Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Poznaj praktyczne wzorce dla zadań w tle z aktualizacją postępu: kolejki, modele statusu, komunikaty UI, akcje anulowania i ponawiania oraz raportowanie błędów.
Długie działania nie powinny blokować UI. Ludzie zmieniają zakładki, tracą połączenie, zamykają laptopa albo po prostu zastanawiają się, czy coś się dzieje. Gdy ekran jest „zamrożony”, użytkownicy zgadują, a zgadywanie prowadzi do wielokrotnych kliknięć, zduplikowanych zgłoszeń i ticketów do wsparcia.
Dobra praca w tle to przede wszystkim budowanie pewności. Użytkownicy chcą trzech rzeczy:
Bez tego zadanie może działać poprawnie, ale doświadczenie będzie zepsute.
Częstym błędem jest traktowanie wolnego żądania jak zadania w tle. Wolne żądanie to nadal jedno wywołanie webowe, które zmusza użytkownika do czekania. Zadanie w tle jest inne: tworzysz job, natychmiast potwierdzasz jego przyjęcie, a ciężka praca dzieje się gdzie indziej, podczas gdy UI pozostaje używalne.
Przykład: użytkownik przesyła CSV do importu klientów. Jeśli UI blokuje, może odświeżyć, przesłać ponownie i stworzyć duplikaty. Jeśli import zaczyna się w tle, a UI pokazuje kartę zadania z postępem i bezpieczną opcją Anuluj, można pracować dalej i wrócić do jasnego rezultatu.
Gdy mówimy o zadaniach w tle z aktualizacją postępu, zwykle chodzi o cztery współpracujące elementy.
Job to jednostka pracy: "zaimportuj ten CSV", "wygeneruj raport" lub "wyślij 5 000 emaili". Kolejka to miejsce, gdzie joby czekają, aż będą mogli je przetworzyć workerzy. Worker pobiera joby z kolejki i wykonuje pracę (pojedynczo lub równolegle).
Dla UI najważniejszy jest cykl życia joba. Trzymaj stany niewielkie i przewidywalne:
Każdy job potrzebuje ID joba (unikalnego odniesienia). Gdy użytkownik kliknie przycisk, zwróć to ID natychmiast i pokaż w panelu zadań wiersz „Zadanie rozpoczęte”.
Potem trzeba mieć sposób na pytanie: „Co teraz się dzieje?”. Zwykle to endpoint statusu (lub dowolna metoda odczytu), która przyjmuje ID joba i zwraca stan oraz szczegóły postępu. UI używa tego do pokazania procentu ukończenia, aktualnego kroku i komunikatów.
Wreszcie, status musi być w trwałym magazynie, a nie tylko w pamięci. Workery padają, aplikacje restartują się, a użytkownicy odświeżają strony. Trwałe przechowywanie to to, co czyni postęp i wyniki wiarygodnymi. Przynajmniej przechowuj:
Jeśli budujesz na platformie takiej jak AppMaster, traktuj magazyn statusu jak każdy inny model danych: UI czyta go po ID joba, a worker aktualizuje, gdy przechodzi przez kolejne kroki.
Wzorzec kolejki, który wybierzesz, zmienia to, jak „sprawiedliwa” i przewidywalna wydaje się twoja aplikacja. Jeśli zadanie tkwi za ogromną ilością pracy, użytkownicy odczują to jako losowe opóźnienia, nawet gdy system jest zdrowy. To sprawia, że wybór kolejki to decyzja UX, a nie tylko infrastruktury.
Prosta kolejka oparta na bazie danych wystarcza często, gdy wolumen jest niski, joby krótkie i możesz tolerować okazjonalne retry. Łatwo ją skonfigurować i zdebugować, a wszystko możesz trzymać w jednym miejscu. Przykład: administrator uruchamia nocny raport dla małego zespołu — jeśli spróbuje raz jeszcze, nikt nie wpada w panikę.
