Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Dowiedz się, jak zaprojektować polityki przechowywania danych w aplikacjach biznesowych z jasnymi oknami czasowymi, etapami archiwizacji oraz przepływem usuwania lub anonimizacji, tak by raporty pozostały użyteczne.
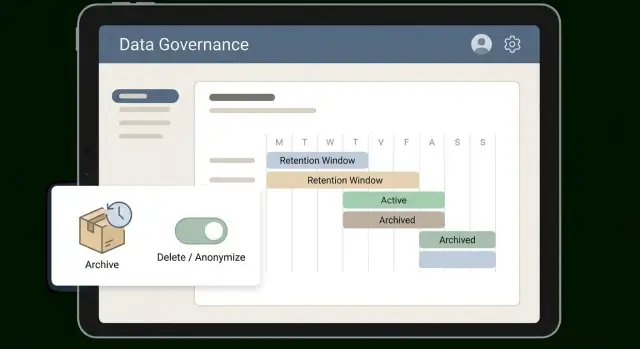
Polityka retencji to zestaw jasnych reguł, które aplikacja stosuje wobec danych: co przechowujesz, jak długo, gdzie to się znajduje i co się dzieje, gdy czas upłynie. Celem nie jest „usunąć wszystko”. Chodzi o zachowanie tego, co potrzebne do prowadzenia biznesu i wyjaśniania przeszłych zdarzeń, przy jednoczesnym usuwaniu tego, czego już nie potrzebujesz.
Bez planu pojawiają się trzy problemy. Przechowywanie rośnie po cichu, aż zaczyna kosztować realne pieniądze. Ryzyko prywatności i bezpieczeństwa rośnie z każdą dodatkową kopią danych osobowych. A raportowanie staje się niewiarygodne, gdy stare rekordy nie pasują do dzisiejszej logiki albo gdy ludzie usuwają rzeczy ad hoc i dashboardy nagle się zmieniają.
Praktyczna polityka retencji równoważy codzienną pracę, dowody i ochronę klienta:
Większość aplikacji biznesowych ma te same ogólne obszary danych, nawet jeśli nazywają je inaczej: profile użytkowników, transakcje, ścieżki audytu, wiadomości i przesłane pliki.
Polityka to część reguły, część workflow, część narzędzi. Reguła może mówić: „przechowujemy zgłoszenia 2 lata”. Workflow definiuje, co to znaczy w praktyce: przenieś starsze zgłoszenia do obszaru archiwum, anonimizuj pola klienta i zapisz, co się stało. Narzędzia czynią to powtarzalnym i audytowalnym.
Jeśli budujesz aplikację na AppMaster, traktuj retencję jako zachowanie produktu, a nie jednorazowe sprzątanie. Zaplanowane Business Processes mogą archiwizować, usuwać lub anonimizować dane w ten sam sposób za każdym razem, dzięki czemu raportowanie pozostaje spójne, a ludzie ufają liczbom.
Zanim ustawisz daty, wyjaśnij, po co w ogóle przechowujesz dane. Decyzje o retencji zwykle kształtują przepisy o prywatności, umowy z klientami oraz wymogi audytu czy podatkowe. Pomiń ten krok, a albo będziesz trzymać za dużo (więcej ryzyka i kosztów), albo usuniesz coś, czego później będziesz potrzebować.
Zacznij od oddzielenia „musimy przechowywać” od „miło mieć”. Dane, które musisz zachować, to często faktury, księgowania i logi audytu potrzebne do udowodnienia, kto co i kiedy zrobił. Miło mieć to stare transkrypcje czatu, szczegółowa historia kliknięć czy surowe logi zdarzeń używane tylko do okazjonalnej analizy.
Wymogi różnią się też w zależności od kraju i branży. Portal wsparcia dla podmiotu medycznego ma inne ograniczenia niż narzędzie administracyjne B2B. Nawet w jednej firmie użytkownicy w różnych krajach mogą wymagać różnych reguł dla tego samego typu rekordu.
Zapisz decyzje prostym językiem i wyznacz właściciela. "Przechowujemy zgłoszenia przez 24 miesiące" to za mało. Zdefiniuj, co jest wliczone, co wyłączone i co się dzieje po upływie okna (archiwizacja, anonimizacja, usunięcie). Wyznacz osobę lub zespół odpowiedzialny, żeby aktualizacje nie ugrzęzły, gdy produkt lub prawo się zmienią.
