Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
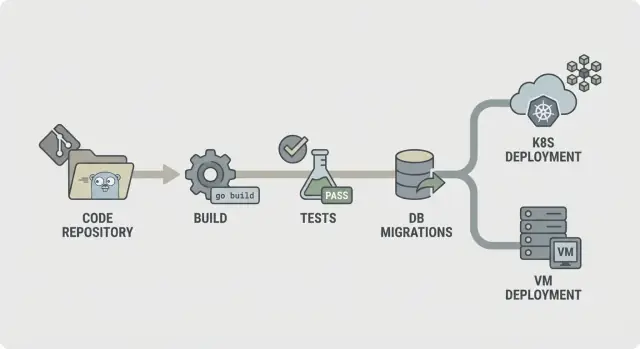
CI/CD für Go-Backends: praktische Pipeline-Schritte für Build, Tests, Migrationen und sichere Deploys zu Kubernetes oder VMs mit vorhersehbaren Umgebungen.
Manuelle Deployments scheitern auf langweilige, wiederkehrende Weise. Jemand baut auf dem Laptop mit einer anderen Go-Version, vergisst eine Umgebungsvariable, überspringt eine Migration oder startet den falschen Service neu. Das Release „funktioniert bei mir“, aber nicht in Produktion — und das merkt man erst, wenn Nutzer es spüren.
Generierter Code nimmt einem die Disziplin beim Release nicht ab. Wenn du ein Backend nach Anforderungsänderungen regenerierst, kannst du neue Endpunkte, neue Datenformen oder neue Abhängigkeiten einführen, auch wenn du nie von Hand am Code gearbeitet hast. Genau dann willst du, dass eine Pipeline wie ein Sicherheitsgeländer wirkt: Jede Änderung durchläuft dieselben Prüfungen, jedes Mal.
Vorhersehbare Umgebungen bedeuten, dass Build- und Deploy-Schritte unter Bedingungen laufen, die du benennen und wiederholen kannst. Ein paar Regeln decken die meisten Fälle ab:
Der Sinn von CI/CD für Go-Backends ist nicht Automation um der Automation willen. Es geht um reproduzierbare Releases mit weniger Stress: regenerieren, Pipeline laufen lassen und darauf vertrauen, dass das Ergebnis deploybar ist.
Wenn du einen Generator wie AppMaster verwendest, der Go-Backends erzeugt, ist das noch wichtiger. Regeneration ist ein Feature, fühlt sich aber nur sicher an, wenn der Weg von der Änderung bis zur Produktion konsistent, getestet und vorhersehbar ist.
„Vorhersehbar“ heißt: dieselben Eingaben erzeugen dasselbe Ergebnis, egal wo du es ausführst. Für CI/CD von Go-Backends beginnt das damit, dass du vereinbarst, was zwischen Dev, Staging und Prod identisch bleiben muss.
Die üblichen Nicht-Verhandelbaren sind die Go-Version, dein Basis-OS-Image, Build-Flags und wie Konfiguration geladen wird. Wenn einer dieser Punkte je nach Umgebung variiert, bekommst du Überraschungen wie anderes TLS-Verhalten, fehlende Systempakete oder Bugs, die nur in Produktion auftauchen.
Die meisten Drift-Probleme zeigen sich an denselben Stellen:
Die Wahl zwischen Kubernetes und VMs ist weniger eine Frage von „was ist am besten“ als davon, was dein Team ruhig betreiben kann.
Kubernetes passt gut, wenn du Autoscaling, Rolling Updates und einen standardisierten Weg brauchst, viele Services zu betreiben. Es hilft auch, Konsistenz durchzusetzen, weil Pods von denselben Images laufen. VMs können richtig sein, wenn du ein oder wenige Services, ein kleines Team hast und weniger bewegliche Teile willst.
Du kannst die Pipeline gleich halten, auch wenn die Runtimes unterschiedlich sind, indem du das Artefakt und den Vertrag darum standardisierst. Zum Beispiel: immer dasselbe Container-Image in CI bauen, dieselben Testschritte ausführen und dasselbe Migrations-Bundle veröffentlichen. Dann ändert sich nur der Deploy-Schritt: Kubernetes wendet einen neuen Image-Tag an, während VMs das Image ziehen und den Service neu starten.
