Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Dowiedz się, jak modelować timery SLA i eskalacje z przejrzystymi stanami, łatwymi do utrzymania regułami i prostymi ścieżkami eskalacji, aby aplikacje przepływu pracy były proste do modyfikacji.
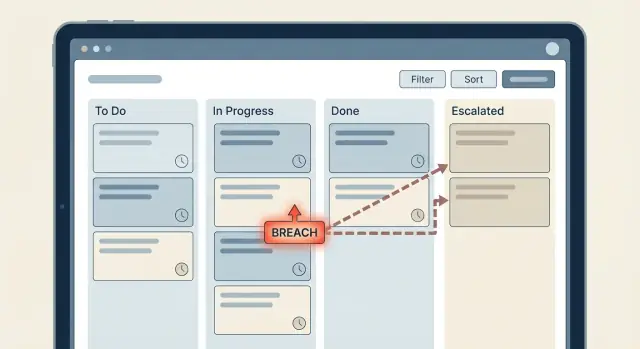
Reguły oparte na czasie zwykle zaczynają się prosto: „Jeśli zgłoszenie nie ma odpowiedzi przez 2 godziny, powiadom kogoś.” Potem workflow rośnie, zespoły dokładają wyjątki i nagle nikt nie jest pewien, co się dzieje. Właśnie tak timery SLA i eskalacje zamieniają się w labirynt.
Pomaga jasne nazwanie poruszających się elementów.
Timer to zegar, który uruchamiasz (lub planujesz) po zdarzeniu, np. „zgłoszenie przeszło do Waiting for Agent”. Eskalacja to działanie, które wykonujesz, gdy zegar osiągnie próg — np. powiadomienie lidera, zmiana priorytetu lub przydzielenie pracy na nowo. Breach to zapisany fakt mówiący „przekroczyliśmy SLA”, który używasz do raportowania, alertów i dalszych działań.
Problemy pojawiają się, gdy logika czasu jest rozproszona po aplikacji: kilka sprawdzeń w flow „update ticket”, kolejne w zadaniu nocnym i jednorazowe reguły dodane później dla specjalnego klienta. Każda część ma sens sama w sobie, ale razem tworzą niespodzianki.
Typowe symptomy:
Cel to przewidywalne zachowanie, które łatwo zmieniać później: jedno jasne źródło prawdy dla timingu SLA, eksplicytne stany naruszenia, które można raportować, i kroki eskalacji, które można modyfikować bez szukania po wizualnej logice.
Zanim zbudujesz jakiekolwiek timery, zapisz dokładną obietnicę, którą mierzysz. Dużo bałaganu wynika z prób objęcia wszystkich możliwych reguł czasowych od razu.
Typowe rodzaje SLA brzmią podobnie, ale mierzą różne rzeczy:
Następnie zdecyduj, co oznacza „czas”. Czas kalendarzowy liczy 24/7. Czas roboczy liczy tylko zdefiniowane godziny pracy (np. pon-pt 9–18). Jeśli naprawdę nie potrzebujesz czasu roboczego, unikaj go na początku — dodaje przypadki brzegowe typu święta, strefy czasowe i częściowe dni.
Potem określ pauzy. Pauza to nie tylko „zmiana statusu”. To reguła z właścicielem. Kto może wstrzymać (tylko agent, tylko system, akcja klienta)? Które statusy wstrzymują (Waiting on Customer, On Hold, Pending Approval)? Co wznawia? Po wznowieniu kontynuujemy od pozostałego czasu czy restartujemy timer?
Na koniec określ, co znaczy breach w terminach produktu. Breach powinien być konkretną rzeczą, którą możesz zapisać i zapytać, na przykład:
breached_at (kiedy termin został przekroczony)Przykład: „First response SLA breached” może oznaczać, że zgłoszenie dostaje stan Breached, ustawiany jest breached_at, i poziom eskalacji ustawiony na 1.
Jeśli chcesz, żeby timery SLA i eskalacje pozostały czytelne, traktuj SLA jak małą maszynę stanów. Gdy „prawda” jest rozsiana po drobnych sprawdzeniach (if now > due, jeśli priorytet jest wysoki, jeśli brak ostatniej odpowiedzi), logika wizualna szybko staje się nieczytelna, a drobne zmiany psują całość.
