Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Erfahren Sie, wie Sie Datenaufbewahrungsrichtlinien für Geschäftsanwendungen gestalten – mit klaren Zeitfenstern, Archivierung sowie Lösch‑ oder Anonymisierungsabläufen, die Reports brauchbar halten.
Eine Aufbewahrungsrichtlinie ist eine klare Regelmenge, nach der Ihre App mit Daten umgeht: was behalten wird, wie lange, wo es gespeichert ist und was passiert, wenn die Zeit abläuft. Das Ziel ist nicht „alles löschen“. Es geht darum, das zu behalten, was Sie zum Betrieb und zur Erklärung vergangener Ereignisse brauchen, und das zu entfernen, was nicht mehr nötig ist.
Ohne Plan tauchen schnell drei Probleme auf. Der Speicher wächst stillschweigend, bis er richtig Geld kostet. Datenschutz- und Sicherheitsrisiken steigen mit jeder zusätzlichen Kopie persönlicher Daten. Und Reports werden unzuverlässig, wenn alte Datensätze nicht mehr zur heutigen Logik passen oder wenn Leute ad‑hoc löschen und Dashboards plötzlich schwanken.
Eine praktische Aufbewahrungsrichtlinie balanciert Tagesbetrieb, Beweisbarkeit und Kundenschutz:
Die meisten Geschäftsanwendungen haben ähnliche Datenbereiche, auch wenn sie unterschiedliche Bezeichnungen verwenden: Nutzerprofile, Transaktionen, Audit-Trails, Nachrichten und hochgeladene Dateien.
Eine Richtlinie ist teils Regel, teils Workflow, teils Tooling. Die Regel könnte lauten: „Supporttickets 2 Jahre aufbewahren.“ Der Workflow definiert, was das praktisch bedeutet: ältere Tickets in ein Archiv verschieben, Kundenfelder anonymisieren und festhalten, was passiert ist. Tools machen das wiederholbar und auditierbar.
Wenn Sie Ihre App mit AppMaster bauen, behandeln Sie Aufbewahrung als Produktverhalten, nicht als einmalige Aufräumaktion. Geplante Business Processes können Daten immer gleich archivieren, löschen oder anonymisieren, sodass Reports konsistent bleiben und Menschen den Zahlen vertrauen.
Bevor Sie Fristen festlegen, klären Sie, warum Sie Daten überhaupt aufbewahren. Aufbewahrungsentscheidungen werden meist von Datenschutzgesetzen, Kundenverträgen und Prüf‑ oder Steuerregeln geprägt. Lassen Sie diesen Schritt aus und Sie behalten entweder zu viel (höheres Risiko und Kosten) oder löschen später etwas, das Sie noch brauchen.
Trennen Sie zuerst „muss behalten werden“ von „nett zu haben“. Muss‑Daten sind oft Rechnungen, Buchungseinträge und Audit‑Logs, die brauchen, wer wann was gemacht hat. Nett‑zu‑haben können alte Chat‑Transkripte, detaillierte Klickverläufe oder rohe Ereignislogs sein, die nur gelegentlich für Analysen genutzt werden.
Anforderungen variieren außerdem nach Land und Branche. Ein Supportportal für einen Gesundheitsanbieter hat andere Zwänge als ein B2B‑Admin‑Tool. Selbst innerhalb eines Unternehmens können Nutzer in mehreren Ländern unterschiedliche Regeln für denselben Datentyp bedeuten.
Schreiben Sie Entscheidungen in einfacher Sprache und benennen Sie einen Verantwortlichen. „Wir behalten Tickets 24 Monate“ reicht nicht. Definieren Sie, was eingeschlossen ist, was ausgeschlossen ist und was am Ende passiert (archivieren, anonymisieren, löschen). Geben Sie eine Person oder ein Team an, damit Aktualisierungen nicht steckenbleiben, wenn Produkte oder Gesetze sich ändern.
Holen Sie früh Genehmigungen ein, bevor das Engineering baut. Legal bestätigt Mindestanforderungen und Löschverpflichtungen. Security bewertet Risiken, Zugriffskontrollen und Logging. Product bestätigt, was Nutzer weiterhin sehen müssen. Finance klärt Buchführungspflichten.
Beispiel: Sie können Rechnungsunterlagen 7 Jahre aufbewahren, Tickets 2 Jahre behalten und nach Kontoschluss Profilfelder anonymisieren, während aggregierte Metriken erhalten bleiben. In AppMaster lassen sich solche schriftlichen Regeln sauber auf geplante Prozesse und rollenbasierte Zugriffe abbilden, mit weniger Rätselraten später.
