Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Naucz się projektować hub integracji, by scentralizować poświadczenia, monitorować status synchronizacji i spójnie obsługiwać błędy wraz ze wzrostem stosu SaaS.
Stos SaaS często zaczyna się prosto: jedno CRM, jedno narzędzie do fakturowania, jedna skrzynka supportu. Potem zespół dodaje automatyzację marketingu, magazyn danych, drugi kanał supportu i kilka niszowych narzędzi, które „tylko potrzebują szybkiej synchronizacji”. Nim się obejrzysz, masz sieć połączeń punkt–punkt, za które nikt nie czuje pełnej odpowiedzialności.
To, co psuje się najpierw, zwykle nie są dane. To spoiwo wokół nich.
Poświadczenia rozrzucają się po kontach osobistych, współdzielonych arkuszach i przypadkowych zmiennych środowiskowych. Tokeny wygasają, ludzie odchodzą i nagle „integracja” zależy od logowania, którego nikt nie potrafi znaleźć. Nawet gdy bezpieczeństwo jest dobrze rozwiązane, rotacja sekretów staje się uciążliwa, bo każde połączenie ma swoją konfigurację i swoje miejsce do aktualizacji.
Następuje utrata widoczności. Każda integracja raportuje status inaczej (albo wcale). Jedno narzędzie mówi „połączono”, a w tle cicho przestaje synchronizować. Inne wysyła niejasne maile, które są ignorowane. Gdy handlowiec pyta, dlaczego klient nie został zprovisionowany, odpowiedź zamienia się w poszukiwania po logach, dashboardach i wątkach czatu.
Obciążenie supportu rośnie szybko, bo awarie trudno zdiagnozować, a łatwo powtórzyć. Małe problemy, jak limity szybkości, zmiany schematu i częściowe retry, zamieniają się w długie incydenty, gdy nikt nie widzi pełnej ścieżki od „zdarzenie wystąpiło” do „dane dotarły”.
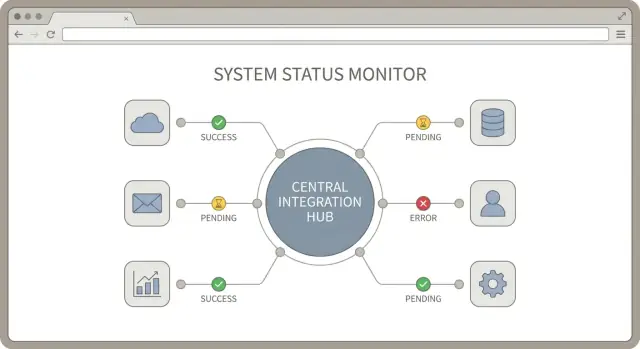
Hub integracji to prosty pomysł: jedno centralne miejsce, gdzie zarządzane, monitorowane i obsługiwane są połączenia do usług zewnętrznych. Dobry projekt huba integracji tworzy spójne zasady dotyczące autoryzacji, raportowania statusu synchronizacji i obsługi błędów.
Praktyczny hub dąży do czterech efektów: mniej awarii (wspólne wzorce retry i walidacji), szybsze naprawy (łatwe śledzenie), bezpieczny dostęp (centralna własność poświadczeń) i niższy wysiłek supportu (standardowe alerty i komunikaty).
Jeśli budujesz stos na platformie takiej jak AppMaster, cel jest ten sam: utrzymać operacje integracyjne na tyle proste, by osoba nietechniczna rozumiała, co się dzieje, a specjalista mógł szybko naprawić problem, gdy się pojawi.
Zanim podejmiesz duże decyzje integracyjne, uzyskaj jasny obraz tego, co już łączysz (lub planujesz połączyć). To etap, który ludzie pomijają, a zwykle powoduje niespodzianki później.
Zacznij od wypisania każdej usługi zewnętrznej w twoim stosie, nawet tych „małych”. Ustal, kto jest właścicielem (osoba lub zespół) i czy jest na żywo, planowana czy eksperymentalna.
Następnie oddziel integracje widoczne dla klientów od automatyzacji działających w tle. Integracja skierowana do użytkownika może być „Połącz swoje konto Salesforce.” Automatyzacja wewnętrzna może być „Gdy faktura w Stripe zostanie opłacona, oznacz klienta jako aktywnego w bazie”. Mają one różne oczekiwania dotyczące niezawodności i różnie zawodzą.
