Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Soft delete vs hard delete: dowiedz się, jak zachować historię, uniknąć złamanych referencji i jednocześnie spełnić wymogi prywatności dzięki jasnym regułom.
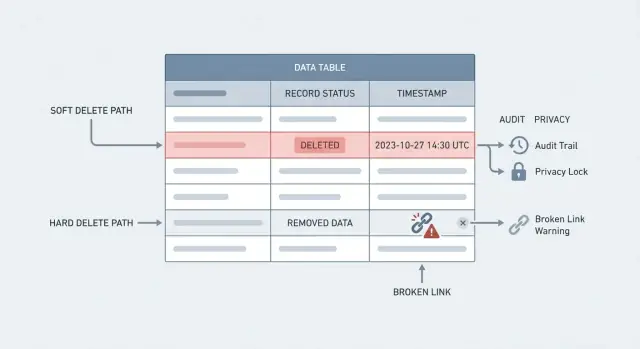
„Usunięcie” może znaczyć dwie bardzo różne rzeczy. Myląc je, zespoły tracą historię lub nie spełniają żądań dotyczących prywatności.
Hard delete to to, co większość osób sobie wyobraża: wiersz zostaje usunięty z bazy danych. Zapytaj go później i go nie ma. To prawdziwe usunięcie, ale może też łamać referencje (np. zamówienie wskazujące na usuniętego klienta), o ile nie zaprojektujesz tego inaczej.
Soft delete zachowuje wiersz, ale oznacza go jako usunięty, zwykle przez pole takie jak deleted_at lub is_deleted. Twoja aplikacja traktuje go jak nieistniejący, ale dane nadal są dostępne do raportów, wsparcia i audytów.
Sednem wyboru soft delete vs hard delete jest prosty kompromis: historia vs faktyczne usunięcie. Soft delete chroni historię i umożliwia „cofnij”. Hard delete zmniejsza ilość przechowywanych danych, co ma znaczenie dla prywatności, bezpieczeństwa i wymogów prawnych.
Usunięcia wpływają na więcej niż pamięć masową. Zmieniają to, na co zespół będzie mógł odpowiedzieć później: agent wsparcia próbujący zrozumieć poprzednią skargę, dział finansów próbujący zrekompensować rozliczenia albo zgodność sprawdzająca, kto i kiedy coś zmienił. Jeśli dane znikają za wcześnie, raporty się przesuwają, sumy przestają się zgadzać, a dochodzenia zamieniają się w domysły.
Przydatny model myślowy:
W praktyce możesz soft-delete'ować konto użytkownika, żeby uniemożliwić logowanie i zachować historię zamówień, a potem uruchomić hard delete (lub anonimizację) pól osobowych po okresie retencji lub po zweryfikowanym żądaniu prawo do usunięcia (GDPR).
Żadne narzędzie samo za Ciebie nie podejmie tej decyzji. Nawet budując na platformie no-code jak AppMaster, prawdziwa praca polega na zdecydowaniu, co „usunięte” znaczy dla każdej tabeli i upewnieniu się, że każdy ekran, raport i API stosuje tę samą regułę.
Większość zespołów zauważa problemy związane z usuwaniem tylko, gdy coś pójdzie nie tak. „Proste” usunięcie może wymazać kontekst, historię i zdolność do wyjaśnienia, co się wydarzyło.
Hard delete jest ryzykowne, bo trudno je cofnąć. Ktoś klika niewłaściwy przycisk, zadanie automatyczne ma błąd albo agent wsparcia postępuje według złego scenariusza. Bez czystych backupów i jasnego procesu przywracania, ta utrata staje się trwała, a biznes szybko odczuje konsekwencje.
Złamane referencje to następna niespodzianka. Usuwasz klienta, ale jego zamówienia nadal istnieją. Masz zamówienia wskazujące w próżnię, faktury, które nie mogą wyświetlić nazwy płatnika, i portal, który błędnie się zachowuje przy ładowaniu powiązanych danych. Nawet z ograniczeniami kluczy obcych, „naprawa” może być gorsza: kaskadowe usunięcia mogą wymazać znacznie więcej niż zamierzałeś.
