Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Naucz się zmian schematu bez przestojów dzięki migracjom addytywnym, bezpiecznym backfillom i wdrożeniom etapowym, które utrzymują działanie starszych klientów podczas wydania.
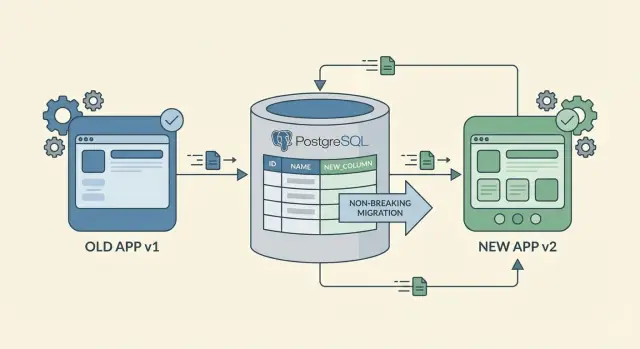
Brak przestojów przy zmianach schematu nie oznacza, że nic się nie zmienia. Oznacza to, że użytkownicy mogą pracować dalej, podczas gdy aktualizujesz bazę i aplikację, bez awarii i blokujących przepływów pracy.
Przestój to każda chwila, gdy system przestaje zachowywać się normalnie. Może to wyglądać jak błędy 500, limity czasu API, ekrany które ładują się, ale pokazują puste lub błędne wartości, zadania tła, które się wykrzaczają, albo baza danych przyjmująca odczyty, ale blokująca zapisy, bo długa migracja trzyma locki.
Zmiana schematu może złamać więcej niż główny interfejs aplikacji. Typowe punkty awarii to klienci API oczekujący starego kształtu odpowiedzi, zadania tła czytające lub zapisujące konkretne kolumny, raporty bezpośrednio zapytujące tabele, integracje z zewnętrznymi usługami i wewnętrzne skrypty admina, które „działały wczoraj”.
Starsze aplikacje mobilne i cachowane klienty są częstym problemem, bo nie możesz ich zaktualizować natychmiast. Niektórzy użytkownicy trzymają wersję aplikacji przez tygodnie. Inni mają niestabilne połączenie i ponawiają stare żądania. Nawet klienci webowi mogą zachowywać się jak „starsze wersje”, gdy service worker, CDN lub proxy trzymają nieaktualny kod lub założenia.
Prawdziwy cel to nie „jedna duża migracja, która skończy się szybko”. To sekwencja małych kroków, w której każdy krok działa samodzielnie, nawet gdy klienci mają różne wersje.
Praktyczna definicja: powinieneś móc wdrożyć nowy kod i nowy schemat w dowolnej kolejności, a system nadal działa.
Takie podejście pomaga uniknąć klasycznej pułapki: wdrożenia nowej aplikacji oczekującej nowej kolumny zanim kolumna istnieje, albo dodania kolumny, której stary kod nie potrafi obsłużyć. Planuj zmiany tak, aby były najpierw addytywne, wprowadzaj je etapami i usuwaj stare ścieżki dopiero gdy będziesz pewien, że nikt ich już nie używa.
Najbezpieczniejsza droga do zmian schematu bez przestojów to dodawanie, nie zastępowanie. Dodanie nowej kolumny lub tabeli rzadko coś psuje, bo istniejący kod nadal może czytać i zapisywać w starym kształcie.
Zmiany nazw i usunięcia są ryzykowne. Zmiana nazwy to w praktyce „dodaj nowe + usuń stare”, a to część „usuń stare” powoduje, że starsi klienci padają. Jeśli potrzebujesz zmiany nazwy, potraktuj to jako dwustopniową zmianę: najpierw dodaj nowe pole, przez jakiś czas trzymaj stare, i usuń je dopiero gdy upewnisz się, że nikt już na nim nie polega.
Przy dodawaniu kolumn zaczynaj od pól opcjonalnych (nullable). Kolumna nullable pozwala staremu kodowi dalej wstawiać wiersze bez wiedzy o nowym polu. Jeśli ostatecznie chcesz NOT NULL, najpierw dodaj jako nullable, wykonaj backfill, a dopiero potem wymuś NOT NULL. Domyślne wartości też pomagają, ale uwaga: dodanie defaultu w niektórych bazach i tak może modyfikować wiele wierszy i spowolnić zmianę.
Indeksy to kolejny „bezpieczny, ale nie darmowy” dodatek. Mogą przyspieszyć odczyty, ale tworzenie i utrzymanie indeksu może spowolnić zapisy. Dodawaj indeksy gdy dokładnie wiesz, które zapytanie z nich skorzysta, i rozważ wykonanie tego w godzinach mniejszego obciążenia, jeśli baza jest zajęta.
