Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Vergleich pgvector vs. managed Vektor-Datenbank für semantische Suche: Einrichtungsaufwand, Skalierungsfragen, Filter- und Berechtigungsunterstützung und Integration in einen typischen App-Stack.
Semantische Suche hilft Menschen, die richtige Antwort zu finden, auch wenn sie nicht die „richtigen“ Schlüsselwörter verwenden. Statt exakte Wörter abzugleichen, vergleicht sie Bedeutung. Jemand, der „reset my login“ tippt, sollte trotzdem einen Artikel wie „Change your password and sign in again“ sehen, weil die Intention gleich ist.
Stichwortsuche versagt in Business-Apps, weil reale Nutzer inkonsistent sind. Sie verwenden Abkürzungen, machen Tippfehler, vermischen Produktnamen und beschreiben Symptome statt offizieller Begriffe. In FAQs, Support-Tickets, Policydokumenten und Onboarding-Guides taucht dasselbe Problem in vielen Formulierungen auf. Eine Stichwort-Engine liefert oft nichts Nützliches oder eine lange Liste, die Nutzer zum Herumklicken zwingt.
Embeddings sind der übliche Baustein. Deine App wandelt jedes Dokument (einen Artikel, ein Ticket, eine Produktnotiz) in einen Vektor um, eine lange Zahlenliste, die Bedeutung repräsentiert. Wenn ein Nutzer fragt, embeddest du auch die Frage und suchst nach den nächsten Vektoren. Eine „Vektor-Datenbank“ ist einfach der Ort, wo du diese Vektoren speicherst und schnell durchsuchen kannst.
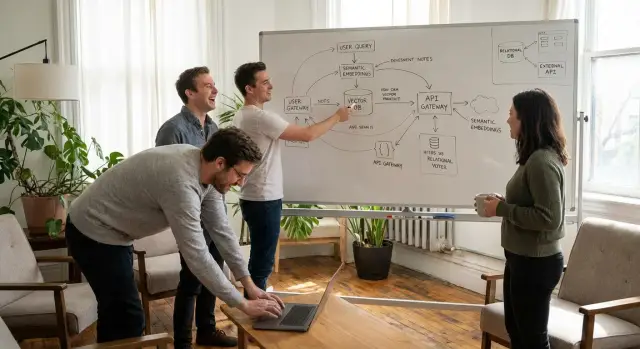
In einem typischen Business-Stack berührt semantische Suche vier Bereiche: den Content-Store (Knowledge Base, Docs, Ticket-System), die Embedding-Pipeline (Importe plus Updates bei Änderungen), die Query-Erfahrung (Suchfeld, vorgeschlagene Antworten, Agent-Assist) und die Guardrails (Berechtigungen plus Metadaten wie Team, Kunde, Tarif und Region).
Für die meisten Teams gilt: „gut genug“ schlägt perfekt. Das praktische Ziel ist Relevanz beim ersten Versuch, Antworten unter einer Sekunde und vorhersehbare Kosten bei wachsendem Inhalt. Das Ziel ist wichtiger als die Diskussion über Tools.
Die meisten Teams entscheiden sich zwischen zwei Mustern für semantische Suche: alles in PostgreSQL mit pgvector behalten oder eine separate managed Vektor-Datenbank neben der Hauptdatenbank einsetzen. Die richtige Wahl hängt weniger von „welches ist besser“ ab und mehr davon, wo du Komplexität haben möchtest.
pgvector ist eine PostgreSQL-Erweiterung, die einen Vektor-Datentyp und Indizes hinzufügt, sodass du Embeddings in einer normalen Tabelle speichern und Ähnlichkeitssuchen per SQL ausführen kannst. In der Praxis enthält deine Dokumenttabelle Text, Metadaten (customer_id, status, visibility) und eine Embedding-Spalte. Die Suche wird dann: Query embedden und Zeilen zurückgeben, deren Embeddings am nächsten liegen.