Analityka i raportowanie też się komplikują. Gdy stare rekordy znikają, metryki zmieniają się retrospektywnie. Współczynnik konwersji z zeszłego miesiąca spada, LTV maleje, a wykresy trendów zaczynają mieć luki, których nikt nie potrafi wytłumaczyć. Zespół zaczyna kłócić się o liczby zamiast podejmować decyzje.
Wsparcie i zgodność to obszary, gdzie boli najbardziej. Klienci pytają „Dlaczego zostałem obciążony?” lub „Kto zmienił mój plan?” Jeśli rekordu nie ma, nie da się odtworzyć osi czasu. Tracisz ścieżkę audytu, która odpowiedziałaby na podstawowe pytania: co się zmieniło, kiedy i przez kogo.
Typowe tryby awarii stojące za debatą soft delete vs hard delete:
Soft delete jest zwykle bezpieczniejszym wyborem, gdy rekord ma wartość długoterminową lub jest powiązany z innymi danymi. Zamiast usuwać wiersz, oznaczasz go jako usunięty (np. deleted_at lub is_deleted) i ukrywasz w normalnych widokach. W wyborze soft delete vs hard delete taki domyślny wybór redukuje niespodzianki później.
Sprawdza się wszędzie tam, gdzie potrzebna jest ścieżka audytu w bazach danych. Zespoły operacyjne często muszą odpowiedzieć na pytania typu „Kto zmienił to zamówienie?” lub „Dlaczego ta faktura została anulowana?” Jeśli usuniesz zbyt wcześnie, tracisz dowody istotne dla finansów, wsparcia i raportowania zgodności.
Soft delete też umożliwia „cofnij”. Administratorzy mogą przywrócić zgłoszenie zamknięte przez pomyłkę, przywrócić produkt, który został zarchiwizowany, lub odzyskać treść stworzoną przez użytkownika po fałszywym zgłoszeniu jako spam. Taki flow przywracania trudno zaoferować, jeśli dane zostały fizycznie skasowane.
Relacje to kolejny duży powód. Twarde usunięcie rekordu rodzica może złamać ograniczenia kluczy obcych lub zostawić mylące luki w raportach. Przy soft delete joiny pozostają stabilne, a historyczne sumy konsekwentne (dzienny przychód, zrealizowane zamówienia, statystyki czasu odpowiedzi).
Soft delete to silny domyślny wybór dla rekordów biznesowych takich jak zgłoszenia wsparcia, wiadomości, zamówienia, faktury, logi audytu, historia aktywności i profile użytkowników (przynajmniej do momentu potwierdzenia ostatecznego usunięcia).
Przykład: agent wsparcia „usuwa” notatkę do zamówienia z błędem. Przy soft delete notatka znika z normalnego UI, ale przełożeni mogą ją dalej przeglądać przy reklamacji, a raporty finansowe pozostają wytłumaczalne.
Soft delete to świetny domyślny wybór dla wielu aplikacji, ale są sytuacje, gdy przechowywanie danych (nawet ukrytych) jest złym wyborem. Hard delete oznacza, że rekord zostaje trwale usunięty i czasem jest jedyną opcją spełniającą wymogi prawne, bezpieczeństwa lub koszty.
Najjaśniejszy przypadek to obowiązki prywatności i wynikające z umowy zobowiązania. Jeśli osoba korzysta z prawa do usunięcia (GDPR) lub umowa obiecuje usunięcie po określonym okresie, „oznaczenie jako usunięty” często nie wystarcza. Może być konieczne usunięcie wiersza, powiązanych kopii i wszystkich identyfikatorów, które mogą wskazywać z powrotem na osobę.
