Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Praktyczne logowanie audytu dla narzędzi wewnętrznych: śledź kto co i kiedy zmienił przy każdej operacji CRUD, bezpiecznie przechowuj różnice i pokaż czytelny kanał aktywności administratora.
Większość zespołów dodaje logi audytu dopiero, gdy coś idzie nie tak. Klient kwestionuje zmianę, liczba w finansach się przesuwa albo audytor pyta „Kto to zatwierdził?”. Jeśli zaczynasz dopiero wtedy, próbujesz odtworzyć przeszłość z fragmentarycznych poszlak: znaczników czasowych w bazie, wiadomości w Slacku i zgadywania.
W przypadku większości aplikacji wewnętrznych „wystarczające dla zgodności” nie oznacza perfekcyjnego systemu śledczego. Chodzi o to, by móc szybko i konsekwentnie odpowiedzieć na kilka pytań: kto wykonał zmianę, który rekord został dotknięty, co się zmieniło, kiedy to się stało i skąd przyszła zmiana (UI, import, API, automatyzacja). To przejrzystość sprawia, że log audytu budzi zaufanie.
Gdzie logi audytu zwykle zawodzą, to nie baza danych, tylko pokrycie. Historia wygląda dobrze przy prostych edycjach, a luki pojawiają się, gdy praca przyspiesza. Typowe problemy to masowe edycje, importy, zadania zaplanowane, akcje administratora omijające normalne ekrany (np. reset haseł lub zmiana ról) oraz usuwania (zwłaszcza hard delete).
Częstym błędem jest też mieszanie logów debugowych z logami audytu. Logi debugowe są tworzone dla deweloperów: hałaśliwe, techniczne i często niespójne. Logi audytu służą rozliczalności: stałe pola, jasne sformułowania i stabilny format, który można pokazać osobom niebędącym inżynierami.
Praktyczny przykład: menedżer wsparcia zmienia plan klienta, a potem automatyzacja aktualizuje dane billingowe. Jeśli zapisujesz tylko „zaktualizowano klienta”, nie dowiesz się, czy zrobiła to osoba, workflow czy import nadpisał zmianę.
Dobry log audytu zaczyna się od jednego celu: osoba powinna móc przeczytać pojedynczy wpis i zrozumieć, co się stało, bez zgadywania.
Zapisuj wyraźnego aktora dla każdej zmiany. Większość zespołów zatrzymuje się na „user id”, ale w narzędziach wewnętrznych dane często zmieniają się przez więcej niż jedno wejście.
Dołącz typ aktora i identyfikator aktora, żeby rozróżniać pracownika, konto serwisowe lub zewnętrzną integrację. Jeśli masz zespoły lub tenantów, zapisuj też id organizacji lub workspace, aby zdarzenia nigdy się nie mieszały.
Zarejestruj akcję (create, update, delete, restore) oraz cel. „Cel” powinien być zarazem czytelny dla człowieka i precyzyjny: nazwa tabeli lub encji, id rekordu i najlepiej krótka etykieta (np. numer zamówienia) dla szybkiego przeglądu.
Praktyczny minimalny zestaw pól:
Przechowuj znacznik czasu w UTC. Zawsze. Później wyświetlaj go w lokalnym czasie widza w UI administracyjnym. To unika sporów „dwóch osób widziało różne czasy” podczas przeglądu.
Jeśli obsługujesz ryzykowne akcje, takie jak zmiany ról, zwroty pieniędzy czy eksporty danych, dodaj pole „reason”. Nawet krótka notatka typu "Zatwierdzone przez menedżera w ticket 1842" może zamienić ślad audytu z szumu w dowód.
Pierwszy wybór projektowy to miejsce, w którym trzymasz „prawdę” o historii zmian. Większość zespołów kończy z jednym z dwóch modeli: append-only event log albo per-entity version history.
Event log to jedna tabela, która zapisuje każdą akcję jako nowy wiersz. Każdy wiersz przechowuje kto to zrobił, kiedy, jaką encję dotknął i ładunek (często JSON) opisujący zmianę.
Ten model jest prosty do dodania i elastyczny, gdy model danych ewoluuje. Naturalnie mapuje się też do kanału aktywności administracyjnej, bo feed to w zasadzie „najnowsze zdarzenia na górze”.
