Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Lerne, wie man einen Integrations‑Hub so gestaltet, dass Zugangsdaten zentral verwaltet, Sync‑Zustände sichtbar gemacht und Fehler konsistent gehandhabt werden, während dein SaaS‑Stack auf viele Dienste wächst.
Ein SaaS‑Stack beginnt oft einfach: ein CRM, ein Abrechnungstool, ein Support‑Postfach. Dann kommen Marketing‑Automatisierung, ein Data Warehouse, ein zweiter Support‑Kanal und ein paar Nischen‑Tools dazu, die „nur schnell synchronisiert werden müssen“. Bald hast du ein Netz von Punkt‑zu‑Punkt‑Verbindungen, das niemand vollständig besitzt.
Was zuerst kaputtgeht, sind selten die Daten. Es ist der Klebstoff darum herum.
Zugangsdaten liegen verstreut in persönlichen Konten, geteilten Tabellen und zufälligen Umgebungsvariablen. Tokens laufen ab, Leute gehen, und plötzlich hängt „die Integration" an einem Login, den niemand mehr findet. Selbst wenn Security ordentlich gehandhabt wird, macht das Rotieren von Geheimnissen Mühe, weil jede Verbindung ihre eigene Einrichtung und ihren eigenen Ort zum Aktualisieren hat.
Als Nächstes bricht die Sichtbarkeit zusammen. Jede Integration meldet Status anders (oder überhaupt nicht). Ein Tool sagt „connected“, während es stillschweigend nicht synchronisiert. Ein anderes verschickt vage E‑Mails, die ignoriert werden. Wenn ein Sales‑Mitarbeiter fragt, warum ein Kunde nicht provisioniert wurde, wird die Antwort zu einer Schatzsuche in Logs, Dashboards und Chat‑Threads.
Die Support‑Last steigt schnell, weil Fehler schwer zu diagnostizieren und leicht zu wiederholen sind. Kleine Probleme wie Ratenbegrenzungen, Schemaänderungen und partielle Retries werden zu langen Incidents, wenn niemand den kompletten Weg vom „Event passiert“ bis „Daten angekommen“ sehen kann.
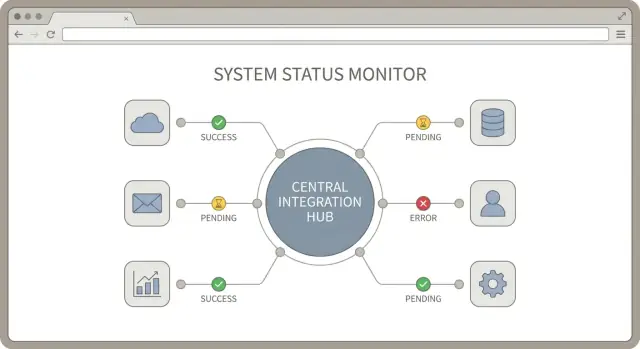
Ein Integrations‑Hub ist eine einfache Idee: ein zentraler Ort, an dem deine Verbindungen zu Drittanbietern verwaltet, überwacht und unterstützt werden. Gutes Hub‑Design schafft konsistente Regeln dafür, wie Integrationen authentifizieren, wie sie ihren Sync‑Status melden und wie Fehler behandelt werden.
Ein praktischer Hub zielt auf vier Ergebnisse ab: weniger Ausfälle (geteilte Retry‑ und Validierungsmuster), schnellere Behebung (einfaches Tracing), sichererer Zugriff (zentrale Besitzverhältnisse für Credentials) und geringerer Support‑Aufwand (standardisierte Alerts und Nachrichten).
Wenn du deinen Stack auf einer Plattform wie AppMaster aufbaust, ist das Ziel dasselbe: die Integrations‑Betriebsabläufe so einfach halten, dass eine nicht‑spezialisierte Person versteht, was passiert, und ein Spezialist es schnell beheben kann, wenn nicht.