Eine managed Vektor-Datenbank ist ein gehosteter Dienst, der hauptsächlich für Embeddings gebaut ist. Sie bietet typischerweise APIs zum Einfügen von Vektoren und Abfragen nach Ähnlichkeit sowie Betriebsfunktionen, die du sonst selbst bauen müsstest.
Beide Optionen erledigen denselben Kernjob: Embeddings mit einer ID und Metadaten speichern, die nächsten Nachbarn für eine Anfrage finden und Top-Matches zurückgeben, damit deine App relevante Einträge anzeigen kann.
Der Unterschied ist das System of Record. Selbst wenn du eine managed Vektor-Datenbank nutzt, behältst du fast immer PostgreSQL für Geschäftsdaten: Accounts, Berechtigungen, Abrechnung, Workflow-Status und Audit-Logs. Der Vektor-Store wird zur Retrieval-Schicht, nicht zur Ausführungsbasis der gesamten App.
Eine übliche Architektur sieht so aus: halte den autoritativen Datensatz in Postgres, speichere Embeddings entweder in Postgres (pgvector) oder im Vektor-Dienst, führe eine Ähnlichkeitssuche aus, um passende IDs zu erhalten, und hole dann die vollständigen Zeilen aus Postgres.
Wenn du Apps auf einer Plattform wie AppMaster baust, ist PostgreSQL bereits ein natürlicher Ort für strukturierte Daten und Berechtigungen. Die Frage ist, ob die Embedding-Suche dort leben oder in einem spezialisierten Dienst liegen soll, während Postgres die Single Source of Truth bleibt.
Teams wählen oft nach Features und sind dann vom täglichen Aufwand überrascht. Die eigentliche Entscheidung ist, wo die Komplexität liegen soll: in deiner bestehenden Postgres-Installation oder in einem separaten Dienst.
Bei pgvector fügst du Vektorsuche zu der Datenbank hinzu, die du bereits betreibst. Das Setup ist in der Regel unkompliziert, aber es ist trotzdem Datenbankarbeit, nicht nur Anwendungslogik.
Ein typisches pgvector-Setup umfasst das Aktivieren der Erweiterung, Hinzufügen einer Embedding-Spalte, Erstellen eines Indexes, der zu deinem Abfragemuster passt (und späteres Tuning), Entscheidungen zum Aktualisieren von Embeddings bei Inhaltsänderungen und das Schreiben von Ähnlichkeitsabfragen, die auch normale Filter anwenden.
Bei einer managed Vektor-Datenbank richtest du ein neues System neben deiner Hauptdatenbank ein. Das bedeutet oft weniger SQL, aber mehr Integrationsaufwand.
Ein typisches managed-Setup umfasst das Erstellen eines Indexes (Dimensionen und Distanzmetrik), Einpflegen von API-Keys in Secrets, Aufbau eines Ingestionsjobs zum Pushen von Embeddings und Metadaten, Pflege einer stabilen ID-Abbildung zwischen App-Records und Vektor-Records sowie Absicherung des Netzwerkzugriffs, damit nur dein Backend abfragen kann.
CI/CD und Migrationen unterscheiden sich ebenfalls. pgvector passt natürlich in existierende Migrationen und Review-Prozesse. Managed-Services verschieben Änderungen in Code plus Admin-Einstellungen, daher brauchst du einen klaren Prozess für Konfigurationsänderungen und Reindexing.
Ownership folgt meist der Wahl: pgvector liegt bei App-Entwicklern plus whoever Postgres betreut (manchmal ein DBA). Ein managed Service liegt oft bei einer Plattform- oder Infrastrukturabteilung, während App-Dev das Ingest- und Query-Handling übernimmt. Deshalb geht es bei der Entscheidung genauso um Teamstruktur wie um Technologie.