Ein praktisches Beispiel: Ein Team regeneriert ein Go-Backend mit AppMaster und deployed nach Staging auf Kubernetes, nutzt in Produktion aber eine VM. Wenn beide genau dasselbe Image ziehen und Konfiguration aus derselben Art von Secret-Store laden, wird „verschiedene Runtime" zur reinen Deployment-Details und nicht zur Fehlerquelle. Wenn du AppMaster (appmaster.io) verwendest, passt dieses Modell gut, weil du zu Managed Cloud-Zielen deployen oder Quellcode exportieren und die gleiche Pipeline auf eigener Infrastruktur laufen lassen kannst.
Eine vorhersehbare Pipeline ist leicht zu beschreiben: Code prüfen, bauen, beweisen, dass es funktioniert, genau das Getestete ausliefern und dann jedes Mal auf dieselbe Weise deployen. Diese Klarheit ist besonders wichtig, wenn dein Backend regeneriert wird (z. B. von AppMaster), weil Änderungen viele Dateien auf einmal berühren können und du schnelles, konsistentes Feedback brauchst.
Ein geradliniger CI/CD-Flow für Go-Backends sieht so aus:
Strukturiere die Pipeline so, dass Fehler früh stoppen. Wenn Lint failt, sollte nichts anderes laufen. Wenn der Build fehlschlägt, solltest du nicht Zeit damit verschwenden, Datenbanken für Integrationschecks zu starten. Das hält Kosten niedrig und die Pipeline fühlt sich schnell an.
Nicht jeder Schritt muss bei jedem Commit laufen. Eine häufige Aufteilung ist:
Entscheide, was du als Artefakte aufbewahrst. Üblich sind die kompilierten Binärdateien oder Container-Images (das, was du deployst), sowie Migrations-Logs und Testreports. Das macht Rollbacks und Audits einfacher, weil du genau aufzeigen kannst, was getestet und promoted wurde.
Eine Build-Stage sollte eine Frage beantworten: Können wir dieselbe Binärdatei heute, morgen und auf einem anderen Runner erzeugen. Wenn das nicht stimmt, wird jeder spätere Schritt (Tests, Migrationen, Deploy) schwerer zu vertrauen.
Beginne damit, die Umgebung einzufrieren. Verwende eine feste Go-Version (z. B. 1.22.x) und ein festes Runner-Image (Linux-Distribution und Paketstände). Vermeide "latest"-Tags. Kleine Änderungen in libc, Git oder der Go-Toolchain können "funktioniert auf meiner Maschine"-Fehler erzeugen, die schwer zu debuggen sind.
Module-Caching hilft, aber nur, wenn du es als Speed-Boost und nicht als Quelle der Wahrheit behandelst. Cache den Go-Build-Cache und den Modul-Download-Cache, aber keye ihn z. B. mit go.sum (oder lösche ihn auf main, wenn Abhängigkeiten sich ändern), sodass neue Dependencies immer einen sauberen Download auslösen.
Füge ein schnelles Gate vor der Kompilierung hinzu. Halte es kurz, damit Entwickler es nicht umgehen. Typisch sind gofmt-Checks, go vet und (wenn schnell genug) staticcheck. Scheitere auch bei fehlenden oder veralteten generierten Dateien — das ist ein häufiges Problem in regenerierten Codebasen.
Kompiliere reproduzierbar und bette Versionsinfo ein. Flags wie -trimpath helfen, und mit -ldflags kannst du Commit-SHA und Build-Zeit injizieren. Erzeuge je Service genau ein benanntes Artefakt. So lässt sich leicht nachvollziehen, was in Kubernetes oder auf einer VM läuft, besonders wenn dein Backend regeneriert wird.
Tests helfen nur, wenn sie jedes Mal gleich laufen. Strebe zuerst schnelles Feedback an und füge dann tiefere Prüfungen hinzu, die trotzdem in einer vorhersehbaren Zeit fertig werden.
Starte mit Unit-Tests bei jedem Commit. Setze ein striktes Timeout, damit ein hängender Test laut fehlschlägt statt die ganze Pipeline aufzuhalten. Entscheide auch, was „ausreichende“ Coverage für dein Team bedeutet. Coverage ist kein Pokal, aber eine Mindestanforderung hilft, langsamen Qualitätsverfall zu verhindern.
