Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Długotrwałe przepływy pracy mogą zawodzić w skomplikowany sposób. Poznaj czytelne wzorce stanów, liczniki ponowień, obsługę dead-letterów i panele operatorskie, którym można zaufać.
Długotrwałe przepływy pracy zawodzą inaczej niż szybkie żądania. Krótkie wywołanie API albo się powiedzie, albo od razu zwróci błąd. Przepływ trwający godziny lub dni może wykonać 9 z 10 kroków i zostawić bałagan: częściowo utworzone rekordy, mylący status i brak jasnej następnej akcji.
Dlatego tak często słyszysz „działało wczoraj”. Przepływ się nie zmienił, zmieniło się jego otoczenie. Długotrwałe przepływy polegają na tym, że inne usługi pozostaną zdrowe, poświadczenia będą ważne, a dane będą miały oczekiwany kształt.
Najczęstsze tryby awarii wyglądają tak: timeouty i wolne zależności (partner API jest dostępne, ale dziś odpowiada 40 s), częściowe aktualizacje (rekord A utworzony, rekord B nie, i nie można bezpiecznie wykonać procesu ponownie), przerwy w działaniu zależności (dostawcy email/SMS, bramki płatności, okna konserwacyjne), zagubione callbacki i nieodpalone harmonogramy (webhook nigdy nie nadeszedł, job czasowy nie zadziałał) oraz kroki ludzkie, które utknęły (zatwierdzenie czeka dniami, potem wznowione z nieaktualnymi założeniami).
Trudność to stan. „Szybkie żądanie” może trzymać stan w pamięci aż do zakończenia. Przepływ nie może — musi utrzymywać stan między krokami i być gotowy do wznowienia po restarcie, deployu czy awarii. Musi też radzić sobie z tym, że ten sam krok może zostać wywołany dwukrotnie (ponowienia, duplikatowe webhooki, odtwarzanie przez operatora).
W praktyce „niezawodne” znaczy mniej „nigdy się nie psuje”, a bardziej „przewidywalne, zrozumiałe, możliwe do odzyskania i z wyraźnym właścicielem”.
Przewidywalne oznacza, że przepływ reaguje tak samo przy każdej awarii zależności. Zrozumiałe oznacza, że operator może w minutę odpowiedzieć: „Gdzie to utknęło i dlaczego?”. Możliwe do odzyskania oznacza, że można bezpiecznie ponowić lub kontynuować bez szkody. Jasne posiadanie oznacza, że każdy zablokowany element ma oczywistą następną akcję: czekaj, ponów, napraw dane lub przekaż do osoby.
Prosty przykład: automatyzacja onboardingu tworzy rekord klienta, nadaje dostęp i wysyła wiadomość powitalną. Jeśli provisioning się powiedzie, ale wysyłka nie zadziała z powodu awarii dostawcy email, niezawodny przepływ zapisuje „Provisioned, message pending” i planuje ponowienie. Nie uruchamia provisioning ponownie w ciemno.
Narzędzia mogą to ułatwić, trzymając logikę przepływu i dane trwałe blisko siebie. Na przykład AppMaster pozwala modelować stan przepływu w danych (Data Designer) i aktualizować go z poziomu Business Processes. Jednak niezawodność bierze się ze wzorca, nie z narzędzia: traktuj długotrwałą automatyzację jako serię trwałych stanów, które przetrwają czas, awarie i interwencje ludzkie.
Długotrwałe przepływy zwykle zawodzą powtarzalnie: zewnętrzne API zwalnia, człowiek nie zatwierdził, albo job stoi w kolejce. Czytelne stany czynią te sytuacje oczywistymi, więc ludzie nie będą mylić „zajmuje czas” z „zepsute”.
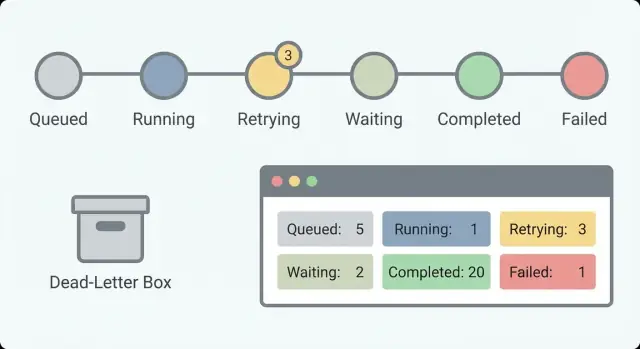
Zacznij od małego zestawu stanów, które odpowiadają na jedno pytanie: co dzieje się teraz? Jeśli masz 30 stanów, nikt ich nie zapamięta. Przy 5–8 stanieczna osoba na dyżurze może przeskanować listę i zrozumieć sytuację.
