Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Erfahren Sie, wie Sie SLA-Timer und Eskalationen mit klaren Zuständen, wartbaren Regeln und einfachen Eskalationspfaden modellieren, damit Workflow-Apps leicht änderbar bleiben.
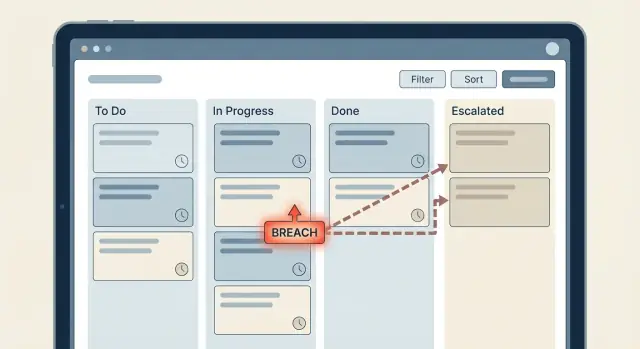
Zeitbasierte Regeln beginnen meist einfach: „Wenn ein Ticket 2 Stunden keine Antwort hat, benachrichtige jemanden.“ Dann wächst der Workflow, Teams fügen Ausnahmen hinzu, und plötzlich weiß niemand mehr genau, was passiert. So verwandeln sich SLA-Timer und Eskalationen in ein Labyrinth.
Es hilft, die beweglichen Teile klar zu benennen.
Ein Timer ist die Uhr, die Sie nach einem Ereignis starten (oder planen), zum Beispiel „Ticket auf Waiting for Agent gesetzt“. Eine Eskalation ist die Aktion, die ausgeführt wird, wenn diese Uhr eine Schwelle erreicht — etwa die Leitung informieren, Priorität ändern oder Arbeit neu zuweisen. Ein Breach ist die aufgezeichnete Tatsache „Wir haben das SLA verpasst“, die Sie für Reporting, Alerts und Nachverfolgung nutzen.
Probleme tauchen auf, wenn Zeitlogik in der App verteilt ist: ein paar Prüfungen im "Ticket aktualisieren"-Flow, weitere in einem Nachtjob und einmalige Regeln für spezielle Kunden. Jedes Stück macht für sich Sinn, aber zusammen erzeugen sie Überraschungen.
Typische Symptome:
Das Ziel ist vorhersehbares Verhalten, das sich später leicht anpassen lässt: eine klare einzige Quelle der Wahrheit für SLA-Timing, explizite Breach-Zustände, die Sie berichten können, und Eskalationsschritte, die Sie ändern, ohne in visuellen Logiken zu suchen.
Bevor Sie Timer bauen, schreiben Sie das genaue Versprechen auf, das Sie messen. Viel unordentliche Logik entsteht dadurch, dass man von Anfang an jede mögliche Zeitregel abdecken will.
Gängige SLA-Typen klingen ähnlich, messen aber unterschiedliche Dinge:
Entscheiden Sie als Nächstes, was „Zeit“ bedeutet. Kalenderzeit zählt 24/7. Arbeitszeit zählt nur definierte Geschäftszeiten (z. B. Mo–Fr, 9–18). Wenn Sie Arbeitszeit nicht wirklich brauchen, vermeiden Sie sie am Anfang. Sie bringt Edge-Cases wie Feiertage, Zeitzonen und Teiltag-Berechnungen mit sich.
Seien Sie anschließend konkret bei Pausen. Eine Pause ist nicht nur "Status geändert" — sie ist eine Regel mit einem Besitzer. Wer darf pausieren (nur Agent, nur System, Kundenaktion)? Welche Status pausieren (Waiting on Customer, On Hold, Pending Approval)? Was setzt die Uhr wieder frei? Setzt sie beim Fortsetzen an der verbleibenden Zeit fort oder startet der Timer neu?
Definieren Sie schließlich, was ein Breach in Produktbegriffen bedeutet. Ein Breach sollte etwas Konkretes sein, das Sie speichern und abfragen können, zum Beispiel:
breached_at)Beispiel: „First response SLA breached“ kann bedeuten, dass das Ticket einen Breached-Zustand bekommt, ein breached_at-Zeitstempel gesetzt wird und ein Eskalationslevel auf 1 gesetzt wird.
Wenn Sie SLA-Timer und Eskalationen lesbar halten wollen, behandeln Sie SLA wie eine kleine Zustandsmaschine. Wenn die „Wahrheit" über viele kleine Prüfungen verteilt ist (if now > due, if priority is high, if last_reply empty), wird visuelle Logik schnell unübersichtlich und kleine Änderungen brechen Dinge.