Gdy rośnie przepustowość, joby stają się ciężkie lub niezawodność jest krytyczna, warto użyć dedykowanego systemu kolejek. Importy, przetwarzanie wideo, masowe powiadomienia i workflowy, które muszą działać przez restarty, korzystają z izolacji, widoczności i bezpieczniejszych retry. To ma znaczenie dla doświadczenia użytkownika, bo ludzie zauważają brak aktualizacji i zablokowane stany.
Struktura kolejki wpływa też na priorytety. Jedna kolejka jest prostsza, ale mieszanie szybkich i wolnych zadań może spowodować, że szybkie akcje będą wydawały się wolne. Oddzielne kolejki pomagają, gdy masz prace inicjowane przez użytkownika, które powinny być natychmiastowe, obok zaplanowanych zadań batchowych, które mogą poczekać.
Ustaw limity równoległości celowo. Zbyt duża paralelizacja może przeciążyć bazę danych i sprawić, że postęp będzie skakać. Zbyt mała — zrobi system ospałym. Zacznij od małej, przewidywalnej równoległości na kolejkę i zwiększaj tylko wtedy, gdy potrafisz utrzymać stabilne czasy zakończenia.
Jeśli model postępu jest niejasny, UI też będzie niejasne. Zdecyduj, co system może uczciwie raportować, jak często to się zmienia i co użytkownik powinien z tym zrobić.
Prosty schemat statusu, który obsłuży większość jobów, wygląda tak:
Następnie zdefiniuj, co oznacza „postęp”.
Procent działa, gdy istnieje prawdziwy mianownik (wiersze w pliku, emaile do wysłania). Wprowadza w błąd, gdy praca jest nieprzewidywalna (czekanie na zewnętrzny serwis, zmienne obciążenie). W takich przypadkach postęp oparty na krokach buduje więcej zaufania, bo porusza się w wyraźnych etapach.
Praktyczna zasada:
Przechowuj częściowe wyniki w trakcie wykonywania joba. To pozwala UI pokazać coś użytecznego zanim job się zakończy, np. żywy licznik błędów lub podgląd zmian. Dla importu CSV możesz zapisywać rows_read, rows_created, rows_updated, rows_rejected oraz kilka ostatnich komunikatów o błędach.
To podstawa zaufania: UI pozostaje spokojne, liczby się przesuwają, a podsumowanie „co się stało?” jest gotowe po zakończeniu.
Doprowadzenie postępu z backendu na ekran to miejsce, gdzie wiele implementacji zawodzi. Wybierz metodę dostawy dopasowaną do tego, jak często postęp się zmienia i ilu użytkowników będzie go obserwować.
Polling jest najprostszy: UI pyta o status co N sekund. Dobry domyślny rytm to 2–5 sekund, gdy użytkownik aktywnie patrzy na stronę, potem stopniowe wydłużanie interwału. Jeśli zadanie trwa dłużej niż minutę, przejdź do 10–30 sekund. Gdy karta jest w tle, zwolnij jeszcze bardziej.
Push (WebSockets, server-sent events lub powiadomienia mobilne) pomaga, gdy postęp zmienia się szybko lub użytkownikom zależy na „tu i teraz”. Push jest świetny dla natychmiastowości, ale potrzebujesz fallbacku, gdy połączenie padnie.
Hybryda często sprawdza się najlepiej: szybko polluj na początku (żeby UI szybko zobaczyło przejście z oczekującego do w toku), potem zwalniaj, gdy job się ustabilizuje. Jeśli dodasz push, trzymaj powolny polling jako siatkę bezpieczeństwa.
Gdy aktualizacje przestają przychodzić, traktuj to jako stan pierwszej klasy. Pokaż „Ostatnia aktualizacja 2 minuty temu” i zaproponuj odświeżenie. Na backendzie oznacz joby jako przestarzałe, jeśli nie mają heartbeatów.
Jasność wynika z dwóch rzeczy: małego zestawu przewidywalnych stanów i tekstu, który mówi ludziom, co nastąpi dalej.
