Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Lernen Sie Operations‑Dashboard‑Metriken kennen, die Durchsatz, Backlog und SLA widerspiegeln. Entscheiden Sie, was zu messen ist, wie zu aggregieren ist und welche Charts zu Aktionen führen.
Ein Operations‑Dashboard ist keine Wand voller Charts. Es ist eine gemeinsame Sicht, die einem Team hilft, dieselben Entscheidungen schneller zu treffen, ohne darüber zu streiten, wessen Zahlen „richtig“ sind. Wenn es nicht beeinflusst, was jemand als Nächstes tut, ist es Dekoration.
Die Aufgabe ist, eine kleine Menge wiederkehrender Entscheidungen zu unterstützen. Die meisten Teams kommen jede Woche auf dieselben zurück:
Verschiedene Personen nutzen dasselbe Dashboard unterschiedlich. Ein Frontline‑Lead schaut es vielleicht täglich an, um zu entscheiden, worauf heute zu achten ist. Ein Manager überprüft es wöchentlich, um Trends zu erkennen, Staffing zu rechtfertigen und Überraschungen zu verhindern. Eine Ansicht dient selten beiden gut; in der Regel braucht man eine Lead‑Ansicht und eine Manager‑Ansicht.
„Schicke Charts“ scheitern auf einfache Weise: Sie zeigen Aktivität, nicht Kontrolle. Ein Chart kann beeindruckend aussehen, während die Arbeit sich aufstaut, altert und Versprechen verfehlt. Das Dashboard sollte Probleme früh sichtbar machen, nicht sie im Nachhinein erklären.
Definieren Sie, wie „gut“ aussieht, bevor Sie Visuals wählen. Für die meisten Operationsteams ist gut langweilig:
Ein kleines Beispiel: Ein Support‑Team sieht einen Anstieg bei „Tickets geschlossen“ und feiert. Aber das Backlog altert und die ältesten Items rutschen an die SLA‑Grenze. Ein nützliches Dashboard zeigt diese Spannung sofort, sodass der Lead neue Anfragen pausieren, einen Spezialisten umschichten oder Blocker eskalieren kann.
Die meisten Operations‑Metriken fallen in drei Bereiche: was Sie fertigstellen, was wartet und ob Sie Ihre Versprechen halten.
Durchsatz ist, wie viel Arbeit in einem Zeitraum auf „fertig“ kommt. Entscheidend ist, dass „fertig“ echt sein muss, nicht halb. Für ein Support‑Team kann „fertig“ bedeuten, dass das Ticket gelöst und geschlossen ist. Für ein Ops‑Team kann „fertig“ heißen, dass die Anfrage geliefert, verifiziert und übergeben wurde. Wenn Sie Arbeit zählen, die noch Nacharbeit braucht, überschätzen Sie die Kapazität und erkennen Probleme zu spät.
Backlog ist die Arbeit, die darauf wartet, begonnen oder abgeschlossen zu werden. Die reine Größe reicht nicht aus, weil 40 neue Items, die heute ankamen, sich sehr von 40 Items unterscheiden, die seit Wochen liegen. Backlog wird nützlich, wenn Sie Alter hinzufügen, etwa „wie lange Items gewartet haben“ oder „wie viele älter als X Tage sind“. Das sagt Ihnen, ob es eine temporäre Spitze oder ein wachsendes Nadelöhr ist.
SLA ist das Zeitversprechen. Es kann intern (an ein anderes Team) oder extern (an Kunden) gerichtet sein. SLAs beziehen sich meist auf einige Uhren:
Diese drei Kennzahlen hängen direkt zusammen. Durchsatz ist der Abfluss. Backlog ist das Wasser in der Wanne. SLA beschreibt, was mit der Wartezeit passiert, während die Wanne füllt oder leert. Wenn das Backlog schneller wächst als der Durchsatz, sitzen Items länger und SLA‑Verletzungen steigen. Wenn der Durchsatz steigt, ohne die Eingänge zu verändern, schrumpft das Backlog und die SLA verbessert sich.