Uzyskaj akceptacje wcześnie, zanim inżynieria cokolwiek zbuduje. Prawo potwierdzi minimum i obowiązki usunięcia. Bezpieczeństwo oceni ryzyko, kontrolę dostępu i logowanie. Produkt potwierdzi, czego użytkownicy naprawdę potrzebują. Finanse potwierdzi wymagania księgowe.
Przykład: możesz przechowywać dane rozliczeniowe 7 lat, zgłoszenia 2 lata i anonimizować pola profilu użytkownika po zamknięciu konta, zachowując jednocześnie metryki agregowane. W AppMaster te zapisane reguły łatwo odwzorujesz w zaplanowanych procesach i dostępach opartych na rolach, bez zgadywania później.
Polityki retencji zawodzą, gdy zespoły mówią „trzymaj przez 2 lata”, nie wiedząc, co obejmuje „to”. Zbuduj prostą mapę danych, które masz. Nie dąż do perfekcji. Dąż do czegoś, co zrozumie zarówno lider wsparcia, jak i lider finansów.
Praktyczny zestaw startowy:
Oznacz wrażliwość prostym językiem: dane osobowe (imię, email), finansowe (dane bankowe, tokeny płatności), poświadczenia (hashe haseł, klucze API) lub dane regulowane (np. informacje zdrowotne). Jeśli nie jesteś pewien, oznacz jako „potencjalnie wrażliwe” i traktuj ostrożnie, dopóki nie potwierdzisz.
„Gdzie to leży” to zwykle coś więcej niż główna baza danych. Zanotuj dokładne lokalizacje: tabele w bazie, storage plików, logi email/SMS, narzędzia analityczne czy hurtownie danych. Zanotuj też, kto polega na każdym zbiorze (wsparcie, sprzedaż, finanse, kierownictwo) i jak często. To pokaże, co się zepsuje, jeśli usuniesz zbyt agresywnie.
Przydatny nawyk: opisz cel każdego zbioru danymi w jednym zdaniu. Przykład: „Zgłoszenia są przechowywane, żeby rozstrzygać spory i śledzić trendy czasu reakcji”.
Jeśli budujesz w AppMaster, możesz skorelować inwentaryzację z tym, co jest faktycznie wdrożone, przeglądając modele w Data Designer, obsługę plików i włączone integracje.
Gdy mapa istnieje, retencja staje się serią małych, jasnych wyborów zamiast jednego wielkiego zgadywania.
Okno działa tylko wtedy, gdy łatwo je wytłumaczyć i jeszcze łatwiej zastosować. Wiele zespołów sprawdza się przy prostych poziomach dopasowanych do sposobu użycia danych: hot (używane codziennie), warm (używane czasem), cold (przechowywane jako dowód), potem usuń albo anonimizuj. Tiers przekształcają abstrakcyjną politykę w rutynę.
Ustalaj okna według kategorii, a nie jednego uniwersalnego numeru. Faktury i zapisy płatnicze zwykle wymagają długiego okresu cold do celów podatkowych i audytowych. Transkrypcje czatu szybko tracą wartość.
Zdecyduj też, co uruchamia licznik. „Trzymaj 2 lata” nie ma sensu bez definicji „2 lata od czego”. Wybierz jeden wyzwalacz na kategorię, np. data utworzenia, ostatnia aktywność klienta, data zamknięcia zgłoszenia lub zamknięcie konta. Jeśli wyzwalacze będą się różnić bez jasnych reguł, ludzie będą zgadywać, a retencja zacznie dryfować.
Zapisz wyjątki z góry, żeby zespoły nie improwizowały później. Typowe wyjątki to legal hold, chargebacki i dochodzenia fraudowe. Powinny one wstrzymać usuwanie. Nie powinny prowadzić do ukrytych kopii.
Zachowaj reguły krótkie i testowalne:
legal_hold=true: nie usuwaj, dopóki nie zostanie zwolnionyArchiwum to nie backup. Backup służy do odzyskania po błędach lub awariach. Archiwum to świadoma decyzja: starsze dane opuszczają hot tables i przechodzą do tańszego storage, ale nadal są dostępne do audytów, sporów i pytań historycznych.
