Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Lerne praxisnahe Muster für Hintergrundaufgaben mit Fortschrittsanzeigen: Queues, Status-Modelle, UI-Nachrichten, Abbrechen/Wiederholen und Fehlerberichte.
Lange laufende Aktionen sollten die UI nicht blockieren. Menschen wechseln Tabs, verlieren die Verbindung, schließen ihren Laptop oder fragen sich einfach, ob überhaupt etwas passiert. Wenn der Bildschirm eingefroren wirkt, fangen Nutzer an zu raten — und Raten führt zu wiederholten Klicks, doppelten Einreichungen und Support-Tickets.
Gute Hintergrundarbeit dreht sich vor allem um Vertrauen. Nutzer wollen drei Dinge:
Ohne diese Dinge kann der Job zwar technisch einwandfrei laufen, aber die Erfahrung fühlt sich kaputt an.
Ein häufiger Fehler ist, eine langsame Anfrage wie echte Hintergrundarbeit zu behandeln. Eine langsame Anfrage ist immer noch ein einzelner Web-Call, der den Nutzer warten lässt. Hintergrundarbeit ist anders: du startest einen Job, bekommst sofort eine Bestätigung, und die schwere Verarbeitung passiert anderswo, während die UI nutzbar bleibt.
Beispiel: Ein Nutzer lädt eine CSV hoch, um Kunden zu importieren. Blockiert die UI, könnte er die Seite neu laden, erneut hochladen und Duplikate erzeugen. Startet der Import im Hintergrund und zeigt die UI eine Job-Karte mit Fortschritt und einer sicheren Abbrechen-Option, kann er weiterarbeiten und später ein klares Ergebnis sehen.
Wenn Leute über Hintergrundaufgaben mit Fortschrittsaktualisierungen sprechen, meinen sie meist vier zusammenarbeitende Teile.
Ein Job ist die Arbeitseinheit: "diese CSV importieren", "diesen Bericht generieren" oder "5.000 E-Mails senden". Eine Queue ist die Warteschlange, in der Jobs sitzen, bis sie bearbeitet werden. Ein Worker zieht Jobs aus der Queue und führt die Arbeit aus (seriell oder parallel).
Für die UI ist das wichtigste Stück der Lifecycle-Status des Jobs. Halte die Zustände wenige und vorhersehbar:
Jeder Job braucht eine Job-ID (eine eindeutige Referenz). Wenn der Nutzer auf einen Button klickt, gib diese ID sofort zurück und zeige eine „Task started“-Zeile im Aufgabenpanel.
Dann brauchst du eine Möglichkeit zu fragen: „Was passiert jetzt?“ Das ist üblicherweise ein Status-Endpunkt (oder jede Lese-Methode), die die Job-ID nimmt und den Zustand plus Fortschrittsdetails zurückgibt. Die UI verwendet das, um Prozentangaben, aktuellen Schritt und Meldungen anzuzeigen.
Schließlich muss der Status in einem dauerhaften Speicher liegen, nicht nur im Speicher des Prozesses. Worker stürzen ab, Apps starten neu und Nutzer laden Seiten neu. Dauerhafter Speicher macht Fortschritt und Ergebnisse verlässlich. Mindestens solltest du speichern:
Wenn du auf einer Plattform wie AppMaster baust, behandle den Status-Speicher wie jedes andere Datenmodell: die UI liest ihn per Job-ID und der Worker aktualisiert ihn, während er den Job durchläuft.
Das Queue-Muster, das du wählst, beeinflusst, wie „fair“ und vorhersehbar deine App wirkt. Wenn eine Aufgabe hinter vielen anderen liegt, wirkt sie für Nutzer wie zufällige Verzögerung, selbst wenn das System gesund ist. Deshalb ist die Queue-Wahl eine UX-Entscheidung, nicht nur Infrastruktur.
Eine einfache datenbankgestützte Queue reicht oft, wenn das Volumen gering ist, Jobs kurz sind und gelegentliche Retries tolerierbar sind. Sie ist leicht aufzusetzen, leicht zu prüfen und alles bleibt an einem Ort. Beispiel: Ein Admin führt einen nächtlichen Bericht für ein kleines Team aus. Wenn er einmal neu startet, gerät niemand in Panik.
