Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
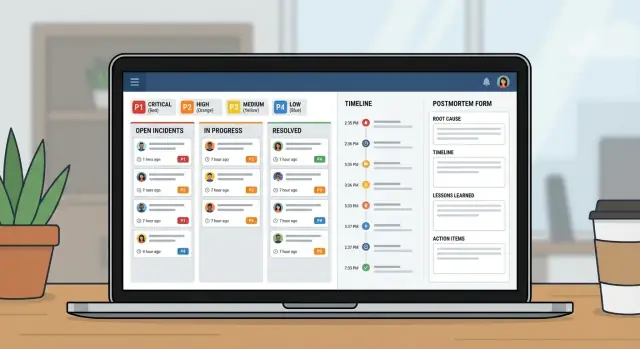
Plane und baue eine Incident‑Management‑App für IT‑Teams mit Schweregrad‑Workflows, klarer Zuständigkeit, Zeitlinien und Postmortems in einem internen Tool.
Wenn ein Ausfall eintritt, greifen die meisten Teams nach dem, was gerade offen ist: ein Chatthread, eine E‑Mail‑Kette, vielleicht eine Tabelle, die jemand aktualisiert, wenn er Zeit hat. Unter Druck versagt dieses Setup immer auf die gleichen Arten: Zuständigkeiten werden unklar, Zeitstempel gehen verloren und Entscheidungen verschwinden im Scroll.
Eine einfache Incident‑Management‑App behebt die Grundlagen. Sie gibt einen Ort, an dem der Vorfall lebt, mit einem klaren Owner, einem Schweregrad, auf den sich alle einigen, und einer Timeline, was wann passiert ist. Dieser einzelne Datensatz ist wichtig, weil in jedem Vorfall die gleichen Fragen auftauchen: Wer führt? Wann hat es begonnen? Wie ist der aktuelle Status? Was wurde bereits probiert?
Ohne dieses gemeinsame Protokoll kosten Übergaben Zeit. Support sagt Kunden etwas anderes, während Engineering etwas anderes macht. Manager fragen nach Updates und reißen die Antwortenden vom Fix weg. Danach kann niemand die Timeline mit Vertrauen rekonstruieren, und das Postmortem wird zur Vermutungssammlung.
Ziel ist nicht, Monitoring, Chat oder Tickets zu ersetzen. Alerts können weiter woanders starten. Der Punkt ist, die Entscheidungsfolge zu erfassen und Menschen auf dem gleichen Stand zu halten.
IT‑Operations und Bereitschaftsingenieure nutzen es zur Koordination. Support nutzt es, um schnell korrekte Updates zu geben. Manager sehen Fortschritt, ohne die Respondenden zu unterbrechen.
Um 09:12 meldet das Monitoring einen Anstieg von 500er‑Fehlern im Kundenportal. Ein Support‑Agent meldet außerdem: „Login schlägt bei den meisten Nutzern fehl.“ Der On‑Call‑IT‑Lead eröffnet ein P1‑Incident in der App und hängt den ersten Alert plus einen Screenshot aus dem Support an.
Bei einem P1 ändert sich das Verhalten schnell. Der Incident‑Owner zieht den Backend‑Owner, den Datenbank‑Owner und einen Support‑Liaison hinzu. Nicht‑essentielle Arbeit pausiert. Geplante Deploys stoppen. Das Team vereinbart eine Update‑Cadence (z. B. alle 15 Minuten). Ein gemeinsamer Call startet, aber der Incident‑Datensatz bleibt die Quelle der Wahrheit.
Um 09:18 fragt jemand: „Was hat sich geändert?“ Die Timeline zeigt ein Deploy um 08:57, aber nicht, was deployed wurde. Der Backend‑Owner rollt trotzdem zurück. Die Fehler gehen zurück, kommen dann aber wieder. Jetzt verdächtigt das Team die Datenbank.
Die meisten Verzögerungen treten an ein paar vorhersehbaren Stellen auf: unklare Übergaben („Ich dachte, du schaust das an“), fehlender Kontext (kürzliche Änderungen, bekannte Risiken, aktueller Owner) und verstreute Updates in Chat, Tickets und E‑Mail.