Większość aplikacji potrzebuje obu. Backupy są częste i szerokie. Archiwa są selektywne i kontrolowane — zwykle odtwarzasz tylko to, czego akurat potrzebujesz.
Tańszy storage pomaga tylko wtedy, gdy ludzie nadal potrafią znaleźć, czego potrzebują. Wiele zespołów używa oddzielnej bazy lub schematu zoptymalizowanego pod zapytania odczytowe, albo eksportuje dane do plików plus tabeli indeksowej do wyszukiwania. Jeśli twoja aplikacja jest zbudowana wokół PostgreSQL (w tym w AppMaster), schemat „archive” lub oddzielna baza może utrzymać produkcyjne tabele szybkie, jednocześnie umożliwiając raportowanie nad danymi archiwalnymi dla uprawnionych użytkowników.
Zanim wybierzesz format, zdefiniuj, co znaczy „przeszukiwalny” w twoim biznesie. Wsparcie może potrzebować wyszukiwania po emailu lub ID zgłoszenia. Finanse może potrzebować sum według miesiąca. Audyty mogą potrzebować śladu po ID zamówienia.
Pełne rekordy zachowują szczegóły, ale kosztują więcej i zwiększają ryzyko prywatności. Podsumowania (miesięczne sumy, liczniki, kluczowe zmiany statusów) są tańsze i często wystarczające do raportowania.
Praktyczne podejście:
Zaplanuj pola indeksujące z wyprzedzeniem. Typowe: główne ID, ID użytkownika/klienta, bucket daty (miesiąc), region i status. Bez nich dane archiwalne istnieją, ale są uciążliwe do odzyskania.
Zdefiniuj też reguły przywracania: kto może poprosić o restore, kto to zatwierdza, gdzie przywrócone dane trafią i ile to potrwa. Przywracanie może być celowo wolne, jeśli zmniejsza to ryzyko, ale powinno być przewidywalne.
Polityka retencji zwykle wymusza wybór: usuwać rekordy, czy zachować je, usuwając dane osobowe. Oba podejścia są poprawne, ale rozwiązują różne problemy.
Twarde usunięcie fizycznie usuwa rekord. Pasuje, gdy nie ma prawnego lub biznesowego powodu, by trzymać dane, a ich przechowywanie stwarza ryzyko (np. stare transkrypcje czatu z wrażliwymi szczegółami).
Soft delete zostawia wiersz, ale oznacza go jako usunięty (często z polem deleted_at) i ukrywa w normalnych ekranach i API. Soft delete jest użyteczny, gdy użytkownicy spodziewają się możliwości przywrócenia albo gdy systemy zewnętrzne mogą nadal odnosić się do rekordu. Wadą jest to, że dane nadal istnieją, zajmują przestrzeń i mogą przeciekać przez eksporty, jeśli nie będziesz ostrożny.
Anonimizacja zachowuje zdarzenie lub transakcję, ale usuwa lub zastępuje wszystko, co identyfikuje osobę. Wykonana poprawnie, nie da się jej odwrócić. Pseudonimizacja to inna rzecz: zastępujesz identyfikatory (np. email) tokenem, ale zachowujesz mapowanie, które może ponownie zidentyfikować osobę. To pomaga w dochodzeniach antyfraudowych, ale nie jest tym samym co anonimowość.
Bądź eksplicyt w kwestii danych powiązanych, bo tu polityki najczęściej zawodzą. Usuwając rekord, ale zostawiając załączniki, miniatury, cache’e, indeksy wyszukiwania czy kopie analityczne, możesz po cichu unieważnić cały sens usunięcia.
Potrzebujesz też dowodu, że usunięcie się odbyło. Zachowaj prosty paragon usunięcia: co zostało usunięte lub zanonimizowane, kiedy to się odbyło, który workflow to wykonał i czy zakończył się powodzeniem. W AppMaster to może być Business Process zapisujący wpis audytowy po zakończeniu zadania.