Aufbewahrungsrichtlinien scheitern, wenn Teams „2 Jahre aufbewahren“ festlegen, ohne zu wissen, was „es“ überhaupt ist. Erstellen Sie eine einfache Karte der vorhandenen Daten. Streben Sie keine Perfektion an. Streben Sie etwas an, das sowohl ein Support‑Lead als auch ein Finance‑Lead verstehen.
Ein praktischer Ausgangspunkt:
Markieren Sie dann die Sensitivität in einfachen Begriffen: personenbezogen (Name, E‑Mail), finanziell (Bankdaten, Zahlungstoken), Zugangsdaten (Passworthashes, API‑Schlüssel) oder regulierte Daten (z. B. Gesundheitsinformationen). Wenn Sie unsicher sind, kennzeichnen Sie es als „potenziell sensibel“ und behandeln es vorsichtig bis zur Klärung.
„Wo es lebt“ ist meist mehr als die Hauptdatenbank. Notieren Sie den genauen Ort: Datenbanktabellen, Dateispeicher, E‑Mail/SMS‑Logs, Analytics‑Tools oder Data‑Warehouses. Notieren Sie auch, wer von jedem Datensatz abhängt (Support, Vertrieb, Finance, Geschäftsführung) und wie oft. Das zeigt, was kaputtgeht, wenn Sie zu aggressiv löschen.
Eine hilfreiche Übung: Dokumentieren Sie den Zweck jedes Datensatzes in einem Satz. Beispiel: „Supporttickets werden aufbewahrt, um Streitfälle zu klären und Antwortzeit‑Trends zu verfolgen.“
Wenn Sie mit AppMaster bauen, können Sie dieses Inventar mit dem tatsächlich bereitgestellten Modell abgleichen, indem Sie Ihre Data Designer‑Modelle, Dateiverwaltung und aktivierte Integrationen prüfen.
Sobald die Karte existiert, wird Aufbewahrung eine Reihe kleiner, klarer Entscheidungen statt einer großen Vermutung.
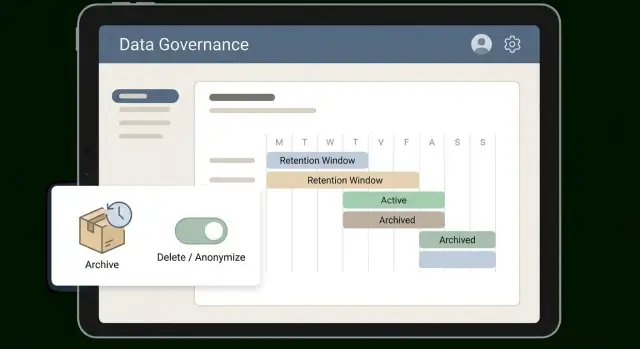
Ein Zeitfenster funktioniert nur, wenn es leicht zu erklären und noch einfacher anzuwenden ist. Viele Teams arbeiten gut mit einfachen Stufen, die zum Datengebrauch passen: hot (täglich gebraucht), warm (gelegentlich gebraucht), cold (als Nachweis behalten) und dann löschen oder anonymisieren. Diese Stufen machen eine abstrakte Richtlinie zur Routine.
Legen Sie Fristen nach Kategorie fest, nicht eine globale Zahl. Rechnungen und Zahlungsunterlagen brauchen in der Regel lange Cold‑Perioden für Steuern und Prüfungen. Support‑Chats verlieren oft schnell an Wert.
Entscheiden Sie auch, was die Uhr startet. „2 Jahre aufbewahren“ ist bedeutungslos, wenn Sie nicht definieren, „2 Jahre ab wann“. Wählen Sie je Kategorie einen Auslöser wie Erstellungsdatum, letzte Kundenaktivität, Schließdatum des Tickets oder Kontoschließung. Wenn Auslöser ohne klare Regeln variieren, wird geraten und die Aufbewahrung driftet.
Schreiben Sie Ausnahmen im Voraus auf, damit Teams später nicht improvisieren. Häufige Ausnahmen sind Legal Holds, Chargebacks und Betrugsuntersuchungen. Diese sollten Löschung pausieren. Sie sollten nicht zu versteckten Kopien führen.
