Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Fehler beim Drag-and-Drop-Prozessdesign machen Workflows schwer änderbar und anfällig. Lerne häufige Anti-Pattern und praktische Refactoring-Schritte.
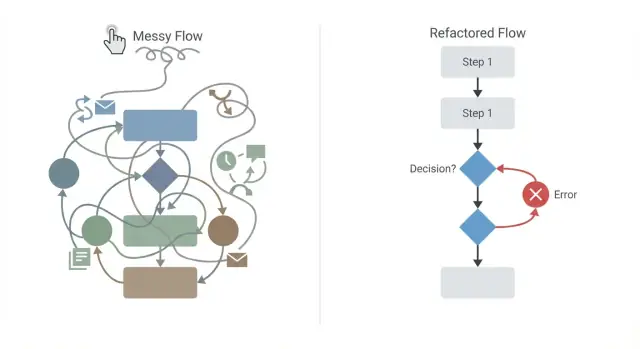
Visuelle Prozess-Editoren wirken sicher, weil man den ganzen Ablauf sehen kann. Trotzdem kann das Diagramm lügen. Ein Workflow kann sauber aussehen und in Produktion versagen, sobald echte Nutzer, echte Daten und echte Timing-Probleme auftauchen.
Viele Probleme entstehen, wenn man das Diagramm wie eine Checkliste behandelt, statt als das, was es wirklich ist: ein Programm. Blöcke enthalten weiterhin Logik. Sie erzeugen Zustand, verzweigen, wiederholen und lösen Nebenwirkungen aus. Wenn diese Teile nicht explizit gemacht werden, können „kleine" Änderungen das Verhalten stillschweigend verändern.
Ein Workflow-Anti-Pattern ist eine wiederkehrende schlechte Struktur, die immer wieder Ärger macht. Es ist kein einzelner Bug. Es ist eine Gewohnheit, etwa wichtigen Zustand in Variablen zu verstecken, die an einer Ecke des Diagramms gesetzt und anderswo verwendet werden, oder den Flow so wachsen zu lassen, dass niemand ihn noch durchdringen kann.
Die Symptome sind vertraut:
Fang mit dem an, was günstig und sichtbar ist: klarere Benennungen, engere Gruppierung, Entfernen toter Pfade und deutlich sichtbare Ein- und Ausgaben jedes Schritts. In Plattformen wie AppMaster bedeutet das oft, Business Processes fokussiert zu halten, sodass jeder Block genau eine Aufgabe erledigt und Daten offen weitergibt.
Dann plane tiefere Refaktoren für strukturelle Probleme: entwirre Spaghetti-Flows, zentralisiere Entscheidungen und füge Kompensationen für teilweise Erfolge hinzu. Das Ziel ist nicht ein hübscheres Diagramm, sondern ein Workflow, der jedes Mal gleich funktioniert und bei sich ändernden Anforderungen sicher anpassbar bleibt.
Viele visuelle Workflow-Fehler beginnen mit einem unsichtbaren Problem: Zustand, auf den du dich verlässt, den du aber nie klar benennst.
Zustand ist alles, was dein Workflow sich merken muss, um korrekt zu funktionieren. Dazu gehören Variablen (wie customer_id), Flags (wie is_verified), Timer und Retries, aber auch Zustand außerhalb deines Diagramms: eine Datenbankzeile, ein CRM-Eintrag, ein Zahlungsstatus oder eine bereits gesendete Nachricht.
Versteckter Zustand taucht auf, wenn dieses „Gedächtnis" an einem unerwarteten Ort lebt. Häufige Beispiele sind Knoteneinstellungen, die stillschweigend wie Variablen wirken; implizite Defaults, die du nie bewusst gesetzt hast; oder Nebenwirkungen, die Daten ändern, ohne es offensichtlich zu machen. Ein Schritt, der etwas „prüft“, aber zugleich ein Statusfeld aktualisiert, ist eine klassische Falle.
Oft funktioniert es, bis du eine kleine Änderung machst. Du verschiebst einen Knoten, verwendest einen Subflow wieder, änderst ein Default oder fügst einen neuen Zweig hinzu. Plötzlich verhält sich der Workflow „zufällig“, weil eine Variable überschrieben wurde, ein Flag nie zurückgesetzt wurde oder ein externes System einen leicht anderen Wert zurückgibt.
Zustand versteckt sich häufig in:
Mache Zustand explizit und benannt. Wenn ein Wert später wichtig ist, speichere ihn in einer klar benannten Variable, setze ihn nur an einer Stelle und setze ihn zurück, wenn er nicht mehr gebraucht wird.