Podejście z historią wersji tworzy tabele historii per encja, np. Order_history lub User_versions, gdzie każda aktualizacja tworzy nowy pełny snapshot (lub ustrukturyzowany zestaw zmienionych pól) z numerem wersji.
Ułatwia to raportowanie punktu w czasie ("jak wyglądał rekord w zeszły wtorek?"). Dla audytorów może też być bardziej przejrzyste, bo linia czasu każdego rekordu jest samowystarczalna.
Praktyczny sposób wyboru:
Niezależnie od wyboru, trzymaj wpisy audytu niemodyfikowalne: bez aktualizacji, bez usuwania. Jeśli coś było nie tak, dodaj nowy wpis wyjaśniający korektę.
Rozważ też dodanie correlation_id (lub id operacji). Jedna akcja użytkownika często powoduje wiele zmian (np. „Dezaktywuj użytkownika” aktualizuje użytkownika, unieważnia sesje i anuluje zadania). Wspólny correlation id pozwala grupować te wiersze w jedną czytelną operację.
Rzetelne logowanie audytu zaczyna się od jednej zasady: każdy zapis przechodzi przez jedną ścieżkę, która też zapisuje zdarzenie audytu. Jeśli pewne aktualizacje dzieją się w background jobie, imporcie lub szybkim edytorze omijającym normalny flow zapisu, twoje logi będą mieć dziury.
Dla tworzeń zapisz aktora i źródło (UI, API, import). Importy to miejsce, gdzie zespoły często tracą „kto”, więc zapisuj jawne pole „performed by” nawet jeśli dane pochodziły z pliku lub integracji. Przydatne jest też zapisanie wartości początkowych (pełny snapshot lub mały zestaw kluczowych pól), by wyjaśnić, dlaczego rekord istnieje.
Aktualizacje są trudniejsze. Możesz zapisywać tylko zmienione pola (małe, czytelne i szybkie) albo przechowywać pełny snapshot po każdym zapisie (proste do zapytań później, ale kosztowne). Praktyczny kompromis: zapisuj diffy dla normalnych edycji i snapshoty tylko dla wrażliwych obiektów (np. uprawnienia, dane bankowe, reguły cenowe).
Usunięcia nie powinny kasować dowodów. Preferuj soft delete (flaga is_deleted plus wpis audytu). Jeśli musisz wykonać hard delete, najpierw zapisz zdarzenie audytu i dołącz snapshot rekordu, by móc udowodnić, co zostało usunięte.
Traktuj przywrócenie jako osobną akcję. „Restore” to nie to samo co „Update”, a rozdzielenie ich ułatwia przeglądy i kontrole zgodności.
Dla masowych edycji unikaj jednej niejasnej pozycji typu "zaktualizowano 500 rekordów." Potrzebujesz wystarczającej szczegółowości, by później odpowiedzieć „które rekordy się zmieniły?”. Praktyczny wzorzec to wpis rodzic + zdarzenia potomne per rekord:
Przykład: lider wsparcia masowo zamyka 120 zgłoszeń. Wpis rodzic rejestruje filtr "status=open, older than 30 days", a każde zgłoszenie dostaje wpis potomny pokazujący status open -> closed.
Logi audytu szybko stają się śmieciem, gdy przechowują zbyt dużo (każdy pełny rekord na zawsze) lub zbyt mało (tylko "edytowano użytkownika"). Celem jest wpis, który jest obronny pod kątem zgodności i czytelny dla administratora.
Praktyczny domyślny wybór to zapisywanie diffu na poziomie pola dla większości aktualizacji. Zapisuj tylko pola, które się zmieniły, z wartościami "before" i "after". To zmniejsza zużycie miejsca i sprawia, że feed jest łatwy do przeglądania: "Status: Pending -> Approved" jest czytelniejsze niż ogromny blob.
Zachowaj pełne snapshoty dla momentów, które mają znaczenie: tworzenia, usunięcia i ważne przejścia workflow. Snapshot jest cięższy, ale chroni, gdy ktoś zapyta „Jak dokładnie wyglądał profil klienta zanim został usunięty?”.
Dane wrażliwe wymagają reguł maskowania, inaczej tabela audytu stanie się drugą bazą tajemnic. Typowe zasady:
Zmiany schematu też mogą złamać historię audytu. Jeśli pole później zostanie przemianowane lub usunięte, zapisz bezpieczny fallback jak "unknown field" oraz oryginalny klucz pola. Dla usuniętych pól zachowaj ostatnią znaną wartość, ale oznacz ją jako "field removed from schema", by feed pozostał uczciwy.
