Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Minimalna konfiguracja obserwowalności dla backendów CRUD: strukturalne logi, podstawowe metryki i praktyczne alerty, które wcześnie wykrywają wolne zapytania, błędy i przestoje.
request_id, użytkowniku, endpointzie i błędzie.\n- Kilka podstawowych metryk: tempo żądań, wskaźnik błędów, latencja i czas w bazie danych.\n- Alerty powiązane z wpływem na użytkownika (skoki błędów lub utrzymująca się wolna odpowiedź), nie każdy wewnętrzny warning.\n\nPomaga też oddzielić symptomy od przyczyn. Symptom to to, co odczuwa użytkownik: 500, time-outy, powolne strony. Przyczyna to to, co to tworzy: contentia locków, wyczerpana pula połączeń, albo wolne zapytanie po dodaniu nowego filtra. Alertuj na symptomy i używaj sygnałów „przyczyny” do dochodzenia.\n\nPraktyczna zasada: wybierz jedno miejsce do oglądania ważnych sygnałów. Przełączanie kontekstu między narzędziem logów, metryk i osobną skrzynką alertów spowalnia cię wtedy, gdy to najważniejsze.\n\n## Strukturalne logi, które pozostają czytelne pod presją\n\nGdy coś psuje się, najszybsza droga do odpowiedzi to zwykle: „Które dokładnie żądanie zrealizował ten użytkownik?” Dlatego stabilne ID korelacji jest ważniejsze niż niemal każda inna poprawka logów.\n\nWybierz jedną nazwę pola (zwykle request_id) i traktuj ją jako obowiązkową. Generuj ją na krawędzi (API gateway lub pierwszy handler), przekazuj przez wewnętrzne wywołania i dołączaj do każdej linii logu. Dla zadań w tle twórz nowe request_id na każde uruchomienie zadania i przechowuj parent_request_id, gdy zadanie zostało wyzwolone przez wywołanie API.\n\nLoguj w JSON, nie jako tekst swobodny. To utrzymuje logi wyszukiwalnymi i spójnymi, gdy jesteś zmęczony, zestresowany i przeglądasz je pobieżnie.\n\nProsty zestaw pól wystarcza dla większości serwisów API CRUD:\n\n- timestamp, level, service, env\n- request_id, route, method, status\n- duration_ms, db_query_count\n- tenant_id lub account_id (bezpieczne identyfikatory, nie dane osobowe)\n\nLogi powinny pomagać zawęzić „który klient i który ekran”, bez zamieniania ich w wyciek danych. Unikaj domyślnie imion, e-maili, numerów telefonów, adresów, tokenów czy pełnych ciał żądań. Jeśli potrzebujesz głębszych detali, loguj je tylko na żądanie i z redakcją.\n\nDwa pola szybko się zwracają w systemach CRUD: duration_ms i db_query_count. Wykrywają wolne handlery i przypadkowe wzory N+1 nawet zanim dodasz tracing.\n\nZdefiniuj poziomy logów, aby wszyscy używali ich w ten sam sposób:\n\n- info: oczekiwane zdarzenia (żądanie zakończone, zadanie rozpoczęte)\n- warn: nietypowe, ale możliwe do odzyskania (wolne żądanie, retry zakończony sukcesem)\n- error: niepowodzenie żądania lub zadania (exception, timeout, zła zależność)\n\nJeżeli budujesz backendy z platformą taką jak AppMaster, zachowaj te same nazwy pól w generowanych serwisach, aby „wyszukaj po request_id” działało wszędzie.\n\n## Kluczowe metryki, które mają znaczenie dla backendów CRUD i API\n\nWiększość incydentów w aplikacjach CRUD ma znajomy kształt: jeden lub dwa endpointy zwalniają, baza danych się przeciąża, a użytkownicy widzą kółka ładowania lub time-outy. Twoje metryki powinny tę historię uczynić oczywistą w kilka minut.