Zum Beispiel: Behandle in AppMaster’s Business Process Editor jede wichtige Ausgabe als erstklassige Variable und nicht als etwas, das „verfügbar ist, weil ein Knoten zuvor lief". Eine kleine Änderung wie status in payment_status umzubenennen und ihn erst nach einer bestätigten Zahlungsantwort zu setzen, kann Stunden an Debugging sparen, wenn der Flow nächsten Monat verändert wird.
Ein Spaghetti-Flow ist ein Prozess, bei dem Verbindungen überall kreuzen, Schritte an überraschende Stellen zurückweisen und Bedingungen so tief verschachtelt sind, dass niemand den Happy Path ohne Zoomen und Scrollen erklären kann. Wenn dein Diagramm wie eine U-Bahn-Karte auf einer Serviette aussieht, zahlst du bereits den Preis.
Das macht Reviews unzuverlässig. Leute übersehen Randfälle, Freigaben dauern länger, und eine Änderung in einer Ecke kann etwas weit entfernte kaputtmachen. Im Incident-Fall ist es schwer, einfache Fragen zu beantworten wie „Welcher Schritt lief zuletzt?“ oder „Warum sind wir in diesen Zweig gegangen?"
Spaghetti wächst meist aus guten Absichten: Copy-Paste eines funktionierenden Zweigs „nur einmal", schnelle Fixes unter Druck, Ausnahmebehandlung als geschachtelte Bedingungen, Rücksprünge zu früheren Schritten anstatt wiederverwendbare Subprozesse zu erstellen, oder das Vermischen von Geschäftsregeln, Datenformatierung und Benachrichtigungen im selben Block.
Ein häufiges Beispiel ist Onboarding. Es beginnt sauber und wächst dann in separate Zweige für Testphasen, Partner-Referrals, manuelle Prüfung und VIP-Behandlung. Nach ein paar Sprints hat das Diagramm mehrere Rücksprünge zu „Dokumente sammeln" und mehrere Stellen, die die Willkommens-E-Mail senden.
Ein gesünderes Ziel ist einfach: ein Hauptpfad für den Normalfall plus klare Nebenpfade für Ausnahmen. In Tools wie AppMaster’s Business Process Editor bedeutet das oft, wiederholte Logik in einen wiederverwendbaren Subprozess auszulagern, Zweige nach Absicht zu benennen („Benötigt manuelle Prüfung") und Schleifen explizit und begrenzt zu halten.
Ein häufiges Muster ist eine lange Kette von Bedingungsknoten: prüfe A, dann prüfe A später nochmal, dann prüfe B an drei verschiedenen Stellen. Es beginnt mit „nur noch eine Regel", dann wird der Workflow zu einem Labyrinth, bei dem kleine Änderungen große Seiteneffekte haben.
Das größere Risiko sind verstreute Regeln, die nach und nach nicht mehr übereinstimmen. Ein Pfad genehmigt eine Anmeldung wegen hoher Kreditwürdigkeit; ein anderer Pfad blockiert dieselbe Anmeldung, weil ein älterer Schritt „fehlende Telefonnummer" noch als harten Stopp behandelt. Beide Entscheidungen mögen lokal sinnvoll erscheinen, zusammen erzeugen sie inkonsistente Ergebnisse.
Wenn dieselbe Regel an mehreren Stellen wiederholt wird, aktualisiert jemand eine Kopie und übersieht die anderen. Mit der Zeit entstehen Prüfungen, die ähnlich aussehen, aber unterschiedliche Logik enthalten: eine sagt „country = US", eine andere „country in (US, CA)" und eine dritte nutzt „currency = USD" als Proxy. Der Workflow läuft zwar, aber er wird unvorhersagbar.
Ein guter Refactor konsolidiert Entscheidungen in einem klar benannten Entscheidungs-Schritt, der eine kleine Menge möglicher Ergebnisse produziert. In Tools wie AppMaster’s Business Process Editor bedeutet das oft, verwandte Prüfungen in einem einzigen Decision-Block zu gruppieren und die Zweige sinnvoll zu benennen.
Halte die Ergebnisse einfach, zum Beispiel:
Leite dann alles über diesen einzelnen Entscheidungspunkt statt Mini-Entscheidungen im ganzen Flow zu verteilen. Wenn sich eine Regel ändert, änderst du sie einmal.
