Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Lang laufende Workflows können aufwändige Fehler verursachen. Lernen Sie klare Zustandsmuster, Retry-Zähler, Dead-Letter-Verarbeitung und Dashboards, denen Operatoren vertrauen können.
Lang laufende Workflows scheitern anders als kurze Anfragen. Ein kurzer API-Aufruf gelingt entweder sofort oder liefert sofort einen Fehler. Ein Workflow, der Stunden oder Tage läuft, kann 9 von 10 Schritten schaffen und trotzdem ein Chaos hinterlassen: halb erstellte Datensätze, verwirrende Stati und keine klare nächste Aktion.
Deshalb hört man so oft „es hat gestern noch funktioniert“. Der Workflow hat sich nicht geändert, aber seine Umgebung schon. Lang laufende Workflows sind davon abhängig, dass andere Dienste gesund bleiben, Zugangsdaten gültig bleiben und Daten weiterhin die Form haben, die der Workflow erwartet.
Die häufigsten Ausfallarten sehen so aus: Timeouts und langsame Abhängigkeiten (eine Partner-API ist erreichbar, braucht aber heute 40 Sekunden), partielle Updates (Datensatz A erstellt, Datensatz B nicht erstellt, und ein erneutes Ausführen ist nicht sicher), Ausfälle von Abhängigkeiten (E-Mail/SMS-Anbieter, Zahlungs-Gateways, Wartungsfenster), verlorene Callbacks und verpasste Zeitpläne (ein Webhook kommt nie an, ein Timer-Job lief nicht), und menschliche Schritte, die ins Stocken geraten (eine Genehmigung liegt Tage, dann wird sie mit veralteten Annahmen fortgesetzt).
Das Schwierige ist der Zustand. Eine „kurze Anfrage“ kann den Zustand im Speicher halten, bis sie fertig ist. Ein Workflow kann das nicht. Er muss Zustand zwischen Schritten persistieren und bereit sein, nach Neustarts, Deployments oder Abstürzen weiterzumachen. Außerdem muss er damit umgehen können, dass derselbe Schritt zweimal ausgelöst wird (Retries, doppelte Webhooks, Operator-Replays).
In der Praxis bedeutet „zuverlässig“ weniger, nie zu scheitern, sondern vorhersehbar, erklärbar, wiederherstellbar und klar im Besitz zu sein.
Vorhersehbar heißt: Der Workflow reagiert jedes Mal gleich, wenn eine Abhängigkeit ausfällt. Erklärbar heißt: Ein Operator kann in einer Minute beantworten: „Wo steckt es und warum?“ Wiederherstellbar heißt: Sie können sicher erneut versuchen oder weitermachen, ohne Schaden anzurichten. Klare Zuständigkeit heißt: Jedes feststeckende Item hat eine offensichtliche nächste Aktion: warten, retryen, Daten reparieren oder an eine Person weiterleiten.
Ein einfaches Beispiel: Eine Onboarding-Automation erstellt einen Kunden, richtet Zugänge ein und sendet eine Willkommensnachricht. Wenn die Einrichtung klappt, aber die Nachricht an einen ausgefallenen E-Mail-Anbieter scheitert, dokumentiert ein zuverlässiger Workflow „Provisioniert, Nachricht ausstehend“ und plant einen Retry. Er wiederholt nicht blind die Provisionierung.
Werkzeuge können das erleichtern, wenn Workflow-Logik und persistente Daten nah beieinander liegen. Bei AppMaster können Sie Workflow-Zustände im Data Designer modellieren und über Business Processes aktualisieren. Die Zuverlässigkeit kommt aber vom Muster, nicht vom Tool: Behandeln Sie lang laufende Automatisierung als eine Folge langlebiger Zustände, die Zeit, Ausfälle und menschliche Eingriffe überdauern.
Lang laufende Workflows scheitern oft auf wiederkehrende Weise: eine Drittanbieter-API wird langsam, ein Mensch hat nicht genehmigt oder ein Job hängt in einer Queue. Klare Zustände machen diese Situationen offensichtlich, damit Leute „nimmt Zeit“ nicht mit „kaputt“ verwechseln.