\n\nMinimalny zestaw zwykle obejmuje pięć obszarów:\n\n- Ruch: żądania na sekundę (po route lub przynajmniej per serwis) i tempo żądań wg klas statusów (2xx, 4xx, 5xx)\n- Błędy: wskaźnik 5xx, liczba timeoutów oraz osobna metryka dla „błędów biznesowych” zwracanych jako 4xx (aby nie budzić ludzi z powodu błędów użytkownika)\n- Latencja (percentyle): p50 dla typowego doświadczenia oraz p95 (czasem p99) jako wykrycie „coś jest nie tak”\n- Saturacja: CPU i pamięć, plus specyficzna dla aplikacji saturacja (wykorzystanie workerów, presja wątków/goroutine, jeśli ją eksponujesz)\n- Obciążenie bazy danych: p95 czasu zapytań, wykorzystanie puli połączeń (in-use vs max) oraz czas oczekiwania na locki (lub liczba zapytań czekających na locki)\n\nDwie rzeczy sprawiają, że metryki są bardziej użyteczne.\n\nPo pierwsze, oddziel interaktywne żądania API od pracy w tle. Wolny wysyłacz e-maili lub pętla retry webhooka może zająć CPU, połączenia DB lub sieć wychodzącą i sprawić, że API będzie wyglądać na „losowo wolne”. Śledź kolejki, retry i czas trwania zadań jako osobne serie czasowe, nawet jeśli działają w tym samym backendzie.\n\nPo drugie, zawsze dołączaj metadane wersji/buildu do dashboardów i alertów. Gdy wdrażasz nowy generowany backend (na przykład po regeneracji kodu z narzędzia no-code jak AppMaster), chcesz szybko odpowiedzieć na pytanie: czy wskaźnik błędów lub p95 latencji wzrósł zaraz po tej wersji?\n\nProsta zasada: jeśli metryka nie potrafi powiedzieć, co zrobić dalej (cofnąć, zwiększyć skalę, poprawić zapytanie, zatrzymać zadanie), nie należy jej trzymać w minimalnym zestawie.\n\n## Sygnały bazy danych: zwykła przyczyna bólu CRUD\n\nW aplikacjach CRUD baza danych często jest miejscem, gdzie „coś wydaje się wolne” staje się prawdziwym bólem użytkownika. Minimalna konfiguracja powinna jasno pokazywać, kiedy wąskie gardło jest w PostgreSQL (nie w kodzie API) i jakiego typu to problem.\n\n### Co mierzyć najpierw w PostgreSQL\n\nNie potrzebujesz dziesiątek dashboardów. Zacznij od sygnałów, które wyjaśniają większość incydentów:\n\n- Wskaźnik wolnych zapytań i p95/p99 czasu zapytań (oraz top najwolniejszych zapytań)\n- Oczekiwania na locki i deadlocki (kto kogo blokuje)\n- Wykorzystanie połączeń (aktywne połączenia vs limit puli, nieudane połączenia)\n- Presja dysku i I/O (latencja, saturacja, wolne miejsce)\n- Opóźnienie replikacji (jeśli używasz read replicas)\n\n### Oddziel czas aplikacji od czasu bazy\n\nDodaj histogram czasu zapytań w warstwie API i otaguj go endpointem lub przypadkiem użycia (np. GET /customers, “search orders”, “update ticket status”). To pokaże, czy endpoint jest wolny, bo wykonuje wiele małych zapytań, czy jedno duże.\n\n### Wykrywaj wzorce N+1 wcześnie\n\nEkrany CRUD często wywołują N+1: jedno zapytanie listujące, potem jedno zapytanie na wiersz po dane powiązane. Obserwuj endpointy, gdzie liczba żądań pozostaje stała, ale liczba zapytań DB na żądanie rośnie. Jeśli generujesz backendy z modeli i logiką biznesową, to właśnie tam często optymalizujesz sposób pobierania danych.\n\nJeśli już masz cache, śledź wskaźnik trafień. Nie dodawaj cache tylko po to, by mieć ładniejsze wykresy.\n\nTraktuj zmiany schematu i migracje jako okno ryzyka. Zarejestruj, kiedy się zaczęły i skończyły, a potem obserwuj skoki w lockach, czasie zapytań i błędach połączeń w tym oknie.