Potem zmapuj przepływy danych, zadając jedno pytanie: kto potrzebuje tych danych, by wykonać swoją pracę? Produkt może potrzebować zdarzeń użycia do onboardingu. Operacje potrzebują statusu konta i provisioningu. Finanse potrzebują faktur, refundów i pól podatkowych. Support potrzebuje ticketów, historii rozmów i dopasowań tożsamości użytkownika. Te potrzeby kształtują hub bardziej niż API dostawców.
Na koniec ustal oczekiwania co do czasu dla każdego przepływu:
Przykład: „Opłacona faktura” może wymagać near real time do kontroli dostępu, ale daily do podsumowań finansowych. Zarejestruj to wcześnie, a monitoring i obsługa błędów staną się znacznie łatwiejsze do ustandaryzowania.
Dobry projekt zaczyna się od granic. Jeśli hub próbuje robić wszystko, staje się wąskim gardłem dla każdego zespołu. Jeśli robi za mało, kończysz z tuzinem jednorazowych skryptów, które zachowują się inaczej.
Zapisz, za co hub odpowiada, a za co nie. Praktyczny podział to:
Wybierz jeden punkt wejścia dla wszystkich integracji i trzymaj się go. Punkt wejścia może być API (inne systemy wywołują hub) albo runner zadań (hub uruchamia zaplanowane pobrania i wysyłki). Używanie obu jest w porządku, ale tylko jeśli dzielą tę samą wewnętrzną ścieżkę, tak by retry, logowanie i alerty działały tak samo.
Kilka decyzji pomoże utrzymać fokus hubu: ustandaryzuj sposób wyzwalania integracji (webhook, harmonogram, manualne ponowne uruchomienie), uzgodnij kształt payloadu granicznego (nawet jeśli partnerzy się różnią), zdecyduj, co będziesz przechowywać (surowe zdarzenia, znormalizowane rekordy, oba albo żadne), zdefiniuj, co oznacza „zrobione" (accepted, delivered, confirmed) i przydziel właściciela do partner-specificznych niuansów.
Zdecyduj, gdzie zachodzą transformacje. Jeśli normalizujesz dane w hubie, systemy downstream pozostaną prostsze, ale hub potrzebuje silniejszego wersjonowania i testów. Jeśli trzymasz hub cienki i przekazujesz surowe payloady partnerów, każdy downstream musi poznać formaty partnerów. Wiele zespołów wybiera drogę pośrednią: normalizują tylko pola wspólne (ID, znaczniki czasu, podstawowy status) i zostawiają reguły domenowe downstream.
Planowanie multi-tenant od pierwszego dnia jest kluczowe. Zdecyduj, czy jednostką izolacji jest klient, workspace czy org. Wpływa to na limity szybkości, przechowywanie poświadczeń i backfille. Gdy token Salesforce jednego klienta wygaśnie, powinieneś wstrzymać tylko zadania tego najemcy, a nie cały pipeline. Narzędzia takie jak AppMaster mogą pomóc modelować najemców i workflowy wizualnie, ale granice i tak muszą być jasne przed budową.
Sejf poświadczeń może albo uspokoić życie, albo stać się stałym źródłem incydentów. Cel jest prosty: jedno miejsce na dostęp, bez dawania systemom i współpracownikom większych uprawnień niż potrzebują.
OAuth i klucze API pojawiają się w różnych miejscach. OAuth jest powszechny w aplikacjach skierowanych do użytkownika, takich jak Google, Slack, Microsoft i wiele CRM-ów. Użytkownik zatwierdza dostęp, a ty przechowujesz token dostępu plus token odświeżający. Klucze API są częstsze w integracjach serwer–serwer i starszych API. Mogą być długotrwałe, co sprawia, że bezpieczne przechowywanie i rotacja są jeszcze ważniejsze.
Przechowuj wszystko zaszyfrowane i powiąż z właściwym najemcą. W produkcie multi-klienckim traktuj poświadczenia jako dane klienta. Zachowaj ścisłą izolację, by token Najemcy A nigdy nie mógł być użyty dla Najemcy B, nawet przez pomyłkę. Przechowuj też metadane, które będą potrzebne później: do którego połączenia należy, kiedy wygasa i jakie uprawnienia przyznano.
Praktyczne zasady zapobiegające większości problemów:
Planuj odświeżanie i odwołanie bez przerywania synchronizacji. Dla OAuth odświeżanie powinno dziać się automatycznie w tle, a hub powinien obsłużyć token expired przez jednokrotne odświeżenie i bezpieczne ponowienie próby. W przypadku odwołania (użytkownik rozłącza, zespół bezpieczeństwa dezaktywuje aplikację lub zakresy się zmieniają) zatrzymaj synchronizację, oznacz połączenie jako needs_auth i zachowaj jasny audyt tego, co się stało.