Bei steigendem Durchsatz, schweren Jobs oder wenn Zuverlässigkeit essentiell wird, brauchst du meist ein dediziertes Queue-System. Importe, Videobearbeitung, Massenbenachrichtigungen und Workflows, die über Neustarts hinweg laufen müssen, profitieren von besserer Isolation, Sichtbarkeit und sichererem Retry-Verhalten. Das wirkt sich auf den wahrgenommenen Fortschritt aus, weil Nutzer fehlende Updates und hängende Zustände bemerken.
Die Struktur der Queue beeinflusst auch Prioritäten. Eine einzige Queue ist einfacher, aber das Mischen von schnellen und langsamen Arbeiten kann schnelle Aktionen langsam wirken lassen. Separate Queues helfen, wenn nutzergetriebene Arbeit sofort wirken soll, während geplante Batch-Jobs warten können.
Setze bewusst Concurrency-Limits. Zu viel Parallelität kann die Datenbank überlasten und Fortschritt ruckelig machen. Zu wenig lässt das System träge erscheinen. Starte mit kleiner, vorhersehbarer Parallelität pro Queue und erhöhe nur, wenn die Laufzeiten stabil bleiben.
Wenn dein Fortschrittsmodell vage ist, wird die UI auch vage wirken. Entscheide, was das System ehrlich berichten kann, wie oft sich das ändert und was Nutzer mit diesen Informationen tun sollen.
Ein einfaches Status-Schema, das die meisten Jobs unterstützen kann, sieht so aus:
Definiere danach, was „Fortschritt“ bedeutet.
Prozent macht Sinn, wenn es einen echten Nenner gibt (Zeilen in einer Datei, zu sendende E-Mails). Es irreführt, wenn die Arbeit unvorhersehbar ist (Warten auf Drittanbieter, variable Berechnung, teure Queries). In solchen Fällen baut schrittbasierter Fortschritt mehr Vertrauen auf, weil er in klaren Abschnitten voranschreitet.
Eine praktische Regel:
Speichere Zwischenergebnisse, während der Job läuft. So kann die UI bereits nützliche Informationen zeigen, bevor der Job fertig ist, z. B. eine Live-Fehleranzahl oder eine Vorschau der Änderungen. Bei einem CSV-Import speicherst du vielleicht rows_read, rows_created, rows_updated, rows_rejected und die letzten Fehlernachrichten.
Das ist die Grundlage für Hintergrundaufgaben mit Fortschrittsaktualisierungen, denen Nutzer vertrauen: die UI bleibt ruhig, Zahlen bewegen sich und die „Was ist passiert?“-Zusammenfassung ist bereit, wenn der Job endet.
Den Fortschritt vom Backend auf den Bildschirm zu bringen ist der Punkt, an dem viele Implementierungen scheitern. Wähle eine Übertragungsmethode, die dazu passt, wie oft sich der Fortschritt ändert und wie viele Nutzer ihn beobachten.
Polling ist am einfachsten: die UI fragt alle N Sekunden nach dem Status. Ein guter Standard sind 2–5 Sekunden, solange der Nutzer aktiv auf der Seite ist, dann ausdünnen über die Zeit. Läuft der Task länger als eine Minute, wechsele zu 10–30 Sekunden. Ist der Tab im Hintergrund, verlangsame weiter.
Push-Updates (WebSockets, Server-Sent Events oder mobile Notifications) helfen, wenn sich der Fortschritt schnell ändert oder Nutzer unmittelbare Informationen brauchen. Push ist gut für Unmittelbarkeit, aber du brauchst immer ein Fallback, wenn die Verbindung abbricht.
Eine Hybrid-Strategie ist oft am besten: polle zu Beginn schnell (damit die UI schnell sieht, dass queued zu running wird), dann verlangsame, wenn der Job stabil ist. Wenn du Push hinzufügst, behalte ein langsames Polling als Sicherheitsnetz.