Zacznij od krótkiego, uzgodnionego zbioru stanów SLA, które każdy krok workflow rozumie. Dla wielu zespołów wystarczają:
Jedna flaga breached = true/false rzadko wystarcza. Nadal musisz wiedzieć, które SLA naruszono (first response vs resolution), czy jest obecnie pauza i czy już eskalowano. Bez tego kontekstu ludzie zaczynają wyprowadzać znaczenie z komentarzy, znaczników czasu i nazw statusów. To tam logika się kruszy.
Uczyń stan eksplicytnym i zapisz znaczniki czasu, które to wyjaśniają. Wtedy decyzje pozostają proste: evaluator czyta rekord, decyduje o następnym stanie, a wszystko inne reaguje na ten stan.
Przydatne pola do przechowywania wraz ze stanem:
started_at i due_at (który zegar prowadzimy i kiedy jest termin?)breached_at (kiedy faktycznie przekroczono linię?)paused_at i paused_reason (dlaczego zegar się zatrzymał?)breach_reason (która reguła wywołała naruszenie, prostymi słowami)last_escalation_level (żeby nie powiadomić tego samego poziomu dwa razy)Przykład: zgłoszenie przechodzi do „Waiting on customer”. Ustaw stan SLA na Paused, zapisz paused_reason = "waiting_on_customer" i zatrzymaj zegar. Kiedy klient odpowie, wznowienie polega na ustawieniu nowego started_at (lub odznaczeniu pauzy i przeliczeniu due_at). Koniec szukania logiki po wielu warunkach.
Drabina eskalacji to jasny plan, co się dzieje, gdy timer SLA zbliża się do przekroczenia lub już je przekroczył. Błąd to wklejenie struktury organizacyjnej w workflow. Chcesz najmniejszy zestaw kroków, który ponownie ruszy zablokowane zadanie.
Prosta drabina używana przez wiele zespołów: przypisany agent (Level 0) dostaje pierwsze pukanie, potem lead zespołu (Level 1) jest wciągany, a dopiero potem manager (Level 2). Działa, bo zaczyna tam, gdzie można wykonać pracę, a autorytet eskaluje tylko gdy trzeba.
Aby reguły eskalacji były łatwe w utrzymaniu, przechowuj progi eskalacji jako dane, a nie hardkodowane warunki. Umieść je w tabeli lub obiekcie ustawień: „pierwsze przypomnienie po 30 minutach” czy „eskaluj do leada po 2 godzinach”. Gdy polityka się zmieni, aktualizujesz jedno miejsce zamiast edytować wiele workflowów.
Zadbaj, żeby eskalacje były pomocne, nie uciążliwe
Eskalacje stają się spamem, gdy wyzwalają się zbyt często. Dodaj zabezpieczenia, aby każdy krok miał sens:
Zdecyduj, kto przejmuje odpowiedzialność po eskalacji
Samo powiadomienie nie rozwiąże zablokowanej pracy, jeśli odpowiedzialność pozostaje niejasna. Zdefiniuj reguły własności z góry: czy zgłoszenie pozostaje przypisane agentowi, zostaje przekazane leadowi, czy trafi do wspólnej kolejki?
Przykład: po eskalacji Level 1 przypisz do team leada i ustaw oryginalnego agenta jako obserwatora. To pokazuje jednoznacznie, kto ma zareagować dalej i zapobiega odbijaniu się tego samego zgłoszenia między ludźmi.
Najprostszy sposób, by timery SLA i eskalacje były utrzymywalne, to traktować je jak mały system z trzema częściami: events, evaluator i actions. To zapobiega rozprzestrzenianiu logiki czasu po dziesiątkach „if time > X”.
Events to proste fakty, które nie powinny zawierać matematyki timerów. Odpowiadają na pytanie „co się zmieniło?”, a nie „co z tym zrobić?”. Typowe events: ticket created, agent replied, customer replied, status changed, manual pause/resume.