Beginnen Sie mit einer kurzen, abgestimmten Menge an SLA-Zuständen, die jeder Workflow-Schritt verstehen kann. Für viele Teams decken folgende Zustände die meisten Fälle ab:
Ein einzelnes breached = true/false-Flag reicht selten aus. Sie müssen wissen, welches SLA betroffen ist (first response vs resolution), ob es gerade pausiert ist und ob bereits eskaliert wurde. Ohne diesen Kontext fangen Menschen an, Bedeutungen aus Kommentaren, Zeitstempeln und Statusnamen herzuleiten — und das macht die Logik fragil.
Machen Sie den Zustand explizit und speichern Sie die Zeitstempel, die ihn erklären. Dann bleiben Entscheidungen einfach: Ihr Evaluator liest den Datensatz, setzt den nächsten Zustand, und alles andere reagiert auf diesen Zustand.
Nützliche Felder, die Sie neben dem Zustand speichern sollten:
started_at und due_at (welche Uhr läuft und wann ist die Frist?)breached_at (wann wurde die Grenze tatsächlich überschritten?)paused_at und paused_reason (warum stoppte die Uhr?)breach_reason (welche Regel den Verstoß ausgelöst hat, in Klartext)last_escalation_level (damit Sie dieselbe Stufe nicht zweimal benachrichtigen)Beispiel: Ein Ticket geht in "Waiting on customer". Setzen Sie den SLA-Zustand auf Paused, speichern Sie paused_reason = "waiting_on_customer" und stoppen Sie die Uhr. Wenn der Kunde antwortet, nehmen Sie die Pause zurück, indem Sie ein neues started_at setzen (oder unpausen und due_at neu berechnen). Kein Suchen in vielen Bedingungen.
Eine Eskalationsleiter ist ein klarer Plan dafür, was passiert, wenn ein SLA-Timer kurz vor dem Ablauf steht oder bereits überschritten ist. Ein häufiger Fehler ist, das Organigramm 1:1 in den Workflow zu kopieren. Sie wollen die kleinste Schrittfolge, die eine feststeckende Aufgabe wieder in Bewegung bringt.
Eine einfache Leiter, die viele Teams nutzen: Der zugewiesene Agent (Level 0) bekommt zuerst eine Erinnerung, dann die Teamleitung (Level 1), und erst danach geht es an einen Manager (Level 2). Das funktioniert, weil es bei der Person beginnt, die arbeiten kann, und Autorität nur bei Bedarf eskaliert.
Um Eskalationsregeln wartbar zu halten, speichern Sie Eskalationsschwellen als Daten, nicht als fest verdrahtete Bedingungen. Legen Sie sie in einer Tabelle oder einem Settings-Objekt ab: "erste Erinnerung nach 30 Minuten" oder "Eskalation an Lead nach 2 Stunden". Wenn sich Richtlinien ändern, aktualisieren Sie eine Stelle statt mehrere Workflows zu bearbeiten.
Eskalationen werden zu Spam, wenn sie zu oft feuern. Fügen Sie Guardrails hinzu, damit jeder Schritt einen Zweck hat:
Benachrichtigungen allein lösen festsitzende Arbeit nicht, wenn die Verantwortlichkeit unklar bleibt. Definieren Sie Ownership-Regeln im Voraus: Bleibt das Ticket dem Agenten zugewiesen, wird es an die Leitung übergeben oder in eine gemeinsame Queue verschoben?
Beispiel: Nach Level-1-Eskalation neu zuweisen an den Teamlead und den ursprünglichen Agenten als Watcher setzen. So ist klar, wer als Nächstes handeln muss, und die Leiterstufe schleudert das Ticket nicht zwischen Personen hin und her.
Der einfachste Weg, SLA-Timer und Eskalationen wartbar zu halten, ist, sie als kleines System mit drei Teilen zu behandeln: Events, Evaluator und Aktionen. So verteilt sich die Zeitlogik nicht über Dutzende if now > X-Prüfungen.
Events sind einfache Fakten und sollten keine Timer-Mathematik enthalten. Sie beantworten „was hat sich geändert?" und nicht „was sollen wir jetzt tun?" Typische Events: Ticket erstellt, Agent geantwortet, Kunde geantwortet, Status geändert, manuelle Pause/Resume.
Speichern Sie diese als Zeitstempel und Statusfelder (z. B. created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
Machen Sie einen einzigen "SLA-Evaluator", der nach jedem Event und in regelmäßigen Abständen läuft. Dieser Evaluator ist der einzige Ort, der due_at und verbleibende Zeit berechnet. Er liest die aktuellen Fakten, berechnet Deadlines neu und schreibt explizite SLA-Zustandsfelder wie sla_response_state und sla_resolution_state.