Um 09:41 findet der Datenbank‑Owner eine ausufernde Query, die von einem geplanten Job gestartet wurde. Er deaktiviert den Job, startet den betroffenen Service neu und bestätigt die Wiederherstellung. Der Schweregrad wird zur Überwachung auf P2 herabgestuft.
Gute Schließung ist nicht „es funktioniert wieder“. Es ist ein sauberer Datensatz: eine Minuten‑für‑Minute‑Timeline, die finale Root Cause‑Erklärung, wer welche Entscheidung getroffen hat, was pausiert wurde und Folgeaufgaben mit Ownern und Fälligkeiten. So wird ein stressiger P1 zu einer Lerngelegenheit statt zu wiederkehrendem Schmerz.
Ein gutes Incident‑Tool ist größtenteils ein gutes Datenmodell. Sind Datensätze vage, werden Leute darüber streiten, was der Incident genau ist, wann er begonnen hat und was noch offen ist.
Halte die Kern‑Entitäten nah an der Sprache, die IT‑Teams ohnehin verwenden:
Um später Verwirrung zu vermeiden, gib dem Incident ein paar strukturierte Felder, die immer ausgefüllt sind. Freitext hilft, aber er sollte nicht die einzige Quelle der Wahrheit sein. Ein praxisnahes Minimum ist: ein klarer Titel, Impact (was Nutzer sehen), betroffene Services, Startzeit, aktueller Status und Schweregrad.
Beziehungen sind wichtiger als zusätzliche Felder. Ein Incident sollte viele Updates und Tasks haben sowie eine Many‑to‑Many‑Verknüpfung zu Services (Ausfälle treffen oft mehrere Systeme). Ein Postmortem sollte eins‑zu‑eins mit einem Incident sein, damit es eine einzige abschließende Geschichte gibt.
Beispiel: Ein „Checkout‑Errors“‑Incident verknüpft die Services „Payments API“ und „PostgreSQL“, hat 15‑minütige Updates und Tasks wie „Rollback Deploy“ und „Retry Guard hinzufügen“. Später fasst das Postmortem Root Cause zusammen und erstellt längerfristige Tasks.
Wenn Leute gestresst sind, brauchen sie einfache Labels, die für alle dasselbe bedeuten. Definiere P1 bis P4 in klarem Text und zeige die Definition direkt neben dem Schweregrad‑Feld.
Reaktionsziele sollten sich wie Verpflichtungen lesen. Ein einfaches Baseline‑Beispiel (an eure Realität anpassen):
| Schweregrad | Erste Reaktion (Bestätigung) | Erste Aktualisierung | Aktualisierungs‑frequenz |
|---|---|---|---|
| P1 | 5 min | 15 min | alle 30 min |
| P2 | 15 min | 30 min | alle 60 min |
| P3 | 4 Stunden | 1 Arbeitstag | täglich |
| P4 | 2 Arbeitstage | 1 Woche | wöchentlich |
Halte Eskalationsregeln mechanisch. Wenn ein P2 seine Update‑Cadence verpasst oder der Impact wächst, sollte das System eine Schweregrad‑Überprüfung vorschlagen. Um Thrash zu vermeiden, begrenze, wer den Schweregrad ändern kann (oft der Incident‑Owner oder Incident‑Commander), aber erlaube jedem, in einem Kommentar eine Überprüfung anzufragen.
Eine kleine Impact‑Matrix hilft Teams, den Schweregrad schnell zu wählen. Erfasse sie als ein paar Pflichtfelder: betroffene Nutzer, Umsatzrisiko, Sicherheit, Compliance, und ob ein Workaround existiert.
Während eines Vorfalls brauchen Leute keine vielen Optionen. Sie brauchen eine kurze Menge an Stati, die den nächsten Schritt offensichtlich machen.
Beginne mit den Schritten, die ihr an einem guten Tag ohnehin folgt, und halte die Liste kurz. Hat man mehr als 6–7 Stati, diskutieren Teams eher Formulierungen als den Fix.