Wenn Updates aufhören, behandle das als ersten klassigen Zustand. Zeige „Zuletzt aktualisiert vor 2 Minuten“ und biete ein Refresh an. Auf dem Backend markiere Jobs als stale, wenn sie keinen Heartbeat haben.
Klarheit entsteht aus zwei Dingen: einer kleinen Menge vorhersehbarer Zustände und Text, der den Leuten sagt, was als Nächstes passiert.
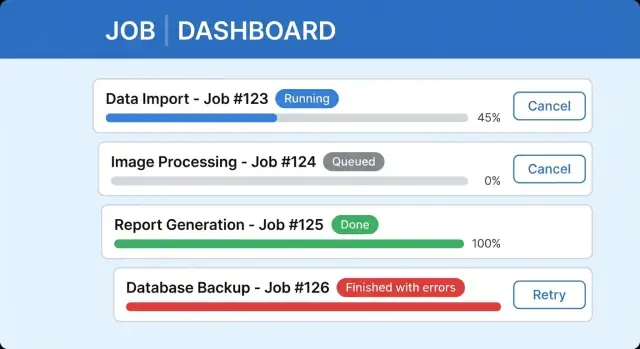
Benenne die Zustände in der UI, nicht nur im Backend. Ein Job kann queued (wartet), running (arbeitet), waiting for input (benötigt eine Entscheidung), completed, completed with errors oder failed sein. Können Nutzer diese nicht unterscheiden, denken sie, die App hänge.
Nutze klare, nützliche Texte neben dem Fortschrittsindikator. „Importiere 3.200 Zeilen (1.140 verarbeitet)“ ist besser als „Processing.“ Füge einen Satz hinzu, der beantwortet: Kann ich schließen und was passiert dann? Zum Beispiel: „Du kannst dieses Fenster schließen. Wir importieren im Hintergrund weiter und benachrichtigen dich, wenn es fertig ist."
Wo Fortschritt angezeigt wird, sollte zum Kontext des Nutzers passen:
Bei allem, das länger als eine Minute dauert, füge eine einfache Jobs-Seite (oder Activity-Panel) hinzu, damit Leute die Arbeit später finden können.
Eine klare UI für langlaufende Aufgaben enthält üblicherweise ein Statuslabel mit zuletzt aktualisiert, einen Fortschrittsbalken (oder Schritte) mit einer Detailzeile, sicheres Cancel-Verhalten und einen Ergebnisbereich mit Zusammenfassung und nächster Aktion. Halte abgeschlossene Jobs auffindbar, damit Nutzer nicht gezwungen sind, auf einer Seite zu warten.
„Fertig“ ist nicht immer ein Erfolg. Wenn ein Hintergrundjob 9.500 Datensätze verarbeitet und 120 fehlschlagen, müssen Nutzer ohne Log-Lektüre verstehen, was passiert ist.
Behandle Teilerfolg als vollwertiges Ergebnis. Zeige in der Hauptzeile beide Seiten: „Imported 9,380 of 9,500. 120 failed.“ Das erhält Vertrauen, weil das System ehrlich ist und bestätigt, dass Arbeit gespeichert wurde.
Zeige dann eine kompakte Fehlerübersicht, die Nutzer handeln lässt: „Fehlendes Pflichtfeld (63)“ und „Ungültiges Datumsformat (41)“. Im Endzustand ist „Completed with issues“ oft klarer als „Failed“, weil es nicht impliziert, dass nichts funktioniert hat.
Ein exportierbarer Fehlerbericht verwandelt Verwirrung in eine To‑Do‑Liste. Halte ihn einfach: Zeilen- oder Item-Identifier, Fehlerkategorie, eine menschliche Nachricht und das Feld, wenn relevant.
Mache die nächste Aktion offensichtlich und nahe an der Zusammenfassung: Daten korrigieren und fehlgeschlagene Items erneut versuchen, den Fehlerbericht herunterladen oder den Support kontaktieren, wenn es wie ein Systemfehler aussieht.