Hier bleibt das Breach-State-Modelling sauber: Der Evaluator setzt Zustände wie OK, AtRisk, Breached, anstatt Logik in Benachrichtigungen zu verstecken.
Benachrichtigungen, Zuweisungen und Eskalationen sollten nur ausgelöst werden, wenn sich ein Zustand ändert (z. B. OK -> AtRisk). Trennen Sie das Versenden von Nachrichten vom Aktualisieren des SLA-Zustands. So können Sie ändern, wer benachrichtigt wird, ohne Berechnungen anzufassen.
Ein wartbares Setup sieht meist so aus: ein paar Felder auf dem Datensatz, eine kleine Policy-Tabelle und ein Evaluator, der entscheidet, was als Nächstes passiert.
Beginnen Sie mit dem Entity, das das SLA besitzt (Ticket, Bestellung, Anfrage). Fügen Sie explizite Zeitstempel und ein einzelnes "aktueller SLA-Zustand"-Feld hinzu. Halten Sie es langweilig und vorhersehbar.
Fügen Sie dann eine kleine Policy-Tabelle hinzu, die Regeln beschreibt, statt sie in viele Flows zu kodieren. Eine einfache Version ist eine Zeile pro Priorität (P1, P2, P3) mit Spalten für Zielminuten und Eskalationsschwellen (z. B. Warnung bei 80 %, Breach bei 100 %). Das ist der Unterschied zwischen dem Ändern eines Datensatzes und dem Editieren von fünf Workflows.
Statt überall separate Timer zu erstellen, nutzen Sie einen geplanten Prozess, der Items periodisch prüft (jede Minute für strikte SLAs, alle 5 Minuten für viele Teams). Der Scheduler ruft einen Evaluator auf, der:
sla_state und next_check_at zurückschreibtSo debuggen Sie einen Evaluator, nicht viele Timer.
Der Evaluator sollte sowohl den neuen Zustand als auch eine Information ausgeben, ob sich dieser Zustand geändert hat. Nur dann senden Sie Nachrichten oder erstellen Tasks (z. B. ok -> warning, warning -> breached). Wenn ein Datensatz eine Stunde lang breached bleibt, wollen Sie nicht 12 wiederholte Benachrichtigungen.
Ein praktikables Muster: speichern Sie sla_state und last_escalation_level, vergleichen Sie sie mit den neu berechneten Werten und rufen Sie dann Messaging (E-Mail/SMS/Telegram) oder interne Aufgaben nur bei tatsächlicher Änderung auf.
Pausen sind der Punkt, an dem Zeitregeln meist unordentlich werden. Ohne klares Modell läuft Ihre SLA-Uhr entweder weiter, wenn sie es nicht soll, oder sie wird durch einen falschen Klick zurückgesetzt.
Eine einfache Regel: Nur ein Status (oder eine kleine Menge) pausiert die Uhr. Eine übliche Wahl ist Waiting for customer. Wenn ein Ticket in diesen Status wechselt, speichern Sie pause_started_at. Wenn der Kunde antwortet und das Ticket den Status verlässt, schließen Sie die Pause durch Setzen von pause_ended_at und addieren die Dauer zu paused_total_seconds.
Speichern Sie nicht nur einen Zähler. Erfassen Sie jedes Pausefenster (Start, Ende, wer oder was es ausgelöst hat), damit Sie später eine Audit-Historie haben. Dann können Sie nachvollziehen, warum ein Fall gebrochen ist (z. B. 19 Stunden Waiting on Customer).
Umschichtungen und normale Statuswechsel sollten die Uhr nicht neu starten. Halten Sie SLA-Zeitstempel getrennt von Ownership-Feldern. Zum Beispiel sollten sla_started_at und sla_due_at einmalig gesetzt werden (bei Erstellung oder bei Policy-Änderung), während assignee_id nur die Zuweisung ändert. Ihr Evaluator kann dann die verstrichene Zeit so berechnen: now minus sla_started_at minus paused_total_seconds.
Regeln, die SLA-Timer vorhersehbar halten:
Ein einfacher Testaufbau sind zwei SLAs für ein Support-Ticket: First Response in 30 Minuten und Resolution in 8 Stunden. Hier bricht Logik oft, wenn sie über Screens und Buttons verteilt ist.
Angenommen, jedes Ticket speichert: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met) sowie Zeitstempel wie created_at, first_agent_reply_at und resolved_at.
Eine realistische Timeline:
Bei Eskalationen behalten Sie eine klare Kette, die bei Zustandsübergängen auslöst. Zum Beispiel: Bei response -> Warning den zugewiesenen Agenten benachrichtigen. Bei response -> Breached Teamlead informieren und Priorität erhöhen.