Bezpieczeństwo to kolejny powód. Niektóre dane są zbyt wrażliwe, by je przechowywać: surowe tokeny dostępu, kody resetu hasła, klucze prywatne, jednorazowe kody weryfikacyjne lub niezaszyfrowane sekrety. Trzymanie ich dla historii rzadko jest warte ryzyka.
Hard delete może być też właściwy ze względu na skalę. Jeśli masz ogromne tabele starych zdarzeń, logów lub telemetryki, soft delete cicho zwiększa rozmiar bazy i spowalnia zapytania. Zaplanowana polityka purge utrzymuje system responsywnym i koszty przewidywalne.
Hard delete często nadaje się do danych tymczasowych (cache, sesje, szkice importów), krótkotrwałych artefaktów bezpieczeństwa (tokeny resetu, OTP, kody zaproszeń), kont testowych/demo oraz dużych historycznych zbiorów, gdzie potrzebne są tylko agregaty.
Praktyczne podejście to oddzielić „historię biznesową” od „danych osobowych”. Na przykład zachowaj faktury dla księgowości, ale trwale usuń (lub zanonimizuj) pola profilu użytkownika identyfikujące osobę.
Jeśli zespół debatuje soft delete vs hard delete, użyj prostego testu: jeśli przechowywanie danych tworzy ryzyko prawne lub bezpieczeństwa, powinno wygrać hard delete (lub nieodwracalna anonimizacja).
Soft delete działa najlepiej, gdy jest nudny i przewidywalny. Cel jest prosty: rekord pozostaje w bazie, ale normalne elementy aplikacji zachowują się, jakby go nie było.
Spotkasz trzy popularne wzorce: znacznik czasu deleted_at, flaga is_deleted albo enum statusu. Wiele zespołów woli deleted_at, bo odpowiada jednocześnie na dwa pytania: czy jest usunięty i kiedy to nastąpiło.
Jeśli już masz wiele stanów cyklu życia (active, pending, suspended), enum statusu też może działać, ale trzymaj „deleted” oddzielnie od „archived” i „deactivated”. To różne rzeczy:
Soft delete vs hard delete często zawodzi przy polach unikalnych jak email, username czy numer zamówienia. Jeśli użytkownik jest „usunięty”, ale jego email nadal jest przechowywany i nadal unikalny, ta sama osoba nie będzie mogła się zapisać ponownie.
Dwa typowe sposoby naprawy: albo wymuszaj unikalność tylko dla nieusuniętych wierszy, albo nadpisz wartość przy usunięciu (np. dopisz losowy sufiks). Co wybierzesz zależy od wymagań prywatności i audytu.
Zdecyduj, co różne grupy widzą. Powszechna zasada: zwykli użytkownicy nigdy nie widzą usuniętych rekordów, użytkownicy wsparcia/administratorzy widzą je z wyraźną etykietą, a eksporty/raporty zawierają je tylko na żądanie.
Nie polegaj na tym, że „wszyscy pamiętają dodać filtr”. Umieść regułę w jednym miejscu: widokach, domyślnych zapytaniach lub warstwie dostępu do danych. Jeśli budujesz w AppMaster, zwykle oznacza to uwzględnienie filtra w tym, jak twoje endpointy i Business Processes pobierają dane, aby usunięte wiersze przypadkowo nie pojawiły się na nowym ekranie.
Zapisz znaczenia w krótkiej wewnętrznej notatce (albo komentarzach w schemacie). Przyszłe „ja” podziękuje, gdy „deleted”, „archived” i „deactivated” pojawią się na tym samym spotkaniu.
Usuwania najczęściej psują aplikacje przez relacje. Rekord rzadko występuje sam: użytkownicy mają zamówienia, zgłoszenia mają komentarze, projekty mają pliki. Trudność w debacie soft delete vs hard delete polega na zachowaniu spójności referencji przy jednoczesnym zachowaniu wrażenia, że element „zniknął”.