Halten Sie die endgültigen Regeln kurz und prüfbar:
legal_hold=true: nicht löschen, bis freigegebenEin Archiv ist kein Backup. Backups dienen der Wiederherstellung nach Fehlern oder Ausfällen. Archive sind überlegt: Ältere Daten verlassen Ihre Hot‑Tabellen und kommen in günstigeren Speicher, bleiben aber für Prüfungen, Streitfälle und historische Fragen verfügbar.
Die meisten Apps brauchen beides. Backups sind häufig und umfangreich. Archive sind selektiv und kontrolliert; in der Regel holt man nur das zurück, was nötig ist.
Günstiger Speicher hilft nur, wenn Menschen weiterhin finden, was sie brauchen. Viele Teams nutzen eine separate Datenbank oder ein Schema, das auf leseintensive Abfragen ausgelegt ist, oder exportieren in Dateien plus eine Index‑Tabelle zur Suche. Wenn Ihre App um PostgreSQL modelliert ist (auch in AppMaster), kann ein „Archive“‑Schema oder eine separate Datenbank die Produktionstabellen schnell halten und dennoch erlauben, berechtigte Reports über archivierte Daten zu fahren.
Definieren Sie vor dem Format, was „durchsuchbar“ in Ihrem Geschäft bedeutet. Support braucht vielleicht Lookup nach E‑Mail oder Ticket‑ID. Finance braucht Monatszusammenfassungen. Audits brauchen Nachverfolgbarkeit nach Bestell‑ID.
Volle Datensätze erhalten Details, kosten aber mehr und erhöhen das Datenschutzrisiko. Zusammenfassungen (Monatszahlen, Counts, wichtige Statuswechsel) sind günstiger und reichen oft für Reporting.
Ein praxisnaher Ansatz:
Planen Sie Indexfelder im Voraus. Übliche Felder sind Primär‑ID, Nutzer-/Kunden‑ID, ein Datumsbucket (Monat), Region und Status. Ohne diese ist archivierte Daten zwar vorhanden, aber schwer abrufbar.
Definieren Sie auch Restore‑Regeln: Wer kann ein Restore anfordern, wer genehmigt, wohin werden Daten zurückgestellt und wie lange dauert es. Restores können bewusst langsam sein, wenn das Risiko reduziert, müssen aber vorhersehbar sein.
Aufbewahrungsrichtlinien führen meist zu einer Entscheidung: Datensätze löschen oder sie behalten und persönliche Details entfernen. Beides kann richtig sein, aber sie lösen unterschiedliche Probleme.
Ein Hard Delete entfernt den Datensatz physisch. Das passt, wenn kein rechtlicher oder geschäftlicher Grund zum Behalten besteht und das Behalten ein Risiko schafft (z. B. alte Chat‑Transkripte mit sensiblen Details).
Soft Delete markiert die Zeile als gelöscht (oft mit einem deleted_at‑Zeitstempel) und blendet sie in normalen Oberflächen und APIs aus. Soft Delete hilft, wenn Nutzer eine Wiederherstellung erwarten oder nachgelagerte Systeme noch Referenzen haben. Der Nachteil ist, dass soft‑gelöschte Daten weiterhin existieren, Speicher verbrauchen und durch Exporte leaken können, wenn Sie nicht sorgfältig filtern.
Anonymisierung behält das Ereignis oder die Transaktion, entfernt aber alles, was eine Person identifizieren kann. Wird sie korrekt durchgeführt, ist sie nicht umkehrbar. Pseudonymisierung ist anders: Hier ersetzen Sie Identifikatoren (z. B. E‑Mail) durch ein Token, behalten aber eine separate Zuordnung, die Re‑Identifikation erlaubt. Das kann bei Betrugsuntersuchungen helfen, ist aber nicht gleichbedeutend mit Anonymität.
Seien Sie explizit bei verwandten Daten, denn hier scheitern Richtlinien oft. Einen Datensatz löschen, aber Anhänge, Thumbnails, Caches, Suchindizes oder Analytics‑Kopien stehen lassen, kann das Ziel heimlich zunichtemachen.
Sie brauchen außerdem einen Beleg, dass Löschung stattgefunden hat. Führen Sie eine einfache Löschquittung: was entfernt oder anonymisiert wurde, wann der Job lief, welcher Workflow es ausgeführt hat und ob er erfolgreich abgeschlossen wurde. In AppMaster kann das eine Business Process sein, die beim Abschluss einen Audit‑Eintrag schreibt.