Aktualisieren Sie dabei stets dieselbe kleine Menge an Feldern, damit alles nachvollziehbar bleibt:
response_status oder resolution_status auf Pending, Warning, Breached oder Met.*_warning_at und *_breach_at Zeitstempel einmalig und überschreiben sie nicht.escalation_level (0, 1, 2) und setzen Sie escalated_to (Agent, Lead, Manager).sla_events-Logzeile mit dem Event-Typ und wer benachrichtigt wurde hinzu.priority und due_at, damit UI und Berichte die Eskalation widerspiegeln.Der Schlüssel ist, dass Warning und Breached explizite Zustände sind. Sie sehen sie in den Daten, können sie auditieren und die Leiter später ändern, ohne versteckte Timerprüfungen zu suchen.
SLA-Logik wird unordentlich, wenn sie sich verteilt. Eine schnelle Zeitprüfung auf einem Button hier, eine bedingte Warnung dort, und bald kann niemand erklären, warum ein Ticket eskaliert hat. Halten Sie SLA-Timer und Eskalationen als kleines, zentrales Logikstück, auf das jeder Screen und jede Aktion zugreift.
Eine häufige Falle ist, Zeitprüfungen an vielen Stellen einzubetten (UI, API-Handler, manuelle Aktionen). Die Lösung: Berechnen Sie SLA-Status in einem Evaluator und speichern Sie das Ergebnis auf dem Datensatz. Screens lesen den Status, nicht erfinden ihn.
Eine weitere Falle ist, dass Timer unterschiedliche Uhren verwenden. Wenn der Browser "Minuten seit Erstellung" berechnet, das Backend aber Serverzeit nutzt, entstehen Edge-Cases bei Schlafmodi, Zeitzonen und Sommerzeit. Verwenden Sie Serverzeit für alles, was eine Eskalation auslöst.
Benachrichtigungen können ebenfalls schnell laut werden. Wenn Sie „jede Minute prüfen und bei Überfälligkeit benachrichtigen“, bekommen Leute eventuell jede Minute Spam. Binden Sie Nachrichten an Übergänge: "warning sent", "escalated", "breached". So senden Sie einmal pro Schritt und können das Geschehen auditieren.
Arbeitszeit-Logik ist eine weitere Quelle für Komplexität. Wenn jede Regel ihren eigenen "wenn Wochenende dann..."-Zweig hat, werden Updates schmerzhaft. Kapseln Sie Business-Hours-Mathematik in einer Funktion (oder einem gemeinsamen Block), die zurückgibt, wie viele SLA-Minuten bereits verbraucht wurden, und wiederverwenden Sie diese.
Verlassen Sie sich außerdem nicht darauf, einen Breach immer neu zu berechnen. Speichern Sie den Moment des ersten Erkennens:
breached_at beim ersten Detektieren und überschreiben Sie ihn nicht.escalation_level und last_escalated_at, damit Aktionen idempotent sind.notified_warning_at (oder Ähnliches), um wiederholte Alerts zu verhindern.Beispiel: Ein Ticket erreicht "Response SLA breached" um 10:07. Wenn Sie nur neu berechnen, kann ein späterer Statuswechsel oder ein Pause/Resume-Bug so aussehen lassen, als wäre der Bruch um 10:42 passiert. Mit breached_at = 10:07 bleiben Reporting und Postmortems konsistent.
Bevor Sie Timer und Alerts hinzufügen, machen Sie einen Durchgang mit dem Ziel, die Regeln lesbar zu halten — auch noch in einem Monat.
now - created_at > X wahr ist.Ein praktischer Test: Nehmen Sie ein Ticket, das kurz vor dem Breach steht, und spielen Sie seine Timeline durch. Wenn Sie nicht ohne Lesen des gesamten Workflows erklären können, was bei jedem Statuswechsel passiert, ist Ihr Modell zu verstreut.
Bauen Sie die kleinste nützliche Variante zuerst. Wählen Sie ein SLA (z. B. First Response) und eine Eskalationsstufe (z. B. Teamlead benachrichtigen). Eine Woche echter Nutzung lehrt oft mehr als ein perfektes Design auf dem Papier.
Halten Sie Schwellenwerte und Empfänger als Daten, nicht als Logik. Legen Sie Minuten und Stunden, Business-Hours-Regeln, wer benachrichtigt wird und welche Queue den Fall besitzt in Tabellen oder Konfigurationsdatensätzen ab. Dann bleibt der Workflow stabil, während das Business Zahlen und Routing anpasst.