Klucze obce chronią przed złamanymi referencjami, ale każda opcja ma inne znaczenie:
Jeśli używasz soft delete, RESTRICT często jest najbezpieczniejszym domyślnym ustawieniem. Zachowujesz wiersz, więc klucze pozostają ważne i unikasz dzieci wskazujących na nic.
Soft delete zwykle nie zmienia kluczy obcych. Zamiast tego filtrujesz usuniętych rodziców w aplikacji i raportach. Jeśli klient jest soft-usunięty, jego faktury nadal powinny dołączać się poprawnie, ale ekrany nie powinny pokazywać klienta w listach wyboru.
Dla załączników, komentarzy i logów aktywności zdecyduj, co „usunięcie” znaczy dla użytkownika. Niektóre zespoły zachowują „powłokę”, ale usuwają ryzykowne części: zastępują zawartość załącznika placeholderem, jeśli wymaga tego prywatność, oznaczają komentarze jako od usuniętego użytkownika (lub anonimizują autora) i traktują logi aktywności jako niezmienne.
Joiny i raportowanie potrzebują jasnej reguły: czy usunięte wiersze mają być uwzględnione? Wiele zespołów utrzymuje dwa standardowe zapytania: jedno „tylko aktywne” i jedno „z uwzględnieniem usuniętych”, by wsparcie i raportowanie nie ukrywały ważnej historii.
Praktyczna polityka często używa soft delete do naprawy codziennych błędów i hard delete do wymogów prawnych lub prywatności. Jeśli potraktujesz to jako jedną decyzję (soft delete vs hard delete), przegapisz środek: zachowaj historię przez jakiś czas, potem oczyść to, co trzeba.
Rozpocznij od podziału danych na kilka grup. „Dane profilu użytkownika” są osobowe, „transakcje” to zapisy finansowe, a „logi” to historia systemu. Każda grupa potrzebuje innych reguł.
Krótki plan, który działa w większości zespołów:
Powiedzmy, klient prosi o zamknięcie konta. Soft-delete'uj rekord użytkownika natychmiast, aby nie mógł się zalogować i żeby nie złamać referencji. Potem anonimizuj pola osobowe, które nie powinny pozostać (imię, email, telefon), pozostawiając fakty transakcyjne potrzebne do księgowości. W końcu zaplanowane zadanie purge usuwa to, co nadal jest osobowe po okresie oczekiwania.
Zespoły wpadają w kłopoty nie dlatego, że wybrały złe podejście, lecz dlatego, że stosują je nierówno. Częsty wzór to: „soft delete vs hard delete” na papierze, ale „ukryj to na jednym ekranie i zapomnij o reszcie” w praktyce.
Łatwy błąd: ukrywasz usunięte rekordy w UI, ale nadal pojawiają się przez API, eksporty CSV, narzędzia admina lub zadania synchronizujące. Użytkownicy szybko zauważą, gdy „usunięty” klient pojawi się na liście mailowej lub w wyszukiwarce mobilnej.
Raporty i wyszukiwanie to kolejna pułapka. Jeśli zapytania raportowe nie filtrują konsekwentnie usuniętych wierszy, sumy dryfują, a dashboardy tracą wiarygodność. Najgorsze przypadki to zadania w tle, które indeksują lub ponownie wysyłają usunięte elementy, bo nie zastosowały tych samych reguł.
Hard delete też może być przesadzony. Jedno kaskadowe usunięcie może wymazać zamówienia, faktury, wiadomości i logi, których faktycznie potrzebowałeś do audytu. Jeśli musisz twardo usuwać, bądź explicit co do tego, co może zniknąć, a co musi pozostać lub zostać zanonimizowane.
Unikalne ograniczenia powodują subtelne problemy przy soft delete. Jeśli użytkownik usuwa konto, a potem próbuje zarejestrować się ponownie z tym samym emailem, rejestracja może nie powieść się, jeśli stary wiersz nadal trzyma unikalny email. Zaplanuj to wcześniej.