Ein einfaches Beispiel: Ihr Team schließt etwa 25 Anfragen pro Tag. Für drei Tage steigen neue Anfragen nach einem Produktupdate auf 40 pro Tag. Das Backlog wächst um etwa 45 Items, und die ältesten Items beginnen, Ihre 48‑Stunden‑SLA zu überschreiten. Ein gutes Dashboard macht Ursache und Wirkung offensichtlich, sodass Sie früh handeln können: nicht‑dringende Arbeit pausieren, einen Spezialisten umleiten oder die Intake‑Regeln temporär anpassen.
Ein nützliches Dashboard beginnt mit den Fragen, die Menschen stellen, wenn etwas nicht stimmt — nicht mit den Daten, die am einfachsten zu holen sind. Schreiben Sie zuerst die Entscheidungen auf, die das Dashboard unterstützen soll.
Die meisten Teams müssen diese jede Woche beantworten:
Beschränken Sie sich dann auf 1–2 primäre Messgrößen pro Bereich. Das hält die Seite lesbar und macht „was wichtig ist“ offensichtlich.
Fügen Sie einen führenden Indikator hinzu, damit Sie das Chart nicht falsch lesen. Ein sinkender Durchsatz kann langsameres Arbeiten bedeuten, aber auch weniger Ankünfte. Verfolgen Sie daher Ankünfte (neu erstellte/geöffnete Items) neben dem Durchsatz.
Entscheiden Sie schließlich, nach welchen Dimensionen Sie schneiden müssen. Slices verwandeln einen Durchschnitt in eine Landkarte, wo zu handeln ist. Gängige sind Team, Queue, Kundensegment und Priorität. Behalten Sie nur Slices, die zu Zuständigkeiten und Eskalationswegen passen.
Ein konkretes Beispiel: Wenn das Gesamtsla gut aussieht, Sie aber nach Priorität aufteilen, finden Sie vielleicht, dass P1‑Arbeit doppelt so oft verletzt wird wie der Rest. Das weist auf andere Maßnahmen hin als „schneller arbeiten“: Lücken in der Rufbereitschaft, unklare P1‑Definitionen oder langsame Übergaben zwischen Queues.
Die meisten Dashboard‑Streitigkeiten drehen sich nicht um Zahlen, sondern um Worte. Wenn zwei Teams unterschiedliche Bedeutungen von „done“ oder „breached“ haben, sehen Ihre Metriken präzise aus und sind trotzdem falsch.
Beginnen Sie damit, die Ereignisse zu definieren, die Sie messen. Schreiben Sie sie als einfache Regeln, die jeder auf dieselbe Weise anwenden kann, auch an einem hektischen Tag.
Wählen Sie eine kleine Menge von Ereignissen und verankern Sie jedes an einem klaren Systemmoment, meist einem Zeitstempelwechsel:
Definieren Sie außerdem, was als breached für SLA‑Reports zählt. Läuft die SLA‑Uhr von „created bis first response“, „created bis done“ oder „started bis done“? Entscheiden Sie, ob die Uhr bei Blockaden pausiert und welche Blockgründe zählen.
Nacharbeit ist der Bereich, in dem Teams versehentlich Zahlen schönrechnen. Entscheiden Sie sich für einen Ansatz und bleiben Sie dabei.
Wenn ein Ticket wieder geöffnet wird: Zählen Sie es als dasselbe Item (mit zusätzlicher Cycle‑Time) oder als neues Item (neues Created‑Datum)? Es als dasselbe zu zählen gibt meist bessere Qualitäts‑Sichtbarkeit, kann aber den Durchsatz geringer erscheinen lassen. Es als neues zu zählen kann die wahren Kosten von Fehlern verbergen.
Ein praktischer Kompromiss ist, eine Arbeitseinheit beizubehalten, aber zusätzlich „Reopen‑Count“ und „Rework‑Time“ zu erfassen, sodass der Hauptfluss ehrlich bleibt.
Jetzt einigen Sie sich auf Ihre Arbeitseinheit und Statusregeln. „Ticket“, „Order“, „Request“ oder „Task“ funktionieren alle, aber nur wenn alle dieselbe Bedeutung verwenden. Beispiel: Spaltet sich eine Bestellung in drei Lieferungen, ist das dann eine Einheit (Order) oder drei Einheiten (Shipments)? Durchsatz und Backlog ändern sich je nach Wahl.