Ein konkretes Beispiel: Ein Signup-Verifizierungs-Workflow prüft das E-Mail-Format an drei Stellen (vor OTP, nach OTP und vor der Kontoerstellung). Verschiebe alle Validierungen in einen einzigen „Validate request“-Entscheid. Wenn das Ergebnis „Needs info" ist, leite an einen einzigen Nachrichtenschritt, der dem Nutzer genau sagt, was fehlt, anstatt später mit einer generischen Fehlermeldung zu scheitern.
Einer der teuersten Fehler ist die Annahme, ein Workflow würde entweder komplett gelingen oder komplett scheitern. Echte Abläufe schlagen oft nur teilweise fehl. Wenn ein späterer Schritt bricht, sitzt man auf einem Durcheinander: Geld abgebucht, Nachrichten gesendet, Datensätze erstellt, aber kein sauberer Weg zurück.
Beispiel: Du belastest die Karte eines Kunden und versuchst dann, die Bestellung anzulegen. Die Zahlung gelingt, die Auftragserstellung schlägt wegen eines Timeouts beim Inventar-Service fehl. Support bekommt wütende Mails, die Buchhaltung sieht die Abbuchung, und dein System hat keine passende Bestellung zur Auslieferung.
Kompensation ist der „Undo"- oder „sicher machen"-Pfad, der ausgeführt wird, wenn etwas nach einem Teil-Erfolg fehlschlägt. Er muss nicht perfekt sein, sollte aber absichtlich sein. Typische Ansätze sind die Rückabwicklung (Refund, Storno, Löschen eines Entwurfs), das Umwandeln des Ergebnisses in einen sicheren Zustand (z. B. „Payment captured, fulfillment pending"), Weiterleitung zur manuellen Prüfung mit Kontext und Idempotency-Checks, damit Retries nicht doppelt belasten oder doppelt senden.
Wichtig ist, wo du Kompensation platzierst. Verstecke nicht die ganze Aufräumarbeit in einer einzelnen „Error"-Box am Ende des Diagramms. Platziere sie neben dem riskanten Schritt, solange du noch die nötigen Daten hast (Payment-ID, Reservierungs-Token, externe Request-ID). In Tools wie AppMaster bedeutet das oft, diese IDs direkt nach dem Aufruf zu speichern und sofort bei Erfolg vs. Fehler zu verzweigen.
Eine nützliche Regel: Jeder Schritt, der mit einem externen System spricht, sollte zwei Fragen beantworten, bevor du weitermachst: „Was haben wir verändert?" und „Wie machen wir es rückgängig oder enthalten es, wenn der nächste Schritt fehlschlägt?"
Viele Fehler treten auf, sobald dein Workflow das eigene System verlässt. Externe Aufrufe scheitern auf unordentliche Weise: langsame Antworten, temporäre Ausfälle, doppelte Anfragen und partielle Erfolge. Wenn dein Diagramm annimmt „Aufruf erfolgreich" und einfach weiterläuft, sehen Nutzer irgendwann fehlende Daten, Doppelabbuchungen oder falsch getimte Benachrichtigungen.
Markiere Schritte, die aus Gründen, die du nicht kontrollierst, fehlschlagen können: externe APIs, Zahlungen und Rückerstattungen (z. B. Stripe), Nachrichten (E-Mail/SMS, Telegram), Dateioperationen und Cloud-Services.
Zwei Fallen sind besonders häufig: fehlende Timeouts und blinde Retries. Ohne Timeout kann eine langsame Anfrage den ganzen Prozess einfrieren. Mit Retries, aber ohne Regeln, verschlimmerst du das Problem leicht — z. B. dieselbe Nachricht dreimal senden oder Duplikate in einem Drittanbietersystem erzeugen.
Hier kommt Idempotency ins Spiel. Einfach gesagt ist eine idempotente Aktion sicher erneut auszuführen. Wenn der Workflow einen Schritt wiederholt, sollte er keine zweite Abbuchung, Bestellung oder Willkommens-Nachricht erzeugen.
Ein praktischer Fix ist, vor dem Aufruf einen Request-Key und Status zu speichern. In AppMaster’s Business Process Editor kann das so einfach sein wie das Schreiben eines Eintrags „payment_attempt: key=XYZ, status=pending" und das Aktualisieren auf „success" oder „failed" nach der Antwort. Wenn der Workflow den Schritt erneut erreicht, prüft er zuerst diesen Eintrag und entscheidet dann, wie weiter verfahren wird.