Jeśli budujesz hub w AppMaster, traktuj poświadczenia jako chroniony model danych, trzymaj dostęp w logice wyłącznie backendowej i eksponuj w UI tylko status connected/disconnected. Operatorzy mogą naprawić połączenie, nie widząc nigdy sekretu.
Gdy łączysz wiele narzędzi, pytanie „czy to działa?” staje się codzienne. Rozwiązaniem nie są kolejne logi. To krótki, spójny zestaw sygnałów synchronizacji, które wyglądają tak samo dla każdej integracji. Dobry hub traktuje status jako funkcję pierwszej klasy.
Zacznij od zdefiniowania krótkiej listy stanów połączenia i używaj ich wszędzie: w UI admina, w alertach i w notatkach supportu. Utrzymuj nazwy proste, żeby osoba nietechniczna mogła podjąć działanie.
Śledź trzy znaczniki czasu dla każdego połączenia: rozpoczęcie ostatniej synchronizacji, ostatni udany sync i czas ostatniego błędu. Opowiadają one szybką historię bez kopania w logach.
Mały widok per-integracja pomaga zespołom supportu działać szybko. Każda strona połączenia powinna pokazywać aktualny stan, te znaczniki czasu i ostatni komunikat o błędzie w czytelnym, przyjaznym formacie (bez stack trace’ów). Dodaj krótką rekomendowaną czynność, np. „Wymagana ponowna autoryzacja” lub „Limit szybkości, ponawiamy próby”.
Dodaj kilka sygnałów zdrowia, które przewidują problemy zanim użytkownicy je zauważą: rozmiar backlogu, liczba retry, trafienia limitów szybkości i ostatnia udana przepustowość (przybliżona liczba elementów zsynchronizowanych w ostatnim przebiegu).
Przykład: twoja synchronizacja CRM jest połączona, ale backlog rośnie, a trafienia limitów szybkości skaczą. To jeszcze nie awaria, ale wyraźny sygnał, by zmniejszyć częstotliwość synców lub partiować żądania. Jeśli budujesz hub w AppMaster, te pola statusu mapują się ładnie do modelu Data Designer i prostego UI panelu supportowego, którego zespół może używać codziennie.
Niezawodna synchronizacja to bardziej powtarzalne kroki niż wyszukana logika. Zacznij od jednego jasnego modelu wykonania, potem dodawaj złożoność tylko tam, gdzie jest potrzebna.
Większość zespołów używa miksu, ale każdy konektor powinien mieć przede wszystkim jedno źródło wyzwalania, żeby było łatwo rozumieć:
W AppMaster często mapuje się to do endpointu webhookowego, procesu w tle i zadania zaplanowanego, które wszystkie zasilają ten sam wewnętrzny pipeline.
Różni dostawcy nazywają to samo inaczej (customerId vs contact_id, różne wartości statusów, formaty dat). Konwertuj każdy przychodzący payload do jednego formatu wewnętrznego, zanim zastosujesz reguły biznesowe. To utrzymuje resztę hubu prostszą i ułatwia zmiany konektora.
Retry są normalne. Hub powinien móc wykonać tę samą akcję dwukrotnie bez tworzenia duplikatów. Powszechne podejście to przechowywanie zewnętrznego ID i „last processed version” (znacznik czasu, numer sekwencji lub ID zdarzenia). Jeśli widzisz ten sam element ponownie, pomijasz go lub bezpiecznie aktualizujesz.
API zewnętrzne mogą być wolne lub zawieszać się. Umieszczaj znormalizowane zadania w trwałej kolejce, a potem przetwarzaj je z wyraźnymi timeoutami. Jeśli wywołanie trwa za długo, oznacz je jako nieudane, zapisz powód i spróbuj ponownie później zamiast blokować wszystko inne.
Obsługuj limity zarówno przez backoff, jak i przez throttling per-konektor. Cofaj się przy 429/5xx z ograniczonym harmonogramem retry, ustaw oddzielne limity współbieżności dla każdego konektora (CRM to nie billing) i dodaj jitter, aby uniknąć fal retry.
Przykład: przychodzi „nowa opłacona faktura” z billingowego webhooka, zostaje znormalizowana i wrzucona do kolejki, potem tworzy lub aktualizuje konto w CRM. Jeśli CRM narzuca limit, ten konektor zwalnia, nie opóźniając synchronizacji ticketów supportu.