Bevor du große Integrationsentscheidungen triffst, verschaffe dir ein klares Bild dessen, was du bereits verbunden hast (oder verbinden willst). Diesen Schritt überspringen Leute oft, und er sorgt später für Überraschungen.
Beginne damit, jeden Drittanbieter in deinem Stack aufzulisten, sogar die „kleinen“. Füge hinzu, wer ihn besitzt (Person oder Team) und ob er live, geplant oder experimentell ist.
Trenne dann Integrationen, die Kunden sehen, von Hintergrundautomationen. Eine nutzerorientierte Integration könnte „Verbinde dein Salesforce‑Konto“ sein. Eine interne Automation könnte lauten: „Wenn eine Rechnung in Stripe bezahlt wird, markiere den Kunden in der Datenbank als aktiv.“ Diese haben unterschiedliche Zuverlässigkeitserwartungen und fallen unterschiedlich aus.
Mappe anschließend die Datenflüsse, indem du eine Frage stellst: Wer braucht die Daten, um seine Arbeit zu tun? Product braucht eventuell Usage‑Events fürs Onboarding. Ops benötigt Account‑Status und Provisioning. Finance braucht Rechnungen, Rückerstattungen und Steuerfelder. Support braucht Tickets, Gesprächshistorie und Identitätsabgleiche. Diese Anforderungen formen deinen Integrations‑Hub stärker als Vendor‑APIs.
Setze schließlich Erwartungen an die Zeitlichkeit für jeden Flow:
Beispiel: „Bezahlte Rechnung" braucht für Zugriffskontrolle möglicherweise nahezu Echtzeit, für Finanzzusammenfassungen reicht täglich. Zeichne das früh auf, dann lassen sich Monitoring und Fehlerbehandlung leichter standardisieren.
Gutes Hub‑Design beginnt mit klaren Grenzen. Versucht der Hub, alles zu tun, wird er zur Engstelle. Tut er zu wenig, entstehen dutzende Ein‑Off‑Skripte, die unterschiedlich funktionieren.
Schreibe auf, was der Hub besitzt und was nicht. Eine praktische Aufteilung ist:
Wähle einen Einstiegspunkt für alle Integrationen und halte dich daran. Das kann eine API sein (andere Systeme rufen den Hub auf) oder ein Job‑Runner (der Hub führt geplante Pulls/Pushes aus). Beide zu nutzen ist in Ordnung, aber nur wenn sie dieselbe interne Pipeline teilen, damit Retries, Logging und Alerts einheitlich funktionieren.
Einige Entscheidungen halten den Hub fokussiert: standardisiere, wie Integrationen ausgelöst werden (Webhook, Zeitplan, manuelles Neulaufen), einigt euch auf eine Grenz‑Payload‑Form (auch wenn Partner unterschiedlich sind), entscheidet, was ihr persistiert (Raw Events, normalisierte Datensätze, beides oder keines), definiert, was „fertig“ heißt (akzeptiert, geliefert, bestätigt) und weise Ownership für partner‑spezifische Sonderfälle zu.
Entscheide, wo Transformationen stattfinden. Normierst du Daten im Hub, bleiben Downstream‑Services einfacher, aber der Hub benötigt stärkere Versionierung und Tests. Hältst du den Hub schlank und leitest rohe Partner‑Payloads weiter, muss jedes Downstream‑System jedes Partnerformat verstehen. Viele Teams finden einen Mittelweg: nur gemeinsame Felder normalisieren (IDs, Timestamps, Basis‑Status) und Domain‑Regeln downstream lassen.
Plane Multi‑Tenant von Anfang an. Entscheide, ob die Isolationseinheit ein Kunde, Workspace oder eine Organisation ist. Diese Wahl beeinflusst Ratenbegrenzungen, Credential‑Speicherung und Backfills. Wenn das Salesforce‑Token eines Kunden abläuft, solltest du nur die Jobs dieses Tenants pausieren, nicht die gesamte Pipeline. Werkzeuge wie AppMaster helfen, Tenants und Workflows visuell zu modellieren, aber die Grenzen müssen explizit vor dem Bau festgelegt werden.