Beginnen Sie mit einer kleinen Menge an Zuständen, die eine Frage beantworten: Was passiert gerade? Bei 30 Zuständen merkt sich niemand mehr den Überblick. Mit etwa 5 bis 8 kann eine zuständige Person die Liste überfliegen und verstehen.
Ein praktisches Zustands-Set, das für viele Workflows funktioniert:
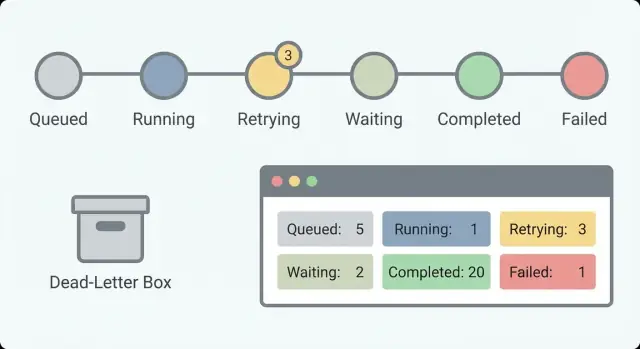
Queued (erstellt, aber noch nicht gestartet)Running (führt aktiv Arbeit aus)Waiting (gestoppt wegen Timer, Callback oder menschlicher Eingabe)Succeeded (abgeschlossen)Failed (mit Fehler gestoppt)Die Trennung von Waiting und Running ist wichtig. „Warten auf Kundenantwort“ ist gesund. „Läuft seit 6 Stunden“ könnte ein Hänger sein. Ohne diese Trennung jagen Sie falschen Alarmen nach und verpassen echte.
Ein Zustandsname allein reicht nicht. Fügen Sie ein paar Felder hinzu, die einen Status handlungsfähig machen:
Beispiel: Ein Onboarding-Flow könnte „Waiting“ mit dem Grund „Ausstehende Manager-Genehmigung“ und zuletzt geändert „vor 2 Tagen“ zeigen. Das sagt: Es hängt nicht, es braucht evtl. eine Erinnerung.
Behandeln Sie Zustandsnamen wie eine API. Wenn Sie sie jeden Monat umbenennen, werden Dashboards, Alerts und Support-Playbooks schnell irreführend. Wenn Sie neue Bedeutung brauchen, führen Sie besser einen neuen Zustand ein und lassen den alten für bestehende Datensätze bestehen.
In AppMaster können Sie diese Zustände im Data Designer modellieren und aus Business Process-Logik heraus aktualisieren. So bleibt der Status sichtbar und konsistent in Ihrer App, statt in Logs versteckt zu sein.
Retries helfen, bis sie das eigentliche Problem verbergen. Das Ziel ist nicht „nie scheitern“, sondern „so scheitern, dass Menschen es verstehen und beheben können“. Das beginnt mit einer klaren Regel, welche Fehler retrybar sind und welche nicht.
Eine Regel, mit der die meisten Teams leben können: Retryen Sie Fehler, die wahrscheinlich temporär sind (Netzwerk-Timeouts, Rate-Limits, kurzfristige Drittanbieter-Ausfälle). Retryen Sie nicht bei eindeutig permanenten Fehlern (ungültige Eingabe, fehlende Berechtigungen, „Konto gesperrt“, „Karte abgelehnt“). Wenn Sie nicht sagen können, in welche Kategorie ein Fehler gehört, behandeln Sie ihn zunächst als nicht-retrybar, bis Sie mehr wissen.
Verfolgen Sie Retry-Zähler pro Schritt (oder pro externem Aufruf), nicht nur einen Zähler für den gesamten Workflow. Ein Workflow kann zehn Schritte haben, und nur einer davon ist fehlerhaft. Schritt-spezifische Zähler verhindern, dass ein späterer Schritt Versuche eines früheren „stiehlt“.