Semantische Suche hilft nur, wenn sie respektiert, was ein Nutzer sehen darf. In einer echten Business-App hat jeder Datensatz Metadaten neben dem Embedding: org_id, user_id, role, status (open, closed) und visibility (public, internal, private). Wenn deine Suchschicht nicht sauber auf diese Metadaten filtern kann, bekommst du verwirrende Ergebnisse oder – noch schlimmer – Datenlecks.
Der größte praktische Unterschied ist Filtern vor vs. nach der Vektor-Suche. Nachträgliches Filtern klingt einfach (alles suchen, dann verbotene Zeilen entfernen), scheitert aber auf zwei Arten. Erstens können die besten Treffer entfernt werden, sodass nur schlechtere Ergebnisse bleiben. Zweitens erhöht es das Sicherheitsrisiko, wenn Teile der Pipeline ungefilterte Ergebnisse loggen, cachen oder exponieren.
Bei pgvector leben Vektoren in PostgreSQL neben den Metadaten, sodass du Berechtigungen in derselben SQL-Abfrage anwenden und Postgres die Durchsetzung übernehmen lassen kannst.
Wenn deine App bereits Postgres nutzt, gewinnt pgvector oft durch Einfachheit: Suche ist „nur eine weitere Abfrage“. Du kannst über Tickets, Kunden und Mitgliedschaften joinen und Row Level Security nutzen, sodass die Datenbank selbst unautorisierte Zeilen blockiert.
Ein übliches Muster ist, die Kandidatenmenge mit Org- und Status-Filtern einzuschränken und dann die Vektorähnlichkeit auf dem Rest auszuführen, optional kombiniert mit Stichwort-Matching für exakte Identifikatoren.
Die meisten managed Vektor-Datenbanken unterstützen Metadatenfilter, aber die Filter-Sprache kann eingeschränkt sein und Joins gibt es nicht. Du musst Metadaten oft in jeden Vektor-Datensatz denormalisieren und Berechtigungsprüfungen in deiner Anwendung nachbauen.
Für hybride Suche in Business-Apps willst du meist alle zusammenarbeiten sehen: harte Filter (org, role, status, visibility), Stichwort-Match (exakte Begriffe wie Rechnungsnummern), Vektorähnlichkeit (Bedeutung) und Ranking-Regeln (z. B. neuere oder offene Elemente boosten).
Beispiel: Ein Support-Portal in AppMaster kann Tickets und Berechtigungen in PostgreSQL halten, sodass sich „Agent sieht nur ihre Org“ leicht durchsetzen lässt und trotzdem semantische Treffer auf Ticket-Zusammenfassungen und Antworten erzielt werden.
Suchqualität ist die Mischung aus Relevanz (sind die Ergebnisse nützlich?) und Geschwindigkeit (fühlt es sich sofort an?). Sowohl bei pgvector als auch bei managed Vektor-Datenbanken tauscht man oft etwas Relevanz gegen geringere Latenz, indem man approximative Suche nutzt. Dieser Kompromiss ist für Business-Apps meist akzeptabel, solange du ihn mit realen Abfragen misst.
Auf hoher Ebene stellst du drei Dinge ein: das Embedding-Modell (wie „Bedeutung“ aussieht), die Index-Einstellungen (wie gründlich die Engine sucht) und die Ranking-Schicht (wie Ergebnisse geordnet werden, wenn du Filter, Aktualität oder Popularität hinzufügst).
In PostgreSQL mit pgvector wählst du typischerweise einen Index wie IVFFlat oder HNSW. IVFFlat ist schneller und leichter zu bauen, aber du musst die Anzahl der "Lists" tunen und meist genug Daten haben, bevor es gut wirkt. HNSW liefert oft bessere Recall-Raten bei niedriger Latenz, kann aber mehr Speicher benötigen und dauert länger beim Aufbau. Managed Systeme bieten ähnliche Optionen, nur mit anderen Namen und Defaults.