Ein Credential‑Vault kann dein Leben beruhigen oder zu dauerhaftem Incident‑Risiko werden. Ziel ist simpel: ein Ort, um Zugänge zu speichern, ohne jedem System und Teammitglied mehr Macht zu geben, als nötig.
OAuth und API‑Keys tauchen an verschiedenen Stellen auf. OAuth ist üblich bei nutzerzentrierten Apps wie Google, Slack, Microsoft und vielen CRMs. Ein Nutzer genehmigt den Zugriff, und du speicherst ein Access‑Token plus Refresh‑Token. API‑Keys sind häufiger für Server‑zu‑Server‑Tools und ältere APIs. Sie können langlebig sein, weshalb sichere Speicherung und Rotation noch wichtiger sind.
Speichere alles verschlüsselt und scope es zum richtigen Tenant. In einem multi‑kunden Produkt behandelst du Credentials als Kundendaten. Halte strikte Isolation, so dass ein Token von Tenant A niemals für Tenant B benutzt werden kann — auch nicht versehentlich. Speichere außerdem Metadaten, die du später brauchst: zu welcher Verbindung es gehört, wann es abläuft und welche Berechtigungen gewährt wurden.
Praktische Regeln, die die meisten Probleme verhindern:
Plane Refresh und Widerruf, ohne den Sync zu brechen. Bei OAuth sollte Refresh automatisch im Hintergrund passieren; dein Hub sollte „token expired“ durch einmaliges Refreshen und sicheres Retry handhaben. Bei Widerruf (ein Nutzer trennt, ein Security‑Team deaktiviert eine App oder Scopes ändern sich) stoppe den Sync, markiere die Verbindung als needs_auth und führe eine klare Audit‑Spur darüber, was passiert ist.
Wenn du deinen Hub in AppMaster baust, behandle Credentials als geschütztes Datenmodell, halte Zugriff in backend‑only Logik und zeige der UI nur verbunden/getrennt. Operatoren können eine Verbindung reparieren, ohne das Geheimnis je zu sehen.
Wenn du viele Tools verbindest, wird „funktioniert es?“ zur täglichen Frage. Die Lösung sind nicht mehr Logs, sondern eine kleine, konsistente Menge an Sync‑Signalen, die bei jeder Integration gleich aussehen. Gutes Hub‑Design behandelt Status als erstklassiges Feature.
Beginne mit einer kurzen Liste von Verbindungszuständen und verwende sie überall: in der Admin‑UI, in Alerts und in Support‑Notizen. Halte die Namen verständlich, damit ein nicht‑technischer Kollege handeln kann.
Verfolge drei Zeitstempel pro Verbindung: letzter Sync‑Start, letzte erfolgreiche Sync‑Zeit und Zeit des letzten Fehlers. Sie erzählen schnell eine Story, ohne zu graben.
Eine kleine per‑Integration‑Ansicht hilft dem Support, schnell zu handeln. Jede Verbindungsseite sollte den aktuellen Zustand, diese Zeitstempel und die letzte Fehlermeldung in einem sauberen, nutzerfreundlichen Format zeigen (keine Stacktraces). Füge eine kurze empfohlene Handlung hinzu wie „Re‑auth erforderlich“ oder „Rate limit, retrying."
Ergänze ein paar Gesundheits‑Signale, die Probleme vorhersagen: Backlog‑Größe, Retry‑Anzahl, Ratenlimit‑Treffer und letzte erfolgreiche Durchsatzgröße (ungefähr, wie viele Items beim letzten Lauf synchronisiert wurden).
Beispiel: Dein CRM‑Sync ist verbunden, aber der Backlog wächst und Ratenlimit‑Treffer steigen. Noch kein Ausfall, aber ein klares Zeichen, die Sync‑Frequenz zu reduzieren oder Anfragen zu batchen. Wenn du deinen Hub in AppMaster baust, lassen sich diese Statusfelder leicht in ein Data Designer‑Modell und ein einfaches Support‑Dashboard abbilden.