\n\n## Alerty, które budzą właściwą osobę z właściwym powodem\n\nAlerty powinny wskazywać na realny problem użytkownika, nie na zajęty wykres. Dla aplikacji CRUD zacznij od obserwowania tego, co odczuwają użytkownicy: błędów i spowolnień.\n\nJeżeli dodasz tylko trzy alerty na start, niech to będą:\n\n- rosnący wskaźnik 5xx\n- utrzymująca się wysoka latencja p95\n- nagły spadek udanych żądań\n\nPo tym dodaj kilka alertów „prawdopodobnej przyczyny”. Backend CRUD często zawodzą w przewidywalny sposób: baza wyczerpuje połączenia, kolejka zadań rośnie, albo pojedynczy endpoint zaczyna timed-outować i ciągnie cały API w dół.\n\n### Progi: baza + margines, nie zgadywanie\n\nTwarde liczby typu „p95 > 200ms” rzadko działają we wszystkich środowiskach. Zmierz normalny tydzień, a potem ustaw alert tuż powyżej normy z marginesem bezpieczeństwa. Na przykład, jeśli p95 latencji zwykle wynosi 350–450 ms w godzinach pracy, ustaw alarm na 700 ms przez 10 minut. Jeśli 5xx typowo wynosi 0.1–0.3%, powiadamiaj przy 2% przez 5 minut.\n\nUtrzymuj progi stabilne. Nie dostrajaj ich codziennie. Dostosuj po incydencie, gdy możesz powiązać zmianę z realnymi skutkami.\n\n### Paging vs ticket: zdecyduj zanim będzie potrzebne\n\nUżywaj dwóch poziomów ważności, aby ludzie ufali sygnałowi:\n\n- Page gdy użytkownicy są zablokowani lub dane są zagrożone (wysokie 5xx, time-outy API, pula połączeń DB bliska wyczerpania).\n- Utwórz ticket gdy degradacja jest, ale nie jest nagląca (wolne narastanie p95, rosnący backlog kolejki, trend wzrostu użycia dysku).\n\nWyciszaj alerty podczas oczekiwanych zmian jak okna wdrożeniowe i planowana konserwacja.\n\nUczyń alerty wykonalnymi. Dołącz „co sprawdzić najpierw” (top endpoint, połączenia DB, ostatnie wdrożenie) i „co się zmieniło” (nowe wydanie, aktualizacja schematu). Jeśli budujesz na AppMaster, zanotuj, który backend lub moduł został ostatnio zregenerowany i wdrożony, bo to często najszybszy trop.\n\n## Proste SLO dla aplikacji biznesowych (i jak kształtują alerty)\n\nMinimalna konfiguracja staje się prostsza, gdy zdefiniujesz, co znaczy „wystarczająco dobrze”. To właśnie robią SLO: jasne cele, które zamieniają nieostre monitorowanie w konkretne alerty.\n\nZacznij od SLI, które odzwierciedlają odczucia użytkownika: dostępność (czy użytkownicy mogą zakończyć żądania), latencja (jak szybko kończą się akcje) oraz wskaźnik błędów (jak często żądania zawodzą).\n\nUstal SLO per grupę endpointów, nie per route. Dla aplikacji CRUD grupowanie utrzymuje czytelność: odczyty (GET/list/search), zapisy (create/update/delete) i auth (login/odświeżanie tokenu). To unika setek malutkich SLO, których nikt nie utrzymuje.\n\nPrzykładowe SLO pasujące do typowych oczekiwań:\n\n- Aplikacja wewnętrzna CRUD (panel admina): 99.5% dostępności miesięcznie, 95% odczytów poniżej 800 ms, 95% zapisów poniżej 1.5 s, wskaźnik błędów poniżej 0.5%.\n- Publiczne API: 99.9% dostępności miesięcznie, 99% odczytów poniżej 400 ms, 99% zapisów poniżej 800 ms, wskaźnik błędów poniżej 0.1%.\n\nBudżety błędów to dozwolony „zły czas” w ramach SLO. SLO 99.9% miesięcznie oznacza, że możesz mieć około 43 minut przestoju w miesiącu. Jeśli wydasz go szybko, wstrzymaj ryzykowne zmiany, dopóki stabilność nie wróci.\n\nUżyj SLO do decyzji, co zasługuje na alert, a co na trend w dashboardzie. Alarmuj, gdy szybko spalasz budżet błędów (użytkownicy aktywnie zawodzą), nie wtedy, gdy metryka jest nieco gorsza niż wczoraj.