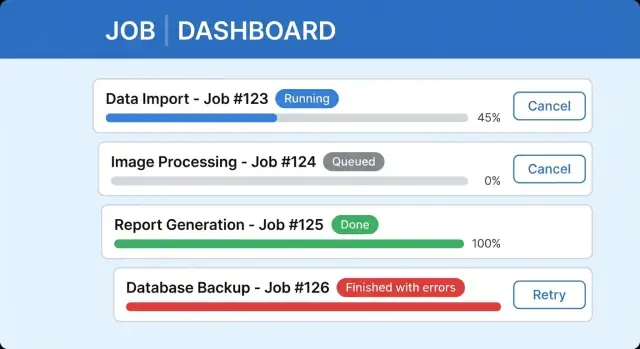
Nazywaj stany w UI, nie tylko w backendzie. Job może być oczekujący (czeka na kolej), w toku (przetwarza), oczekuje na dane (potrzebna decyzja), zakończony, zakończony z problemami lub nieudany. Jeśli użytkownicy nie potrafią tego odróżnić, założą, że aplikacja utknęła.
Używaj prostego, użytecznego tekstu obok wskaźnika postępu. „Importuję 3 200 wierszy (1 140 przetworzono)” jest lepsze niż „Przetwarzanie.” Dodaj jedno zdanie odpowiadające: czy mogę opuścić stronę i co się stanie? Na przykład: „Możesz zamknąć to okno. Będziemy importować w tle i powiadomimy cię, gdy będzie gotowe.”
Miejsce, w którym pokazujesz postęp, powinno odpowiadać kontekstowi użytkownika:
Dla wszystkiego dłuższego niż minuta dodaj prostą stronę Zadań (lub panel Aktywności), żeby ludzie mogli wrócić do wyników.
Jasne UI długotrwałego zadania zwykle zawiera etykietę statusu z ostatnią aktualizacją, pasek postępu (lub kroki) z jedną linią szczegółu, bezpieczne działanie Anuluj oraz obszar wyników z podsumowaniem i następną akcją. Trzymaj zakończone joby łatwo odnajdywalne, żeby użytkownicy nie byli zmuszeni czekać na jednym ekranie.
„Zakończone” nie zawsze oznacza sukces. Gdy job przetwarza 9 500 rekordów i 120 nie przejdzie, użytkownicy muszą zrozumieć, co się stało bez czytania logów.
Traktuj częściowy sukces jako wynik pierwszej klasy. W głównej linii statusu pokaż obie strony: „Zaimportowano 9 380 z 9 500. 120 nie powiodło się.” To buduje zaufanie, bo system jest szczery i potwierdza, że część pracy została zachowana.
Pokaż małe podsumowanie błędów, które użytkownik może obsłużyć: „Brak wymaganego pola (63)” i „Nieprawidłowy format daty (41).” W stanie końcowym „Zakończone z problemami” często jest jaśniejsze niż „Niepowodzenie”, bo nie sugeruje, że nic nie zadziałało.
Eksportowalny raport błędów zamienia zamieszanie w listę zadań. Trzymaj to proste: numer wiersza lub identyfikator elementu, kategoria błędu, czytelny komunikat i nazwa pola gdy ma to sens.
Umieść następną akcję blisko podsumowania: popraw dane i ponów tylko nieudane elementy, pobierz raport błędów lub skontaktuj się z pomocą, jeśli wygląda to na problem systemowy.
Anuluj i ponów wyglądają prosto, ale szybko psują zaufanie, gdy UI mówi jedno, a system robi drugie. Zdefiniuj, co Anuluj oznacza dla każdego typu joba, a potem odzwierciedl to szczerze w interfejsie.
Są zwykle dwa sensowne tryby anulowania:
W UI pokazuj stan pośredni jak „Żądanie anulowania”, żeby użytkownicy nie klikali wielokrotnie.