Zespoły zgodności zapytają: czy potraficie udowodnić, że usunięcie miało miejsce i kiedy? „Wydaje nam się, że zostało usunięte” nie przejdzie w wielu przeglądach polityki retencji danych. Przechowuj znacznik czasu usunięcia, kto/co je wywołało oraz niezmienny wpis logu.
Przed wdrożeniem sprawdź całą powierzchnię: API, eksporty, wyszukiwanie, raporty i zadania w tle. Przejrzyj kaskady tabelę po tabeli i potwierdź, że użytkownicy mogą ponownie tworzyć „unikalne” dane jak email lub username, gdy jest to częścią obietnicy produktu.
Zanim wybierzesz soft delete vs hard delete, zweryfikuj rzeczywiste zachowanie aplikacji, nie tylko schemat.
Potem przetestuj ścieżkę prywatności end-to-end. Czy potrafisz zrealizować żądanie usunięcia danych zgodnie z GDPR w kopiach, eksportach, indeksach wyszukiwania, tabelach analitycznych i integracjach, nie tylko w głównej bazie?
Praktyczny sposób na walidację to uruchomienie jednego „usuń użytkownika” w środowisku staging i prześledzenie śladu danych.
Klient pisze: „Proszę usunąć moje konto.” Masz też faktury, które muszą pozostać dla księgowości i sprawdzeń chargeback. Tu soft delete vs hard delete staje się praktyczny: możesz usunąć dostęp i dane osobowe, zachowując zapisy finansowe, które firma musi przechować.
Oddziel „konto” od „rekordu rozliczeniowego”. Konto dotyczy logowania i tożsamości. Rekord rozliczeniowy dotyczy transakcji, która już miała miejsce.
Czyste podejście:
Zgłoszenia do wsparcia i wiadomości często są pośrodku. Jeśli treść wiadomości zawiera dane osobowe, może być konieczne wyredagowanie części tekstu, usunięcie załączników i zachowanie „skorupy” zgłoszenia (znaczniki czasowe, kategoria, rozwiązanie) do śledzenia jakości. Jeśli produkt wysyła wiadomości (email/SMS, Telegram), usuń też identyfikatory wychodzące, aby osoba nie była ponownie kontaktowana.
Co wsparcie może nadal zobaczyć? Zwykle numery faktur, daty, kwoty, status oraz notatkę, że użytkownik został usunięty i kiedy. Czego nie mogą widzieć: cokolwiek identyfikującego osobę: email logowania, pełne imię i nazwisko, adresy, zapisane metody płatności czy aktywne sesje.
Decyzje o usuwaniu przetrwają tylko wtedy, gdy zostaną spisane i zastosowane jednakowo w całym produkcie. Traktuj soft delete vs hard delete najpierw jako pytanie polityczne, nie trik techniczny.
Zacznij od prostej polityki retencji danych, którą każdy w zespole będzie mógł przeczytać. Powinna mówić, co przechowujesz, jak długo i dlaczego. „Dlaczego” ma znaczenie, bo to mówi, co wygra, gdy cele będą w konflikcie (np. historia wsparcia vs żądania prywatności).
Dobrym domyślnym wyborem często jest: soft delete dla codziennych rekordów biznesowych (zamówienia, zgłoszenia, projekty), hard delete dla naprawdę wrażliwych danych (tokeny, sekrety) i wszystkiego, czego nie powinieneś przechowywać.
Gdy polityka jest jasna, zbuduj przepływy, które ją egzekwują: widok „kosza” do przywracania, kolejkę purge do nieodwracalnego usunięcia po kontrolach oraz widok audytu pokazujący kto co i kiedy zrobił. Uczyń „purge” trudniejszym niż zwykłe „usuń”, aby nie był używany przypadkowo.
Jeśli wdrażasz to w AppMaster (appmaster.io), warto modelować pola soft-delete w Data Designer i scentralizować logikę delete, restore i purge w jednym Business Process, aby te same zasady obowiązywały na wszystkich ekranach i endpointach.