Na koniec, twórz wpisy przyjazne dla ludzi. Zapisuj etykiety do wyświetlania ("Assigned to") obok surowych kluczy ("assignee_id") i formatuj wartości (daty, waluta, nazwy statusów).
Rzetelny ślad audytu to nie logowanie więcej. To stosowanie jednego powtarzalnego wzorca wszędzie, by nie skończyć z lukami typu "import masowy nie był logowany" lub "edycje z mobilnego wyglądają anonimowo."
Zacznij w modelu danych i stwórz mały zestaw tabel, które potrafią opisać dowolną zmianę.
Trzymaj to proste: jedna tabela na zdarzenie, jedna na zmienione pola i mały kontekst aktora.
Stwórz wielokrotnego użytku podproces, który:
Zasada jest ścisła: każda ścieżka zapisu musi wywoływać ten sam podproces. To obejmuje przyciski w UI, endpointy API, zadania zaplanowane i integracje.
Nie ufaj przeglądarce co do "kto" i "kiedy". Odczytaj aktora z sesji uwierzytelnienia i generuj znaczniki czasu na serwerze. Jeśli działa automatyzacja, ustaw actor_type na system i zapisz nazwę joba jako etykietę aktora.
Wybierz pojedynczy rekord (np. zgłoszenie klienta): utwórz je, edytuj dwa pola (status i assignee), usuń je, a potem przywróć. Feed audytu powinien pokazać pięć zdarzeń, z dwoma elementami update pod zdarzeniem edycji oraz aktorem i znacznikiem czasu wypełnionymi w ten sam sposób za każdym razem.
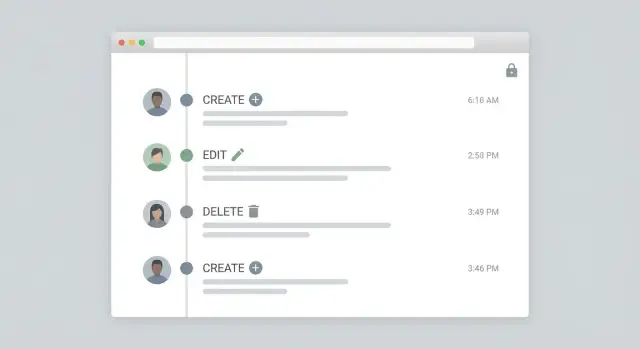
Log audytu jest użyteczny tylko wtedy, gdy ktoś potrafi go szybko przeczytać podczas przeglądu lub incydentu. Celem feedu administracyjnego jest proste: odpowiedzieć "co się stało?" na pierwszy rzut oka, a potem umożliwić głębsze sprawdzenie bez topienia się w surowym JSONie.
Zacznij od układu osi czasu: najnowsze u góry, jeden wiersz na zdarzenie i jasne czasowniki jak Created, Updated, Deleted, Restored. Każdy wiersz powinien pokazywać aktora (osoba lub system), cel (typ rekordu plus czytelna nazwa) i czas.
Praktyczny format wiersza:
Trzymaj "co się zmieniło" zwarte. Pokaż 1–3 pola inline, potem oferuj panel drill-down (drawer/modal) z pełnymi szczegółami: before/after, źródło żądania (web, mobile, API) oraz pole reason/comment.
Filtrowanie to to, co sprawia, że feed jest użyteczny po pierwszym tygodniu. Skup się na filtrach odpowiadających realnym pytaniom:
Linkowanie ma znaczenie, ale tylko gdy pozwalają uprawnienia. Jeśli widz ma dostęp do danego rekordu, pokaż akcję "View record". Jeśli nie, pokaż bezpieczny placeholder (np. "Restricted record") przy zachowaniu widoczności wpisu audytu.
Oznacz akcje systemowe wyraźnie. Etykietuj zadania zaplanowane i integracje odmiennie, aby administratorzy wiedzieli, czy „Dana to usunęła”, czy „Nightly billing sync to zaktualizował”.
Logi audytu są dowodem, ale też zawierają wrażliwe informacje. Traktuj audyt jako odrębny produkt w aplikacji: jasne reguły dostępu, ograniczenia i ostrożne obchodzenie się z danymi osobowymi.