Ein zuverlässiger Sync beruht mehr auf wiederholbaren Schritten als auf ausgefallener Logik. Starte mit einem klaren Ausführungsmodell und füge Komplexität nur dort hinzu, wo sie nötig ist.
Die meisten Teams nutzen eine Mischung, aber jeder Connector sollte einen primären Trigger haben, damit man ihn leicht nachvollziehen kann:
Wenn du in AppMaster baust, mappt das oft auf einen Webhook‑Endpoint, einen Hintergrundprozess und eine geplante Aufgabe, die alle in dieselbe interne Pipeline fließen.
Verschiedene Anbieter nennen dasselbe unterschiedlich (customerId vs contact_id, Status‑Strings, Datumsformate). Wandle jede eingehende Payload in ein internes Format, bevor du Geschäftsregeln anwendest. Das hält den Rest des Hubs einfacher und macht Connector‑Änderungen weniger schmerzhaft.
Retries sind normal. Dein Hub sollte dieselbe Aktion zweimal ausführen können, ohne Duplikate zu erzeugen. Eine übliche Methode ist, eine externe ID und eine „last processed version“ (Timestamp, Sequenznummer oder Event‑ID) zu speichern. Siehst du denselben Eintrag nochmal, überspringst du ihn oder aktualisierst sicher.
Drittanbieter‑APIs können langsam sein oder hängen. Lege normalisierte Tasks in eine durable Queue und verarbeite sie mit expliziten Timeouts. Wenn ein Call zu lange dauert, fehle ihn, dokumentiere warum und versuche es später erneut, anstatt alles zu blockieren.
Behandle Limits mit Backoff und Connector‑spezifischem Throttling. Backe off bei 429/5xx Antworten mit einem gedeckelten Retry‑Plan, setze separate Concurrency‑Limits pro Connector (CRM ist nicht Billing) und füge Jitter hinzu, um Retry‑Bursts zu vermeiden.
Beispiel: Ein „neue bezahlte Rechnung“‑Event landet via Webhook, wird normalisiert und queued, dann erstellt/updated es das passende Account im CRM. Wenn das CRM dich limitiert, verlangsamt sich dieser Connector, ohne Support‑Ticket‑Syncs aufzuhalten.
Ein Hub, der „manchmal ausfällt“, ist schlimmer als gar kein Hub. Die Lösung ist eine gemeinsame Art, Fehler zu beschreiben, zu entscheiden, was als Nächstes passiert, und nicht‑technischen Admins zu sagen, was zu tun ist.
Beginne mit einer standardisierten Fehlerform, die jeder Connector zurückgibt, auch wenn Drittanbieter‑Payloads unterschiedlich sind. Das hält UI, Alerts und Support‑Playbooks konsistent.
RATE_LIMIT)Klassifiziere Fehler in wenige Buckets (klein halten): auth, validation, timeout, rate limit und outage.
Hänge klare Retry‑Regeln an jeden Bucket. Rate‑Limits bekommen verzögerte Retries mit Backoff. Timeouts können schnell und kurz wiederholt werden. Validierung ist manuell, bis die Daten korrigiert sind. Auth pausiert die Integration und verlangt einen Admin zur Wiederverbindung.
Bewahre rohe Drittanbieter‑Antworten auf, aber speichere sie sicher. Redigiere Secrets (Tokens, API‑Keys, vollständige Kartendaten) bevor du sie speicherst. Wenn es Zugriff gewähren kann, gehört es nicht in Logs.
Schreibe zwei Nachrichten pro Fehler: eine für Admins und eine für Entwickler. Eine Admin‑Meldung könnte lauten: „Salesforce‑Verbindung abgelaufen. Erneut verbinden, um Sync fortzusetzen.“ Die Entwickler‑Ansicht kann die sanitisierten Response‑Daten, Request‑ID und den fehlgeschlagenen Schritt enthalten. Genau hier zahlt sich ein konsistenter Hub aus — ob du Abläufe in Code implementierst oder mit einem visuellen Tool wie AppMaster's Business Process Editor arbeitest.