Ein zuverlässiges Muster sieht so aus:
Ein häufiger Fehler ist, einen einzelnen Schritt zu bauen, der stillschweigend vier Aufgaben erledigt: Input validieren, Werte berechnen, in die DB schreiben und Menschen benachrichtigen. Das wirkt effizient, macht Änderungen aber riskant. Wenn etwas schiefgeht, weißt du nicht, welcher Teil es verursacht hat, und du kannst den Schritt nicht sicher anderswo verwenden.
Ein Schritt ist überladen, wenn sein Name vage ist (z. B. „Handle order") und du dessen Ausgabe nicht in einem Satz beschreiben kannst. Ein weiteres Zeichen sind lange Eingabelisten, die nur von „einem Teil" des Schritts benutzt werden.
Überladene Schritte vermischen oft:
Teile den großen Schritt in kleinere, benannte Blöcke, wobei jeder Block eine Aufgabe und klare Eingabe sowie Ausgabe hat. Eine einfache Namenskonvention hilft: Verben für Schritte (Validate Address, Calculate Total, Create Invoice, Send Confirmation) und Nomen für Datenobjekte.
Verwende konsistente Namen für Ein- und Ausgaben. Zum Beispiel lieber „OrderDraft" (vor dem Speichern) und „OrderRecord" (nach dem Speichern) statt „order1/order2" oder „payload/result". Das macht das Diagramm auch nach Monaten noch lesbar.
Wenn ein Muster sich wiederholt, extrahiere es in einen wiederverwendbaren Subflow. In AppMaster’s Business Process Editor sieht das oft so aus, dass „Validate -> Normalize -> Persist" in einen gemeinsamen Block wandert, der von mehreren Workflows genutzt wird.
Beispiel: Ein Onboarding-Workflow, der „Benutzer erstellen, Berechtigungen setzen, E-Mail senden und Audit loggen" tut, kann in vier Schritte plus einen wiederverwendbaren „Write Audit Event"-Subflow aufgeteilt werden. Das vereinfacht Tests, macht Änderungen sicherer und reduziert Überraschungen.
Die meisten Workflow-Probleme entstehen, weil man „nur noch eine" Regel oder Verbindung hinzufügt, bis niemand mehr vorhersagen kann, was passiert. Refaktorisieren bedeutet, den Flow wieder lesbar zu machen und jede Nebenwirkung sowie jeden Fehlerfall sichtbar zu machen.
Beginne damit, den Happy Path als eine klare Linie von Start bis Ziel zu zeichnen. Wenn das Hauptziel „eine Bestellung genehmigen" ist, sollte diese Linie nur die wesentlichen Schritte zeigen, die nötig sind, wenn alles glattläuft.
Arbeit dann in kleinen Schritten:
payment_status ist besser als flag2)Ein schneller Weg, versteckte Komplexität zu finden, ist zu fragen: „Was passiert, wenn dieser Schritt zweimal läuft?" Wenn die Antwort „wir könnten doppelt abrechnen" oder „wir könnten zwei E-Mails senden" ist, brauchst du klaren Zustand und idempotentes Verhalten.
Beispiel: Ein Onboarding-Workflow erstellt ein Konto, weist einen Plan zu, belastet Stripe und sendet eine Willkommensnachricht. Wenn die Zahlung erfolgreich ist, aber die Willkommensnachricht fehlschlägt, möchtest du keinen zahlenden Benutzer ohne Zugang. Füge einen nahegelegenen Kompensationspfad hinzu: markiere den Benutzer als pending_welcome, versuche Messaging erneut und wenn Retries scheitern, refundiere und setze den Plan zurück.
In AppMaster wird dieses Aufräumen einfacher, wenn du den Business Process Editor flach hältst: kleine Schritte, klare Variablennamen und Subflows für „Charge payment" oder „Send notification", die du überall wiederverwenden kannst.
Refaktorisieren sollte Prozesse verständlicher machen und sicherer änderbar. Manche Fixes fügen jedoch neue Komplexität hinzu, besonders unter Zeitdruck.
Eine Falle ist, alte Pfade „nur für den Fall" beizubehalten, ohne klaren Schalter, Versionskennzeichen oder Löschdatum. Leute testen weiter den alten Weg, Support referenziert ihn, und bald pflegst du zwei Prozesse. Wenn du eine schrittweise Einführung brauchst, mach sie explizit: benenne den neuen Pfad, gate ihn mit einer sichtbaren Entscheidung und plane, wann der alte gelöscht wird.