Einige Taktiken sind wichtiger als erwartet: cache beliebte Queries, batch-arbeit wo möglich (z. B. Prefetch der nächsten Seite) und überlege einen Zwei-Stufen-Flow, bei dem du eine schnelle Vektor-Suche machst und dann die Top-20 bis -100 mit Business-Signalen (Aktualität, Kundentier) rerankst. Achte auch auf Netzwerk-Hops: Wenn die Suche in einem separaten Dienst lebt, ist jede Anfrage ein weiterer Roundtrip.
Um Qualität zu messen, starte klein und konkret. Sammle 20–50 echte Nutzerfragen, definiere, was eine „gute“ Antwort ist, und tracke Top‑3 und Top‑10 Hit‑Rate, Median- und p95-Latenz, Anteil an Anfragen ohne gutes Ergebnis und wie stark die Qualität unter Anwendung von Berechtigungen und Filtern sinkt.
Hier hört die Wahl oft auf theoretisch zu sein. Die beste Option trifft dein Relevanzziel bei einer akzeptablen Latenz und ist mit dem Tuning, das du unterhalten kannst, erreichbar.
Viele Teams starten mit pgvector, weil alles an einem Ort bleibt: App-Daten und Embeddings. Für viele Business-Apps reicht ein einzelner PostgreSQL-Knoten, besonders wenn du Zehntausende bis wenige Hunderttausend Vektoren hast und Suche nicht der dominante Traffic-Treiber ist.
Limits erreicht man meist, wenn semantische Suche zur Kernaktion wird (auf den meisten Seiten, in jedem Ticket, im Chat) oder wenn Millionen von Vektoren gespeichert werden und zu Spitzenzeiten enge Antwortzeiten nötig sind.
Anzeichen, dass eine einzelne Postgres-Instanz belastet ist: p95-Suchlatenz springt bei normalen Schreibvorgängen, du musst zwischen schnellen Indizes und akzeptabler Schreibleistung wählen, Wartungsaufgaben werden zu „nachts planen“-Events und du brauchst unterschiedliche Skalierung für Suche und den Rest der DB.
Bei pgvector bedeutet Skalierung oft Read-Replicas für Abfragen, Partitionierung von Tabellen, Index-Tuning und Planung rund um Index-Builds und Speicherwachstum. Das ist machbar, aber wird zu laufender Arbeit. Du stehst auch vor Designentscheidungen wie Embeddings in derselben Tabelle wie Geschäftsdaten zu belassen oder zu separieren, um Bloat und Lock-Contention zu reduzieren.
Managed Vektor-Datenbanken verschieben vieles davon zum Anbieter. Sie bieten oft unabhängige Skalierung von Compute und Storage, eingebautes Sharding und einfache Hochverfügbarkeit. Der Tradeoff ist, zwei Systeme zu betreiben (Postgres plus Vektor-Store) und Metadaten sowie Berechtigungen synchron zu halten.
Kosten überraschen Teams häufiger als Performance. Treiber sind Storage (Vektoren + Indizes wachsen schnell), Spitzenabfragevolumen (setzt oft die Rechnung), Update-Frequenz (Re-Embedding und Upserts) und Datenbewegung (zusätzliche Calls wenn deine App stark filtert).
Wenn du zwischen pgvector und managed Service entscheidest, wähle die Art von Schmerz, die du lieber trägst: tiefere Postgres-Optimierung und Kapazitätsplanung oder mehr Kosten für einfachere Skalierung und eine zusätzliche Abhängigkeit.
Sicherheitsaspekte entscheiden oft schneller als Speed-Benchmarks. Frage früh, wo Daten liegen, wer Zugriff hat und was bei einem Ausfall passiert.
Beginne mit Datenresidenz und Zugriff. Embeddings können Bedeutung leaken, und viele Teams speichern auch Text-Snippets für Highlighting. Kläre, welches System Rohtexte (Tickets, Notizen, Dokumente) hält und welches nur Embeddings. Bestimme außerdem, wer innerhalb deines Unternehmens den Store direkt abfragen darf und ob eine strikte Trennung zwischen Prod- und Analytics-Zugriff nötig ist.