Raporty psują się, gdy usuwasz lub anonimizujesz rekordy, na których dashboardy polegały przy łączeniu danych w czasie. Zanim cokolwiek zmienisz, zapisz, które liczby muszą pozostać porównywalne miesiąc do miesiąca. W przeciwnym razie potem będziesz rozwiązywać zagadkę „dlaczego wykres z zeszłego roku się zmienił?”.
Zacznij od krótkiej listy metryk, które muszą zostać zachowane:
Następnie przeprojektuj, co przechowujesz dla raportów, tak aby nie wymagało identyfikatorów osobowych. Najbezpieczniejsze jest agregowanie. Zamiast trzymać każdy surowy wiersz na zawsze, trzymaj dzienne sumy, kohorty tygodniowe i liczniki, których nie da się przypisać do osoby. Na przykład możesz zachować „zgłoszenia utworzone dziennie według kategorii” i „mediana czasu pierwszej odpowiedzi tygodniowo”, nawet jeśli później usuniesz pełną treść zgłoszeń.
Niektóre raporty potrzebują stabilnego sposobu grupowania zachowań w czasie. Użyj zastępczego klucza analitycznego, który nie jest bezpośrednio identyfikowalny (np. losowy UUID używany tylko do analityki) i usuń lub zablokuj mapowanie do prawdziwego ID użytkownika po upływie okna retencji.
Oddziel też tabele operacyjne od raportowych, gdy możesz. Dane operacyjne się zmieniają i są usuwane. Tabele raportowe powinny być append-only snapshotami lub agregatami.
Anonimizacja ma konsekwencje. Udokumentuj, co się zmieni, żeby zespoły nie były zaskoczone:
Jeśli budujesz w AppMaster, traktuj anonimizację jako workflow: najpierw zapisz agregaty, zweryfikuj wyniki raportów, a potem anonimizuj pola w rekordach źródłowych.
Polityka retencji działa tylko wtedy, gdy staje się normalnym zachowaniem systemu. Traktuj ją jak każdą inną funkcję: zdefiniuj wejścia, działania i spraw, by rezultaty były widoczne.
Zacznij od jednokartkowej macierzy. Dla każdego typu danych zanotuj okno retencji, wyzwalacz i co się dzieje dalej (zachowaj, archiwizuj, usuń, anonimizuj). Jeśli ludzie nie potrafią tego opisać w minutę, nie będzie przestrzegane.
Dodaj jasne stany cyklu życia, by rekordy nie „znikały tajemniczo”. Większość aplikacji poradzi sobie z trzema stanami: active, archived i pending delete. Przechowuj stan na rekordzie, nie tylko w arkuszu kalkulacyjnym.
Praktyczna sekwencja wdrożenia:
archived_at i delete_after) i zaktualizuj ekrany oraz API, by je respektowały.Przykład: zgłoszenia wsparcia mogą być aktywne przez 90 dni, potem przeniesione do archiwum na 18 miesięcy, a następnie zanonimizowane. Workflow oznacza zgłoszenia jako zarchiwizowane, przenosi duże załączniki do tańszego storage, zachowuje ID zgłoszenia i znaczniki czasu oraz zastępuje imiona i email anonimowymi wartościami.
W AppMaster stany cyklu życia mogą żyć w Data Designer, a logika archiwizacji/purge może działać jako zaplanowane Business Processes. Celem są powtarzalne uruchomienia z czytelnymi logami, łatwymi do audytu.
Większość niepowodzeń retencji nie wynika z niewłaściwego okresu, lecz z tego, że usuwanie dotyka złych tabel, pomija powiązane pliki albo zmienia klucze, od których zależą raporty.
Typowy scenariusz: zespół wsparcia usuwa „stare zgłoszenia”, ale zapomina o załącznikach przechowywanych w osobnej tabeli lub file storze. Później audytor prosi o dowód do zwrotu pieniędzy. Tekst zgłoszenia jest, ale zrzuty ekranu już nie.
Inne pułapki:
user_id) bez aktualizacji dashboardów, joinów i zapisanych zapytańInny częsty problem to raporty oparte na kluczach person-based. Nadpisanie emaila i imienia zwykle jest OK. Zastąpienie wewnętrznego user ID może cicho podzielić historię jednej osoby na wiele tożsamości, a raporty typu MAU czy LTV zaczną się odchylać.