Ein praxisorientiertes Set:
Jeder Status braucht klare Ein‑ und Austrittsregeln. Zum Beispiel:
Nutze Transitionen, um Felder zu erzwingen, die Leute vergessen. Eine gängige Regel: Du kannst einen Incident nicht schließen, ohne eine kurze Root‑Cause‑Zusammenfassung und mindestens einen Follow‑Up‑Punkt. Wenn „RCA: TBD“ erlaubt ist, bleibt es oft so.
Die Incident‑Seite sollte drei Fragen auf einen Blick beantworten: Wer ist Owner, was ist die nächste Aktion und wann wurde zuletzt aktualisiert.
Bei lauten Incidents ist der schnellste Weg, Zeit zu verlieren, unscharfe Zuständigkeiten. Deine App sollte eine Person klar verantwortlich machen und dennoch anderen das Helfen erleichtern.
Ein einfaches, belastbares Muster:
Die Zuordnung sollte explizit und prüfbar sein. Verfolge, wer den Owner gesetzt hat, wer ihn angenommen hat und jede Veränderung danach. „Angenommen“ ist wichtig, denn jemandem zuzuweisen, der schläft oder offline ist, ist keine echte Verantwortlichkeit.
On‑Call vs. Team‑basierte Zuordnung hängt meist vom Schweregrad ab. Bei P1/P2 nutze standardmäßig die Bereitschaftsrotation, damit es immer einen namentlich genannten Owner gibt. Bei niedrigerem Schweregrad kann Team‑basierte Zuordnung funktionieren, aber fordere trotzdem innerhalb kurzer Zeit einen einzelnen primären Owner.
Plane Urlaube und Ausfälle in eurem Prozess, nicht nur im System. Wenn die zugewiesene Person als unavailable markiert ist, leite an einen sekundären On‑Call oder Team‑Lead weiter. Halte es automatisch, aber sichtbar, damit es schnell korrigiert werden kann.
Eskalation sollte sowohl bei Schweregrad als auch bei Stille auslösen. Ein nützlicher Startpunkt:
Eine gute Timeline ist geteiltes Gedächtnis. Während eines Vorfalls verschwindet Kontext schnell. Wenn du die richtigen Momente an einem Ort festhältst, werden Übergaben einfacher und das Postmortem ist größtenteils schon geschrieben, bevor jemand ein Dokument öffnet.
Halte die Timeline meinungsstark. Verwandle sie nicht in ein Chat‑Log. Die meisten Teams verlassen sich auf wenige Einträge: Erkennung, Bestätigung, wichtige Mitigations‑Schritte, Wiederherstellung und Abschluss.
Jeder Eintrag braucht einen Zeitstempel, einen Autor und eine kurze, klare Beschreibung. Jemand, der später dazukommt, sollte fünf Einträge lesen können und verstehen, was los ist.
Verschiedene Updates dienen verschiedenen Zielgruppen. Es hilft, wenn Einträge einen Typ haben, etwa interner Hinweis (rohe Details), kundenfreundliches Update (sichere Formulierung), Entscheidung (warum Option A) und Übergabe (was die nächste Person wissen muss).
Erinnerungen sollten dem Schweregrad folgen, nicht persönlichen Vorlieben. Wenn der Timer anschlägt, pinge zuerst den aktuellen Owner, dann eskaliere bei wiederholtem Versäumnis.
Benachrichtigungen sollten gezielt und vorhersehbar sein. Eine kleine Regelmenge reicht meist: benachrichtige bei Erstellung, Schweregrad‑Änderung, Wiederherstellung und überfälligen Updates. Vermeide, die ganze Firma bei jedem kleinen Change zu informieren.
Ein Postmortem hat zwei Aufgaben: in einfacher Sprache erklären, was passiert ist, und dafür sorgen, dass derselbe Fehler weniger wahrscheinlich wiederholt wird.
Halte das Schreiben kurz und zwinge es in Aktionen. Eine praktische Struktur: Zusammenfassung, Kundenimpact, Root Cause, angewandte Fixes und Follow‑Ups.