Eine stabile Test-Stage umfasst typischerweise:
go test ./... mit Timeout pro Package und globalem Job-TimeoutDer Race-Detector ist wertvoll, kann Builds aber deutlich verlangsamen. Ein guter Kompromiss ist, ihn auf Pull Requests und nächtlichen Builds oder nur für ausgewählte Packages laufen zu lassen, statt bei jedem Push.
Flaky Tests sollten den Build failen. Wenn du einen Test quarantänen musst, halte ihn sichtbar: verschiebe ihn in einen separaten Job, der weiterhin läuft und rot meldet, und setze einen Owner sowie eine Deadline zur Behebung.
Speichere Test-Output, damit Debugging nicht das komplette Wiederholen erfordert. Hebe rohe Logs sowie einen einfachen Report (Pass/Fail, Dauer und die langsamsten Tests) auf. Das erleichtert das Erkennen von Regressionen, besonders wenn regenerierte Änderungen viele Dateien berühren.
Unit-Tests sagen, dass dein Code isoliert funktioniert. Integrationschecks prüfen, ob der Service beim Starten, beim Verbinden zu echten Diensten und beim Beantworten echter Requests korrekt agiert. Dieses Sicherheitsnetz fängt Probleme, die nur beim Zusammenspiel sichtbar werden.
Nutze ephemere Abhängigkeiten, wenn dein Code sie zum Start braucht. Ein temporäres PostgreSQL (und Redis, falls verwendet), das nur für den Job hochfährt, reicht meist aus. Halte die Versionen nah an der Produktion, aber versuche nicht, jede Produktions-Detail exakt zu kopieren.
Eine gute Integration-Stufe ist bewusst klein:
Für API-Contract-Checks konzentriere dich auf Endpunkte, deren Ausfall am meisten schadet. Du brauchst kein komplettes End-to-End-Suite. Ein paar Request/Response-Wahrheiten reichen: Pflichtfelder führen zu 400, fehlende Auth zu 401 und ein Happy-Path liefert 200 mit den erwarteten JSON-Schlüsseln.
Um Integrationstests oft genug laufen zu lassen, begrenze den Umfang und kontrolliere die Laufzeit. Bevorzuge eine Datenbank mit kleinem Dataset. Führe nur wenige Requests aus. Setze harte Timeouts, sodass ein hängender Boot in Sekunden statt Minuten fehlschlägt.
Wenn du dein Backend regenerierst (z. B. mit AppMaster), haben diese Checks ein größeres Gewicht. Sie bestätigen, dass der regenerierte Service sauber startet und die API spricht, die deine Web- oder Mobile-App erwartet.
Beginne damit, zu entscheiden, wo Migrationen laufen. Sie in CI auszuführen fängt Fehler früh ab, aber CI sollte normalerweise nicht die Produktion berühren. Die meisten Teams führen Migrationen während des Deploys (als dedizierten Schritt) oder als separaten "migrate"-Job aus, der fertig sein muss, bevor die neue Version startet.
Eine praktische Regel: Bau und Tests in CI, dann Migrationen so nah wie möglich an der Produktion ausführen, mit Produktions-Credentials und produktion-ähnlichen Limits. In Kubernetes ist das oft ein One-Off Job. Auf VMs kann es ein skriptgesteuerter Befehl im Release-Schritt sein.
Reihenfolge ist wichtiger, als viele erwarten. Nutze timestamp-basierte Dateien (oder sequenzielle Nummern) und erzwinge "apply in order, exactly once." Mach Migrationen, wo möglich, idempotent, sodass ein Retry keine Duplikate erzeugt oder halb abstürzt.
Halte die Migrationsstrategie einfach:
Füge eine Sicherheitsklappe hinzu, bevor etwas läuft. Das kann ein DB-Lock sein, sodass nur eine Migration gleichzeitig läuft, plus eine Policy wie "keine destruktiven Änderungen ohne Genehmigung." Zum Beispiel: die Pipeline soll fehlschlagen, wenn eine Migration DROP TABLE oder DROP COLUMN enthält, außer ein manueller Gate wurde genehmigt.
Rollback ist die harte Wahrheit: Viele Schema-Änderungen sind nicht umkehrbar. Wenn du eine Spalte löschst, sind die Daten weg. Plane Rollbacks als Vorwärts-Fixes: behalte ein Down-Migration nur, wenn es wirklich sicher ist, und setze ansonsten auf Backups plus eine neue Vorwärts-Migration.