Reports brechen, wenn Sie Datensätze löschen oder anonymisieren, auf die Dashboards zeitlich verknüpft sind. Schreiben Sie vorher auf, welche Kennzahlen vergleichbar bleiben müssen. Andernfalls debuggen Sie später „Warum hat sich das Jahresdiagramm geändert?“
Starten Sie mit einer kurzen Liste an Metriken, die stabil bleiben müssen:
Überarbeiten Sie dann, was Sie fürs Reporting speichern, sodass es nicht personenbezogene Identifier braucht. Der sicherste Weg ist Aggregation. Statt jede rohe Zeile unbegrenzt zu behalten, speichern Sie tägliche Totals, Wochen‑Cohorts und Counts, die nicht auf eine Person zurückführbar sind. Beispiel: „Tickets pro Tag pro Kategorie“ und „Median erste Antwortzeit pro Woche“ reichen oft, auch wenn Sie später Ticketinhalt entfernen.
Manche Reports brauchen eine stabile Gruppierung über Zeit. Verwenden Sie einen surrogaten Analytics‑Key, der nicht direkt identifizierend ist (z. B. eine zufällige UUID nur für Analytics), und entfernen oder sperren Sie die Zuordnung zur echten Nutzer‑ID, sobald das Aufbewahrungsfenster abgelaufen ist.
Trennen Sie außerdem operative Tabellen von Reporting‑Tabellen, wenn möglich. Operative Daten ändern sich und werden gelöscht. Reporting‑Tabellen sollten append‑only‑Snapshots oder Aggregationen sein.
Anonymisierung hat Konsequenzen. Dokumentieren Sie, was sich ändert, damit Teams nicht überrascht sind:
Wenn Sie in AppMaster arbeiten, behandeln Sie Anonymisierung als Workflow: schreiben Sie zuerst Aggregationen, prüfen Sie Report‑Outputs und anonymisieren Sie dann Felder in den Quell‑Datensätzen.
Eine Aufbewahrungsrichtlinie funktioniert nur, wenn sie normales Softwareverhalten wird. Behandeln Sie sie wie ein Feature: definieren Sie Eingaben, Aktionen und machen Sie Ergebnisse sichtbar.
Starten Sie mit einer einseitigen Matrix. Für jeden Datentyp halten Sie Aufbewahrungsfenster, Auslöser und das nächste Vorgehen (behalten, archivieren, löschen, anonymisieren) fest. Wenn Leute es nicht in einer Minute erklären können, wird es nicht befolgt.
Fügen Sie klare Lifecycle‑Status hinzu, damit Datensätze nicht „mysteriös verschwinden“. Die meisten Apps kommen mit drei Zuständen aus: active, archived und pending delete. Speichern Sie den Status auf dem Datensatz selbst, nicht nur in einem Spreadsheet.
Eine praktische Implementierungssequenz:
archived_at und delete_after) und aktualisieren Sie Oberflächen und APIs, damit sie diese respektieren.Beispiel: Supporttickets bleiben 90 Tage aktiv, dann 18 Monate im Archiv, dann anonymisiert. Der Workflow markiert Tickets als archiviert, verschiebt große Anhänge in günstigen Speicher, behält Ticket‑IDs und Zeitstempel und ersetzt Namen und E‑Mails durch anonyme Werte.
In AppMaster können Lifecycle‑Felder im Data Designer leben und Archiv/ Löschlogik als geplante Business Processes laufen. Ziel sind wiederholbare Läufe mit klaren Logs, die leicht zu prüfen sind.
Die meisten Aufbewahrungsfehler betreffen nicht das gewählte Zeitfenster. Sie passieren, wenn Löschung die falschen Tabellen trifft, verwandte Dateien übersieht oder Keys ändert, von denen Reports abhängen.
Ein typisches Szenario: Das Supportteam löscht „alte Tickets“, vergisst aber Anhänge in einer separaten Tabelle oder im Dateispeicher. Später verlangt ein Prüfer Nachweise für eine Rückerstattung. Der Tickettext ist da, aber Screenshots fehlen.
Weitere Fallen:
user_id), ohne Dashboards, Joins und gespeicherte Queries anzupassenEin weiterer häufiger Bruch sind Reports, die auf personenbasierten Keys aufgebaut sind. E‑Mail und Name zu überschreiben ist oft unproblematisch. Die interne user_id zu ersetzen kann jedoch die Historie einer Person in mehrere Identitäten aufspalten, sodass Monthly Active Users oder LTV‑Reports driftet.