Planen Sie früh eine einfache Dashboard-Ansicht. Sie brauchen kein großes Analytics-System, sondern nur ein gemeinsames Bild des aktuellen Zustands: On track, Warning, Breached, Escalated.
Wenn Sie das in einer No-Code-Workflow-App bauen, wählen Sie eine Plattform, die Datenmodellierung, Logik und geplante Evaluatoren an einer Stelle erlaubt. Zum Beispiel unterstützt AppMaster (appmaster.io) Datenbank-Modellierung, visuelle Geschäftsprozesse und das Erstellen produktionsbereiter Apps — das passt gut zum Muster „Events, Evaluator, Actions".
Verfeinern Sie sicher, indem Sie in dieser Reihenfolge iterieren:
Wenn Sie bereit sind, bauen Sie zuerst eine kleine Version und wachsen Sie dann mit echtem Feedback und realen Tickets.
Beginnen Sie mit einer klaren Definition des Versprechens, das Sie messen möchten — zum Beispiel First Response oder Resolution — und halten Sie genau fest, welches Ereignis die Uhr startet, welches sie stoppt und welche Regeln Pausen auslösen. Zentralisieren Sie dann die Zeitberechnung in einem Evaluator, der explizite SLA-Zustände setzt, anstatt überall "wenn now > X"-Prüfungen zu verteilen.
Ein Timer ist die Uhr, die Sie nach einem Ereignis starten oder planen (z. B. wenn ein Ticket in einen neuen Status wechselt). Eine Eskalation ist die Aktion, die Sie ausführen, wenn eine Schwelle erreicht wird (z. B. eine Leitung informieren oder die Priorität ändern). Ein Breach ist die gespeicherte Tatsache, dass das SLA verpasst wurde und die Sie später berichten können — zum Beispiel durch einen breached_at-Zeitstempel.
Ja. First Response misst die Zeit bis zur ersten sinnvollen menschlichen Antwort, Resolution die Zeit bis zur tatsächlichen Schließung des Problems. Sie verhalten sich unterschiedlich bei Pausen und Wiederöffnungen, daher ist es einfacher und genauer, sie getrennt zu modellieren.
Standardmäßig Kalenderzeit (24/7) verwenden — sie ist einfacher und leichter zu debuggen. Business-Hours-Regeln bringen zusätzliche Komplexität (Feiertage, Zeitzonen, Teiltag-Berechnungen). Schalten Sie Working-Time nur ein, wenn es wirklich nötig ist.
Modellieren Sie Pausen als explizite Status (z. B. Waiting on Customer) und speichern Sie wann die Pause begann und endete. Beim Fortsetzen schließen Sie die Pause durch Setzen von pause_ended_at und addieren die Dauer zu paused_total_seconds. Legen Sie fest, wer pausieren kann und welche Status die Uhr anhalten, statt zufällige Statuswechsel die Zeitrechnung beeinflussen zu lassen.
Weil eine einzelne Flagge zu wenig Kontext liefert. Man muss wissen, welches SLA betroffen ist, ob es gerade pausiert und ob bereits eskaliert wurde. Explizite Zustände wie On track, Warning, Breached, Paused und Completed machen das System vorhersehbar und auditierbar.
Speichern Sie Zeitstempel, die den Zustand erklären: started_at, due_at, breached_at sowie Pausenfelder wie paused_at und paused_reason. Zusätzlich helfen Felder wie last_escalation_level, damit Sie dieselbe Eskalationsstufe nicht mehrfach benachrichtigen.
Klein halten: fangen Sie bei der Person an, die die Arbeit erledigen kann, dann die Teamleitung, und nur bei Bedarf den Manager. Legen Sie Schwellenwerte und Empfänger als Daten (Policy-Tabelle) ab, damit eine Änderung der Zeiten nicht mehrere Workflows bearbeiten muss.
Ziehen Sie Benachrichtigungen an Zustandsübergänge statt an wiederholte Zeitprüfungen: OK -> Warning oder Warning -> Breached. Ergänzen Sie Guardrails wie Cooldown-Zeiten, Retry-Regeln und eine Maximalstufe, um Spam zu vermeiden.
Nutzen Sie das Muster Events → Evaluator → Actions: Events zeichnen Fakten auf, der Evaluator berechnet Fristen und setzt SLA-Zustände, und Aktionen reagieren nur auf Zustandsänderungen. In Tools wie AppMaster (appmaster.io) können Sie Daten modellieren, visuelle Business-Prozesse für den Evaluator bauen und Benachrichtigungen von den Zustandsupdates auslösen, während die Zeitlogik zentral bleibt.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