Prosty zestaw reguł dla addytywnych migracji baz danych:
NOT NULL, unique, foreign keys) do czasu po backfillu.Traktuj zmiany schematu bez przestojów jak rollout, a nie pojedyncze wdrożenie. Celem jest pozwolić starszym i nowym wersjom aplikacji współistnieć, podczas gdy baza stopniowo przechodzi do nowego kształtu.
Praktyczna sekwencja:
Przykład: wprowadzasz full_name, ale starsze klienty wysyłają first_name i last_name. Przez pewien okres backend może konstruować full_name przy zapisie, wykonać backfill istniejących użytkowników, potem domyślnie czytać full_name, lecz wciąż obsługiwać stare payloady. Dopiero gdy adopcja jest jasna, usuwasz stare pola.
Backfill wypełnia nową kolumnę lub tabelę dla istniejących wierszy. To często najniebezpieczniejszy element zmian schematu bez przestojów, bo może generować duże obciążenie bazy, długie locki i mylące „półprzemigrowane” zachowanie.
Zacznij od decyzji, jak uruchomisz backfill. Dla małych datasetów jednorazowy runbook może wystarczyć. Dla dużych danych lepiej użyć background workerów lub zaplanowanego zadania, które można powtarzać i bezpiecznie zatrzymać.
Dziel pracę na partie, aby kontrolować nacisk na bazę. Nie aktualizuj milionów wierszy w jednej transakcji. Celuj w przewidywalny rozmiar porcji i krótki odstęp między batchami, aby ruch użytkowników pozostał płynny.
Praktyczny wzorzec:
Uczyń zadanie restartowalnym. Przechowuj prosty znacznik postępu w dedykowanej tabeli i projektuj zadanie tak, by ponowne uruchomienie nie uszkodziło danych. Idempotentne aktualizacje (np. UPDATE ... WHERE new_field IS NULL) są przyjacielem.
Waliduj na bieżąco. Śledź ile wierszy wciąż brak, dodaj sanity checki: brak sald ujemnych, znaczniki czasu w oczekiwanym zakresie, status w dozwolonym zbiorze. Sprawdzaj losowo prawdziwe rekordy.
Zdecyduj, co aplikacja powinna robić, gdy backfill jest niekompletny. Bezpieczny wariant to fallback reads: jeśli nowe pole jest null, oblicz lub odczytaj starą wartość. Przykład: dodajesz preferred_language. Dopóki backfill się nie skończy, API może zwracać istniejący język z ustawień profilu, a wymagać preferred_language dopiero po ukończeniu backfillu.
Gdy wypuszczasz zmianę schematu, rzadko kontrolujesz wszystkie klientów. Użytkownicy web aktualizują się szybko, a starsze buildy mobilne mogą być aktywne tygodniami. Dlatego wstecznie kompatybilne API mają znaczenie nawet przy „bezpiecznej” migracji bazy.
Traktuj nowe dane jako opcjonalne na początku. Dodaj nowe pola do żądań i odpowiedzi, ale nie wymagaj ich od razu. Jeśli starszy klient nie wyśle nowego pola, serwer powinien zaakceptować żądanie i zachować dotychczasowe zachowanie.
Unikaj zmiany znaczenia istniejących pól. Zmiana nazwy jest w porządku, jeśli stara nazwa nadal działa. Reużycie pola do nowego znaczenia to źródło subtelnych awarii.
Domyślne wartości po stronie serwera to siatka bezpieczeństwa. Gdy wprowadzasz nową kolumnę jak preferred_language, ustaw domyślną wartość po stronie serwera, gdy jej brak. Odpowiedź API może zawierać nowe pole, a starsze klienty mogą je ignorować.
Zasady kompatybilności, które zapobiegają większości awarii:
Przykład: dodajesz company_size do procesu rejestracji. Backend może ustawić domyślnie wartość „unknown”, gdy pole jest pominięte. Nowe klienty przesyłają rzeczywistą wartość, starsze działają jak wcześniej, a dashboardy pozostają czytelne.
Jeśli platforma regeneruje aplikację, masz czysty rebuild kodu i konfiguracji. To pomaga przy zmianach schematu bez przestojów, bo możesz robić małe, addytywne kroki i wdrażać często zamiast nosić łaty miesiącami.
Klucz to jedno źródło prawdy. Jeśli schemat bazy zmienia się w jednym miejscu, a logika biznesowa gdzie indziej, dryf pojawia się szybko. Zdecyduj, gdzie zmiany są definiowane i traktuj wszystko inne jako output generowany.
Jasne nazewnictwo zmniejsza wpadki podczas wdrożeń etapowych. Jeśli wprowadzasz nowe pole, zaznacz które jest bezpieczne dla starych klientów, a które to nowa ścieżka. Na przykład nazwanie kolumny status_v2 jest bezpieczniejsze niż status_new, bo ma sens także za pół roku.