Zapisuj je jako znaczniki czasu i pola statusu (np. created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
Zrób jeden „SLA evaluator”, który uruchamia się po każdym evencie i okresowo. To evaluator jest jedynym miejscem, które liczy due_at i pozostały czas. Odczytuje aktualne fakty, przelicza terminy i zapisuje eksplicytne pola stanu SLA, jak sla_response_state i sla_resolution_state.
Tutaj modelowanie stanu breach pozostaje czyste: evaluator ustawia stany jak OK, AtRisk, Breached, zamiast ukrywać logikę wewnątrz powiadomień.
Powiadomienia, przydziały i eskalacje powinny wyzwalać się tylko przy zmianie stanu (np. OK -> AtRisk). Trzymaj wysyłanie wiadomości oddzielnie od aktualizacji stanu SLA. Dzięki temu zmienisz, kto dostaje powiadomienie, bez dotykania obliczeń.
Utrzymywalne ustawienie zwykle wygląda tak: kilka pól na rekordzie, mała tabela polityk i jeden evaluator decydujący, co dalej.
Zacznij od encji, która właścicieluje SLA (ticket, order, request). Dodaj eksplicytne znaczniki czasu i jedno pole „current SLA state”. Trzymaj to proste i przewidywalne.
Następnie dodaj małą tabelę polityk, która opisuje reguły zamiast hardkodować je w wielu flowach. Prosta wersja: jeden wiersz na priorytet (P1, P2, P3) z kolumnami na docelowe minuty i progi eskalacji (np. warn przy 80%, breach przy 100%). To różnica między zmianą jednego rekordu a edycją pięciu workflowów.
Zamiast tworzyć timery wszędzie, użyj jednego procesu zaplanowanego, który okresowo sprawdza elementy (co minutę dla ścisłych SLA, co 5 minut dla wielu zespołów). Harmonogram wywołuje jeden evaluator, który:
sla_state i next_check_atTo ułatwia rozumienie timerów SLA i eskalacji, bo debugujesz jeden evaluator, a nie wiele timerów.
Evaluator powinien wypisywać zarówno nowy stan, jak i informację, czy się on zmienił. Wysyłaj wiadomości lub twórz zadania tylko wtedy, gdy stan się zmienił (np. ok -> warning, warning -> breached). Jeśli rekord pozostaje breached godzinę, nie chcesz 12 powtórzeń powiadomień.
Praktyczny wzorzec: przechowuj sla_state i last_escalation_level, porównuj je z nowo obliczonymi wartościami i tylko wtedy wywołuj messaging (email/SMS/Telegram) lub twórz wewnętrzne zadanie.
Pauzy to miejsce, gdzie reguły czasowe zwykle się plączą. Jeśli ich nie zamodelujesz jasno, SLA albo będzie biec, gdy nie powinno, albo zresetuje się, gdy ktoś kliknie niewłaściwy status.
Prosta reguła: tylko jeden status (lub niewielki zestaw) wstrzymuje zegar. Często wybiera się Waiting for customer. Kiedy zgłoszenie przechodzi do tego statusu, zapisz pause_started_at. Gdy klient odpowie i zgłoszenie opuści ten status, zamknij pauzę, zapisując pause_ended_at i dodając czas do paused_total_seconds.
Nie trzymaj tylko jednego licznika. Zarejestruj każde okno pauzy (start, end, kto/co je wywołało), aby mieć ślad audytu. Później, gdy ktoś zapyta, dlaczego sprawa naruszyła SLA, pokażesz, że spędziła 19 godzin oczekując na klienta.
Reasignacja i normalne zmiany statusu nie powinny restartować zegara. Trzymaj znaczniki SLA oddzielone od pól własności. Na przykład sla_started_at i sla_due_at powinny być ustawione raz (przy tworzeniu lub zmianie polityki), podczas gdy reasignacja aktualizuje tylko assignee_id. Twój evaluator może wtedy obliczyć upływ czasu jako: now minus sla_started_at minus paused_total_seconds.
Reguły, które utrzymują timery SLA i eskalacje przewidywalne:
Prosty test projektu to zgłoszenie wsparcia z dwoma SLA: pierwsza odpowiedź w 30 minut i pełne rozwiązanie w 8 godzin. To miejsce, gdzie logika zwykle się psuje, jeśli jest rozproszona po ekranach i przyciskach.