\n\nJeśli szybko budujesz backendy (na przykład AppMaster generujący serwis Go), SLO pomagają skupić się na wpływie na użytkownika, nawet gdy implementacja pod spodem się zmienia.\n\n## Krok po kroku: zbuduj minimalną konfigurację obserwowalności w jeden dzień\n\nZacznij od części systemu, której dotykają użytkownicy najczęściej. Wybierz wywołania API i zadania, które gdy będą wolne lub zepsute, sprawiają wrażenie, że cała aplikacja nie działa.\n\nZapisz swoje kluczowe endpointy i pracę w tle. Dla aplikacji CRUD to zwykle login, list/search, create/update i jedno zadanie eksportu lub importu. Jeśli używasz AppMaster, uwzględnij generowane endpointy i dowolne Business Processy, które uruchamiają się okresowo lub na webhooki.\n\n### Plan na jeden dzień\n\n- Godzina 1: Wybierz top 5 endpointów i 1–2 zadania w tle. Zanotuj, co znaczy „dobrze”: typowa latencja, oczekiwany wskaźnik błędów, normalny czas DB.\n- Godziny 2–3: Dodaj strukturalne logi ze spójnymi polami: request_id, user_id (jeśli jest), endpoint, status_code, latency_ms, db_time_ms i krótki error_code dla znanych błędów.\n- Godziny 3–4: Dodaj podstawowe metryki: żądania na sekundę, p95 latencji, wskaźnik 4xx, wskaźnik 5xx oraz czasy DB (czas zapytań i wykorzystanie puli połączeń jeśli je masz).\n- Godziny 4–6: Zbuduj trzy dashboardy: przegląd (health at a glance), widok API (rozdzielone endpointy) i widok bazy danych (wolne zapytania, locki, użycie połączeń).\n- Godziny 6–8: Dodaj alerty, wywołaj kontrolowaną awarię i potwierdź, że alert jest wykonalny.\n\nTrzymaj alerty nieliczne i ukierunkowane. Chcesz alerty, które wskazują na wpływ na użytkownika, nie „coś się zmieniło”.\n\n### Alerty do rozpoczęcia (5–8 łącznie)\n\nSolidny zestaw startowy to: zbyt wysoka p95 latencja API, utrzymujący się wskaźnik 5xx, nagły skok 4xx (często auth lub zmiany walidacji), błędy zadań w tle, wolne zapytania DB, połączenia DB bliskie limitu oraz mało miejsca na dysku (jeśli hostujesz samodzielnie).\n\nNastępnie napisz mały runbook per alert. Jedna strona wystarczy: co sprawdzić najpierw (panele dashboardu i kluczowe pola w logach), prawdopodobne przyczyny (locki DB, brak indeksu, brakujący restart workera), i pierwsza bezpieczna akcja (zrestartuj zawieszony worker, cofnij zmianę, zatrzymaj ciężkie zadanie).\n\n## Typowe błędy, które czynią monitoring głośnym lub bezużytecznym\n\nNajszybszy sposób zmarnować minimalną konfigurację obserwowalności to potraktować monitoring jak checkbox. Aplikacje CRUD zwykle zawodzą w kilku przewidywalnych sposobach (wolne zapytania DB, time-outy, złe wydania), więc twoje sygnały powinny być skupione na tych rzeczach.\n\nNajczęstsza porażka to zmęczenie alertami: za dużo alarmów, za mało akcji. Jeśli budzisz ludzi przy każdym skoku, przestaną ufać alertom po dwóch tygodniach. Dobra zasada: alert powinien wskazywać prawdopodobną naprawę, nie tylko „coś się zmieniło”.\n\nInny klasyczny błąd to brak ID korelacji. Jeśli nie możesz powiązać logu błędu, wolnego żądania i zapytania DB z jednym żądaniem, tracisz godziny. Upewnij się, że każde żądanie ma request_id (i że jest on w logach, trace'ach jeśli je masz, i w odpowiedziach gdy to bezpieczne).\n\n### Co zwykle generuje hałas\n\nHałaśliwe systemy mają wspólne problemy:\n\n- Jeden alert miesza 4xx i 5xx, więc błędy klienta i serwera wyglądają identycznie.