Nawet gdy zmiany są addytywne, rebuild może ujawnić ukryte sprzężenia. Po każdej regeneracji i wdrożeniu sprawdź krótki zestaw krytycznych flow:
Zaplanuj kroki migracji zanim zaczniesz edytować kod: dodaj nowe pole, wdroż z obsługą obu pól, wykonaj backfill, przełącz odczyty, a potem wycofaj starą ścieżkę. Taka sekwencja trzyma schemat, logikę i generowany kod razem, więc zmiany pozostają małe, podlegające review i odwracalne.
Większość awarii podczas zmian schematu bez przestojów nie wynika z „twardej” pracy bazy, lecz z zmiany kontraktu między bazą, API i klientami w złej kolejności.
Typowe pułapki i bezpieczniejsze ruchy:
NOT NULL w ostatniej migracji.Jeśli regenerujesz aplikację, kusi „posprzątać” nazwy i ograniczenia od razu. Powstrzymaj się. Sprzątanie to ostatni krok, nie pierwszy.
Dobra reguła: jeśli zmiana nie da się bezpiecznie przeprowadzić ani do przodu, ani w tył, nie jest gotowa do produkcji.
Sukces zmian schematu bez przestojów zależy od dwóch rzeczy: co obserwujesz i jak szybko możesz zatrzymać proces.
Śledź sygnały odzwierciedlające rzeczywisty wpływ na użytkownika, nie tylko „wdrożenie się zakończyło":
Jeżeli wykonujesz dual writes, dodaj tymczasowe logowanie porównujące oba źródła. Trzymaj to oszczędnie: loguj tylko gdy wartości się różnią, dołącz ID rekordu i krótki kod powodu, i próbkuj jeśli wolumen jest wysoki. Stwórz przypomnienie, aby usunąć to logowanie po migracji, żeby nie stało się stałym hałasem.
Rollback musi być realistyczny. Zazwyczaj nie cofasz schematu — cofasz kod i zostawiasz addytywny schemat.
Praktyczny runbook rollbacku:
Dla backfilli zrób przełącznik, który możesz odciąć w kilka sekund (feature flag, wartość konfiguracyjna, pauza joba). Komunikuj etapy z wyprzedzeniem: kiedy zaczyna się dual write, kiedy uruchamia się backfill, kiedy przełączają się odczyty i co oznacza „stop”, żeby nikt nie improwizował pod presją.
Tuż przed wypuszczeniem zmiany schematu zatrzymaj się i uruchom tę szybką kontrolę. Złapie małe założenia, które zamieniają się w awarie przy mieszanych wersjach klientów.
Jeśli używasz platformy regenerującej, dodaj jeszcze jedną kontrolę: wygeneruj i wdroż build z dokładnym modelem, który migracji dotyczy, a potem potwierdź, że wygenerowane API i logika biznesowa nadal tolerują stare rekordy. Częstym błędem jest założenie, że nowy schemat implikuje od razu nową, obowiązkową logikę.
Zapisz też dwie szybkie akcje, które podejmiesz, gdy coś pójdzie nie tak po wdrożeniu: co będziesz monitorować (błędy, timeouty, postęp backfillu) i co wycofasz najpierw (wyłączenie flagi, wstrzymanie backfillu, revert release). To zamienia „szybko zareagujemy” w konkretny plan.
Masz aplikację zamówieniową. Potrzebujesz nowego pola delivery_window, które będzie wymagane dla nowych reguł biznesowych. Problem w tym, że starsze buildy iOS i Android są nadal w użyciu i nie będą wysyłać tego pola przez dni lub tygodnie. Gdybyś od razu uczynił je wymaganym w bazie, ci klienci zaczęliby dostawać błędy.
Bezpieczna ścieżka:
delivery_window dla starych rekordów regułą (wywnioskuj z metody wysyłki lub ustaw domyślnie „dowolnie”, dopóki klient nie zmieni).delivery_window w pierwszej kolejności, ale nadal fallbackowały do wartości wywnioskowanej gdy pole jest puste.NOT NULL i usuń fallback.Użytkownicy odczuwają to jako nudne (to cel):
Prosty gate monitorujący każdy krok: śledź odsetek nowych zamówień, gdzie delivery_window nie jest null. Gdy utrzymuje się na stałym, wysokim poziomie (i błędy walidacji „brak pola” są bliskie zera), zwykle bezpiecznie przejść od backfillu do wymuszania ograniczenia.