Uczyń anulowanie bezpiecznym, projektując pracę powtarzalnie. Jeśli job zapisuje dane, preferuj operacje idempotentne (bezpieczne do uruchomienia wielokrotnie) i rób sprzątanie tam, gdzie trzeba. Na przykład przy imporcie CSV zapisuj job-run ID, żeby móc przejrzeć, co zmieniło się w przebiegu #123.
Ponawianie wymaga tej samej jasności. Ponowienie tej samej instancji joba ma sens, gdy można wznowić. Stworzenie nowej instancji jest bezpieczniejsze, gdy chcesz czysty przebieg z nowym znacznikiem czasu i audytem. W każdym przypadku wyjaśnij, co zostanie zrobione, a co nie.
Zabezpieczenia, które utrzymują przewidywalność anulowania i ponawiania:
Dobry flow end-to-end zaczyna się jedną zasadą: UI nigdy nie powinno czekać na samą pracę. Powinno czekać tylko na ID joba.
Użytkownik uruchamia zadanie, API zwraca szybko. Gdy użytkownik kliknie Import lub Generuj raport, serwer natychmiast tworzy rekord joba i zwraca unikalne ID.
Wstaw pracę do kolejki i ustaw pierwszy status. Włóż ID joba do kolejki i ustaw status na oczekujące z postępem 0%. To daje UI coś realnego do pokazania, zanim worker się zajmie jobem.
Worker uruchamia job i raportuje postęp. Gdy worker zaczyna, ustaw status na w toku, zapisz czas rozpoczęcia i aktualizuj postęp małymi, uczciwymi skokami. Jeśli nie da się zmierzyć procentu, pokazuj kroki takie jak Parsowanie, Walidacja, Zapisywanie.
UI utrzymuje orientację użytkownika. UI polluje lub subskrybuje aktualizacje i renderuje czytelne stany. Pokaż krótki komunikat (co się teraz dzieje) i tylko te akcje, które mają sens w danym momencie.
Finalizuj z trwałym rezultatem. Po zakończeniu zapisz czas zakończenia, wynik (referencja do pobrania, utworzone ID, podsumowanie), oraz szczegóły błędów. Obsłuż wynik „zakończone z błędami” jako odrębny rezultat, a nie zbitą informację sukces/porażka.
Anulowanie powinno być eksplicytne: żądanie anulowania zgłasza żądanie, worker potwierdza i oznacza jako anulowane. Ponów powinno tworzyć nowe ID joba, zachowując oryginał jako historię i wyjaśniać, co zostanie ponownie przetworzone.
Typowym miejscem, gdzie aktualizacje postępu są ważne, jest import CSV. Wyobraź sobie CRM, w którym osoba z działu sprzedaży wgrywa customers.csv z 8 420 wierszami.
Zaraz po przesłaniu UI powinno przejść ze stanu „kliknąłem przycisk” do „istnieje job i możesz odejść.” Prosta karta jobu na stronie Imports działa dobrze:
Podczas działania pokaż jedną liczbę postępu, której użytkownik może ufać (przetworzone wiersze) i jedną krótką linię statusu (co robi teraz). Jeśli użytkownik odejdzie, trzymaj job widoczny w obszarze Ostatnich zadań.
Dodajmy częściowe niepowodzenia. Po zakończeniu unikaj strasznego banera "Niepowodzenie", jeśli większość wierszy została poprawnie zaimportowana. Użyj „Zakończone z problemami” plus wyraźne rozbicie:
Zaimportowano 8 102 klientów. Pominięto 318 wierszy.
Wyjaśnij główne powody prostymi słowami: nieprawidłowy format emaila, brak wymaganych pól jak company, duplikaty zewnętrznych ID. Pozwól pobrać lub zobaczyć tabelę błędów z numerem wiersza, nazwą klienta i dokładnym polem do poprawy.