Stelle diese Fragen für beide Optionen:
Multi-Tenant-Trennung führt die meisten in die Irre. Wenn ein Kunde niemals einen anderen beeinflussen darf, brauchst du starke Tenant-Scoping in jeder Abfrage. Mit PostgreSQL lässt sich das mit Row-Level Security und sorgfältigen Query-Patterns erzwingen. Bei einer managed Vektor-Datenbank verlässt du dich oft auf Namespaces oder Collections plus Anwendungslogik.
Plane für Suchausfälle. Wenn der Vektor-Store down ist, was sehen Nutzer? Ein sicherer Default ist, auf Stichwortsuche zurückzufallen oder nur neuere Items zu zeigen, statt die Seite zu zerstören.
Beispiel: In einem Support-Portal mit AppMaster kannst du Tickets in PostgreSQL halten und semantische Suche als optionales Feature behandeln. Wenn Embeddings ausfallen, zeigt das Portal weiterhin Ticket-Listen und erlaubt genaue Stichwortsuche, während du den Vektor-Service wiederherstellst.
Am sichersten ist ein kleiner Pilot, der deiner echten App ähnelt, nicht einem Demo-Notebook.
Schreibe zuerst auf, was du suchst und was gefiltert werden muss. „Unsere Docs suchen“ ist vage. „Hilfsartikel, Ticket-Antworten und PDF-Handbücher durchsuchen, aber nur Inhalte zeigen, die der Nutzer sehen darf“ ist eine konkrete Anforderung. Berechtigungen, Tenant-ID, Sprache, Produktbereich und „nur veröffentlichte Inhalte“ Filter entscheiden oft.
Wähle dann ein Embedding-Modell und einen Refresh-Plan. Entscheide, was eingebettet wird (Ganzes Dokument, Chunks oder beides) und wie oft es aktualisiert wird (bei jeder Bearbeitung, nachts oder beim Veröffentlichen). Wenn Inhalte häufig ändern, messe, wie schmerzhaft Re-Embedding ist, nicht nur wie schnell Abfragen sind.
Baue eine einfache Search-API im Backend. Halte sie langweilig: ein Endpoint, der eine Query plus Filterfelder annimmt, Top-Ergebnisse zurückgibt und protokolliert, was passiert ist. Wenn du mit AppMaster baust, kannst du Ingestion und Update-Flow als Backend-Service und Business Process implementieren, der deinen Embedding-Provider aufruft, Vektoren und Metadaten schreibt und Zugriffsregeln durchsetzt.
Führe einen zweiwöchigen Pilot mit echten Nutzern und Aufgaben durch. Verwende eine Handvoll häufiger Nutzerfragen, tracke "gefundenen Antwort"-Rate und Zeit bis zur ersten nützlichen Antwort, überprüfe schlechte Ergebnisse wöchentlich, beobachte Re-Embedding-Volumen und Query-Load und teste Fehlerfälle wie fehlende Metadaten oder veraltete Vektoren.
Am Ende entscheide anhand der Evidenz. Behalte pgvector, wenn es Qualität und Filteranforderungen bei akzeptabler Betriebsarbeit erfüllt. Wechsle zu einem managed Service, wenn Skalierung und Zuverlässigkeit dominieren. Oder nutze ein hybrides Setup (PostgreSQL für Metadaten und Berechtigungen, Vektor-Store für Retrieval), wenn das zu deinem Stack passt.
Die meisten Fehler zeigen sich nach dem ersten Demo. Ein schneller Proof-of-Concept kann toll aussehen und dann auseinanderfallen, wenn reale Nutzer, echte Daten und echte Regeln hinzukommen.
