dürfen identifizierende Informationen wie Login‑E‑Mail, vollständiger Name, Adressen, gespeicherte Zahlungsdaten oder aktive Sessions.
Löschentscheidungen halten nur, wenn sie schriftlich festgelegt und einheitlich in der Produktumsetzung verankert sind. Behandle Soft Delete vs Hard Delete zuerst als Policy‑Frage, nicht als reines Coding‑Problem.
Beginne mit einer einfachen Datenaufbewahrungsrichtlinie, die jeder im Team lesen kann. Sie sollte sagen, was du behältst, wie lange und warum. Das „Warum“ ist wichtig, weil es entscheidet, was gewinnt, wenn zwei Ziele kollidieren (z. B. Support‑Historie vs Datenschutzanfragen).
Ein guter Default ist oft: Soft Delete für alltägliche Geschäftsdaten (Bestellungen, Tickets, Projekte), Hard Delete für wirklich sensible Daten (Tokens, Secrets) und alles, was nicht aufbewahrt werden sollte.
Wenn die Policy klar ist, baue Flows, die sie durchsetzen: eine "Papierkorb"‑Ansicht zur Wiederherstellung, eine "Purge Queue" für irreversible Löschungen nach Prüfungen und eine Audit‑Ansicht, die zeigt, wer wann was getan hat. Mache "Purge" schwerer zugänglich als "Delete", damit es nicht aus Versehen verwendet wird.
Wenn du das in AppMaster (appmaster.io) umsetzt, hilft es, Soft‑Delete‑Felder im Data Designer zu modellieren und Lösch‑, Wiederherstellungs‑ und Bereinigungslogik zentral in einem Business Process zu halten, damit die Regeln in allen Bildschirmen und API‑Endpoints gleich angewendet werden.
Ein Hard Delete entfernt die Zeile physisch aus der Datenbank, sodass spätere Abfragen sie nicht mehr finden. Ein Soft Delete behält die Zeile, markiert sie aber als gelöscht (oft mit deleted_at), sodass die App sie in normalen Ansichten ausblendet, während die Historie für Support, Prüfungen und Reports erhalten bleibt.
Verwende Soft Delete standardmäßig für Geschäftsdaten, die später erklärt werden müssen, z. B. Bestellungen, Rechnungen, Tickets, Nachrichten und Kontoaktivitäten. Es reduziert versehentlichen Datenverlust, erhält Beziehungen und ermöglicht ein sicheres "Rückgängig" ohne Backup‑Wiederherstellung.
Hard Delete ist angebracht, wenn das Behalten der Daten ein Datenschutz‑ oder Sicherheitsrisiko schafft oder wenn Aufbewahrungsregeln echte Entfernung verlangen. Typische Beispiele sind Passwort‑Reset‑Tokens, Einmalcodes, Sessions, API‑Tokens und personenbezogene Daten, die nach einem verifizierten Löschersuchen entfernt werden müssen.
Ein deleted_at‑Timestamp ist üblich, weil er zwei Fragen in einem beantwortet: ist der Datensatz gelöscht und wann geschah das? Er unterstützt Aufbewahrungsfenster (z. B. Löschen nach 30 Tagen) und Audit‑Fragen („Wann wurde das entfernt?“), ohne ein eigenes Log für Zeitpunkte nötig zu machen.
Eindeutige Felder wie E‑Mail oder Benutzername blockieren oft die erneute Registrierung, wenn die gelöschte Zeile den Wert weiter enthält. Übliche Lösungen sind: Einzigartigkeit nur für nicht‑gelöschte Zeilen erzwingen oder den Wert beim Löschen umschreiben (z. B. mit einem zufälligen Suffix). Die Wahl hängt von Datenschutz‑ und Auditbedürfnissen ab.
Das harte Löschen eines Eltern‑Datensatzes kann Kinder verwaisen lassen (z. B. Bestellungen) oder Kaskaden auslösen, die weit mehr entfernen als beabsichtigt. Soft Delete vermeidet meist gebrochene Referenzen, weil Schlüssel gültig bleiben, aber du musst trotzdem konsistente Filterregeln sicherstellen, damit gelöschte Eltern nicht in Dropdowns oder nutzerorientierten Joins auftauchen.
Wenn historische Zeilen hart gelöscht werden, ändern sich vergangene Summen, Trends bekommen Lücken und Finanzzahlen stimmen nicht mehr mit früheren Ansichten überein. Soft Delete bewahrt die Historie, aber nur wenn Reports und Analytics klar definieren, ob gelöschte Zeilen einbezogen werden, und diese Regel überall konsequent angewendet wird.
„Soft deleted" reicht bei einem Recht auf Löschung (GDPR) oft nicht aus, weil personenbezogene Daten noch in der Datenbank oder Backups vorhanden sein können. Ein praktisches Muster ist: sofort Zugriff entziehen, dann personenbezogene Kennzeichen anonymisieren oder hart löschen, während nicht‑personenbezogene Transaktionsdaten für die Buchhaltung erhalten bleiben.
Wiederherstellung sollte den Datensatz in einen sicheren, gültigen Zustand zurückbringen, ohne sensible Elemente wiederherzustellen, die verschwinden sollten (z. B. Sessions oder Reset‑Tokens). Es braucht zudem klare Regeln für verbundene Daten, damit du nicht ein Konto wiederherstellst, dem dann notwendige Beziehungen oder Berechtigungen fehlen.
Zentralisiere Lösch-, Wiederherstellungs‑ und Bereinigungslogik, damit jede API, jeder Screen, Export und Hintergrundjob dieselben Filterregeln anwendet. In AppMaster (appmaster.io) bedeutet das meist, Soft‑Delete‑Felder im Data Designer anzulegen und die Logik einmal in einem Business Process zu implementieren, damit neue Endpunkte gelöschte Daten nicht versehentlich freigeben.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