Praktyczny zestaw stanów, który działa w wielu przepływach:
Queued (utworzony, ale nie rozpoczęty)Running (aktywnie wykonuje pracę)Waiting (wstrzymany na timerze, callbacku lub wejściu od człowieka)Succeeded (zakończony)Failed (zatrzymany z błędem)Oddzielenie Waiting od Running ma znaczenie. „Czekanie na odpowiedź klienta” jest zdrowe. „Działa od 6 godzin” może oznaczać zawieszenie. Bez tego podziału będziesz gonić fałszywe alarmy i przegapisz prawdziwe.
Nazwa stanu to za mało. Dodaj kilka pól, które zamienią status w coś działania:
Przykład: przepływ onboardingu może pokazywać „Waiting” z powodem „Pending manager approval” i ostatnią zmianą „2 dni temu”. To informuje, że nie jest zawieszony, ale może wymagać przypomnienia.
Traktuj nazwy stanów jak API. Jeśli zmieniasz je co miesiąc, dashboardy, alerty i playbooki szybko będą wprowadzać w błąd. Jeśli potrzebujesz nowego znaczenia, rozważ wprowadzenie nowego stanu i pozostawienie starego dla istniejących rekordów.
W AppMaster możesz modelować te stany w Data Designer i aktualizować je z Business Process. To utrzymuje status widocznym i spójnym w całej aplikacji zamiast chować go w logach.
Ponawiania pomagają, dopóki nie ukrywają prawdziwego problemu. Celem nie jest „nigdy się nie psuć”, lecz „psuć się w sposób zrozumiały i możliwy do naprawienia”. Zaczyna się od jasnej reguły, które błędy są retryowalne, a które nie.
Reguła, którą większość zespołów może przyjąć: ponawiaj błędy prawdopodobnie tymczasowe (timeouty sieciowe, limity szybkości, krótkie awarie usług zewnętrznych). Nie ponawiaj błędów ewidentnie trwałych (błędne dane wejściowe, brak uprawnień, „konto zamknięte”, „karta odrzucona”). Jeśli nie wiesz, do której kategorii błąd należy, traktuj go jako nieponawialny, dopóki nie nauczysz się więcej.
Prowadź liczniki ponowień per krok (lub per wywołanie zewnętrzne), a nie jeden licznik dla całego przepływu. Przepływ może mieć dziesięć kroków, a tylko jeden może być zawodny. Liczniki na poziomie kroku zapobiegają sytuacji, w której krok późniejszy „kradnie” próby kroku wcześniejszego.
Na przykład wywołanie „Upload document” może być powtarzane kilka razy, podczas gdy „Send welcome email” nie powinno próbować w nieskończoność tylko dlatego, że wcześniej zużyto próby na upload.
Wybierz wzór backoff dopasowany do ryzyka. Stałe opóźnienia mogą być wystarczające dla prostych, niskokosztowych ponowień. Backoff wykładniczy pomaga, gdy możesz trafić na limity szybkości. Ustaw limit, żeby opóźnienia nie rosły bez końca, i dodaj odrobinę jitteru, aby uniknąć fal ponowień.
Potem zdecyduj, kiedy przestać. Dobre warunki zatrzymania są eksplicitne: maksymalna liczba prób, maksymalny łączny czas lub „zrezygnuj dla określonych kodów błędów”. Bramki płatności zwracające „invalid card” powinny przestać od razu, nawet jeśli zwykle pozwalasz na pięć prób.
Operatorzy muszą też wiedzieć, co się stanie dalej. Zapisz czas następnego ponowienia i powód (np. „Retry 3/5 at 14:32 due to timeout”). W AppMaster możesz trzymać to na rekordzie przepływu, aby dashboard mógł pokazać „waiting until” bez zgadywania.
Dobra polityka ponowień zostawia ślad: co zawiodło, ile było prób, kiedy spróbuje ponownie i kiedy przekaże element do obsługi dead-letter.
W przepływach trwających godziny lub dni ponawiania są normalne. Ryzyko polega na powtórzeniu kroku, który już się wykonał. Idempotencja to reguła, która to zabezpiecza: krok jest idempotentny, jeśli jego uruchomienie dwa razy daje ten sam skutek co raz.
Klasyczna awaria: pobierasz opłatę, potem przepływ padł zanim zapisano „payment succeeded”. Przy ponownym uruchomieniu pobierasz ponownie — podwójne obciążenie. To problem podwójnego zapisu: świat zewnętrzny się zmienił, a stan przepływu tego nie odzwierciedla.
Najbezpieczniejszy wzorzec to stworzenie stabilnego klucza idempotencji dla każdego krokowego działania, wysłanie go z wywołaniem zewnętrznym i zapisanie wyniku kroku zaraz po jego otrzymaniu. Wielu dostawców płatności i odbiorców webhooków wspiera klucze idempotencji (np. obciążenie zamówienia po OrderID). Jeśli krok się powtórzy, dostawca zwróci pierwotny wynik zamiast wykonać akcję ponownie.