Abbrechen und Wiederholen wirken simpel, zerstören aber Vertrauen schnell, wenn die UI etwas sagt und das System etwas anderes tut. Definiere, was Cancel für jeden Jobtyp bedeutet, und spiegle das ehrlich in der Oberfläche.
Üblicherweise gibt es zwei sinnvolle Cancel-Modi:
Zeige in der UI einen Zwischenzustand wie „Cancel requested“, damit Nutzer nicht weiter klicken.
Mache Abbruch sicher, indem du die Arbeit wiederholbar gestaltest. Schreibt ein Job Daten, bevorzuge idempotente Operationen (sicher zweimal durchführbar) und räume bei Bedarf auf. Bei einem CSV-Import speicher z. B. eine Job-Run-ID, damit du sehen kannst, was in Lauf #123 geändert wurde.
Retry braucht die gleiche Klarheit. Das Wiederholen derselben Job-Instanz macht Sinn, wenn sie fortsetzbar ist. Eine neue Job-Instanz ist sicherer, wenn du einen sauberen Lauf mit neuem Zeitstempel und Audit-Trail willst. Erkläre in beiden Fällen, was passieren wird und was nicht.
Guardrails, die Cancel und Retry vorhersehbar machen:
Ein guter End-to-End-Flow beginnt mit einer Regel: die UI darf niemals auf die Arbeit selbst warten. Sie wartet nur auf eine Job-ID.
Der Nutzer startet die Aufgabe, API antwortet schnell. Wenn der Nutzer Import oder Bericht generieren klickt, legt dein Server sofort einen Job an und gibt eine eindeutige Job-ID zurück.
Die Arbeit enqueued und erster Status gesetzt. Lege die Job-ID in eine Queue und setze den Status auf queued mit 0% Fortschritt. Das gibt der UI etwas Echtes zu zeigen, noch bevor ein Worker ihn aufnimmt.
Worker läuft und meldet Fortschritt. Wenn ein Worker startet, setze Status auf running, speichere Startzeit und aktualisiere den Fortschritt in kleinen, ehrlichen Schritten. Kannst du kein Prozent messen, zeige Schritte wie Parsing, Validating, Saving.
Die UI hält den Nutzer orientiert. Die UI pollt oder abonniert Updates und rendert klare Zustände. Zeige eine kurze Nachricht (was gerade passiert) und nur die Aktionen, die gerade sinnvoll sind.
Finalisiere mit einem dauerhaften Ergebnis. Beim Abschluss speichere Finish-Zeit, Output (Download-Referenz, erstellte IDs, Zusammenfassungszahlen) und Fehlerdetails. Unterstütze „finished-with-errors“ als eigenes Ergebnis, nicht als verschwommenen Erfolg.
Cancel sollte explizit sein: Cancel-Anfragen verlangen Abbruch, dann bestätigt der Worker und markiert den Job als canceled. Retry sollte eine neue Job-ID erzeugen, das Original als Historie behalten und erklären, was erneut ausgeführt wird.
Ein häufiger Fall ist ein CSV-Import. Stell dir ein CRM vor, in das eine Sales-Ops-Person customers.csv mit 8.420 Zeilen hochlädt.
Direkt nach dem Upload sollte die UI vom Zustand „Ich habe auf einen Button geklickt“ zu „Ein Job existiert, du kannst weggehen“ wechseln. Eine einfache Job-Karte in einer Imports-Seite funktioniert gut:
Während des Laufs zeige eine verlässliche Fortschrittszahl (verarbeitete Zeilen) und eine kurze Statuszeile (was gerade passiert). Wenn der Nutzer weg navigiert, halte den Job sichtbar in einem Recent-Jobs-Bereich.
Kommen Teilfehler hinzu: Vermeide ein furchteinflößendes Failed-Banner, wenn die meisten Zeilen importiert wurden. Nutze Finished with issues plus eine klare Aufteilung:
Imported 8,102 customers. Skipped 318 rows.
Erkläre die Hauptgründe in einfachen Worten: ungültiges E-Mail-Format, fehlende Pflichtfelder wie Firma oder doppelte externe IDs. Lass den Nutzer einen Fehler-Tabellen-Download machen mit Zeilennummer, Kundennamen und dem betroffenen Feld.