Dwa usprawnienia pomagają większości zespołów. Po pierwsze, zdefiniuj klucze raportowe, które nigdy się nie zmieniają (np. wewnętrzne ID konta) i trzymaj je oddzielnie od pól osobowych, które będą anonimizowane. Po drugie, zaimplementuj usuwanie jako kompletny workflow, który przechodzi po wszystkich powiązanych danych, włączając pliki i logi. W AppMaster często mapuje się to do Business Process, który zaczyna od użytkownika lub konta, zbiera zależności, a potem usuwa lub anonimizuje w bezpiecznej kolejności.
Na koniec: ustal, kto może wstrzymać usuwanie z powodu legal hold i jak ta pauza jest zapisywana. Jeśli nikt nie jest odpowiedzialny za wyjątki, polityka będzie stosowana niespójnie.
Zanim uruchomisz zadania usuwania lub archiwizacji, zrób kontrolę realiów. Większość niepowodzeń wynika z tego, że nikt nie wie, kto jest właścicielem danych, gdzie są kopie, ani jak raporty na nich polegają.
Polityka retencji potrzebuje jasnej odpowiedzialności i planu testowalnego, nie tylko dokumentu.
Proste sprawdzenie to suchy bieg: weź małą partię (np. stare sprawy jednego klienta), uruchom workflow w środowisku testowym, a potem porównaj kluczowe raporty przed i po.
Przechowuj potwierdzenia w sposób, który nie przywraca danych osobowych:
Jeśli budujesz na AppMaster, te kontrole bezpośrednio mapują się na implementację: pola retencji w Data Designer, zaplanowane zadania w Business Process Editor i czytelne wyjścia audytowe.
Wyobraź sobie portal klienta, który przechowuje zgłoszenia wsparcia, faktury i zwroty oraz surowe logi aktywności (logowania, odsłony, wywołania API). Celem jest zmniejszyć ryzyko i koszty przechowywania bez szkody dla rozliczeń, audytów czy trendów.
Zacznij od oddzielenia danych, które musisz trzymać, od tych używanych tylko do codziennego wsparcia.
Prosty harmonogram retencji może wyglądać tak:
Dodaj krok archiwizacji dla starszych zgłoszeń. Zamiast trzymać każdą wiadomość wiecznie w głównych tabelach, przenieś zamknięte zgłoszenia starsze niż 18 miesięcy do obszaru archiwum z małym, przeszukiwalnym podsumowaniem: ID zgłoszenia, daty, obszar produktu, tagi, kod rozwiązania i krótki fragment ostatniej notatki agenta. To zachowuje kontekst bez trzymania pełnych danych osobowych.
Dla zamkniętych kont wybierz anonimizację zamiast usuwania, gdy nadal potrzebujesz trendów. Zastąp identyfikatory osobowe (imię, email, adres) losowymi tokenami, ale zachowaj pola nieidentyfikujące, takie jak typ planu czy miesięczne sumy. Przechowuj agregowane metryki użytkowania (dzienne liczby aktywnych użytkowników, zgłoszenia na miesiąc, przychód na miesiąc) w oddzielnej tabeli raportowej, która nigdy nie zawiera danych osobowych.
Miesięczne raportowanie może się zmienić, ale nie powinno się pogorszyć, jeśli to zaplanujesz:
W AppMaster kroki archiwizacji i anonimizacji mogą działać jako zaplanowane Business Processes, więc polityka wykona się za każdym razem w ten sam sposób.
Polityka retencji działa, gdy ludzie mogą jej przestrzegać, a system ją konsekwentnie wymusza. Zacznij od prostej macierzy retencji: każdy zbiór danych, właściciel, okno, wyzwalacz, następna akcja (archiwizuj, usuń, anonimizuj) i podpis. Przeglądnij to z prawem, bezpieczeństwem, finansami i zespołem obsługi klienta.
Nie automatyzuj wszystkiego naraz. Wybierz jeden zbiór danych end-to-end, najlepiej coś powszechnego jak zgłoszenia wsparcia lub logi logowań. Zrób workflow realnym, uruchom go przez tydzień i potwierdź, że raportowanie odpowiada oczekiwaniom biznesu. Potem rozszerzaj ten wzorzec na kolejne zbiory.