Dokumentieren Sie die minimalen Felder, die Ihr System erfassen muss, sonst ist das Dashboard voller Lücken und Vermutungen:
Aggregation ist ein häufiger Fehlerpunkt. Sie komprimieren unordentliche Realität in wenige Zahlen und wundern sich dann, warum die „gute“ Kurve nicht dem täglichen Gefühl des Teams entspricht. Ziel ist keine hübschere Grafik, sondern eine ehrliche Zusammenfassung, die Risiken zeigt.
Beginnen Sie mit Zeitbuckets, die zu den Entscheidungen passen. Tagesansichten helfen Operativen, heutige Staus zu erkennen. Wochenansichten zeigen, ob eine Änderung geholfen hat. Monatsansichten sind gut für Planung und Staffing, können aber kurze Spitzen verbergen, die SLAs brechen.
Für zeitbasierte Maße (Cycle Time, First Response Time, Time to Resolution) verlassen Sie sich nicht auf Durchschnitte. Einige sehr lange Fälle verzerren sie, einige sehr kurze machen alles besser aussehen. Mediane und Perzentile erzählen die Geschichte, die Teams interessiert: was typisch ist (p50) und was schmerzt (p90).
Ein einfaches Muster, das funktioniert:
Segmentierung ist der andere Hebel. Eine einzige Gesamtlinie reicht für die Führungsebene, aber sie sollte nicht die einzige Ansicht sein. Teilen Sie nach ein oder zwei Dimensionen, die dem tatsächlichen Arbeitsfluss entsprechen, z. B. Queue, Priorität, Region, Produkt oder Kanal (E‑Mail, Chat, Telefon). Halten Sie es eng. Wenn Sie nach fünf Dimensionen gleichzeitig aufsplitten, erhalten Sie winzige Gruppen und laute Charts.
Randfälle sind diejenigen, in denen Teams sich selbst belügen. Entscheiden Sie vorher, wie pausierte Arbeit, „Warten auf Kunde“, Feiertage und außerhalb‑der‑Arbeitszeiten behandelt werden. Wenn Ihre SLA‑Uhr beim Warten auf Kunde stoppt, muss das Dashboard dieselbe Regel widerspiegeln sonst jagen Sie Probleme, die nicht real sind.
Eine praktische Vorgehensweise ist, zwei Uhren nebeneinander zu veröffentlichen: Kalenderzeit und Geschäftstag‑Zeit. Kalenderzeit entspricht der Kundenerfahrung. Geschäftstag‑Zeit entspricht dem, was Ihr Team kontrollieren kann.
Prüfen Sie schließlich jede Aggregation stichprobenartig an echten Tickets oder Orders. Wenn der p90 großartig aussieht, aber Operatives zehn festhängende Items nennen kann, verbergen Ihre Gruppierungen oder Uhrregeln den Schmerz.
Gute Metriken können eines gut: sie zeigen, was als Nächstes zu tun ist. Wenn ein Chart zu Definitionen diskutieren lässt oder eine Zahl feiert ohne Verhalten zu ändern, ist es wahrscheinlich Eitelkeit.
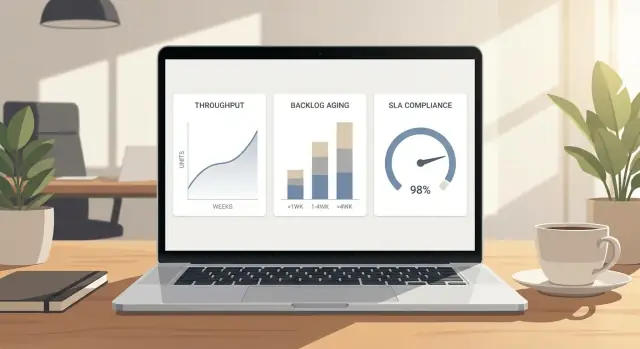
Ein Liniendiagramm für Durchsatz (pro Tag oder Woche abgeschlossene Arbeit) wird nützlicher, wenn Sie Kontext ergänzen. Legen Sie ein Zielband auf das Chart, nicht nur eine Ziel‑Linie, damit man sieht, wann Leistung wirklich außerhalb des Erwartbaren ist.
Fügen Sie Ankünfte auf derselben Zeitachse hinzu. Wenn der Durchsatz gut aussieht, aber die Ankünfte steigen, erkennen Sie den Moment, in dem das System ins Hintertreffen gerät.