Follow‑Ups sind der Punkt. Lass sie nicht als Fließtext am Ende stehen. Mach aus jedem Follow‑Up eine nachverfolgbare Aufgabe mit Owner und Fälligkeitsdatum, auch wenn das Fälligkeitsdatum „nächster Sprint“ ist. Das ist der Unterschied zwischen „Monitoring verbessern“ und „Alex legt bis Freitag eine DB‑Connection‑Saturation‑Alarmregel an."
Tags machen Postmortems später nützlich. Füge jedem Incident 1–3 Themen hinzu (Monitoring‑Lücke, Deployment, Kapazität, Prozess). Nach einem Monat kannst du einfache Fragen wie „Kommen die meisten P1s von Releases oder fehlenden Alerts?“ beantworten.
Evidence sollte leicht anhängbar, aber nicht verpflichtend sein. Unterstütze optionale Felder für Screenshots, Log‑Snippets und Referenzen zu externen Systemen (Ticket‑IDs, Chat‑Threads, Vendor‑Case‑Nummern). Halte es leichtgewichtig, damit Leute es tatsächlich ausfüllen.
Behandle das wie ein kleines Produkt, nicht wie eine Tabelle mit ein paar Spalten. Eine gute Incident‑App ist faktisch drei Ansichten: was jetzt passiert, was als Nächstes zu tun ist, und was danach zu lernen ist.
Skizziere zuerst die Bildschirme, die Leute unter Druck öffnen:
Baue Datenmodell und Berechtigungen zusammen. Kann jeder alles bearbeiten, wird die Historie chaotisch. Ein üblicher Ansatz: breiter Lesebereich für IT, kontrollierte Status/Schweregrad‑Änderungen, Responders können Updates hinzufügen und ein klarer Owner für Postmortem‑Freigabe.
Füge dann Workflow‑Regeln hinzu, die halb ausgefüllte Incidents verhindern. Pflichtfelder sollten vom Status abhängen. Du erlaubst eventuell „New“ nur mit Titel und Reporter, verlangst aber bei „Mitigating“ eine Impact‑Zusammenfassung und bei „Resolved“ eine Root‑Cause‑Zusammenfassung plus mindestens einen Follow‑Up‑Task.
Teste abschließend durch das Nachspielen von 2–3 vergangenen Incidents. Lass eine Person Incident‑Commander spielen und eine andere Responder. Du siehst schnell, welche Stati unklar sind, welche Felder übersprungen werden und wo bessere Defaults nötig sind.
Die meisten Incident‑Systeme scheitern aus einfachen Gründen: Leute erinnern sich unter Stress nicht mehr an die Regeln und die App erfasst nicht die Fakten, die du später brauchst.
Bei sechs Severity‑Leveln und zehn Stati raten Leute. Halte die Schweregrade bei 3–4 und fokussiere Stati auf die nächste erwartete Handlung.
Wenn alle „nur zuschauen“, treibt keiner das Geschehen voran. Fordere einen benannten Owner, bevor der Incident weitergeht, und mache Übergaben explizit.
Wenn „was wann passiert ist" vom Chat abhängt, werden Postmortems zu Streitfällen. Erfasse automatisch Zeiten für geöffnet, bestätigt, mitigiert und gelöst und halte Timeline‑Einträge kurz.
Schließe nicht mit vagen Root‑Cause‑Notizen wie „Netzwerkproblem“. Erfordere eine klare Root‑Cause‑Aussage plus mindestens einen konkreten nächsten Schritt.
Bevor du das in die ganze IT‑Organisation ausrollst, stress‑test die Grundlagen. Findet jemand den richtigen Button in den ersten zwei Minuten nicht, fällt er zurück auf Chat und Tabellen.
Fokussiere dich auf eine kurze Launch‑Checkliste: Rollen und Berechtigungen, klare Schweregrad‑Definitionen, erzwungene Ownership, Erinnerungsregeln und ein Eskalationspfad, wenn Reaktionsziele verfehlt werden.