Utrzymuj automatyzację obserwowalną. Podstawowy monitoring zwykle obejmuje:
Zaplanuj też stronę użytkową. Zdecyduj, o co użytkownik może poprosić (eksport, usunięcie, korekta), kto to zatwierdza i co system robi. Daj wsparciu krótką wewnętrzną instrukcję: które dane są dotknięte, ile to trwa i co nie podlega odzyskaniu po usunięciu.
Jeśli chcesz to wdrożyć bez własnego kodu, AppMaster (appmaster.io) dobrze pasuje do automatyzacji retencji, bo możesz modelować pola cyklu życia w Data Designer i uruchamiać zaplanowane Business Processes do archiwizacji i anonimizacji z logowaniem audytu. Zacznij od jednego zbioru, zrób to nudne i niezawodne, a potem powtarzaj wzorzec w całej aplikacji.
Polityka retencji zapobiega niekontrolowanemu wzrostowi danych i nawykowi „trzymaj wszystko”. Ustala przewidywalne reguły: co przechowujemy, jak długo i co się dzieje po upływie czasu, dzięki czemu koszty, ryzyko prywatności i niespodzianki w raportach nie narastają z czasem.
Zacznij od tego, po co dane istnieją i kto ich potrzebuje: operacje, audyt/podatki oraz ochrona klienta. Wybierz proste okna dla typów danych (faktury, zgłoszenia, logi, pliki) i uzyskaj wczesne zatwierdzenie od prawników, bezpieczeństwa, finansów i produktu, żeby nie budować procesów, które później trzeba będzie cofać.
Zdefiniuj jeden jasny wyzwalacz dla każdej kategorii, np. data zamknięcia zgłoszenia, ostatnia aktywność lub zamknięcie konta. Jeśli wyzwalacz jest niejasny, różne zespoły będą go interpretować inaczej i retencja zacznie dryfować.
Użyj flagi legal hold lub stanu, który wstrzymuje archiwizację/anonimizację/usuwanie dla konkretnych rekordów, i spraw, by to wstrzymanie było widoczne i audytowalne. Celem jest wstrzymanie normalnego przepływu bez tworzenia ukrytych kopii.
Backup służy do odzyskiwania po awariach i pomyłkach — jest szeroki i częsty. Archiwum to świadomy ruch starszych danych z hot tables do tańszego, kontrolowanego miejsca, które wciąż jest możliwe do odczytu w celu audytów i sporów.
Usuń, gdy naprawdę nie ma powodu, by trzymać dane, a ich istnienie zwiększa ryzyko. Anonimizuj, gdy potrzebujesz zdarzenia lub transakcji dla trendów lub dowodu, ale możesz trwale usunąć pola osobowe, tak że nie da się powiązać rekordu z osobą.
Soft delete jest przydatny do przywracania i unikania złamanych referencji, ale nie jest prawdziwym usunięciem. Wiersze ze soft delete nadal zajmują miejsce i mogą przeciekać do eksportów, analityki czy widoków administracyjnych, jeśli każde zapytanie i workflow ich nie filtruje.
Zabezpiecz raportowanie przez przechowywanie długoterminowych metryk jako agregatów lub snapshotów, które nie zależą od identyfikatorów osobowych. Jeśli dashboardy łączą pola, które planujesz nadpisać (np. email), najpierw przeprojektuj model raportowy, by historyczne wykresy nie zmieniały się po uruchomieniu retencji.
Traktuj retencję jak funkcję produktu: pola cyklu życia na rekordach, zaplanowane zadania do archiwizacji i potem usuwania/anonimizacji oraz wpisy audytowe potwierdzające działania. W AppMaster to łatwo odwzorować w Data Designer i zaplanowanych Business Processes, które wykonują te same kroki za każdym razem.
Przeprowadź mały dry run na środowisku testowym lub kopi produkcyjnej i porównaj kluczowe sumy przed i po. Upewnij się też, że potrafisz odnaleźć rekord we wszystkich miejscach (baza, storage plików, eksporty, logi) i że zapisujesz potwierdzenie usunięcia/anonimizacji z nazwą reguły, znacznikami czasu i liczbami.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