Retry sollte sicher und konkret wirken. Die Hauptaktion kann "Retry failed rows" sein, die einen neuen Job anlegt, der nur die 318 übersprungenen Zeilen erneut verarbeitet, nachdem der Nutzer die CSV korrigiert hat. Belasse das Original read-only, damit die Historie wahr bleibt.
Mache Ergebnisse später leicht auffindbar. Jeder Import sollte eine stabile Zusammenfassung haben: wer ihn gestartet hat, wann, Dateiname, Zähler (importiert, übersprungen) und einen Weg, den Fehlerbericht zu öffnen.
Der schnellste Weg, Vertrauen zu verlieren, ist Zahlen zu zeigen, die nicht echt sind. Ein Fortschrittsbalken, der zwei Minuten bei 0% bleibt und dann auf 90% springt, wirkt wie geraten. Kannst du kein wahres Prozent wissen, zeige Schritte (Queued, Processing, Finalizing) oder "X of Y items processed".
Ein weiteres Problem ist, Fortschritt nur im Speicher zu halten. Startet der Worker neu, „vergisst“ die UI den Job oder setzt den Fortschritt zurück. Speichere den Jobzustand dauerhaft und lass die UI von dieser einzigen Quelle der Wahrheit lesen.
Retry-UX bricht auch, wenn Nutzer denselben Job mehrfach starten können. Wenn der Import-CSV-Button weiterhin aktiv aussieht, klickt jemand zweimal und erzeugt Duplikate. Dann ist nicht mehr klar, welcher Lauf zu korrigieren ist.
Fehler, die immer wieder auftreten:
Ein kleiner, aber wichtiger Punkt: trenne Nutzerbotschaften von Entwicklerdetails. Zeige dem Nutzer „12 Zeilen fehlten die Validierung“ und halte den technischen Trace in Logs.
Vor dem Release mach eine schnelle Überprüfung der Punkte, die Nutzer bemerken: Klarheit, Vertrauen und Wiederherstellung.
Jeder Job sollte einen Snapshot ausliefern, den du überall zeigen kannst: Zustand (queued, running, succeeded, failed, canceled), Fortschritt (0–100 oder Schritte), eine kurze Nachricht, Timestamps (created, started, finished) und einen Ergebniszeiger (wo das Output oder der Bericht liegt).
Mach UI-Zustände offensichtlich und konsistent. Nutzer brauchen einen verlässlichen Ort, um aktuelle und vergangene Jobs zu finden, plus klare Labels, wenn sie später zurückkehren ("Completed yesterday", "Still running"). Ein Recent-Jobs-Panel verhindert oft wiederholte Klicks und doppelte Arbeit.
Definiere Cancel- und Retry-Regeln in einfachen Worten. Entscheide, was Cancel für jeden Jobtyp bedeutet, ob Retry erlaubt ist und welche Eingaben wiederverwendet werden (gleiche Eingaben, neue Job-ID). Teste Randfälle wie Abbruch kurz vor Fertigstellung.
Behandle Teilfehler als echtes Ergebnis. Zeige eine kurze Zusammenfassung ("Imported 97, skipped 3") und biete einen handhabbaren Bericht an, den Nutzer sofort nutzen können.
Plane für Wiederherstellung. Jobs sollten Neustarts überleben und hängende Jobs sollten in einen klaren Zustand mit Anleitung ("Erneut versuchen" oder "Support mit Job-ID kontaktieren") übergehen.
Wähle einen Workflow, über den Nutzer sich bereits beschweren: CSV-Importe, Berichtsexporte, Massen-E-Mails oder Bildverarbeitung. Fang klein an und beweise die Grundlagen: Ein Job wird erstellt, er läuft, meldet Status und der Nutzer kann ihn später finden.
Ein einfaches Job-History-Screen ist oft der größte Qualitätsgewinn. Es gibt Menschen einen Ort zum Zurückkehren, statt auf einen Spinner zu starren.
Wähle zuerst eine Methode zur Fortschrittsübertragung. Polling ist für Version eins in Ordnung. Mach das Intervall so, dass es deinem Backend gut tut, aber so schnell, dass es lebendig wirkt.