Viele Integrationsprojekte scheitern an langweiligen Gründen. Der Hub läuft in der Demo, bricht aber zusammen, wenn du mehr Tenants, Datentypen und Edge‑Cases hinzufügst.
Eine große Falle ist, Verbindungslogik mit Geschäftslogik zu vermischen. Wenn „wie man mit der API spricht“ im selben Codepfad sitzt wie „was ein Kunden‑Datensatz bedeutet“, riskiert jede neue Regel, den Connector zu brechen. Halte Adapter fokussiert auf Auth, Paging, Ratenbegrenzungen und Mapping. Geschäftsregeln gehören in eine separate Schicht, die du testen kannst, ohne Drittanbieter‑APIs zu kontaktieren.
Ein weiteres häufiges Problem ist, Tenant‑State global zu behandeln. In einem B2B‑Produkt braucht jeder Tenant eigene Tokens, Cursors und Sync‑Checkpoints. Wenn du „letzte Sync‑Zeit“ an einer gemeinsamen Stelle speicherst, kann ein Kunde den anderen überschreiben und du bekommst fehlende Updates oder Cross‑Tenant‑Lecks.
Fünf Fallen, die immer wieder auftauchen, plus einfache Fixes:
Retries verdienen besondere Vorsicht. Wenn ein Create‑Call time‑outet, kann ein Retry Duplikate erzeugen, es sei denn, du verwendest Idempotency‑Keys oder eine starke Upsert‑Strategie. Unterstützt die API keine Idempotenz, tracke ein lokales Schreib‑Ledger, damit du wiederholte Writes erkennen und vermeiden kannst.
Überspringe nicht die Audit‑Logs. Wenn Support fragt, warum ein Datensatz fehlt, brauchst du in Minuten eine Antwort, nicht eine Vermutung. Selbst bei visuellen Tools wie AppMaster sollten Logs und per‑Tenant‑State Erstklassigkeit haben.
Ein guter Integrations‑Hub ist im besten Sinn langweilig: er verbindet, meldet seine Gesundheit klar und fällt auf eine für dein Team verständliche Weise aus.
Prüfe, wie jede Integration authentifiziert und was du mit diesen Credentials machst. Fordere die kleinstmöglichen Berechtigungen an (so weit wie möglich read‑only). Bewahre Secrets in einem dedizierten Secret‑Store oder verschlüsseltem Vault auf und rotiere sie ohne Codeänderungen. Stelle sicher, dass Logs und Fehlermeldungen niemals Tokens, API‑Keys, Refresh‑Tokens oder rohe Header enthalten.
Sobald Credentials sicher sind, bestätige, dass jede Kundenverbindung eine einzige, klare Quelle der Wahrheit hat.
Betriebliche Klarheit ist das, was Integrationen handhabbar hält, wenn du Dutzende Kunden und viele Drittanbieter hast.
Verfolge Verbindungszustand pro Kunde (connected, needs_auth, paused, failing) und zeige ihn in der Admin‑UI an. Notiere einen letzten erfolgreichen Sync‑Zeitstempel pro Objekt oder pro Sync‑Job, nicht nur „wir haben gestern etwas ausgeführt“. Mache den letzten Fehler leicht auffindbar mit Kontext: welcher Kunde, welche Integration, welcher Schritt, welche externe Anfrage und was als Nächstes passiert ist.
Halte Retries begrenzt (maximale Versuche und eine Abbruchfenster), und entwerfe Writes idempotent, damit erneutes Ausführen keine Duplikate erzeugt. Setze ein Support‑Ziel: Jemand im Team sollte den neuesten Fehler und seine Details in unter zwei Minuten finden können, ohne Code zu lesen.
Wenn du UI und Status‑Tracking schnell bauen willst, kann eine Plattform wie AppMaster helfen, intern ein Dashboard und Workflow‑Logik zu liefern, während sie produktionsbereiten Code generiert.