Jednorazowy, ostrożny rollout to nie strategia. Traktuj zmiany schematu jak rutynę: te same kroki, te same nazwy, te same zatwierdzenia. Wtedy następna addytywna zmiana będzie nudna, nawet gdy aplikacja jest intensywnie używana, a klienci mają różne wersje.
Utrzymuj playbook krótki. Powinien odpowiadać: co dodajemy, jak to bezpiecznie wypuścić i kiedy usuwamy stare elementy.
Prosty szablon:
Zacznij od niskiego ryzyka tabeli (nowy opcjonalny status, pole notatek) i przejdź cały playbook end-to-end: addytywna zmiana, backfill, klienci w mieszanych wersjach, potem cleanup. Ten trening odsłoni luki w monitoringu, batchowaniu i komunikacji zanim spróbujesz większego redesignu.
Jedien nawyk, który zapobiega bałaganowi: traktuj „usuń później” jak prawdziwą pracę. Gdy dodajesz tymczasową kolumnę, kod kompatybilności lub dual-write, od razu stwórz ticket sprzątający z właścicielem i datą. Trzymaj małą notatkę o „długu kompatybilności” w dokumentacji wydania, żeby pozostała widoczna.
Jeśli budujesz z AppMaster, możesz traktować regenerację jako część procesu bezpieczeństwa: zamodeluj addytywny schemat, zaktualizuj logikę biznesową tak, by obsługiwała stare i nowe pola w trakcie przejścia, i zregeneruj, by źródło kodu pozostało czyste wraz ze zmianami wymagań. Jeśli chcesz zobaczyć jak ten workflow pasuje do no-code podejścia, które nadal produkuje realny kod źródłowy, AppMaster (appmaster.io) jest zaprojektowany wokół takiego iteracyjnego, etapowego dostarczania.
Cel nie jest w perfekcji. To powtarzalność: każda migracja ma plan, metrykę i rampę wyjścia.
Zero-downtime oznacza, że użytkownicy mogą pracować normalnie, podczas gdy zmieniasz schemat i wdrażasz kod. To nie tylko unikanie oczywistych przerw, ale też unikanie ukrytych awarii, jak puste ekrany, błędne wartości, awarie zadań tła czy blokowane zapisy przez długie locki.
Ponieważ wiele części systemu zależy od kształtu bazy danych, nie tylko główny interfejs. Zadania w tle, raporty, skrypty administracyjne, integracje i starsze aplikacje mobilne mogą dalej wysyłać lub oczekiwać starych pól długo po wdrożeniu nowego kodu.
Starsze wersje mobilne mogą być używane przez tygodnie, a niektórzy klienci ponawiają stare żądania później. Twoje API musi przez pewien czas akceptować zarówno stare, jak i nowe payloady, żeby różne wersje mogły współistnieć bez błędów.
Zmiany addytywne zazwyczaj nie łamią istniejącego kodu, ponieważ stary schemat dalej istnieje. Zmiany ryzykowne to głównie usuwanie i zmiany nazw — one eliminują coś, czego starsi klienci nadal używają.
Dodaj kolumnę jako nullable, żeby stary kod nadal mógł wstawiać wiersze. Wypełnij stare wiersze partiami, a dopiero gdy pokrycie będzie wysokie i nowe zapisy będą spójne, wymuś NOT NULL jako ostatni krok.
Traktuj to jak rollout: dodaj kompatybilny schemat, wdrażaj kod obsługujący obie wersje, wykonaj backfill partiami, zmień odczyty z fallbackiem, i usuń stare pole tylko gdy naprawdę nikt go nie używa. Każdy krok powinien działać samodzielnie.
Działaj partiami z krótkimi transakcjami, aby nie blokować tabel ani nie przeciążać bazy. Uczyń zadanie restartowalnym i idempotentnym (np. aktualizuj tylko tam, gdzie new_field IS NULL) i śledź postęp, by móc zatrzymać i wznowić bez ryzyka.
Nowe pola na początku traktuj jako opcjonalne i stosuj domyślne wartości po stronie serwera, gdy ich brak. Nie zmieniaj znaczenia istniejących pól i testuj oba scenariusze: „nowy klient wysyła” oraz „stary klient pomija”.
Zwykle wycofujesz kod aplikacji, nie schemat. Zachowaj addytywne kolumny/tabele, wyłącz nowe odczyty najpierw, potem wyłącz zapisy i wstrzymaj backfille, aż metryki się ustabilizują — to umożliwia szybkie odzyskanie bez utraty danych.
Obserwuj sygnały realnego wpływu na użytkownika: wskaźnik błędów API (4xx/5xx), wolne zapytania (p95/p99), opóźnienia zapisów, głębokość kolejek oraz zużycie CPU/IO bazy. Przejdź dalej tylko gdy metryki są stabilne i pokrycie nowego pola wysokie.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