Die Probleme, die meistens zu Nacharbeit führen, sind:
Ein einfacher "Day‑2"-Test fängt das früh ab: Füge eine neue Berechtigungsregel hinzu, aktualisiere 20 Items, lösche 5 und stelle dann dieselben 10 Evaluationsfragen erneut. Wenn du AppMaster nutzt, plane diese Checks zusammen mit deiner Business-Logik und dem Datenbankmodell, nicht als Nachgedanken.
Ein mittelgroßes SaaS-Unternehmen betreibt ein Support-Portal mit zwei Hauptinhalten: Kundentickets und Help-Center-Artikel. Sie wollen ein Suchfeld, das Bedeutung versteht, sodass „can’t log in after changing phone“ den richtigen Artikel und ähnliche vergangene Tickets anzeigt.
Die Nicht-Verhandelbaren sind praktisch: Jeder Kunde darf nur seine eigenen Tickets sehen, Agenten müssen nach Status filtern können (open, pending, solved) und Ergebnisse müssen sich sofort anfühlen, weil Vorschläge beim Tippen gezeigt werden.
Wenn Portal-Tickets und Artikel bereits in PostgreSQL liegen (häufig bei Stacks mit Postgres, z. B. wenn du mit AppMaster arbeitest), ist pgvector oft ein sauberer erster Schritt. Du behältst Embeddings, Metadaten und Berechtigungen an einem Ort, sodass "nur Tickets für customer_123" einfach eine normale WHERE-Klausel ist.
Das funktioniert gut, wenn dein Datensatz moderat ist (Zehntausende oder Hunderttausende Items), dein Team sich mit Postgres-Index- und Query-Plan-Tuning wohlfühlt und du weniger bewegliche Teile mit einfacherem Zugriffskontrollmodell willst.
Der Tradeoff ist, dass Vektorsuche mit transaktionaler Last konkurrieren kann. Mit wachsendem Nutzung musst du vielleicht Kapazität hinzufügen, Indizes sorgfältig pflegen oder sogar eine separate Postgres-Instanz einplanen, um Ticket-Writes und SLAs zu schützen.
Bei einer managed Vektor-Datenbank speicherst du typischerweise Embeddings und eine ID dort und hältst die "Wahrheit" (Ticket-Status, customer_id, Berechtigungen) in PostgreSQL. In der Praxis filtern Teams entweder zuerst in Postgres und suchen dann unter den berechtigten IDs oder suchen zuerst und prüfen Berechtigungen, bevor Ergebnisse angezeigt werden.
Diese Option gewinnt oft, wenn Wachstum unsicher ist oder das Team keine Zeit für Performance-Nursing hat. Aber der Permission-Flow braucht echte Sorgfalt, sonst riskierst du, Ergebnisse zwischen Kunden zu leaken.
Eine praktische Faustregel: Starte mit pgvector, wenn du jetzt enge Filter und einfache Betriebsabläufe brauchst, und plane einen Wechsel zu einem managed Vektor-Service, wenn du schnelles Wachstum, hohes Query-Volumen erwartest oder nicht riskieren kannst, dass Suche deine Kerndatenbank verlangsamt.
Wenn du feststeckst: Hör auf zu debattieren und schreibe auf, was deine App am ersten Tag tun muss. Die echten Anforderungen zeigen sich meist in einem kleinen Pilot mit echten Nutzern und Daten.
Diese Fragen entscheiden oft schneller als Benchmarks:
Plane auch für Veränderung. Embeddings sind nicht "einmal und fertig". Texte ändern sich, Modelle ändern sich und Relevanz driftet, bis jemand sich beschwert. Entscheide früh, wie du Updates handhabst, wie du Drift erkennst und was du überwacht (Query-Latenz, Fehlerquote, Recall auf einem kleinen Testsatz und "keine Ergebnisse"-Suchen).