Paar jede Migration mit einem Recovery-Plan: Was tust du, wenn sie mittendrin scheitert, und was, wenn die App zurückgerollt werden muss. Wenn du Go-Backends generierst (z. B. mit AppMaster), behandle Migrationen als Teil deines Release-Vertrags, sodass regenerierter Code und Schema synchron bleiben.
Eine Pipeline fühlt sich nur dann vorhersehbar an, wenn das, was du deployst, immer genau das ist, was du getestet hast. Das hängt von Packaging und Konfiguration ab. Behandle das Build-Output als versiegeltes Artefakt und halte alle Umgebungsunterschiede außerhalb davon.
Packaging bedeutet in der Regel zwei Wege. Ein Container-Image ist Standard für Kubernetes, weil es die OS-Schicht pinnt und Rollouts konsistent macht. Ein VM-Bundle kann genauso verlässlich sein, solange es die kompilierte Binärdatei plus die wenigen Laufzeit-Dateien enthält (z. B. CA-Zertifikate, Templates oder statische Assets) und du es jedes Mal gleich auslieferst.
Konfiguration sollte extern sein, nicht in die Binary eingebettet. Verwende Umgebungsvariablen für die meisten Einstellungen (Ports, DB-Host, Feature-Flags). Nutze eine Konfigdatei nur, wenn Werte lang oder strukturiert sind, und halte sie umgebungsspezifisch. Wenn du einen Config-Service nutzt, behandle ihn wie eine Abhängigkeit: gesperrte Berechtigungen, Audit-Logs und ein klares Fallback.
Secrets sind die Grenze, die du nicht überschreitest. Sie gehören nicht ins Repo, nicht ins Image und nicht in CI-Logs. Vermeide das Ausgeben von Connection-Strings beim Start. Bewahre Secrets im CI-Secret-Store und injiziere sie beim Deploy.
Um Artefakte nachvollziehbar zu machen, gib jedem Build eine Identität: tagge Artefakte mit Version und Commit-Hash, füge Build-Metadaten (Version, Commit, Build-Zeit) in einen Info-Endpunkt ein und protokolliere das Artefakt-Tag im Deployment-Log. Mach es einfach, mit einem Befehl oder Dashboard zu sagen, „was läuft da gerade“.
Wenn du Go-Backends generierst (z. B. mit AppMaster), ist diese Disziplin noch wichtiger: Regeneration ist sicher, wenn deine Artefakt-Namenskonventionen und Konfig-Regeln jedes Release reproduzierbar machen.
Die meisten Deploy-Fehler sind kein "schlechter Code". Sie entstehen durch nicht übereinstimmende Umgebungen: unterschiedliche Konfiguration, fehlende Secrets oder ein Service, der zwar startet, aber nicht wirklich bereit ist. Ziel ist simpel: dasselbe Artefakt überall deployen und nur die Konfiguration ändern.
Auf Kubernetes strebe kontrollierte Rollouts an. Nutze Rolling Updates, damit Pods schrittweise ersetzt werden, und füge Readiness- und Liveness-Probes hinzu, damit die Plattform weiß, wann sie Traffic senden und wann sie einen hängenden Container neu starten soll. Resource Requests und Limits sind wichtig, denn ein Go-Service, der auf einem großen CI-Runner läuft, kann auf einem kleinen Node OOM-gekillt werden.
Halte Konfiguration und Secrets aus dem Image. Baue ein Image pro Commit und injiziere umgebungsspezifische Einstellungen zur Deploy-Zeit (ConfigMaps, Secrets oder dein Secret-Manager). So laufen Staging und Produktion mit denselben Bits.
Wenn du auf VMs deployst, kann systemd dein "Mini-Orchestrator" sein. Erstelle eine Unit-Datei mit klarem Arbeitsverzeichnis, einer Environment-Datei und einer Restart-Policy. Mach Logs vorhersehbar, indem du stdout/stderr an deinen Log-Collector oder journald schickst, sodass Incidents keine SSH-Schnitzeljagd werden.