\n- Metryki śledzą tylko średnie, ukrywając ogon latencji (p95 lub p99), gdzie użytkownicy odczuwają ból.\n- Logi zawierają przypadkowo dane wrażliwe (hasła, tokeny, pełne ciała żądań).\n- Alerty uruchamiają się na symptomy bez kontekstu (wysokie CPU) zamiast wpływu na użytkownika (wskaźnik błędów, latencja).\n- Wdrożenia są niewidoczne, więc regresje wyglądają jak losowe awarie.\n\nAplikacje CRUD są szczególnie podatne na „pułapkę średniej”. Jedno wolne zapytanie może uczynić 5% żądań uciążliwymi, podczas gdy średnia wygląda dobrze. Ogon latencji razem z wskaźnikiem błędów daje jaśniejszy obraz.\n\nDodaj markery deployu. Niezależnie czy wysyłasz z CI, czy regenerujesz kod na platformie jak AppMaster, zarejestruj wersję i czas wdrożenia jako zdarzenie i w logach.\n\n## Szybkie sprawdzenia: minimalna lista kontrolna obserwowalności\n\nTwoja konfiguracja działa, gdy możesz szybko odpowiedzieć na kilka pytań bez grzebania w dashboardach przez 20 minut. Jeśli nie możesz szybko dostać „tak/nie”, brakuje ci kluczowego sygnału lub twoje widoki są zbyt rozproszone.\n\n### Szybkie kontrole podczas incydentu\n\nWiększość tego powinna zająć mniej niż minutę:\n\n- Czy możesz stwierdzić, czy użytkownicy właśnie teraz zawodzą (tak/nie) z jednego widoku błędów (5xx, time-outy, nieudane zadania)?\n- Czy widzisz najwolniejszą grupę endpointów i jej p95 latencję oraz czy się pogarsza?\n- Czy potrafisz oddzielić czas aplikacji od czasu DB dla żądania (czas handlera, czas zapytań DB, wywołania zewnętrzne)?\n- Czy widzisz, czy baza danych jest blisko limitu połączeń lub limitu CPU, i czy zapytania się kolejkowały?\n- Jeśli alert się uruchomił, czy sugeruje następny krok (cofnąć, skalować, sprawdzić połączenia DB, zbadać jeden endpoint), a nie tylko „latencja wysoka”?\n\nLogi powinny być jednocześnie bezpieczne i użyteczne. Muszą mieć wystarczający kontekst, by śledzić jedno nieudane żądanie przez usługi, ale nie mogą wyciekać danych osobowych.\n\n### Sprawdzenie sanity logów\n\nWeź jedno niedawne niepowodzenie i otwórz jego logi. Potwierdź, że masz request_id, endpoint, kod statusu, czas trwania i czytelny komunikat błędu. Potwierdź też, że nie logujesz surowych tokenów, haseł, pełnych danych płatności ani pól osobowych.\n\nJeśli budujesz backendy CRUD z AppMaster, dąż do jednego widoku incydentu, który łączy te kontrole: błędy, p95 latencję po endpointach i zdrowie DB. To samo w sobie obejmuje większość rzeczywistych przerw w aplikacjach biznesowych.\n\n## Przykład: diagnozowanie wolnego ekranu CRUD z właściwymi sygnałami\n\nPanel admina działa dobrze przez poranek, potem staje się zauważalnie wolny w godzinach szczytu. Użytkownicy skarżą się, że otwieranie listy „Orders” i zapisywanie zmian trwa 10–20 sekund.\n\nZaczynasz od sygnałów wysokiego poziomu. Dashboard API pokazuje, że p95 latencja dla endpointów odczytujących skoczyła z ~300 ms do 4–6 s, podczas gdy wskaźnik błędów pozostał niski. Równocześnie panel bazy danych pokazuje aktywne połączenia bliskie limitowi puli i wzrost oczekiwań na locki. CPU w węzłach backendowych wygląda normalnie, więc to raczej nie problem compute.\n\nNastępnie bierzesz jedno wolne żądanie i śledzisz je w logach. Filtrujesz po endpointzie (np. GET /orders) i sortujesz po czasie trwania. Bierzesz request_id z żądania 6-sekundowego i szukasz go we wszystkich usługach. Widzisz, że handler zakończył się szybko, ale linia logu zapytania DB w tym samym request_id pokazuje zapytanie 5.4 s z rows=50 i dużym lock_wait_ms.