Stell dir ein SaaS‑Produkt vor, das drei gängige Integrationen braucht: Stripe für Billing‑Events, HubSpot für Sales‑Handoffs und Zendesk für Support‑Tickets. Anstatt jedes Tool direkt mit deiner App zu verknüpfen, leitest du alles durch einen Integrations‑Hub.
Das Onboarding beginnt im Admin‑Panel. Ein Admin klickt „Connect Stripe“, „Connect HubSpot“ und „Connect Zendesk“. Jeder Connector speichert Credentials im Hub, nicht in Skripten oder auf Laptops. Dann führt der Hub einen initialen Import aus:
Nach dem Import startet der erste Sync. Der Hub schreibt für jeden Connector einen Sync‑Datensatz, damit alle dieselbe Historie sehen. Eine einfache Admin‑Ansicht beantwortet die meisten Fragen: Verbindungszustand, letzte erfolgreiche Sync‑Zeit, aktueller Job (importing, syncing, idle), Fehlerzusammenfassung und Code sowie die nächste geplante Ausführung.
Nun ist eine geschäftige Stunde und Stripe limitiert deine API‑Aufrufe. Anstatt das System ganz scheitern zu lassen, markiert der Stripe‑Connector den Job als retrying, speichert den Partial‑Fortschritt (z. B. „Invoices bis 10:40“) und backt off. HubSpot und Zendesk synchronisieren weiterhin.
Support erhält ein Ticket: „Billing wirkt veraltet.“ Sie öffnen den Hub und sehen Stripe in failing mit einem Rate‑Limit‑Fehler. Die Lösung ist prozedural:
Wenn du auf einer Plattform wie AppMaster baust, mappt dieser Ablauf sauber auf visuelle Logik (Job‑Zustände, Retries, Admin‑Screens) und erzeugt trotzdem echten Backend‑Code für die Produktion.
Gutes Integrations‑Hub‑Design geht weniger darum, alles auf einmal zu bauen, als darum, jede neue Verbindung vorhersehbar zu machen. Starte mit einer kleinen Menge geteilter Regeln, die jeder Connector befolgen muss, auch wenn die erste Version „zu simpel“ erscheint.
Beginne mit Konsistenz: standardisierte Zustände für Sync‑Jobs (pending, running, succeeded, failed), eine kurze Menge an Fehlerkategorien (auth, rate limit, validation, upstream outage, unknown) und Audit‑Logs, die beantworten, wer was wann mit welchen Datensätzen ausgeführt hat. Wenn du Status und Logs nicht vertraust, machen Dashboards und Alerts nur Lärm.
Füge Connectoren einzeln mit denselben Templates und Konventionen hinzu. Jeder Connector sollte denselben Credential‑Flow, dieselben Retry‑Regeln und die gleiche Art, Statusupdates zu schreiben, wiederverwenden. Diese Wiederholung hält den Hub betreibbar, wenn du statt drei zehn Integrationen hast.
Ein praktischer Rollout‑Plan:
Führe Dashboards und Alerts erst ein, wenn die zugrunde liegenden Statusdaten korrekt sind. Beginne mit einem Screen, der letzte Sync‑Zeit, letztes Ergebnis, nächste Ausführung und die neueste Fehlermeldung mit Kategorie zeigt.
Wenn du einen No‑Code‑Ansatz bevorzugst, kannst du Daten modellieren, Sync‑Logik bauen und Status‑Screens in AppMaster erstellen und dann in deine Cloud deployen oder Quellcode exportieren. Halte die erste Version langweilig und beobachtbar, und verbessere Performance sowie Edge‑Cases erst, wenn der Betrieb stabil ist.
Beginne mit einem einfachen Inventar: liste jedes Drittanbietertool auf, wer es besitzt und ob es live oder geplant ist. Beschreibe dann die Daten, die zwischen Systemen fließen, und warum sie für ein Team wichtig sind (Support, Finanzen, Ops). Diese Karte zeigt dir, welche Flows echtzeitfähig sein müssen, welche täglich laufen können und welche die stärkste Überwachung benötigen.