Załóżmy, że każde zgłoszenie przechowuje: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), oraz znaczniki czasu jak created_at, first_agent_reply_at, resolved_at.
Realistyczna oś czasu:
Dla eskalacji trzymaj jedną jasną ścieżkę wyzwalaną przy przejściach stanów. Na przykład, gdy response przechodzi w Warning, powiadom przypisanego agenta. Gdy przechodzi w Breached, powiadom team leada i zaktualizuj priorytet.
Na każdym kroku aktualizuj ten sam mały zestaw pól, by wszystko było proste do rozumienia:
response_status lub resolution_status na Pending, Warning, Breached lub Met.*_warning_at i *_breach_at raz, nigdy ich nie nadpisuj.escalation_level (0, 1, 2) i ustaw escalated_to (Agent, Lead, Manager).sla_events z typem zdarzenia i kim powiadomiono.priority i due_at, aby UI i raporty odzwierciedlały eskalację.Kluczowe jest to, że Warning i Breached są eksplicytnymi stanami. Widać je w danych, można je audytować i zmienić drabinę później bez szukania ukrytych sprawdzeń timera.
Logika SLA robi się chaotyczna, gdy się rozprzestrzenia. Szybkie sprawdzenie czasu dodane do przycisku tu, warunek alertu tam i wkrótce nikt nie potrafi wytłumaczyć, dlaczego zgłoszenie eskalowało. Trzymaj timery SLA i eskalacje jako mały, centralny fragment logiki, na którym polegają wszystkie ekrany i akcje.
Typowa pułapka to osadzanie sprawdzeń czasu w wielu miejscach (UI, handlery API, akcje ręczne). Naprawa to: obliczaj status SLA w jednym evaluatorze i zapisuj wynik na rekordzie. Ekrany powinny czytać status, a nie wymyślać go od nowa.
Inna pułapka to niezgodność zegarów: jeśli przeglądarka liczy „minuty od utworzenia”, a backend używa czasu serwera, zobaczysz przypadki brzegowe wokół uśpienia, stref czasowych i zmiany czasu. Preferuj czas serwera do wszystkiego, co wyzwala eskalację.
Powiadomienia też mogą szybko zagłuszyć zespół. Jeśli „sprawdzasz co minutę i wysyłasz, gdy przeterminowane”, ludzie mogą być spamowani co minutę. Powiąż wiadomości z przejściami stanów: „warning sent”, „escalated”, „breached”. Wtedy wysyłasz raz na krok i możesz audytować, co się stało.
Logika godzin pracy to kolejne źródło przypadkowej złożoności. Jeśli każda reguła ma własne „jeśli weekend to…”, aktualizacje staną się bolesne. Umieść obliczenia dotyczące godzin pracy w jednej funkcji (lub jednym wspólnym bloku), który zwraca „zużyte minuty SLA”, i używaj go wielokrotnie.
Wreszcie: nie polegaj tylko na ponownym przeliczaniu naruszenia od zera. Zapisz moment, gdy to nastąpiło:
breached_at przy pierwszym wykryciu naruszenia i nigdy go nie nadpisuj.escalation_level i last_escalated_at, żeby akcje były idempotentne.notified_warning_at (lub podobne), aby zapobiec powtarzaniu alertów.Przykład: zgłoszenie narusza Response SLA o 10:07. Jeśli tylko przeliczysz później, błąd pauzy/wznowienia może spowodować, że naruszenie wygląda, jakby było o 10:42. Z breached_at = 10:07 raporty i post-mortemy pozostają spójne.
Zanim dodasz timery i alerty, zrób jedną rundę z celem, aby reguły były czytelne za miesiąc.
Praktyczny test: wybierz jedno zgłoszenie bliskie naruszenia i odtwórz jego oś czasu. Jeśli nie potrafisz wyjaśnić, co się stanie przy każdej zmianie statusu bez czytania całego workflow, twój model jest za rozproszony.
Zbuduj najmniejszy użyteczny fragment najpierw. Wybierz jedno SLA (np. first response) i jeden poziom eskalacji (np. powiadomienie team leada). Tydzień realnego użycia nauczy więcej niż perfekcyjny projekt na papierze.