Temporäre Flags sind ein weiteres Leck. Ein Flag für Debugging oder eine einwöchige Migration wird oft dauerhaft. Behandle Flags wie verderbliche Gegenstände: dokumentiere Zweck, bestimme einen Owner und setze ein Entfernungsdatum.
Die dritte Falle ist, Einmal-Ausnahmen hinzuzufügen statt das Modell zu ändern. Wenn du immer wieder „special case"-Knoten einfügst, wächst das Diagramm seitlich und Regeln werden unvorhersagbar. Taucht dieselbe Ausnahme zweimal auf, braucht das Datenmodell oder der Prozessstatus meist ein Update.
Und verstecke Geschäftsregeln nicht in unpassenden Knoten, nur damit es funktioniert. Das ist verlockend, besonders in visuellen Editoren, aber später findet niemand die Regel.
Warnzeichen:
Beispiel: Wenn VIP-Kunden eine andere Genehmigung brauchen, füge nicht in drei Stellen versteckte Checks ein. Füge einmal eine klare „Customer type"-Entscheidung hinzu und leite davon ausgehend weiter.
Die meisten Probleme tauchen kurz vor dem Launch auf: Jemand führt den Flow mit echten Daten aus und das Diagramm macht etwas, das niemand erklären kann.
Mache einen Walkthrough laut. Wenn der Happy Path eine lange Geschichte braucht, hat der Flow wahrscheinlich versteckten Zustand, doppelte Regeln oder zu viele zusammengefügte Zweige.
Führe den Flow mit drei Fällen aus: ein normaler Erfolg, ein wahrscheinlicher Fehler (z. B. Zahlungsablehnung) und ein seltsamer Randfall (fehlende optionale Daten). Achte auf jeden Schritt, der „irgendwie funktioniert" und das System halb fertig zurücklässt.
In Tools wie AppMaster’s Business Process Editor führt das oft zu einem sauberen Refactor: wiederholte Prüfungen in einen gemeinsamen Schritt ziehen, Nebenwirkungen als explizite Knoten anlegen und für jeden riskanten Aufruf einen klaren Kompensationspfad daneben hinzufügen.
Stell dir einen Kunden-Onboarding-Workflow vor, der drei Dinge tut: Identität verifizieren, Konto erstellen und ein kostenpflichtiges Abonnement starten. Klingt einfach, wird aber oft zu einem Flow, der „meist funktioniert" bis etwas ausfällt.
Die erste Version wächst Schritt für Schritt. Ein „Verified"-Häkchen wird ergänzt, dann ein „NeedsReview"-Flag, dann noch mehr Flags. Prüfungen wie „if verified" tauchen an mehreren Stellen auf, weil jede neue Funktion ihren eigenen Zweig hinzufügt.
Bald sieht der Workflow so aus: verifizieren, Benutzer erstellen, Karte belasten, Willkommens-E-Mail senden, Workspace erstellen, dann zurückspringen, um Verifizierung erneut zu prüfen, weil ein späterer Schritt davon abhängt. Wenn die Belastung gelingt, aber die Workspace-Erstellung fehlschlägt, gibt es kein Rollback. Der Kunde wurde belastet, sein Konto ist halb fertig, und Support-Tickets entstehen.
Ein saubereres Design macht Zustand sichtbar und kontrolliert. Ersetze verstreute Flags durch einen einzigen expliziten Onboarding-Status (z. B. Draft, Verified, Subscribed, Active, Failed). Lege die „Sollen wir weitermachen?"-Logik in einen Entscheidungspunkt.
Refactor-Ziele, die schnell Linderung bringen:
Modelliere danach Daten und Workflow zusammen. Wenn Subscribed wahr ist, speichere Subscription-ID, Payment-ID und Provider-Antwort an einem Ort, damit Kompensation ohne Rätselraten laufen kann.
Teste schließlich Fehlerfälle absichtlich: Verifizierungs-Timeouts, Zahlung erfolgreich aber E-Mail fehlgeschlagen, Workspace-Erstellungsfehler und doppelte Webhook-Events.
Wenn du diese Workflows in AppMaster baust, hilft es, Geschäftslogik in wiederverwendbare Business Processes zu halten und die Plattform sauberen Code generieren zu lassen, während sich Anforderungen ändern. Alte Zweige bleiben so nicht hängen. Wenn du den Refactor schnell prototypen willst (Backend, Web und Mobile zusammen), ist AppMaster auf appmaster.io genau für diese Art End-to-End-Workflows ausgelegt.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