Zdecyduj, kto co może zobaczyć. Typowy podział to: administrator systemu widzi wszystko; menedżerowie działów widzą zdarzenia dla swojego zespołu; właściciele rekordów widzą zdarzenia powiązane z rekordami, do których już mają dostęp (i nic poza tym). Jeśli udostępniasz feed, stosuj te same reguły do każdego wiersza, nie tylko do ekranu.
Widoczność na poziomie wiersza ma największe znaczenie w narzędziach multi-tenant lub międzydziałowych. Tabela audytu powinna przenosić te same klucze zakresu co dane biznesowe (tenant_id, department_id, project_id), żeby filtrowanie było spójne. Przykład: menedżer wsparcia powinien widzieć zmiany zgłoszeń w swoim koszyku, ale nie korekty wynagrodzeń w HR, nawet jeśli obie czynności odbywają się w tej samej aplikacji.
Prosta polityka, która działa w praktyce:
Prywatność to druga część. Przechowuj wystarczająco, by udowodnić, co się stało, ale unikaj zamieniania logu w kopię bazy danych. Dla pól wrażliwych (SSN, notatki medyczne, dane płatnicze) preferuj redakcję: zarejestruj, że pole się zmieniło, bez przechowywania starej/nowej wartości. Możesz zalogować „email changed” przy maskowaniu rzeczywistej wartości lub zapisać hashowany odcisk do weryfikacji.
Oddziel zdarzenia bezpieczeństwa od zmian rekordów biznesowych. Próby logowania, reset MFA, tworzenie kluczy API i zmiany ról powinny trafić do security_audit ze ściślejszymi uprawnieniami i dłuższym okresem przechowywania. Zmiany biznesowe (aktualizacje statusów, zatwierdzenia, zmiany workflow) mogą żyć w ogólnym strumieniu audytu.
Gdy ktoś żąda usunięcia danych osobowych, nie kasuj całego śladu audytu. Zamiast tego:
Przydatny log audytu to nie tylko "zapisujemy zdarzenia." Dla zgodności musisz udowodnić trzy rzeczy: dane przechowywano wystarczająco długo, nie zostały zmienione po fakcie i potrafisz je szybko odzyskać, gdy ktoś poprosi.
Zacznij od prostej reguły dopasowanej do twojego ryzyka. Wiele zespołów wybiera 90 dni do codziennego debugowania, 1–3 lata dla wewnętrznej zgodności i dłużej tylko dla rekordów regulowanych. Zapisz, co resetuje zegar (zwykle: czas zdarzenia) i co jest wyłączone (np. logi zawierające pola, których nie powinieneś przechowywać).
Jeśli masz wiele środowisk, ustaw różne okresy retencji. Logi produkcyjne zwykle potrzebują najdłuższej retencji; logi testowe często nie muszą być przechowywane wcale.
Traktuj logi audytu jako append-only. Nie aktualizuj wierszy i nie pozwalaj zwykłym administratorom na ich usuwanie. Jeśli usunięcie jest naprawdę wymagane (wniosek prawny, czyszczenie danych), zaloguj tę akcję jako osobne zdarzenie.
Praktyczny wzorzec:
Audytorzy często proszą o CSV lub JSON. Zaplanuj eksport, który filtruje po zakresie dat i typie obiektu (np. Invoice, User, Ticket), żeby nie wykonywać ad-hoc zapytań w najgorszym możliwym momencie.
Dla wydajności indeksuj pola istotne dla wyszukiwania:
Uważaj na ciche awarie. Jeśli zapis audytu przestaje działać, tracisz dowody i często tego nie zauważysz. Dodaj prosty alert: jeśli aplikacja przetwarza zapisy, ale liczba zdarzeń audytu spada do zera przez pewien okres, powiadom właścicieli i zarejestruj błąd głośno.
Najszybszy sposób na marnowanie czasu to zbieranie wielu wierszy, które nie odpowiadają na realne pytania: kto zmienił co, kiedy i skąd.
Jedną pułapką jest poleganie wyłącznie na triggerach bazy danych. Triggery mogą zarejestrować, że wiersz się zmienił, ale często pomijają kontekst biznesowy: z którego ekranu użytkownik działał, jakie żądanie to spowodowało, jaką miał rolę i czy to była normalna edycja czy reguła automatyczna.