Hub, który „czasem zawodzi”, jest gorszy niż brak hubu. Naprawa to wspólny sposób opisu błędów, decyzji, co robić dalej, i komunikowania się z administratorami nietechnicznymi.
Zacznij od standardowego kształtu błędu, który każdy konektor zwraca, nawet jeśli payloady zewnętrzne różnią się. To utrzymuje UI, alerty i playbooki supportu spójne.
RATE_LIMIT)Następnie skategoryzuj awarie w kilka kubełków (trzymaj to małe): auth, validation, timeout, rate limit i outage.
Do każdego kubełka dołącz jasne reguły retry. Limity szybkości dostają opóźnione retryy z backoffem. Timeouty można próbować szybko kilka razy. Walidacja wymaga ręcznej interwencji, dopóki dane nie zostaną poprawione. Auth zatrzymuje integrację i prosi admina o ponowne połączenie.
Przechowuj surowe odpowiedzi od dostawców, ale zabezpieczaj je. Redaguj sekrety (tokeny, klucze API, pełne dane kart) przed zapisem. Jeśli coś może dać dostęp, nie powinno trafić do logów.
Napisz dwa komunikaty na błąd: jeden dla administratorów i jeden dla inżynierów. Wiadomość dla admina może brzmieć: "Połączenie Salesforce wygasło. Ponownie połącz, aby wznowić synchronizację." Widok inżyniera może zawierać zsanityzowaną odpowiedź, request ID i krok, który zawiódł. To miejsce, gdzie spójny hub się opłaca, niezależnie od tego, czy implementujesz flow w kodzie, czy w narzędziu wizualnym jak Business Process Editor w AppMaster.
Wiele projektów integracyjnych zawodzi z nudnych powodów. Hub działał w demo, potem rozsypał się, gdy dodałeś więcej najemców, więcej typów danych i więcej edge case’ów.
Jedną z dużych pułapek jest mieszanie logiki połączenia z logiką biznesową. Gdy „jak rozmawiać z API" leży w tym samym kodzie co „co oznacza rekord klienta”, każda nowa reguła ryzykuje zepsucie konektora. Trzymaj adaptery skoncentrowane na auth, paginacji, limitach szybkości i mapowaniu. Reguły biznesowe trzymaj w osobnej warstwie, którą możesz testować bez wywoływania API zewnętrznych.
Inny powszechny problem to traktowanie stanu najemcy jako globalnego. W produkcie B2B każdy najemca potrzebuje własnych tokenów, kursorów i checkpointów synchronizacji. Jeśli zapisujesz "ostatni czas sync" w jednym współdzielonym miejscu, jeden klient może nadpisać drugiego i otrzymujesz brakujące aktualizacje lub przecieki danych między najemcami.
Pięć pułapek, które pojawiają się najczęściej, i proste naprawy:
Retryom poświęć szczególną uwagę. Jeśli wywołanie tworzące się kończy timeoutem, ponowne uruchomienie może stworzyć duplikat, chyba że używasz kluczy idempotency lub silnej strategii upsert. Jeśli API nie wspiera idempotencji, śledź lokalny ledger zapisów, by wykryć i uniknąć powtórnych zapisów.
Nie pomijaj logów audytu. Gdy support pyta, dlaczego rekord zaginął, potrzebujesz odpowiedzi w minutach, nie zgadywania. Nawet jeśli budujesz hub w narzędziu wizualnym jak AppMaster, traktuj logi i stan per-najemca jako pierwszorzędne.
Dobry hub integracji jest nudny w najlepszym znaczeniu: łączy, jasno raportuje zdrowie i zawodzi w sposób, który zespół potrafi zrozumieć.
Zacznij od sprawdzenia, jak każda integracja się autoryzuje i co robisz z tymi poświadczeniami. Proś o najmniejszy zestaw uprawnień, który nadal pozwala wykonać zadanie (gdzie możliwe, tylko do odczytu). Przechowuj sekrety w dedykowanym sklepie sekretów lub zaszyfrowanym sejfie i rotuj je bez zmian w kodzie. Upewnij się, że logi i komunikaty o błędach nigdy nie zawierają tokenów, kluczy API, tokenów odświeżających ani surowych nagłówków.
Gdy poświadczenia są bezpieczne, potwierdź, że każde połączenie klienta ma jedno, jasne źródło prawdy.