Zum Beispiel darf ein „Dokument hochladen“-Aufruf ein paar Mal wiederholt werden, während „Willkommens-E-Mail senden“ nicht ewig weiterretryen sollte, nur weil das Hochladen zuvor Versuche verbraucht hat.
Wählen Sie ein Backoff-Muster, das zum Risiko passt. Feste Verzögerungen sind für einfache, kostengünstige Retries in Ordnung. Exponentielles Backoff hilft bei Rate-Limits. Setzen Sie eine Obergrenze, damit Wartezeiten nicht unendlich wachsen, und fügen Sie etwas Jitter hinzu, um Retry-Stürme zu vermeiden.
Dann entscheiden Sie, wann aufgehört wird. Gute Abbruchbedingungen sind explizit: maximale Versuche, maximale Gesamtzeit oder „bei bestimmten Fehlercodes aufgeben“. Ein Payment-Gateway, das „ungültige Karte“ zurückgibt, sollte sofort stoppen, auch wenn Sie normalerweise fünf Versuche erlauben.
Operatoren müssen außerdem wissen, was als Nächstes passiert. Speichern Sie die nächste Retry-Zeit und den Grund (z. B. „Retry 3/5 um 14:32 wegen Timeout“). In AppMaster können Sie das auf dem Workflow-Datensatz speichern, sodass ein Dashboard „wartet bis“ anzeigen kann, ohne zu raten.
Eine gute Retry-Policy hinterlässt eine Spur: was fehlgeschlagen ist, wie oft versucht wurde, wann der nächste Versuch geplant ist und wann aufgehört und an die Dead-Letter-Verarbeitung übergeben wird.
Bei Workflows, die Stunden oder Tage laufen, sind Retries normal. Das Risiko ist, einen Schritt zu wiederholen, der bereits erfolgreich war. Idempotenz macht das sicher: Ein Schritt ist idempotent, wenn zweimaliges Ausführen den gleichen Effekt hat wie einmal.
Ein klassisches Problem: Sie belasten eine Karte, dann stürzt der Workflow ab, bevor „Zahlung erfolgreich“ gespeichert wird. Beim Retry wird erneut belastet. Das ist ein Double-Write-Problem: Die Außenwelt hat sich geändert, aber der Workflow-Zustand nicht.
Das sicherste Muster ist, für jeden nebenwirkenden Schritt einen stabilen Idempotency-Key zu erzeugen, ihn mit dem externen Aufruf zu senden und das Schritt-Ergebnis sofort zu speichern. Viele Zahlungsanbieter und Webhook-Empfänger unterstützen Idempotency-Keys (z. B. Belastung nach OrderID). Wiederholungen liefern dann das ursprüngliche Ergebnis statt die Aktion erneut auszuführen.
Innerhalb Ihrer Workflow-Engine gehen Sie davon aus, dass jeder Schritt wiedergegeben werden kann. In AppMaster bedeutet das oft, Schritt-Ausgaben in Ihrem Datenmodell zu speichern und in der Business Process-Logik vor einem Integrationsaufruf zu prüfen. Wenn „Willkommens-E-Mail senden“ bereits eine MessageID gespeichert hat, sollte ein Retry diese nutzen und weitermachen.
Ein praktischer, Duplikat-sicherer Ansatz:
Duplikate werden trotzdem vorkommen, besonders bei eingehenden Webhooks oder wenn ein Benutzer zweimal den selben Button drückt. Legen Sie die Policy pro Ereignistyp fest: exakte Duplikate ignorieren (gleicher Idempotency-Key), kompatible Updates zusammenführen (z. B. last-write-wins für ein Profilfeld) oder bei Geld/Compliance-Risiko zur Prüfung markieren.
Ein Dead-Letter ist ein Workflow-Item, das fehlgeschlagen ist und absichtlich aus dem normalen Pfad genommen wurde, damit es nicht alles blockiert. Ziel ist, leicht zu erkennen, was passiert ist, ob es reparierbar ist und wie man es sicher erneut verarbeitet.
Der größte Fehler ist, nur eine Fehlermeldung zu speichern. Später braucht die Person, die das Dead-Letter betrachtet, genug Kontext, um das Problem zu reproduzieren, ohne raten zu müssen.