Trzymaj progi i odbiorców jako dane, nie logikę. Wstaw minuty i godziny, reguły godzin pracy, kto jest powiadamiany i która kolejka właścicielska znajduje się w tabelach lub rekordach konfiguracyjnych. Dzięki temu workflow pozostaje stabilny, gdy biznes zmienia liczby i routing.
Zaplanuj prosty widok dashboardu wcześnie. Nie potrzebujesz wielkiego systemu analitycznego — wystarczy wspólny obraz tego, co dzieje się teraz: on track, warning, breached, escalated.
Jeśli budujesz to w narzędziu no-code, warto wybrać platformę, która pozwala modelować dane, logikę i zaplanowane evaluatory w jednym miejscu. Na przykład AppMaster (appmaster.io) wspiera modelowanie bazy danych, wizualne procesy biznesowe i generowanie aplikacji produkcyjnych, co dobrze pasuje do wzorca „events, evaluator, actions”.
Dopracowuj bezpiecznie, iterując w tej kolejności:
Gdy będziesz gotowy/a, zbuduj małą wersję najpierw, potem rozwijaj ją na podstawie realnego feedbacku i prawdziwych zgłoszeń.
Zacznij od jasnego zdefiniowania obietnicy, którą mierzysz, np. pierwsza odpowiedź lub rozwiązanie, i zapisz dokładne reguły startu, zatrzymania i pauzy. Następnie scentralizuj matematykę czasu w jednym evaluatorze, który ustawia eksplicytne stany SLA, zamiast rozsypywać warunki "if now > X" po wielu workflowach.
Timer to zegar, który uruchamiasz po zdarzeniu (np. zmiana statusu). Eskalacja to działanie po osiągnięciu progu (np. powiadomienie lidera, zmiana priorytetu). Breach to zapis faktu, że SLA zostało przekroczone, który możesz później raportować.
Tak — warto śledzić je osobno. First response mierzy czas do pierwszej znaczącej odpowiedzi człowieka, a resolution — do właściwego zamknięcia problemu. Zachowują się inaczej przy pauzach i ponownych otwarciach, więc oddzielne modelowanie upraszcza reguły i raportowanie.
Domyślnie używaj czasu kalendarzowego (24/7), bo jest prostszy. Wprowadź working time tylko jeśli naprawdę go potrzebujesz — dodaje to złożoność z powodu świąt, stref czasowych i częściowych dni.
Modeluj pauzy jako eksplicytne stany powiązane ze specyficznymi statusami (np. Waiting on Customer). Zapisuj, kiedy pauza się zaczęła i skończyła. Przy wznowieniu kontynuuj od pozostałego czasu albo przelicz due time w jednym miejscu — nie pozwalaj, by przypadkowe przełączanie statusu resetowało zegar.
Bo pojedyncze pole breached = true/false ukrywa kontekst: które SLA naruszono, czy jest pauza i czy już eskalowano. Użyj jawnych stanów: On track, Warning, Breached, Paused, Completed — są przewidywalne i łatwiejsze do audytu.
Przechowuj znaczniki czasu i pola wyjaśniające stan: started_at, due_at, breached_at, pola pauzy jak paused_at i paused_reason. Dodaj tracking eskalacji jak last_escalation_level, żeby nie wysyłać tej samej eskalacji wielokrotnie.
Mała drabina: najpierw osoba przypisana do zadania, potem lead zespołu, a manager tylko w razie potrzeby. Przechowuj progi i odbiorców jako dane (tabela polityk), żeby zmiana czasu eskalacji nie wymagała edycji wielu workflowów.
Powiąż powiadomienia ze zmianami stanów (np. OK -> Warning, Warning -> Breached), a nie z każdym kolejnym sprawdzeniem. Dodaj cooldowny i warunki zatrzymania, żeby wysyłać maksymalnie jedno powiadomienie na krok zamiast spamować.
Użyj wzorca events, evaluator, actions: events zapisują fakty, evaluator oblicza terminy i ustawia stany SLA, a actions reagują tylko na zmiany stanu. W AppMaster możesz modelować dane, zbudować evaluator jako proces wizualny i wyzwalać powiadomienia z aktualizacji stanu, zachowując matematykę czasu w jednym miejscu.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