Ponów powinien być bezpieczny i konkretny. Główna akcja może być „Ponów nieudane wiersze”, tworząc nowe joby, które przetworzą tylko 318 pominiętych wierszy po poprawieniu CSV. Oryginalny job zachowaj tylko do odczytu, żeby historia była prawdziwa.
Na koniec, ułatw znajdowanie wyników później: każdy import powinien mieć stabilne podsumowanie: kto go uruchomił, kiedy, nazwa pliku, liczniki (zaimportowane, pominięte) i sposób otwarcia raportu błędów.
Najszybszy sposób na utratę zaufania to pokazywanie liczb, które nie są prawdziwe. Pasek postępu stojący na 0% przez dwie minuty, a potem skok do 90% — wygląda jak zgadywanie. Jeśli nie znasz prawdziwego procentu, pokaż kroki (Oczekujące, Przetwarzanie, Finalizacja) lub „X z Y elementów przetworzonych.”
Inny problem to przechowywanie postępu tylko w pamięci. Jeśli worker restartuje się, UI „zapomina” job lub resetuje postęp. Zapisuj stan joba w trwałym magazynie i spraw, by UI czytało jedno źródło prawdy.
UX ponawiania też psuje się, gdy użytkownicy mogą uruchomić ten sam job wiele razy. Jeśli przycisk Import CSV nadal wygląda aktywnie, ktoś kliknie dwa razy i stworzy duplikaty. Teraz ponawianie jest niejasne, bo nie wiadomo, który przebieg naprawić.
Błędy, które pojawiają się najczęściej:
Mały, lecz ważny detal: oddziel wiadomość dla użytkownika od detali deweloperskich. Pokaż „12 wierszy nie przeszło walidacji” użytkownikowi, a ślad techniczny trzymaj w logach.
Przed wydaniem zrób szybki przegląd elementów, które użytkownicy zauważą: jasność, zaufanie i odzyskiwanie.
Każdy job powinien wystawiać snapshot do pokazania wszędzie: stan (oczekujące, w toku, zakończone, niepowodzenie, anulowane), postęp (0–100 lub kroki), krótki komunikat, znaczniki czasu (utworzono, rozpoczęto, zakończono) i wskaźnik wyniku (gdzie jest output lub raport).
Uczyń stany UI oczywistymi i spójnymi. Użytkownicy potrzebują jednego pewnego miejsca, by znaleźć bieżące i przeszłe joby, plus wyraźne etykiety po powrocie („Zakończone wczoraj”, „Wciąż w toku”). Panel Ostatnich zadań często zapobiega powtórnym kliknięciom i dublowaniu pracy.
Zdefiniuj zasady anulowania i ponawiania prostym językiem. Zdecyduj, co oznacza Anuluj dla każdego typu, czy ponawianie jest dozwolone i co jest ponownie używane (te same wejścia czy nowe ID). Testuj edge case’y jak anulowanie tuż przed zakończeniem.
Traktuj częściowe niepowodzenia jako realny wynik. Pokaż krótkie podsumowanie („Zaimportowano 97, pominięto 3”) i udostępnij raport, który użytkownik może od razu użyć.
Planuj odzyskiwanie. Joby powinny przetrwać restarty, a zablokowane joby powinny timeoutować do jasnego stanu z instrukcją („Spróbuj ponownie” lub „Skontaktuj się z pomocą, podając ID joba”).
Wybierz workflow, na który użytkownicy już narzekają: importy CSV, eksporty raportów, masowe wysyłki emaili lub przetwarzanie obrazów. Zacznij mało i udowodnij podstawy: job jest tworzony, działa, raportuje status i użytkownik może go znaleźć później.
Prosty ekran historii jobów często daje największy skok jakości. Daje ludziom miejsce do powrotu, zamiast wpatrywania się w spinner.
Wybierz jedną metodę dostarczania postępu na start. Polling jest OK na wersję pierwszą. Ustaw interwał odświeżania na tyle rzadki, by oszczędzać backend, ale na tyle częsty, by wydawać się żywy.