Twarde usunięcie fizycznie usuwa wiersz z bazy danych, więc przyszłe zapytania go nie znajdą. Miękkie usunięcie zachowuje wiersz, ale oznacza go jako usunięty (często przez deleted_at), więc aplikacja ukrywa go w normalnych widokach, zachowując historię dla wsparcia, audytów i raportów.
Stosuj soft delete domyślnie dla rekordów biznesowych, które mogą się przydać do wyjaśnień później — np. zamówienia, faktury, zgłoszenia, wiadomości i aktywność konta. Zmniejsza to ryzyko przypadkowej utraty danych, zachowuje relacje i umożliwia bezpieczne „cofnij” bez przywracania z backupu.
Hard delete jest najlepszy, gdy przechowywanie danych stwarza ryzyko prywatności lub bezpieczeństwa, albo gdy przepisy wymagają faktycznego usunięcia. Typowe przykłady to tokeny resetujące hasło, jednorazowe kody, sesje, tokeny API i dane osobowe, które muszą być skasowane po zweryfikowanym żądaniu lub po okresie retencji.
Pole deleted_at (znacznik czasu) jest powszechnym wyborem, ponieważ mówi zarówno, że rekord jest usunięty, jak i kiedy to się stało. Wspiera to praktyczne scenariusze, takie jak okna retencji (np. purge po 30 dniach) i pytania audytowe („kiedy to zostało usunięte?”) bez potrzeby oddzielnego logu dotyczącego czasu.
Unikalne pola jak email czy username często blokują ponowną rejestrację, jeśli „usunięty” wiersz nadal trzyma wartość. Typowe rozwiązania to: egzekwowanie unikalności tylko dla nieusuniętych wierszy albo nadpisanie wartości przy usunięciu (np. dopisanie losowego sufiksu). Wybór zależy od wymogów prywatności i audytu.
Twarde usunięcie rekordu rodzica może osierocić rekordy potomne (np. zamówienia) lub wywołać kaskadowe usunięcia, które usuwają więcej niż zamierzano. Soft delete zwykle unika złamanych referencji, bo klucze pozostają ważne, ale nadal trzeba konsekwentnie filtrować, by usunięci rodzice nie pojawiali się w dropdownach czy widokach użytkownika.
Jeśli historyczne wiersze zostaną trwale usunięte, przeszłe sumy mogą się zmienić, trendy mogą mieć luki, a liczby finansowe przestaną się zgadzać z tym, co widziano wcześniej. Soft delete pomaga zachować historię, ale tylko wtedy, gdy raporty i zapytania analityczne jednoznacznie określą, czy uwzględniają usunięte wiersze i stosują tę regułę konsekwentnie.
„Soft deleted” często nie wystarcza przy prawie do usunięcia danych, bo dane osobowe mogą nadal istnieć w bazie i kopiach zapasowych. Praktyczny wzorzec to natychmiastowe odebranie dostępu, następnie trwałe usunięcie lub nieodwracalna anonimizacja identyfikatorów osobowych, pozostawiając tylko nieosobowe fakty transakcyjne potrzebne do księgowości lub rozstrzygania sporów.
Przywracanie powinno odtworzyć rekord w bezpiecznym, poprawnym stanie bez reanimowania wrażliwych elementów, które powinny pozostać usunięte, jak sesje czy tokeny resetujące. Potrzebne są też jasne zasady dla danych powiązanych, by nie przywrócić konta jednocześnie z brakującymi relacjami lub uprawnieniami.
Centralizuj zachowanie usuwania, przywracania i purge, aby każdy API, ekran, eksport i job tła stosował ten sam filtr. W AppMaster (appmaster.io) zwykle oznacza to dodanie pól soft-delete w Data Designer i wdrożenie logiki raz w Business Process, aby nowe endpointy nie ujawniały przypadkowo usuniętych danych.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