Zwei Maßnahmen helfen den meisten Teams: Erstens Reporting‑Keys definieren, die nie geändert werden (z. B. eine interne Account‑ID) und getrennt halten von personenbezogenen Feldern. Zweitens Löschung als kompletten Workflow implementieren, der alle verwandten Daten durchläuft, einschließlich Dateien und Logs. In AppMaster passt das meist gut zu einem Business Process, der von einem Nutzer oder Account ausgeht, Abhängigkeiten sammelt und dann sicher löscht oder anonymisiert.
Zum Schluss: Legen Sie fest, wer Löschung bei Legal Holds pausieren kann und wie diese Pause protokolliert wird. Ohne Verantwortliche werden Regeln inkonsistent angewendet.
Bevor Sie Lösch‑ oder Archivierungsjobs starten, machen Sie einen Realitätscheck. Die meisten Fehlschläge passieren, weil niemand weiß, wer die Daten besitzt, wo Kopien liegen oder wie Reports davon abhängen.
Eine Aufbewahrungsrichtlinie braucht klare Verantwortung und einen prüfbaren Plan, nicht nur ein Dokument.
Ein einfacher Validierungsschritt ist ein Trockenlauf: nehmen Sie ein kleines Batch (z. B. einen Kunden mit alten Fällen), führen Sie den Workflow in einer Testumgebung aus und vergleichen Sie wichtige Reports davor und danach.
Bewahren Sie Belege so auf, dass sie keine personenbezogenen Daten wieder einführen:
Wenn Sie auf AppMaster bauen, lassen sich diese Checks direkt implementieren: Retention‑Felder im Data Designer, geplante Jobs in der Business Process‑Umgebung und klare Audit‑Outputs.
Stellen Sie sich ein Kundenportal vor, das Supporttickets, Rechnungen und Rückerstattungen sowie rohe Aktivitätslogs (Logins, Pageviews, API‑Calls) speichert. Ziel ist Risikominimierung und Kostenreduktion, ohne Billing, Audits oder Trend‑Reporting zu zerstören.
Trennen Sie zuerst Daten, die Sie behalten müssen, von Daten, die nur für den täglichen Support gebraucht werden.
Ein einfacher Aufbewahrungsplan könnte sein:
Fügen Sie einen Archivschritt für ältere Tickets hinzu. Anstatt jede Nachricht ewig in den Haupttabellen zu behalten, verschieben Sie geschlossene Tickets, die älter als 18 Monate sind, in ein Archiv mit einer kleinen durchsuchbaren Zusammenfassung: Ticket‑ID, Daten, Produktbereich, Tags, Lösungscode und ein kurzer Auszug der letzten Agent‑Notiz. Das erhält Kontext ohne alle personenbezogenen Details.
Für geschlossene Konten wählen Sie Anonymisierung statt Löschung, wenn Sie Trends brauchen. Ersetzen Sie persönliche Identifikatoren (Name, E‑Mail, Adresse) durch zufällige Tokens, behalten Sie aber nicht identifizierende Felder wie Tariftyp und Monatsgesamtwerte. Speichern Sie aggregierte Nutzungsmetriken (DAU, Tickets pro Monat, Umsatz pro Monat) in einer separaten Reporting‑Tabelle, die niemals personenbezogene Daten enthält.
Monatliche Reports werden sich ändern, sollten aber nicht schlechter werden, wenn Sie es planen:
In AppMaster können Archiv‑ und Anonymisierungsschritte als geplante Business Processes laufen, sodass die Richtlinie jedes Mal gleich ausgeführt wird.
Eine Aufbewahrungsrichtlinie funktioniert, wenn Menschen sie befolgen können und das System sie konsequent durchsetzt. Starten Sie mit einer einfachen Retention‑Matrix: jeder Datensatz, Owner, Fenster, Auslöser, nächste Aktion (archivieren, löschen, anonymisieren) und Sign‑off. Besprechen Sie das mit Legal, Security, Finance und dem Support‑Team.
Automatisieren Sie nicht alles auf einmal. Wählen Sie einen Datensatz komplett durch, idealerweise etwas Alltägliches wie Supporttickets oder Login‑Logs. Machen Sie den Workflow real, betreiben Sie ihn eine Woche und bestätigen Sie, dass Reporting den Erwartungen entspricht. Dann erweitern Sie auf die nächsten Datensätze nach demselben Muster.