Pilote mit einem Team und ein paar Services, die häufig Alerts erzeugen. Lauf es zwei Wochen, und passe es anhand echter Vorfälle an.
Wenn du das als ein internes Tool bauen willst, ohne Tabellen und getrennte Apps zusammenzukleben, ist AppMaster (appmaster.io) eine Option. Damit kannst du ein Datenmodell, Workflow‑Regeln und Web/Mobile‑Interfaces an einem Ort erstellen—eine gute Passform für Queue, Incident‑Seite und Postmortem‑Tracking.
Es ersetzt verstreute Updates durch einen gemeinsamen Datensatz, der die wichtigsten Fragen schnell beantwortet: Wer ist Owner, was sehen Nutzer, was wurde bereits versucht und wie geht es weiter. Das reduziert Zeitverlust durch Übergaben, widersprüchliche Meldungen und ständige Zusammenfassungsanfragen.
Öffne den Vorfall, sobald ein echter Kunden‑ oder Geschäftseinfluss wahrscheinlich ist, auch wenn die Ursache noch unklar ist. Du kannst mit einem vorläufigen Titel und „Impact unbekannt“ starten und die Details nach und nach präzisieren, sobald Umfang und Schwere bestätigt sind.
Halte es klein und strukturiert: ein klarer Titel, Kurzbeschreibung des Impacts, betroffene(r) Service(s), Startzeit, aktueller Status, Schweregrad und ein einzelner Owner. Ergänze Updates und Tasks während des Vorfalls, verlasse dich aber nicht auf Freitext für die Kernfakten.
Nutze 3 bis 4 Level mit klaren Bedeutungen, über die niemand diskutieren muss. Ein gutes Default: P1 für Ausfall/Kritisches Datenrisiko, P2 für wichtigen Funktionsausfall mit Workaround oder begrenztem Umfang, P3 für kleinere Auswirkungen, P4 für kosmetische oder sehr geringe Probleme.
Werte wie Zeit bis zur Bestätigung, Zeit bis zur ersten Aktualisierung und die Aktualisierungsfrequenz. Mache sie zu Verpflichtungen, nicht zu groben Schätzungen, und löse Erinnerungen sowie Eskalationen aus, wenn die Cadence verpasst wird — Schweigen ist während Incidents oft das eigentliche Problem.
Ziel sind etwa sechs Stati: New, Acknowledged, Investigating, Mitigating, Monitoring und Resolved. Jedes State sollte die nächste Handlung klar machen; Übergänge sollten Felder erzwingen, die im Stress oft vergessen werden (z. B. Owner bevor Acknowledged).
Erzwinge einen primären Owner, der die Response steuert und Updates postet. Protokolliere die Annahme des Auftrags explizit, damit du niemanden zuweist, der offline ist, und mache Handoffs zu einer dokumentierten Aktion, sodass die nächste Person nicht von vorne anfangen muss.
Erfasse nur die Momente, die zählen: Erkennung, Bestätigung, wichtige Entscheidungen, Maßnahmen zur Minderung, Wiederherstellung und Abschluss — jeweils mit Zeitstempel und Autor. Behandle die Timeline als gemeinsames Gedächtnis, nicht als Chattranskript, damit Neueinsteiger in Minuten aufschließen können.
Halte das Postmortem kurz und handlungsorientiert: Was ist passiert, Kundenimpact, Root Cause, während der Minderung vorgenommene Änderungen und Follow‑Ups. Wichtig sind die nachverfolgten Tasks mit Ownern und Fälligkeitsdaten — das ist es, was verhindert, dass derselbe Vorfall wieder passiert.
Ja. Wenn du Incidents, Updates, Tasks, Services und Postmortems als echte Daten modellierst und Workflow‑Regeln im Tool durchsetzt, brauchst du keine verstreuten Tabellen. AppMaster (appmaster.io) erlaubt es, das Datenmodell, Workflows und Web/Mobile‑Oberflächen in einem System zu erstellen, sodass der Prozess nicht unter Druck in Tabellen zurückfällt.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