Praktyczna kolejność budowy, która minimalizuje przepisywanie:
Jeśli budujesz to bez pisania kodu, platforma no-code jak AppMaster może pomóc, pozwalając zamodelować tabelę statusu joba (PostgreSQL) i aktualizować ją z workflowów, a potem renderować status w web i mobile UI. Dla zespołów, które chcą jednego miejsca do budowy backendu, UI i logiki w tle, AppMaster (appmaster.io) jest zaprojektowany do pełnych aplikacji, nie tylko formularzy lub stron.
Zadanie w tle jest tworzone szybko i od razu zwraca ID zadania, dzięki czemu UI pozostaje używalne. Wolne żądanie to pojedyncze wywołanie webowe, które zmusza użytkownika do czekania — prowadzi to do odświeżeń, podwójnych kliknięć i zduplikowanych zapisów.
Utrzymaj prostotę: oczekujące, w toku, zakończone i niepowodzenie, plus anulowane jeśli wspierasz anulowanie. Dodaj osobny wynik typu „zakończone z problemami” gdy większość pracy się powiodła, ale część elementów nie przeszła, żeby użytkownik nie myślał, że nic się nie udało.
Zwróć unikalne ID zadania natychmiast po uruchomieniu akcji, a następnie wyrenderuj wiersz lub kartę zadania używając tego ID. UI powinno czytać status po ID zadania, żeby użytkownicy mogli odświeżać, zmieniać zakładki lub wrócić później bez utraty śledzenia.
Przechowuj status zadania w trwałej tabeli bazy danych, a nie tylko w pamięci. Zapisz bieżący stan, znaczniki czasu, wartość postępu, krótką wiadomość dla użytkownika oraz podsumowanie wyniku lub błędu, aby UI mogło odtworzyć ten sam widok po restarcie.
Używaj procentu tylko wtedy, gdy możesz uczciwie raportować „X z Y” przetworzonych elementów. Jeśli nie masz rzeczywistego mianownika, pokaż postęp w krokach, np. „Walidacja”, „Import”, „Finalizacja”, i aktualizuj komunikat tak, żeby użytkownik widział ruch do przodu.
Polling jest najprostszy i dobrze działa w większości aplikacji; zaczynaj co 2–5 sekund, gdy użytkownik patrzy, a potem zwalniaj dla dłuższych zadań lub kart w tle. Push daje większą natychmiastowość, ale potrzebujesz fallbacku, bo połączenia znikają i użytkownicy przechodzą między ekranami.
Pokaż, że aktualizacje są przestarzałe zamiast udawać, że zadanie nadal się rusza — np. „Ostatnia aktualizacja 2 minuty temu” i zaproponuj ręczne odświeżenie. Na backendzie wykrywaj brak heartbeatów i przenoś zadania do jasnego stanu z instrukcją (spróbuj ponownie lub skontaktuj się z pomocą, podając ID zadania).
Spraw, by następna akcja była oczywista: czy użytkownik może dalej pracować, opuścić stronę, czy bezpiecznie anulować. Dla zadań dłuższych niż minuta warto mieć dedykowany widok Zadań lub Aktywności, żeby użytkownicy mogli znaleźć wyniki później zamiast wpatrywać się w spinner.
Traktuj to jako równorzędny wynik i pokaż obie strony jasno, np. „Zaimportowano 9 380 z 9 500. 120 nie powiodło się.” Potem podaj małe, akcyjne podsumowanie błędów, które użytkownik może naprawić bez czytania logów, a techniczne szczegóły zostaw w wewnętrznych logach.
Zdefiniuj znaczenie Anuluj dla każdego typu zadania i pokazuj to uczciwie, w tym stan pośredni „żądanie anulowania”, żeby użytkownicy nie klikali wielokrotnie. Projektuj operacje tak, by były idempotentne, ograniczaj liczbę ponowień i decyduj, czy ponowienie wznawia ten sam przebieg, czy tworzy nowe ID z czystą historią.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