Ein nützlicher Dead-Letter-Eintrag enthält:
Klassifikation macht Dead-Letter handlungsfähig. Eine kurze Kategorie hilft Operatoren, die richtige Maßnahme zu wählen. Übliche Gruppen sind: permanenter Fehler (Logikfehler, ungültiger Zustand), Datenproblem (fehlendes Feld, falsches Format), Abhängigkeit down (Timeout, Rate-Limit, Ausfall) und Auth/Permission (abgelaufener Token, abgelehnte Credentials).
Das Nachbearbeiten sollte kontrolliert erfolgen. Ziel ist, wiederholten Schaden zu vermeiden, z. B. doppelte Abbuchungen oder Spam. Definieren Sie Regeln, wer retryen darf, wann, was geändert werden darf (bestimmte Felder editieren, fehlendes Dokument anhängen, Token auffrischen) und was fest bleiben muss (Request-ID und downstream Idempotency-Keys).
Machen Sie Dead-Letter-Items durchsuchbar über stabile Identifikatoren. Wenn ein Operator „Order 18422“ eintippt und genau Schritt, Eingaben und Versuchshistorie sieht, werden Fixes schnell und konsistent.
Wenn Sie das in AppMaster bauen, behandeln Sie das Dead-Letter als erstes Datenmodell und speichern Zustand, Versuche und Identifikatoren als Felder. So kann Ihr internes Dashboard abfragen, filtern und eine kontrollierte Reprocess-Aktion auslösen.
Lang laufende Workflows können langsam und verwirrend scheitern: ein Schritt wartet auf eine E-Mail-Antwort, ein Zahlungsanbieter timet out oder ein Webhook kommt doppelt. Wenn Sie nicht sehen können, was der Workflow gerade macht, geraten Sie ins Raten. Gute Sichtbarkeit verwandelt „es ist kaputt“ in eine klare Antwort: Welcher Workflow, welcher Schritt, welcher Zustand und was ist die nächste sichere Aktion.
Beginnen Sie damit, dass jeder Schritt dasselbe kleine Set an Feldern emittiert, damit Operatoren schnell überblicken können:
Diese Felder unterstützen Basis-Metriken, die Gesundheit auf einen Blick zeigen. Bei lang laufenden Workflows zählen Zahlen mehr als einzelne Fehler, weil Sie nach Trends suchen: Arbeit, die sich anhäuft, steigende Retry-Raten oder Wartezeiten, die nie enden.
Verfolgen Sie gestartet, abgeschlossen, fehlgeschlagen, retrying und waiting über die Zeit. Eine kleine Zahl in Waiting kann normal sein (menschliche Genehmigungen). Eine steigende Waiting-Zahl deutet oft auf Blockaden hin. Ein ansteigender Retry-Count weist meist auf ein Provider-Problem oder einen wiederholbaren Bug hin.
Alarme sollten zu dem passen, was Operatoren erleben. Statt „Fehler aufgetreten“, alarmieren Sie bei Symptomen: wachsender Rückstau (gestartet minus abgeschlossen steigt), zu viele Workflows in Waiting länger als erwartet, hohe Retry-Rate für einen bestimmten Schritt oder ein Fehleranstieg direkt nach einem Release oder einer Konfig-Änderung.
Führen Sie eine Ereignis-Spur für jeden Workflow, damit „was ist passiert?“ in einer Ansicht beantwortet werden kann. Eine nützliche Spur enthält Zeitstempel, Zustandsübergänge, Zusammenfassungen von Eingaben und Ausgaben (nicht komplette sensitive Payloads) und den Grund für Retries oder Fehler. Beispiel: „Charge card: retry 3/5, Timeout vom Provider, nächster Versuch in 10m."
Korrelations-IDs sind der Klebstoff. Wenn ein Kunde sagt „meine Zahlung wurde zweimal belastet“, müssen Sie Ihre Workflow-Events mit der Charge-ID des Zahlungsanbieters und Ihrer internen Order-ID verbinden. In AppMaster können Sie das in Business Process-Logik standardisieren, indem Sie Korrelations-IDs erzeugen und durch API-Aufrufe und Messaging-Schritte mitgeben, sodass Dashboard und Logs zusammenpassen.