Halten Sie es lesbar:
Ein einzelner Backlog‑Wert versteckt das eigentliche Problem: alte Arbeit. Nutzen Sie Aging‑Buckets, die dem Schmerz Ihres Teams entsprechen. Eine übliche Einteilung ist 0–2 Tage, 3–7, 8–14, 15+.
Ein gestapeltes Balkendiagramm pro Woche funktioniert gut, weil es zeigt, ob das Backlog älter wird, selbst wenn das Gesamtvolumen stabil bleibt. Wenn das 15+ Segment steigt, haben Sie ein Priorisierungs‑ oder Kapazitätsproblem, nicht nur „eine stressige Woche“.
SLA‑Compliance über Zeit (wöchentlich oder monatlich) beantwortet die Frage „Halten wir das Versprechen?“. Sie sagt aber nicht, was heute zu tun ist.
Koppeln Sie sie mit einer Breach‑Queue: der Anzahl offener Items, die noch innerhalb des SLA‑Fensters sind, aber kurz vor einer Verletzung stehen. Zum Beispiel zeigen Sie „Items, die in den nächsten 24 Stunden fällig sind“ und „bereits verletzt“ als zwei kleine Zähler neben dem Trend. Das macht Prozentwerte zu einer täglichen Aktionsliste.
Ein praktisches Szenario: Nach einem neuen Produkt‑Launch steigen Ankünfte. Der Durchsatz bleibt gleich, aber das Backlog‑Aging wächst in den 8–14 und 15+ Buckets. Gleichzeitig steigt die Breach‑Queue. Sie können sofort handeln: Arbeit umschichten, Intake einschränken oder Rufbereitschaft anpassen.
Eine Dashboard‑Spec sollte auf zwei Seiten passen: eine Seite für das, was Leute sehen, eine Seite für wie die Zahlen berechnet werden. Ist es länger, versucht es meist, zu viele Probleme gleichzeitig zu lösen.
Skizzieren Sie das Layout zuerst auf Papier. Für jedes Panel schreiben Sie eine tägliche Frage, die es beantworten muss. Wenn Sie die Frage nicht formulieren können, wird das Chart zu einer „schönen“ Metrik.
Eine einfache Struktur, die brauchbar bleibt:
Definieren Sie dann jede Metrik in einem Satz und listen Sie die Felder auf, die zur Berechnung nötig sind. Halten Sie Formeln explizit, wie: „Cycle Time ist closed_at minus started_at, gemessen in Stunden, exklusive Items im Waiting‑Status.“ Schreiben Sie die genauen Statuswerte, Datumsfelder und welche Tabelle/System die Quelle der Wahrheit ist.
Fügen Sie Schwellenwerte und Alerts hinzu, solange Sie noch schreiben, nicht erst nach dem Launch. Ein Chart ohne Aktion ist nur ein Report. Für jeden Schwellenwert geben Sie an:
Planen Sie Drill‑Down‑Pfade, damit man in unter einer Minute von Trend zur Ursache kommt. Ein praktischer Flow ist: Trendlinie (Woche) -> Queue‑Ansicht (heute) -> Item‑Liste (Top‑Offender) -> Item‑Detail (Historie und Owner). Ohne Drill‑Down zu einzelnen Items bekommen Sie Diskussionen statt Lösungen.
Validieren Sie vor dem Rollout mit drei echten Wochen historischer Daten. Wählen Sie eine ruhige und eine sehr hektische Woche. Prüfen Sie, ob Summen bekannten Ergebnissen entsprechen, und stichprobenartig 10 Items end‑to‑end, um Zeitstempel, Statusübergänge und Ausschlüsse zu bestätigen.
Ein Support‑Team releast am Montag ein großes Produkt‑Update. Bis Mittwoch stellen Kunden häufig dieselbe „Wie mache ich…“ Frage und melden ein paar neue Bugs. Das Team wirkt beschäftigter, aber niemand kann sagen, ob es eine temporäre Spitze oder eine SLA‑Katastrophe ist.
Ihr Dashboard ist simpel: eine Ansicht pro Queue (Billing, Bugs, How‑to). Es verfolgt Ankünfte (neue Tickets), Durchsatz (gelöste Tickets), Backlog‑Größe, Backlog‑Aging und SLA‑Risiko (wie viele Tickets voraussichtlich verletzen basierend auf Alter und verbleibender Zeit).