Der Hub sollte die gemeinsame Infrastruktur liefern: Verbindungsaufbau, Speicherung von Zugangsdaten, Zeitplanung/Trigger, konsistente Statusmeldung und einheitliche Fehlerbehandlung. Geschäftsentscheidungen (zum Beispiel, welche Kunden abgerechnet werden oder was als qualifizierter Lead gilt) gehören außerhalb des Hubs. Diese Trennung verhindert ständige Änderungen am Connector‑Code und hält den Hub nützlich, ohne ihn zur Engstelle zu machen.
Verwende pro Connector einen primären Einstiegspunkt, damit sich Fehler leicht nachvollziehen lassen. Webhooks eignen sich für nahezu Echtzeit‑Updates, geplante Pulls für Anbieter, die keine Events pushen können, und Job‑Workflows, wenn Schritte in Reihenfolge ausgeführt werden müssen. Wichtig ist, dass Wiederholungen, Logging und Statusmeldungen bei allen Triggern gleich gehandhabt werden.
Behandle Zugangsdaten als Kundendaten und speichere sie verschlüsselt mit strikter Mandantenisolierung. Zeige Tokens nicht in Logs, UI‑Screens oder Support‑Screenshots und verwende keine Produktionsgeheimnisse in Staging. Speichere außerdem Metadaten wie Ablaufdatum, Scopes und zugehörigen Tenant/Connection, damit der Betrieb sicher möglich ist.
OAuth ist geeignet, wenn Kunden ihre eigenen Konten verbinden und du widerrufbaren, scoped Zugriff möchtest. API‑Keys sind für Server‑zu‑Server‑Integrationen oft einfacher, sind aber meist langlebig — daher sind Rotation und Zugriffskontrolle hier wichtiger. Wenn möglich, verwende OAuth für nutzerzentrierte Verbindungen und halte Keys eng begrenzt und regelmäßig rotiert.
Halte Mandanten‑State getrennt: Tokens, Cursors, Checkpoints, Retry‑Zähler und Backfill‑Fortschritt pro Tenant. Ein Fehler eines Tenants darf nur dessen Jobs pausieren, nicht den gesamten Connector. Diese Isolation verhindert Datenaustausch zwischen Tenants und erleichtert das Troubleshooting.
Zeige eine kleine, einheitliche Menge an Zuständen für jeden Connector, z. B. connected, needs_auth, paused und failing. Speichere pro Verbindung drei Zeitstempel: letzter Sync‑Start, letzte erfolgreiche Sync‑Zeit und letzte Fehlerzeit. Mit diesen Signalen lassen sich die meisten “Funktioniert es?”‑Fragen beantworten, ohne in Logs zu graben.
Mach jeden Schreibvorgang idempotent, damit Wiederholungen keine Duplikate erzeugen. Typischerweise bedeutet das, eine externe Objekt‑ID und einen „last processed“‑Marker zu speichern und Upserts statt blinder Creates zu verwenden. Unterstützt der Anbieter keine Idempotenz, führe ein lokales Schreib‑Ledger, um wiederholte Versuche vor dem Schreiben zu erkennen.
Gehe mit Ratenbegrenzungen gezielt um: throttele pro Connector, backe off bei 429 und transienten Fehlern und füge Jitter hinzu, damit Wiederholungen sich nicht bündeln. Verarbeite Arbeit über eine haltbare Queue mit Timeouts, damit langsame API‑Aufrufe andere Integrationen nicht blockieren. Ziel ist, einen Connector zu verlangsamen, ohne den gesamten Hub lahmzulegen.
Wenn du schnell mit No‑Code arbeiten willst, modelliere Verbindungen, Tenants und Statusfelder im Data Designer von AppMaster und implementiere Sync‑Workflows im Business Process Editor. Halte Zugangsdaten in Backend‑Logik und zeige in der UI nur sichere Status und Handlungsaufforderungen. So kannst du ein internes Operations‑Dashboard schnell liefern und trotzdem produktionsfähigen Code generieren.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