Wenn ein Workflow Stunden oder Tage läuft, sind Fehler normal. Was normale Fehler zu Ausfällen macht, ist ein Dashboard, das nur „Failed“ anzeigt und sonst nichts. Ziel ist, dass ein Operator drei Fragen schnell beantworten kann: Was passiert, warum passiert es und was kann ich sicher als Nächstes tun?
Beginnen Sie mit einer Workflow-Liste, die es einfach macht, die wenigen relevanten Items zu finden. Filter reduzieren Panik und unnötige Chats, weil jeder die Ansicht schnell eingrenzen kann.
Nützliche Filter sind Zustand, Alter (Startzeit und Zeit im aktuellen Zustand), Besitzer (Team/Kunde/verantwortlicher Operator), Typ (Workflow-Name/Version) und Priorität bei kundensichtigen Schritten.
Zeigen Sie als Nächstes das „Warum“ neben dem Status, statt es in Logs zu verstecken. Ein Status-Pill hilft nur, wenn er mit der letzten Fehlermeldung, einer kurzen Fehlerkategorie und dem, was das System als Nächstes plant, gepaart ist. Zwei Felder erledigen den Großteil: letzte Fehlermeldung und nächste Retry-Zeit. Wenn nächste Retry-Zeit leer ist, machen Sie deutlich, ob der Workflow auf einen Menschen wartet, pausiert ist oder dauerhaft fehlgeschlagen ist.
Operator-Aktionen sollten standardmäßig sicher sein. Leiten Sie Leute zu risikoarmen Aktionen und machen Sie riskante Aktionen explizit:
„Forced continue“ ist der Ort, an dem die meisten Schäden passieren. Wenn Sie es anbieten, formulieren Sie das Risiko klar: „Dies überspringt die Zahlungsprüfung und kann zu unbezahlten Bestellungen führen.“ Zeigen Sie auch, welche Daten geschrieben werden, falls es weitergeht.
Protokollieren Sie alles, was Operatoren tun. Speichern Sie wer, wann, den Vorher/Nachher-Zustand und die Begründung. Wenn Sie interne Tools in AppMaster bauen, speichern Sie dieses Audit als erste Klasse Tabelle und zeigen es auf der Workflow-Detailseite an, damit Übergaben sauber bleiben.
Dieses Muster hält Workflows vorhersehbar: Jedes Item ist immer in einem klaren Zustand, jeder Fehler hat eine Route, und Operatoren können handeln, ohne zu raten.
Schritt 1: Definieren Sie Zustände und erlaubte Übergänge. Schreiben Sie ein kleines Set von Zuständen auf, die eine Person verstehen kann (z. B. Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter). Entscheiden Sie dann, welche Übergänge legal sind, damit Arbeit nicht ins Leere driftet.
Schritt 2: Zerlegen Sie Arbeit in kleine Schritte mit klaren Eingaben und Ausgaben. Jeder Schritt sollte eine klar definierte Eingabe annehmen und genau eine Ausgabe produzieren (oder einen klaren Fehler). Wenn Sie eine menschliche Entscheidung oder einen externen API-Aufruf brauchen, machen Sie das zu einem eigenen Schritt, damit er sauber pausieren und fortsetzen kann.
Schritt 3: Fügen Sie pro Schritt eine Retry-Policy hinzu. Wählen Sie Limit für Versuche, Verzögerung zwischen Versuchen und Abbruchgründe, die niemals retryen sollen (ungültige Daten, permission denied, fehlende Felder). Speichern Sie einen Retry-Zähler pro Schritt, damit Operatoren genau sehen, was hängt.
Schritt 4: Persistieren Sie den Fortschritt nach jedem Schritt. Nach Abschluss eines Schritts speichern Sie den neuen Zustand plus Schlüssel-Ausgaben. Bei Neustart soll der Prozess vom letzten abgeschlossenen Schritt weitermachen, nicht neu beginnen.