Du kannst auch ohne Cluster sichere Rollouts machen. Ein einfaches Blue/Green-Setup funktioniert: zwei Verzeichnisse (oder zwei VMs) vorhalten, Load Balancer umbuchen und die vorherige Version bereit halten für schnellen Rollback. Canary ist ähnlich: leite nur einen kleinen Anteil Traffic zur neuen Version, bevor du endgültig umschaltest.
Bevor du ein Deploy als „fertig“ markierst, führe dieselben Post-Deploy-Smoke-Checks überall aus:
Wenn du Backends regenerierst (z. B. ein AppMaster Go-Backend), bleibt dieser Ansatz stabil: einmal bauen, Artefakt deployen und die Umgebungs-Konfiguration die Unterschiede steuern lassen — nicht ad-hoc-Skripte.
Die meisten kaputten Releases entstehen nicht wegen "schlechtem Code". Sie passieren, wenn die Pipeline von Lauf zu Lauf unterschiedlich arbeitet. Wenn du CI/CD für Go-Backends ruhig und vorhersehbar machen willst, achte auf diese Muster.
Migrationen automatisch bei jedem Deploy laufen zu lassen, ohne Schutzmechanismen, ist klassisch. Eine Migration, die eine Tabelle sperrt, kann einen stark belasteten Service lahmlegen. Setze Migrationen hinter einen expliziten Schritt, erfordere Genehmigung für Prod und sorge dafür, dass sie sicher wiederholt werden können.
latest-Tags oder ungepinnten Basisimages zu verwenden, ist ein weiterer leichter Weg zu mysteriösen Fehlern. Pinne Docker-Images und Go-Versionen, damit deine Build-Umgebung nicht driftet.
Das „temporäre“ Teilen einer Datenbank über Umgebungen wird oft dauerhaft und führt dazu, dass Testdaten in Staging gelangen oder Staging-Skripte Produktion treffen. Trenne Datenbanken (und Credentials) pro Umgebung, auch wenn das Schema gleich ist.
Fehlende Health- und Readiness-Checks lassen ein Deploy „erfolgreich“ aussehen, obwohl der Service kaputt ist und Traffic zu früh ankommt. Füge Checks hinzu, die echtes Verhalten abbilden: startet die App, kann sie die Datenbank erreichen und eine Anfrage bedienen?
Schließlich macht unklare Verantwortlichkeit für Secrets, Config und Zugriffe Releases zu Ratespielen. Jemand muss Eigentümer sein, wie Secrets erstellt, rotiert und injiziert werden.
Ein realistisches Szenario: Ein Team merged eine Änderung, die Pipeline deployed und eine automatische Migration läuft zuerst. Sie geht in Staging durch (kleine Daten), scheitert aber in Produktion (große Daten). Mit gepinnten Images, Trennung der Umgebungen und einem gated Migration-Schritt hätte das Deploy sicher gestoppt.
Wenn du Go-Backends generierst (z. B. mit AppMaster), sind diese Regeln noch wichtiger, weil Regeneration viele Dateien auf einmal berühren kann. Vorhersehbare Eingaben und explizite Gates verhindern, dass „große“ Änderungen in riskante Releases kippen.
Nutze das als Schnelltest für CI/CD bei Go-Backends. Wenn du jede Frage klar mit „ja“ beantworten kannst, werden Releases leichter.
Beschränke Produktionszugriff und mache ihn auditierbar. CI sollte mit einem dedizierten Service-Account deployen, Secrets zentral verwaltet werden und jede manuelle Aktion in Produktion eine klare Spur hinterlassen (wer, was, wann).
Ein kleines Ops-Team von vier Leuten releast wöchentlich. Sie regenerieren ihr Go-Backend oft, weil das Produktteam Workflows verfeinert. Ziel: weniger nächtliche Fixes und Releases, die niemand überraschen.
Ein typischer Freitag-Change: Sie fügen ein neues Feld zu customers (Schema-Änderung) hinzu und aktualisieren die API, die es schreibt (Code-Änderung). Die Pipeline behandelt beides als ein Release. Sie baut ein Artefakt, testet genau dieses Artefakt und wendet erst dann Migrationen an und deployed. So ist die Datenbank nie weiter als der Code, der sie erwartet, und der Code wird nie ohne dazugehöriges Schema deployed.