Wenn du schnell an der ganzen Business-App rund um Suche arbeiten willst, kann AppMaster (appmaster.io) praktisch sein: Es bietet PostgreSQL-Datenmodellierung, Backend-Logik und Web- oder Mobile-UI in einem No-Code-Workflow, und du kannst semantische Suche iterativ hinzufügen, sobald Kern-App und Berechtigungen stehen.
Semantische Suche liefert nützliche Ergebnisse, auch wenn die Worte des Nutzers nicht exakt mit dem Dokument übereinstimmen. Sie hilft besonders bei Tippfehlern, Abkürzungen oder wenn Nutzer Symptome statt offizieller Begriffe beschreiben – typisch in Support-Portalen, internen Tools und Wissensdatenbanken.
Nimm pgvector, wenn du weniger bewegliche Teile willst, enge SQL-basierte Filter benötigst und dein Datenbestand sowie Traffic noch moderat sind. Es ist oft der schnellste Weg zu einer sicheren, berechtigungsbewussten Suche, weil Vektoren und Metadaten in denselben PostgreSQL-Abfragen liegen.
Eine gemanagte Vektor-Datenbank ist sinnvoll, wenn du schnelles Wachstum bei Vektoren oder Abfragen erwartest oder Skalierung und Verfügbarkeit außerhalb deiner Hauptdatenbank gehandhabt werden sollen. Du tauschst einfachere Betriebsaufgaben gegen zusätzlichen Integrationsaufwand und sorgfältige Berechtigungsprüfung.
Ein Embedding ist die Umwandlung von Text in einen numerischen Vektor, der Bedeutung repräsentiert. Eine Vektor-Datenbank (oder pgvector in PostgreSQL) speichert diese Vektoren und findet schnell die nächstgelegenen zu einer eingebetteten Nutzeranfrage – so entstehen „ähnliche nach Intention“ Ergebnisse.
Nach der Suche zu filtern entfernt oft die besten Treffer und kann Nutzer mit schlechteren Ergebnissen oder leeren Seiten zurücklassen. Außerdem erhöht es das Risiko unbeabsichtigter Offenlegung über Logs, Caches oder Debugging; deshalb sollte man Mandanten- und Rollenfilter so früh wie möglich anwenden.
Mit pgvector kannst du Berechtigungen, Joins und Row Level Security in derselben SQL-Abfrage anwenden, die die Ähnlichkeitssuche durchführt. Das macht es einfacher sicherzustellen, dass verbotene Zeilen nie angezeigt werden, weil PostgreSQL die Regeln dort durchsetzt, wo die Daten liegen.
Die meisten managed vector databases unterstützen Metadatenfilter, aber Joins sind in der Regel nicht möglich und die Filter-Sprache ist oft begrenzt. Üblich ist, berechtigungsrelevante Metadaten in jeden Vektor-Datensatz zu denormalisieren und die endgültigen Autorisierungschecks in der Anwendung durchzuführen.
Chunking bedeutet, große Dokumente vor dem Embedding zu teilen, was die Präzision verbessert, weil jeder Vektor eine fokussierte Idee repräsentiert. Full-Document-Embeddings funktionieren bei kurzen Einträgen, aber bei langen Tickets, Richtlinien und PDFs werden Ergebnisse ohne Chunking oft vage.
Plane Updates von Anfang an: Re-embed beim Veröffentlichen oder Bearbeiten für Inhalte, die sich häufig ändern, und entferne Vektoren wenn die Quelldaten gelöscht werden. Wenn du das übersiehst, lieferst du veraltete Treffer, die auf fehlende oder überholte Inhalte verweisen.
Ein praktisches Pilotprojekt nutzt reale Anfragen und strikte Filter, misst Relevanz und Latenz und testet Fehlerfälle wie fehlende Metadaten oder veraltete Vektoren. Wähle die Option, die unter deinen Berechtigungsregeln zuverlässig gute Top-Ergebnisse liefert und dessen Kosten und Betriebsaufwand dein Team tragen kann.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