Schritt 5: Route in ein Dead-Letter und unterstützen Sie Reprocessing. Wenn Retries erschöpft sind, verschieben Sie das Item in einen Dead-Letter-Zustand und bewahren Sie vollen Kontext auf: Eingaben, letzte Fehlermeldung, Schrittname, Versuchszähler und Zeitstempel. Reprocessing sollte bewusst erfolgen: Daten oder Konfiguration korrigieren, dann gezielt von einem bestimmten Schritt neu anstellen.
Schritt 6: Definieren Sie Dashboard-Felder und Operator-Aktionen. Ein gutes Dashboard beantwortet „was ist fehlgeschlagen, wo und was kann ich als Nächstes tun?“ In AppMaster können Sie das als einfaches Admin-Web-App bauen, das auf Ihren Workflow-Tabellen aufsetzt.
Wichtige Felder und Aktionen:
Employee-Onboarding ist ein guter Belastungstest. Es mischt Genehmigungen, externe Systeme und Menschen, die offline sein können. Ein einfacher Ablauf: HR füllt ein New-Hire-Formular aus, der Manager genehmigt, IT-Konten werden erstellt und der neue Mitarbeiter erhält eine Willkommensnachricht.
Machen Sie Zustände lesbar. Wenn jemand den Eintrag öffnet, sollte sofort der Unterschied zwischen „Warten auf Genehmigung“ und „Retrying Account Setup“ sichtbar sein. Eine einzige Klarstellung kann eine Stunde Rätselraten sparen.
Ein klares Set an Zuständen für die UI:
Retries gehören auf Schritte, die von Netzwerken oder Drittanbieter-APIs abhängen. Account-Provisioning (E-Mail, SSO, Slack), E-Mail/SMS-Versand und interne API-Aufrufe sind gute Retry-Kandidaten. Halten Sie den Retry-Zähler sichtbar und begrenzen Sie ihn (z. B. bis zu fünf Versuche mit wachsender Verzögerung, dann stoppen).
Dead-Letter ist für Probleme, die sich nicht von selbst lösen: kein Manager im Formular, ungültige E-Mail-Adresse oder ein Zugriffsantrag, der mit Richtlinien kollidiert. Wenn Sie einen Lauf dead-lettern, speichern Sie Kontext: welches Feld die Validierung nicht bestand, die letzte API-Antwort und wer eine Override-Genehmigung erteilen kann.
Operatoren sollten eine kleine Menge klarer Aktionen haben: Daten korrigieren (Manager hinzufügen, E-Mail berichtigen), einen einzelnen fehlgeschlagenen Schritt neu ausführen (nicht den ganzen Workflow) oder sauber abbrechen (und Teil-Setups ggf. rückgängig machen).
Mit AppMaster können Sie das im Business Process Editor modellieren, Retry-Zähler in Daten halten und einen Operator-Bildschirm im Web-UI-Builder erstellen, der Zustand, letzte Fehlermeldung und einen Button zum Retry des fehlgeschlagenen Schritts zeigt.
Die meisten Zuverlässigkeitsprobleme sind vorhersehbar: ein Schritt läuft zweimal, Retries drehen sich um 2 Uhr morgens, oder ein „festhängendes" Item hat keine Ahnung, was zuletzt passiert ist. Eine Checkliste verhindert, dass daraus Rätselraten wird.
Kurze Prüfungen, die die meisten Probleme früh auffangen:
Wenn Sie nur eine Sache verbessern können: verbessern Sie die Sichtbarkeit. Viele „Workflow-Bugs" sind eigentlich „wir können nicht sehen, was es tut". Ihr Dashboard sollte zeigen, was zuletzt passiert ist, was als Nächstes passieren wird und wann.
Eine praktische Operator-Ansicht enthält aktuellen Zustand, letzte Fehlermeldung, Attempt-Count, nächste Retry-Zeit und eine klare Aktion (jetzt retryen, als gelöst markieren oder zur manuellen Prüfung schicken). Halten Sie Aktionen standardmäßig sicher: Führen Sie einen einzelnen Schritt erneut aus, nicht den ganzen Workflow.