Jasność operacyjna to to, co utrzymuje integracje pod kontrolą, gdy masz dziesiątki klientów i wiele usług zewnętrznych.
Śledź stan połączenia per klient (connected, needs_auth, paused, failing) i eksponuj go w UI admina. Zapisuj ostatni udany czas synchronizacji per obiekt lub per zadanie sync, a nie tylko „coś uruchomiliśmy wczoraj”. Ułatw znalezienie ostatniego błędu z kontekstem: który klient, która integracja, który krok, który zewnętrzny request i co stało się potem.
Ogranicz retry (maks liczba prób i okno czasowe) i projektuj zapisy tak, by były idempotentne, dzięki czemu ponowne uruchomienia nie tworzą duplikatów. Ustal cel supportu: ktoś z zespołu powinien zlokalizować najnowszą porażkę i jej szczegóły w mniej niż dwie minuty bez czytania kodu.
Jeśli szybko budujesz UI hubu i śledzenie statusu, platforma taka jak AppMaster może pomóc szybko wypuścić wewnętrzny dashboard i logikę workflow, przy jednoczesnym generowaniu kodu produkcyjnego.
Wyobraź sobie produkt SaaS, który potrzebuje trzech powszechnych integracji: Stripe do zdarzeń billingowych, HubSpot do przekazywania leadów sprzedaży i Zendesk do ticketów supportu. Zamiast łączyć każde narzędzie bezpośrednio z aplikacją, kierujesz je przez jeden hub integracji.
Onboarding zaczyna się w panelu admina. Admin klika „Connect Stripe”, „Connect HubSpot” i „Connect Zendesk”. Każdy konektor przechowuje poświadczenia w hubie, nie w przypadkowych skryptach czy laptopach pracowników. Potem hub uruchamia import początkowy:
Po imporcie uruchamia się pierwsza synchronizacja. Hub zapisuje rekord synchronizacji dla każdego konektora, aby wszyscy widzieli tę samą historię. Prosty widok admina odpowiada na większość pytań: stan połączenia, ostatni udany czas sync, aktualne zadanie (importowanie, synchronizacja, idle), podsumowanie błędu i kod oraz następne zaplanowane uruchomienie.
Teraz jest ruchliwa godzina i Stripe narzuca limity twoich wywołań. Zamiast psuć cały system, konektor Stripe oznacza zadanie jako retrying, zapisuje częściowy postęp (np. "faktury do 10:40") i cofa próby. HubSpot i Zendesk kontynuują synchronizację.
Support otrzymuje ticket: "Dane billingowe wydają się nieaktualne." Otwierają hub i widzą Stripe w stanie failing z błędem limitu szybkości. Rozwiązanie jest proceduralne:
Jeśli budujesz na platformie takiej jak AppMaster, ten flow mapuje się czysto na logikę wizualną (stany zadań, retry, ekrany administracyjne), a jednocześnie generuje realny backendowy kod produkcyjny.
Dobry projekt huba integracji to mniej budowanie wszystkiego naraz, a więcej uczynienia każdego nowego połączenia przewidywalnym. Zacznij od małego zestawu wspólnych zasad, których każdy konektor musi przestrzegać, nawet jeśli pierwsza wersja wydaje się "zbyt prosta".
Zacznij od spójności: standardowe stany zadań synchronizacji (pending, running, succeeded, failed), krótki zestaw kategorii błędów (auth, rate limit, validation, upstream outage, unknown) i logi audytu, które odpowiadają kto wykonał co, kiedy i dlaczego się nie powiodło. Jeśli nie możesz ufać statusom i logom, dashboardy i alerty będą tylko generować szum.
Dodawaj konektory jeden po drugim, używając tych samych szablonów i konwencji. Każdy konektor powinien ponownie wykorzystywać ten sam flow poświadczeń, te same zasady retry i ten sam sposób zapisywania aktualizacji statusu. To powtarzalność sprawia, że hub jest obsługiwalny, gdy masz dziesięć integracji zamiast trzech.
Praktyczny plan wdrożenia:
Wprowadź dashboardy i alerty dopiero po skorygowaniu podstawowych danych statusu. Zacznij od jednego ekranu pokazującego ostatni czas sync, ostatni wynik, następne uruchomienie i najnowszy komunikat o błędzie z kategorią.
Jeśli wolisz podejście no-code, możesz wymodelować dane, zbudować logikę syncu i udostępnić ekrany statusu w AppMaster, a następnie wdrożyć do chmury lub wyeksportować kod źródłowy. Utrzymaj pierwszą wersję nudną i obserwowalną, potem poprawiaj wydajność i edge case’y, gdy operacje będą stabilne.