Błędy, które najczęściej łamią zgodność i użyteczność dnia codziennego:
Ustandaryzuj słownictwo zdarzeń wcześnie (np. user.created, user.updated, invoice.voided, access.granted) i wymuszaj, by każda ścieżka zapisu emitowała jedno zdarzenie. Traktuj dane audytu jako write-once: jeśli ktoś zrobił złą zmianę, zaloguj nową korekcyjną akcję zamiast przepisywać historię.
Zanim uznasz zadanie za zakończone, przeprowadź kilka szybkich testów. Dobry log audytu jest nudny w najlepszym znaczeniu: kompletny, spójny i czytelny, gdy coś pójdzie nie tak.
Użyj tej listy w środowisku testowym z realistycznymi danymi:
Jeśli budujesz narzędzia wewnętrzne z AppMaster (appmaster.io), jednym praktycznym sposobem na utrzymanie wysokiego pokrycia jest kierowanie akcji UI, endpointów API, importów i automatyzacji przez ten sam wzorzec Business Process, który zapisuje zarówno zmianę danych, jak i zdarzenie audytu. W ten sposób twój ślad audytu CRUD pozostaje spójny nawet gdy ekrany i workflowy się zmieniają.
Zacznij od małego: jedna ważna ścieżka (zgłoszenia, zatwierdzenia, zmiany billingowe), dopracuj czytelność feedu, a potem rozszerzaj, aż każda ścieżka zapisu wyemituje przewidywalne, przeszukiwalne zdarzenie audytu.
Dodawaj logi audytu, gdy narzędzie może już zmieniać rzeczywiste dane. Pierwszy spór lub żądanie audytowe zwykle pojawia się wcześniej, niż się spodziewasz, a odtwarzanie historii po fakcie to głównie zgadywanka.
Przydatny log audytu pozwala szybko odpowiedzieć: kto wykonał akcję, jaki rekord został zmieniony, co się zmieniło, kiedy to nastąpiło i skąd to pochodziło (UI, API, import lub zadanie). Jeśli nie możesz szybko odpowiedzieć na choćby jedno z tych pytań, log nie będzie budził zaufania.
Logi debugowania są dla programistów — zwykle są głośne i niespójne. Logi audytu służą rozliczalności: mają stałe pola, jasne sformułowania i format czytelny dla osób niebędących inżynierami.
Braki w pokryciu pojawiają się, gdy zmiany dzieją się poza normalnym ekranem edycji. Masowe edycje, importy, zadania zaplanowane, skróty administratora i usuwania to najczęstsze miejsca, gdzie zapominamy emitować zdarzenia audytu.
Zapisuj typ aktora i identyfikator aktora, nie tylko user_id. Dzięki temu wyraźnie odróżnisz pracownika od zadania systemowego, konta serwisowego czy zewnętrznej integracji i unikniesz niejasności typu „ktoś to zrobił”.
Przechowuj znaczniki czasu w UTC w bazie, a w UI pokazuj je w lokalnej strefie czasowej użytkownika. To zapobiega sporom o różne czasy i ułatwia spójne eksporty.
Wybierz append-only event log, gdy chcesz mieć jedno miejsce do wyszukiwania i prosty kanał aktywności. Wybierz versioned history, gdy często potrzebujesz widoków punktu w czasie dla pojedynczego rekordu; w wielu aplikacjach event log z diffami pól zaspokaja większość potrzeb przy mniejszym zużyciu miejsca.
Preferuj miękkie usuwanie i jawnie zaloguj akcję usunięcia. Jeśli musisz wykonać hard delete, najpierw zapisz zdarzenie audytu i dołącz snapshot lub kluczowe pola, by można było udowodnić, co zostało usunięte.
Domyślnie zapisuj diffy pól przy aktualizacjach i snapshoty przy tworzeniu oraz usuwaniu. Dla pól wrażliwych zapisz jedynie fakt zmiany bez przechowywania sekretu; redaguj lub maskuj dane osobowe, żeby log nie stał się drugą bazą danych z poufnymi informacjami.
Stwórz jedną wspólną ścieżkę „write + audit” i zmuszaj wszystkie zapisy do jej używania — UI, API, importy i background joby. W AppMaster zespoły często implementują to jako wielokrotnego użytku Business Process, który zmienia dane i zapisuje zdarzenie audytu w tym samym przepływie, by uniknąć luk.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