Nach dem Update zeigen die Metriken:
Das sieht nicht nach einem allgemeinen Performance‑Problem aus, sondern nach einem Routing‑ und Fokus‑Problem. Das Dashboard macht drei klare Entscheidungen sichtbar:
Sie wählen eine Mischung: einen zusätzlichen Agenten in Spitzenzeiten für How‑to, plus eine Standardantwort und einen kleinen Hilfeartikel.
Am nächsten Tag prüfen sie erneut. Der Durchsatz ist nicht dramatisch höher, aber die wichtigen Signale bewegen sich in die richtige Richtung. Backlog‑Aging stoppt das Wachstum und beginnt zu sinken. Das SLA‑Risiko fällt zuerst, echte Verletzungen folgen später. Die Ankünfte in How‑to gehen zurück, was bestätigt, dass die Root‑Cause‑Lösung geholfen hat.
Ein Dashboard soll helfen, die nächste Handlung zu entscheiden — nicht gestern gut aussehen zu lassen. Viele Teams enden mit vollen Charts, die Risiko verbergen.
Klassiker ist „Tickets diese Woche geschlossen“ allein gezeigt. Das kann steigen, während die Arbeit schlechter wird, weil es Ankünfte, Reopens und Aging ignoriert.
Achten Sie auf Muster wie:
Ein einfacher Fix: Kombinieren Sie jede Output‑Zahl mit einer Demand‑Zahl und einer Zeit‑Zahl. Z. B. closed vs created plus Median Cycle Time.
Der Durchschnitt der Lösungszeit ist ein schneller Weg, Kundenschmerz zu übersehen. Ein festhängender Fall von 20 Tagen kann unsichtbar bleiben, wenn der Durchschnitt durch viele schnelle Fälle gedrückt wird.
Nutzen Sie Mediane und Perzentile (p75 oder p90) zusammen mit einer Aging‑Ansicht. Wenn Sie nur eine Metrik wählen können, wählen Sie Median. Ergänzen Sie dann eine kleine Tabelle „schlimmste 10 offene Items nach Alter“, damit der Long Tail sichtbar bleibt.
Wenn Team A „done“ als „erste Antwort gesendet“ zählt und Team B „done“ als „vollständig gelöst“, entfachen Ihre Charts Diskussionen statt Entscheidungen. Schreiben Sie Definitionen in einfachen Worten und halten Sie sie konsistent: was die Uhr startet, was sie stoppt und was pausiert.
Ein realistisches Beispiel: Support führt einen Statuswechsel von „Warten auf Kunde“ zu „On hold“ ein, aber Engineering nutzt diesen Status nie. Die SLA‑Uhr pausiert für eine Gruppe und nicht für die andere, sodass die Führung „SLA verbessert“ sieht, während Kunden langsamere Lösungen erleben.
Filter helfen, aber ein Dashboard mit 12 Filtern und 20 Charts wird zur Choose‑Your‑Own‑Adventure. Wählen Sie eine klare Standardansicht (letzte 6–8 Wochen, alle Kunden, alle Kanäle) und machen Sie Ausnahmen bewusst.
Fehlende Zeitstempel, nachträglich eingefügte Statusänderungen und inkonsistente Statusnamen vergiften Ergebnisse still und leise. Validieren Sie Schlüssel‑Felder, bevor Sie mehr Charts bauen.
Bevor Sie es „fertig“ nennen, prüfen Sie, ob das Dashboard echte Fragen an einem hektischen Montagmorgen beantwortet. Gute Operations‑Dashboards helfen, Risiko früh zu erkennen, erklären, was sich geändert hat, und sagen, was als Nächstes zu tun ist.
Ein schneller One‑Screen‑Check:
Wenn eine Antwort „nein“ ist, machen Sie zuerst einen kleinen Fix. Oft reicht ein Vergleich zur Vorwoche, eine Aufteilung nach Priorität oder eine 7‑Tage‑Rollingsicht neben der Wochenansicht. Wenn Sie eine Verbesserung wählen müssen, wählen Sie die, die Überraschungen verhindert: Backlog‑Aging nach Priorität oder eine SLA‑Countdown‑Ansicht.