Wenn eine Schema-Änderung enthalten ist, fügt die Pipeline ein Safety-Gate hinzu. Sie prüft, ob die Migration additiv ist (z. B. nullable Spalte) und markiert riskante Aktionen (DROP COLUMN oder große Table-Rewrites). Ist die Migration riskant, stoppt das Release vor Produktion. Das Team schreibt die Migration sicherer oder plant ein Wartungsfenster.
Wenn Tests fehlschlagen, bewegt sich nichts weiter. Dasselbe gilt, wenn Migrationen in einer Vorproduktionsumgebung fehlschlagen. Die Pipeline sollte nicht versuchen, Änderungen "diesmal trotzdem" durchzudrücken.
Einfache nächste Schritte, die bei den meisten Teams funktionieren:
Wenn du Backends mit AppMaster generierst, halte Regeneration in denselben Pipeline-Stufen: regenerieren, bauen, testen, in einer sicheren Umgebung migrieren und dann deployen. Behandle generierten Source wie jeden anderen Source. Jedes Release sollte aus einer getaggten Version reproduzierbar sein, mit denselben Schritten jedes Mal.
Pinne deine Go-Version und die Build-Umgebung, sodass dieselben Eingaben immer dieselbe Binärdatei oder das gleiche Image erzeugen. So verschwinden "works on my machine"-Unterschiede und Fehler lassen sich leichter reproduzieren und beheben.
Regenerieren kann Endpunkte, Datenmodelle und Abhängigkeiten ändern, selbst wenn niemand am Code von Hand gearbeitet hat. Eine Pipeline sorgt dafür, dass diese Änderungen jedes Mal dieselben Prüfungen durchlaufen, sodass Regeneration sicher statt riskant ist.
Einmal bauen und das exakt gleiche Artefakt durch Dev, Staging und Prod befördern. Wenn du für jede Umgebung neu baust, kannst du unbeabsichtigt etwas ausliefern, das du nie getestet hast, selbst wenn der Commit identisch ist.
Führe schnelle Gates bei jedem Pull Request aus: Formatierung, grundlegende statische Checks, Build und Unit-Tests mit Timeouts. Halte es so schnell, dass Entwickler es nicht umgehen, und so strikt, dass fehlerhafte Änderungen früh stoppen.
Nutze eine kleine Integrationsstufe, die den Service mit produktionsähnlicher Konfiguration hochfährt und mit echten Abhängigkeiten wie PostgreSQL spricht. Ziel ist, zu erkennen, dass "es kompiliert" nicht gleichbedeutend mit "es startet und spricht die API" ist, ohne CI zu einem stundenlangen End-to-End-Lauf zu machen.
Behandle Migrationen als kontrollierten Release-Schritt, nicht als etwas, das automatisch bei jedem Deploy läuft. Führe sie mit klaren Logs und einer Single-Run-Sperre aus und sei ehrlich bezüglich Rollbacks: Viele Schema-Änderungen brauchen Vorwärts-Fixes oder Backups, nicht einfaches Zurückrollen.
Nutze Readiness-Checks, damit Traffic erst zu neuen Pods geleitet wird, wenn der Service wirklich bereit ist, und Liveness-Checks, um festgefahrene Container neu zu starten. Außerdem realistische Resource Requests/Limits setzen, damit ein Service, der in CI läuft, in Produktion nicht OOM-gekillt wird.
Eine einfache systemd-Unit plus ein konsistentes Release-Skript reichen oft für ruhige Deploys auf VMs. Behalte dasselbe Artefakt-Modell wie bei Containern bei, wenn möglich, und füge einen kleinen Post-Deploy-Smoke-Check hinzu, sodass ein scheinbar erfolgreicher Neustart nicht einen defekten Service versteckt.
Geheimnisse gehören nie ins Repo, nicht ins Image und nicht in CI-Logs. Injiziere Secrets zur Deploy-Zeit aus einem verwalteten Secret-Store, begrenze Zugriffsrechte und mache Rotation zur Routine, nicht zur Notfallaktion.
Lege Regeneration in dieselben Pipeline-Stufen wie jede andere Änderung: regenerieren, bauen, testen, paketieren, dann mit Gates migrieren und deployen. Wenn du AppMaster nutzt, erlaubt dir das schnelles Arbeiten, ohne zu raten, was sich geändert hat, und du kannst den No-Code-Flow zum sicheren Regenerieren und Ausliefern nutzen.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