Eine praktische Aufbau-Reihenfolge, die Nacharbeiten vermeidet:
Wenn du das ohne Code baust, kann eine No-Code-Plattform wie AppMaster helfen, indem du eine Job-Status-Tabelle (PostgreSQL) modellierst und aus Workflows aktualisierst, dann diesen Status in Web- und Mobile-UI darstellst. Für Teams, die Backend, UI und Hintergrundlogik an einem Ort bauen wollen, ist AppMaster (appmaster.io) für vollständige Anwendungen ausgelegt, nicht nur für Formulare oder Seiten.
Ein Background-Job startet schnell und gibt sofort eine Job-ID zurück, sodass die UI nutzbar bleibt. Eine langsame Anfrage lässt den Nutzer auf dieselbe Web-Antwort warten, was zu Neuladen, Doppelklicks und doppelten Einreichungen führen kann.
Halte es einfach: queued, running, done und failed, plus canceled, wenn du Abbrechen unterstützt. Füge ein separates Ergebnis wie „done with issues“ hinzu, wenn der Großteil erfolgreich war, aber einzelne Items fehlgeschlagen sind, damit Nutzer nicht denken, alles sei verloren.
Gib sofort nach dem Start eine eindeutige Job-ID zurück und rendere eine Task-Zeile oder Karte mit dieser ID. Die UI sollte den Status per Job-ID lesen, damit Nutzer beim Refreshen, Tab-Wechseln oder späteren Zurückkehren den Vorgang nicht verlieren.
Speichere den Job-Status in einer dauerhaften Datenbanktabelle, nicht nur im Arbeitsspeicher. Lege aktuellen Zustand, Timestamps, Fortschrittswert, eine kurze Nutzer-Nachricht und ein Ergebnis- oder Fehler-Resümee ab, damit die UI nach Neustarts immer die gleiche Ansicht aufbauen kann.
Verwende Prozent nur, wenn du ehrlich „X von Y“ melden kannst. Wenn kein echter Nenner vorhanden ist, zeige schrittbasierten Fortschritt wie „Validating“, „Importing“ und „Finalizing“ und halte die Nachricht aktuell, damit Nutzer Bewegung sehen.
Polling ist am einfachsten und für die meisten Apps ausreichend; starte mit etwa 2–5 Sekunden, solange der Nutzer die Seite aktiv betrachtet, und verlangsame es für lange Jobs oder Hintergrund-Tabs. Push-Updates wirken unmittelbarer, aber du brauchst immer ein Fallback, weil Verbindungen abbrechen.
Zeige an, dass Updates veraltet sind, anstatt so zu tun, als wäre der Job noch frisch, zum Beispiel mit „Last updated 2 minutes ago“ und biete eine manuelle Aktualisierung an. Auf dem Backend markiere Jobs ohne Heartbeat als stale und leite in einen klaren Zustand mit Handlungsempfehlung (erneut versuchen oder Support mit Job-ID kontaktieren).
Mache die nächste Aktion offensichtlich: kann der Nutzer weiterarbeiten, die Seite verlassen oder sicher abbrechen. Für Aufgaben, die länger als eine Minute dauern, hilft eine eigene Jobs- oder Activity-Ansicht, damit Nutzer Ergebnisse später finden, statt auf einen Spinner zu starren.
Behandle es als gleichwertiges Ergebnis und zeige beide Seiten klar, z. B. „Imported 9,380 of 9,500. 120 failed.“ Biete dann eine kleine, handhabbare Fehlerzusammenfassung an, die Nutzer ohne Log-Analyse beheben können, und lagere technische Details in internen Logs.
Definiere für jeden Job klar, was Cancel bedeutet, und spiegle das ehrlich wider, inklusive eines Zwischenzustands „cancel requested“, damit Nutzer nicht weiter klicken. Mache Arbeit möglichst idempotent, begrenze Retries und entscheide, ob ein Retry denselben Job fortsetzt oder eine neue Job-ID mit sauberer Audit-Trail erstellt.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