\n\nTeraz możesz z przekonaniem stwierdzić przyczynę: spowolnienie jest w ścieżce bazy danych (wolne zapytanie lub contentia locków), nie w sieci czy CPU backendu. To właśnie daje minimalna konfiguracja: szybsze zawężenie przyczyny.\n\nTypowe naprawy, w kolejności bezpieczeństwa:\n\n- Dodaj lub dostosuj indeks dla filtra/sortu używanego na ekranie listy.\n- Usuń N+1 przez pobranie powiązanych danych jednym zapytaniem lub pojedynczym joinem.\n- Dostosuj pulę połączeń, aby nie głodzić DB pod obciążeniem.\n- Dodaj cache tylko dla stabilnych, czytanych często danych (i udokumentuj reguły invalidacji).\n\nZamknij pętlę celowanym alertem. Page tylko wtedy, gdy p95 latencja dla grupy endpointów pozostaje ponad twoim progiem przez 10 minut i użycie połączeń DB jest powyżej np. 80%. Ta kombinacja unika hałasu i wykryje problem wcześniej następnym razem.\n\n## Następne kroki: trzymaj to na minimalnym poziomie, potem ulepszaj po rzeczywistych incydentach\n\nMinimalna konfiguracja obserwowalności powinna być nudna pierwszego dnia. Jeśli zaczniesz od zbyt wielu dashboardów i alertów, będziesz je stroił wiecznie i i tak przegapisz prawdziwe problemy.\n\nTraktuj każdy incydent jako informację zwrotną. Po wypuszczeniu naprawy zapytaj: co sprawiłoby, że wykrycie i diagnoza byłyby szybsze? Dodaj tylko to.\n\nStandaryzuj wcześnie, nawet jeśli dziś masz tylko jedną usługę. Używaj tych samych nazw pól w logach i tych samych nazw metryk wszędzie, aby nowe usługi pasowały do wzoru bez dyskusji. To też sprawia, że dashboardy są wielokrotnego użytku.\n\nMała dyscyplina wydawnicza szybko się spłaca:\n\n- Dodaj marker deployu (wersja, środowisko, commit/build ID), aby widzieć, czy problemy zaczęły się po wydaniu.\n- Napisz krótki runbook dla top 3 alertów: co to znaczy, pierwsze sprawdzenia i kto za to odpowiada.\n- Trzymaj pojedynczy „złoty” dashboard z tym, co najważniejsze dla każdej usługi.\n\nJeśli budujesz backendy z AppMaster, pomaga zaplanować pola obserwowalności i kluczowe metryki przed generacją serwisów, aby każdy nowy API wychodził ze spójnymi strukturalnymi logami i sygnałami zdrowia domyślnie. Jeśli chcesz jedno miejsce do rozpoczęcia budowy tych backendów, AppMaster (appmaster.io) jest zaprojektowany do generowania produkcyjnych backendów, aplikacji webowych i mobilnych przy zachowaniu spójnej implementacji w miarę zmiany wymagań.\n\nWybierz jedno kolejne ulepszenie na raz, bazując na tym, co faktycznie zaszkodziło:\n\n- Dodaj pomiar czasu zapytań DB (i loguj najwolniejsze zapytania z kontekstem).\n- Uszczelnij alerty tak, aby wskazywały wpływ na użytkownika, a nie tylko skoki zasobów.\n- Uczyń jeden dashboard czytelniejszym (przemianuj wykresy, dodaj progi, usuń nieużywane panele).\n\nPowtarzaj ten cykl po każdym realnym incydencie. W kilka tygodni uzyskasz monitoring dopasowany do twojej aplikacji CRUD i ruchu API zamiast ogólnego szablonu.Rozpocznij wdrażanie obserwowalności, gdy problemy produkcyjne zajmują więcej czasu na wyjaśnienie niż na naprawę. Jeśli widzisz „losowe 500”, wolne listy lub time-outy, których nie potrafisz odtworzyć, mały zestaw spójnych logów, metryk i alertów zaoszczędzi godziny przepytywania.