Halten Sie Automation beobachtbar. Basis‑Monitoring umfasst in der Regel:
Planen Sie auch die Nutzerseite: Was können Nutzer anfordern (Export, Löschung, Korrektur), wer genehmigt und was macht das System? Geben Sie dem Support ein kurzes internes Script: welche Daten sind betroffen, wie lange dauert es und was ist nach Löschung nicht wiederherstellbar.
Wenn Sie das ohne eigenen Code umsetzen wollen, ist AppMaster (appmaster.io) ein praktischer Ansatz für Retention‑Automation, weil Sie Lifecycle‑Felder im Data Designer modellieren und geplante Archiv‑ sowie Anonymisierungs‑Business Processes mit Audit‑Logging ausführen können. Starten Sie mit einem Datensatz, machen Sie ihn langweilig zuverlässig und wiederholen Sie das Muster für den Rest der App.
Eine Aufbewahrungsrichtlinie verhindert unkontrolliertes Datenwachstum und das „wir behalten einfach alles“-Verhalten. Sie legt vorhersehbare Regeln fest, was man wie lange behält und was am Ende passiert, damit Kosten, Datenschutzrisiken und Überraschungen in Reports nicht schleichend entstehen.
Fangen Sie mit dem Zweck der Daten an und wer sie braucht: Betrieb, Prüfungen/Steuern und Kundenschutz. Wählen Sie einfache Zeitfenster pro Datentyp (Rechnungen, Tickets, Logs, Dateien) und holen Sie früh Zustimmungen von Legal, Security, Finance und Product ein, damit Sie keine Workflows bauen, die später rückgängig gemacht werden müssen.
Definieren Sie für jede Kategorie einen klaren Auslöser, z. B. Schließdatum des Tickets, letzte Aktivität oder Kontoschließung. Wenn der Auslöser vage ist, interpretieren Teams „2 Jahre“ unterschiedlich und die Aufbewahrung driftet auseinander.
Verwenden Sie ein legal hold-Flag oder einen Status, der Archivierung/Anonymisierung/Löschung für bestimmte Datensätze pausiert, und machen Sie die Sperre sichtbar und auditierbar. Ziel ist, den normalen Ablauf anzuhalten, ohne versteckte Kopien zu erzeugen.
Ein Backup dient der Wiederherstellung nach Fehlern oder Ausfällen und ist breit und häufig. Ein Archiv ist eine gezielte Verschiebung älterer Daten aus den Hot-Tabellen in günstigeren, kontrollierten Speicher, der trotzdem abrufbar bleibt für Prüfungen oder Streitfälle.
Löschen, wenn es keinen rechtlichen oder geschäftlichen Grund mehr gibt und das Vorhandensein der Daten nur Risiko schafft. Anonymisieren, wenn Sie das Ereignis oder die Transaktion weiterhin für Trends oder Nachweise brauchen, aber personenbezogene Felder dauerhaft entfernen können.
Soft Deletes sind nützlich für Wiederherstellung und um Referenzen zu vermeiden, aber sie sind keine echte Entfernung. Soft-deleted Zeilen verbrauchen weiterhin Platz und können in Exports, Analytics oder Admin-Views auftauchen, wenn nicht überall korrekt herausgefiltert wird.
Sichern Sie Reporting, indem Sie langfristige Kennzahlen als Aggregationen oder Snapshots speichern, die nicht auf personenbezogenen Identifikatoren beruhen. Überarbeiten Sie das Reporting-Modell, bevor Sie Felder überschreiben, die Dashboards joinen.
Behandeln Sie Aufbewahrung wie ein Produktfeature: Lebenszyklusfelder auf Datensätzen, geplante Jobs zum Archivieren und anschließenden Löschen/Anonymisieren sowie Audit-Einträge, die dokumentieren, was passiert ist. In AppMaster lässt sich das sauber mit Data Designer-Feldern und geplanten Business Processes abbilden.
Führen Sie einen kleinen Dry-Run in einer testähnlichen Umgebung durch und vergleichen Sie die wichtigsten Kennzahlen vor und nach dem Lauf. Vergewissern Sie sich außerdem, dass Sie einen Datensatz überall finden können, wo er liegt (Datenbank, Dateispeicher, Exporte, Logs) und dass eine Lösch-/Anonymisierungsquittung erzeugt wird.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