Nächste Schritte:
Behandeln Sie das als lebendige Checkliste. Jedes Mal, wenn Sie einen neuen Schritt hinzufügen, prüfen Sie diese Punkte, bevor er in Produktion geht.
Lang laufende Workflows können erst nach Stunden scheitern und dabei nur teilweise Änderungen hinterlassen. Außerdem hängen sie von Dingen ab, die sich während der Ausführung ändern können, etwa Drittanbieter-Verfügbarkeit, Zugangsdaten, Datenformate oder menschliche Reaktionszeiten.
Halten Sie die Zustandsmenge klein und verständlich, damit ein Operator sie auf einen Blick begreift. Ein gutes Standard-Set ist etwa: queued, running, waiting, succeeded und failed — wobei „waiting“ klar von „running“ getrennt sein sollte, damit gesunde Pausen nicht als Hänger gewertet werden.
Speichern Sie genug, damit der Status handlungsfähig wird: aktuellen Zustand, Zeitpunkt der letzten Änderung, vorherigen Zustand und eine kurze Begründung, wenn gewartet oder fehlgeschlagen wird. Bei Retries sollten auch Zähler und die geplante nächste Retry-Zeit sichtbar sein.
Es verhindert falsche Alarme und verpasste Vorfälle. „Warten auf Genehmigung“ kann völlig normal sein, während „läuft seit sechs Stunden“ ein Hänger sein könnte. Die Trennung verbessert Alarme und Entscheidungen des Operators.
Retryen Sie Fehler, die wahrscheinlich temporär sind: Timeouts, Rate-Limits, kurzzeitige Ausfälle. Nicht retryen sollten Sie klar permanente Fehler wie ungültige Eingaben, fehlende Berechtigungen oder abgelehnte Zahlungen, denn wiederholte Versuche nützen nichts und können Schaden anrichten.
Retry-Zähler pro Schritt verhindern, dass ein fehleranfälliger Schritt alle Versuche des gesamten Workflows aufbraucht. Außerdem erleichtern sie die Diagnose: Sie sehen genau, welcher Schritt wie oft versucht wurde und ob andere Schritte unbeeinflusst sind.
Wählen Sie ein Backoff-Muster, das zum Risiko passt, und setzen Sie immer eine Obergrenze, damit Wartezeiten nicht ins Unendliche wachsen. Haltepunkte sollten explizit sein (maximale Versuche, maximale Gesamtzeit oder bestimmte Fehlercodes). Notieren Sie Grund und nächste Retry-Zeit, damit klar ist, wer zuständig ist.
Gehen Sie davon aus, dass jeder Schritt mehrfach ausgeführt werden kann. Nutzen Sie stabile Idempotency-Keys pro nebenwirkendem Schritt, schreiben Sie vor dem externen Aufruf ein „step started“-Protokoll und speichern Sie das Ergebnis sofort, damit Wiederholungen das Ergebnis wiederverwenden statt die Aktion zu wiederholen.
Ein Dead-Letter-Eintrag ist ein Workflow-Item, das nach erschöpften Retries bewusst aus dem normalen Pfad genommen wird. Speichern Sie genug Kontext, um das Problem später reproduzieren oder sicher nachbearbeiten zu können: IDs, Eingaben (oder sichere Snapshots), wo es fehlgeschlagen ist, Retry-Historie und die Antwort des Abhängigkeits-Systems — nicht nur eine vage Fehlermeldung.
Schnell nutzbare Dashboards zeigen, wo es steht, warum es dort ist und was als Nächstes passiert. Konsistente Felder sind z. B. Workflow-ID, aktueller Schritt, Zustand, Verweildauer im Zustand, letzte Fehlermeldung und Korrelations-IDs. Operatoren sollten sichere Standardaktionen haben, wie einen einzelnen Schritt erneut ausführen oder pausieren, während riskante Aktionen deutlich gekennzeichnet sind.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