Monitoring mówi ci że coś jest nie tak, natomiast obserwowalność pomaga zrozumieć dlaczego to się stało dzięki sygnałom bogatym w kontekst, które można skorelować. W praktyce dla API CRUD chodzi o szybkie zdiagnozowanie: który endpoint, który użytkownik/tenant i czy czas spędzono w aplikacji czy w bazie danych.
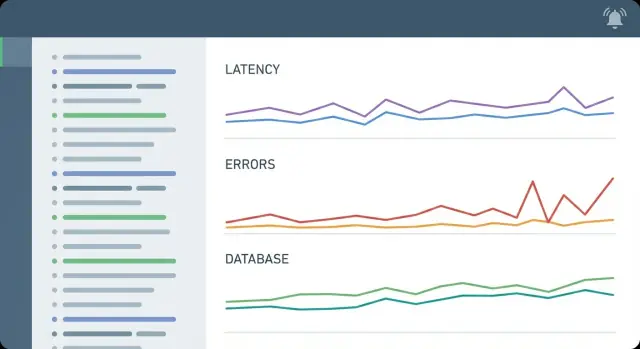
Zacznij od strukturalnych logów żądań, kilku podstawowych metryk i kilku alertów wpływających na użytkownika. Śledzenie (tracing) może poczekać w wielu aplikacjach CRUD, jeśli logujesz duration_ms, db_time_ms (lub podobne) i masz stabilne request_id, po którym można wyszukiwać.
Użyj jednego pola korelacji, na przykład request_id, i dołączaj je do każdej linii logu żądania oraz do każdego uruchomienia zadania w tle. Generuj je na krawędzi (edge), przepuszczaj przez wewnętrzne wywołania i upewnij się, że możesz wyszukać logi po tym ID, aby szybko odtworzyć jedno nieudane lub wolne żądanie.
Loguj timestamp, level, service, env, route, method, status, duration_ms oraz bezpieczne identyfikatory jak tenant_id lub account_id. Domyślnie unikaj logowania danych osobowych, tokenów i pełnych treści żądań; jeśli potrzebujesz detali, dodawaj je tylko dla konkretnych błędów z redakcją danych.
Śledź tempo żądań, wskaźnik 5xx, percentyle latencji (przynajmniej p50 i p95) oraz podstawową saturację (CPU/pamięć oraz presję workerów czy kolejek). Dodaj wczesne metryki czasu bazy danych i użycia puli połączeń, ponieważ wiele awarii CRUD wynika z przeciążenia bazy lub wyczerpania puli połączeń.
Ponieważ ukrywają one ogon wolnych żądań, które odczuwają użytkownicy. Średnie wartości mogą wyglądać dobrze, podczas gdy p95 jest fatalne dla znaczącej części żądań — to dokładnie powoduje wrażenie „losowej” wolności stron CRUD.
Obserwuj wskaźniki wolnych zapytań i percentyle czasu zapytań, oczekiwania na locki/deadlocki oraz użycie połączeń względem limitu puli. Te sygnały pokażą, czy baza danych jest wąskim gardłem i czy problem wynika z wydajności zapytań, blokad czy braku połączeń pod obciążeniem.
Zacznij od alertów na objawy widoczne dla użytkownika: utrzymujący się wzrost 5xx, utrzymująca się wysoka latencja p95 oraz nagły spadek liczby udanych żądań. Dodawaj alerty wskazujące prawdopodobne przyczyny (np. użycie puli DB blisko limitu, zalegające kolejki) dopiero po tym, aby sygnał on-call pozostał wiarygodny i wykonalny.
Dołącz metadane wersji/buildu do logów, dashboardów i alertów oraz rejestruj markery wdrożeń, aby szybko sprawdzić, czy regresja pojawiła się tuż po wydaniu. Dla generowanych backendów (jak AppMaster generujący serwisy Go) to szczególnie ważne, bo regeneracje i redeploye mogą występować często.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