Zacznij od prostego inwentarza: każde narzędzie zewnętrzne, kto je posiada i czy jest w produkcji, planowane, czy eksperymentalne. Następnie zapisz, jakie dane przepływają między systemami i dlaczego są ważne dla konkretnego zespołu (support, finanse, operacje). Taka mapa powie ci, co musi działać w czasie rzeczywistym, co może działać codziennie, i co wymaga najsilniejszego monitoringu.
Hub powinien zarządzać wspólną „instalacją”: konfiguracją połączeń, przechowywaniem poświadczeń, harmonogramami/wyzwalaczami, spójnym raportowaniem statusu i obsługą błędów. Decyzje biznesowe (kogo fakturować, co jest kwalifikowanym leadem itp.) trzymaj poza hubem, aby nie musieć zmieniać kodu konektorów za każdym razem, gdy reguły produktowe się zmienią. Taki podział utrzymuje hub użytecznym bez zamieniania go w wąskie gardło.
Wybierz jeden główny punkt wejścia dla każdego konektora, żeby łatwo rozumieć awarie. Webhooki są najlepsze, gdy potrzebujesz aktualizacji niemal w czasie rzeczywistym; zaplanowane pobrania sprawdzają się, gdy dostawcy nie potrafią pushować zdarzeń; a workflowy jobowe są dobre, gdy musisz wykonać kroki w określonej kolejności. Cokolwiek wybierzesz, utrzymuj te same zasady retry, logowania i aktualizacji statusu dla wszystkich wyzwalaczy.
Traktuj poświadczenia jako dane klienta i przechowuj je zaszyfrowane z wyraźną izolacją najemców. Nie pokazuj tokenów w logach, zrzutach ekranu ani w UI, i nie używaj sekretów produkcyjnych w środowisku staging. Również zapisuj metadane potrzebne do operacji, takie jak czas wygaśnięcia, zakresy uprawnień i do którego najemcy/połączenia token należy.
OAuth jest najlepszy, gdy klienci łączą własne konta i chcesz mieć odwoływalny dostęp z zakresami uprawnień. Klucze API są prostsze dla integracji serwer–serwer, ale często żyją dłużej, więc rotacja i kontrola dostępu są ważniejsze. Jeśli możesz wybierać, preferuj OAuth dla połączeń użytkownika, a klucze trzymaj mocno ograniczone i regularnie rotowane.
Oddziel stan najemcy dla wszystkiego: tokeny, kursory, checkpointy, liczniki retry i postęp backfillu. Awaria jednego najemcy powinna wstrzymać tylko jego zadania, a nie cały konektor. Taka izolacja zapobiega przeciekom danych między najemcami i ułatwia diagnozę problemów.
Używaj małego, prostego zestawu stanów we wszystkich konektorach, np. connected, needs_auth, paused i failing. Zapisuj trzy znaczniki czasu: rozpoczęcie ostatniej synchronizacji, ostatni udany sync i czas ostatniego błędu. Na podstawie tych sygnałów większość pytań "czy to działa?" da się odpowiedzieć bez przeglądania logów.
Spraw, by każdy zapis był idempotentny, aby retry nie tworzyły duplikatów. Zazwyczaj oznacza to przechowywanie zewnętrznego ID obiektu i znacznika "last processed" oraz wykonywanie upsertów zamiast bezwarunkowego tworzenia. Jeśli dostawca nie wspiera idempotencji, prowadź lokalny ledger zapisów, żeby wykryć i uniknąć powtórnych zapisów.
Obsługuj limity celowo: throttling per konektor, backoff na 429 i błędy przejściowe oraz dodawanie jitteru, aby retry nie kumulowały się w tym samym czasie. Trzymaj pracę w trwałej kolejce z timeoutami, żeby wolne wywołania API nie blokowały innych integracji. Celem jest spowolnienie jednego konektora bez zatrzymywania całego hubu.
W podejściu no-code wymodeluj połączenia, najemców i pola statusu w AppMaster's Data Designer, a następnie zaimplementuj workflowy synchronizacji w Business Process Editorze. Trzymaj poświadczenia w logice backendowej i eksponuj w UI tylko bezpieczne statusy i podpowiedzi akcji. Możesz szybko wypuścić wewnętrzny panel operacyjny i nadal wygenerować kod produkcyjny.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