Verwandeln Sie die Checkliste in ein kurzes Spec, das jemand ohne Rätselraten umsetzen kann. Halten Sie es knapp und konzentrieren Sie sich auf Definitionen und Entscheidungsregeln.
Wenn Sie schnell den kompletten Workflow prototypen möchten (Datenmodell, Geschäftsregeln und Web‑Dashboard‑UI), hilft AppMaster (appmaster.io), komplette Anwendungen ohne Hand‑Coding zu erstellen und dabei echten Quellcode zu generieren. Wichtig ist: klein starten, ausliefern und nur solche Metriken hinzufügen, die Entscheidungen verändern.
Starten Sie mit den wiederkehrenden Entscheidungen Ihres Teams (Personalplanung, Prioritäten, Eskalation und Prozessverbesserungen) und wählen Sie dann die wenigen Kennzahlen, die diese Entscheidungen direkt unterstützen. Wenn eine Metrik nicht beeinflusst, was jemand als Nächstes tut, lassen Sie sie weg.
Verfolgen Sie drei Kernsignale zusammen: Durchsatz (was wirklich „done“ ist), Backlog mit Aging (was wartet und wie lange) und SLA‑Leistung (ob Versprechen eingehalten werden). Viele „wir sind in Ordnung“-Dashboards scheitern, weil sie Aktivität zeigen, aber kein Risiko.
Definieren Sie „done“ als den Moment, in dem die Arbeit Ihre Akzeptanzregel erfüllt — nicht einen Zwischenstatus wie „zur Prüfung gesendet“ oder „wartet auf jemanden“. Ist „done“ nicht konsistent, wirkt der Durchsatz besser als die Realität und Kapazitätsprobleme zeigen sich erst, wenn SLAs rutschen.
Nur die Backlog‑Größe ist irreführend, weil neue Arbeit sich ganz anders anfühlt als alte Arbeit. Fügen Sie mindestens ein Altersignal hinzu, etwa „Wie viele Elemente sind älter als X Tage“, damit Sie sehen, ob es eine vorübergehende Spitze oder ein wachsendes Nadelöhr ist.
SLA ist das Zeitversprechen, das Sie geben — typischerweise für erste Antwort, Lösung oder Zeit in wichtigen Status. Wählen Sie für jedes Versprechen eine klare Uhr (z. B. created→done oder started→done) und dokumentieren Sie, wann sie startet, wann sie stoppt und ob sie bei Blockaden pausiert.
Setzen Sie Ankünfte (neu erstellte Elemente) neben den Durchsatz auf dieselbe Zeitachse. Ein Durchsatz‑Abfall kann langsameres Arbeiten oder einfach weniger Ankünfte bedeuten; beides zu sehen verhindert Fehlschlüsse.
Verwenden Sie Mediane und Perzentile (z. B. p50 und p90) für zeitbasierte Kennzahlen. Durchschnitte werden von einigen Extremfällen verzerrt und verbergen oft den Long Tail, also den Bereich, in dem Kunden wirklich leiden.
Entscheiden Sie vorher, ob ein wiedereröffnetes Ticket als dasselbe Arbeitselement bleibt oder als neues zählt, und halten Sie diese Regel durch. Ein üblicher Kompromiss ist: Behalten Sie das gleiche Element bei, tracken Sie aber zusätzlich „Reopen‑Count“ oder „Rework‑Time“, damit Qualitätsprobleme sichtbar bleiben.
Aggregation verschleiert Probleme, wenn Buckets nicht zu Ihren Entscheidungen passen oder wenn Sie zu viel zusammenfassen. Nutzen Sie tägliche Ansichten für die operative Steuerung, wöchentliche für Trendchecks und nur monatliche Rollups für Planung — und prüfen Sie die Ergebnisse stichprobenartig an echten Fällen.
Erstellen Sie eine kurze Spezifikation: eine Seite für die Nutzeransicht und eine Seite für die genaue Berechnung der Kennzahlen, inklusive Status‑ und Zeitstempelregeln. Wenn Sie schnell prototypen wollen, kann AppMaster (appmaster.io) helfen, das Datenmodell, die Geschäftsregeln und eine Web‑Dashboard‑UI ohne Hand‑Coding zu modellieren, während echter Quellcode generiert wird.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