W silniku przepływów zakładaj, że każdy krok może być powtórzony. W AppMaster często oznacza to zapisanie wyników kroków w bazie danych i sprawdzenie ich w Business Process przed ponownym wywołaniem integracji. Jeśli „Send welcome email” ma już zapisane MessageID, ponowienie powinno użyć tego rekordu i przejść dalej.
Praktyczne podejście odporne na duplikaty:
Duplikaty nadal się zdarzają, szczególnie przy inbound webhookach lub gdy użytkownik klika przycisk dwa razy. Zdecyduj politykę per typ zdarzenia: ignoruj dokładne duplikaty (ten sam klucz idempotencji), łącz kompatybilne aktualizacje (np. last-write-wins dla pola profilu) albo oznacz do przeglądu, gdy w grę wchodzą pieniądze lub zgodność.
Dead-letter to element przepływu, który nie powiódł się i został przeniesiony poza normalną ścieżkę, żeby nie blokować reszty pracy. Trzymasz go celowo. Celem jest ułatwienie zrozumienia, czy problem da się naprawić i bezpieczne ponowne przetworzenie.
Największy błąd to zapisywanie tylko komunikatu o błędzie. Kiedy ktoś spojrzy na dead-letter później, potrzebuje wystarczającego kontekstu, aby odtworzyć problem bez zgadywania.
Przydatny wpis dead-letterowy zawiera:
Klasyfikacja ułatwia działanie. Krótka kategoria pomaga operatorom wybrać właściwy krok. Typowe grupy: błąd trwały (reguła biznesowa, niepoprawny stan), problem z danymi (brak pola, zły format), zależność nieosiągalna (timeout, rate limit, awaria) i auth/permission (wygasły token, odrzucone poświadczenia).
Ponowne przetwarzanie powinno być kontrolowane. Chodzi o uniknięcie powtarzalnej szkody, jak podwójne obciążenie karty czy spamowanie emaili. Zdefiniuj reguły: kto może ponawiać, kiedy, co można zmienić (edytować konkretne pola, dołączyć brakujący dokument, odświeżyć token), a co musi pozostać stałe (request ID i downstream idempotency keys).
Umożliw wyszukiwanie dead-letterów po stabilnych identyfikatorach. Gdy operator może wpisać „order 18422” i zobaczyć dokładny krok, wejścia i historię prób, naprawy idą szybko i spójnie.
Jeśli budujesz to w AppMaster, traktuj dead-letter jako model bazy danych i przechowuj stan, próby i identyfikatory jako pola. Dzięki temu wewnętrzny dashboard może je filtrować, wyszukiwać i wyzwalać kontrolowane akcje ponownego przetworzenia.
Długotrwałe przepływy zawodzą powoli i w sposób mylący: krok czeka na odpowiedź email, bramka płatności timeouuje, webhook przychodzi dwukrotnie. Jeśli nie widzisz, co przepływ robi teraz, zaczynasz zgadywać. Dobra widoczność zamienia „to jest zepsute” w jasną odpowiedź: który przepływ, który krok, jaki stan i co zrobić dalej.
Zacznij od tego, aby każdy krok emitował ten sam mały zestaw pól, żeby operator mógł szybko przeskanować:
Te pola wspierają podstawowe wskaźniki pokazujące zdrowie systemu. W długotrwałych przepływach bardziej liczą się liczby niż pojedyncze błędy, ponieważ szukasz trendów: gromadzenie pracy, skoki ponowień lub czekania, które nigdy się nie kończą.
Śledź uruchomienia, zakończenia, błędy, ponawianie i oczekiwanie w czasie. Mała liczba oczekujących może być normalna (zatwierdzenia przez ludzi). Rosnąca liczba oczekujących zwykle oznacza blokadę. Rosnący wskaźnik ponowień często wskazuje na problem z dostawcą lub błąd, który wciąż trafia w ten sam warunek.
Alerty powinny odpowiadać temu, co widzi operator. Zamiast „wystąpił błąd”, alertuj na symptomy: rosnące zaległości (started minus completed rośnie), zbyt wiele workflowów utkwiło w oczekiwaniu dłużej niż oczekiwano, wysoki wskaźnik ponowień dla konkretnego kroku lub skok błędów po wdrożeniu/zmianie konfiguracji.
Trzymaj ślad zdarzeń dla każdego przepływu, żeby pytanie „co się stało?” dało się odpowiedzieć w jednym widoku. Przydatny ślad zawiera znaczniki czasu, przejścia stanów, podsumowania wejść i wyjść (nie pełne wrażliwe payloady) oraz powód ponowień lub błędu. Przykład: „Charge card: retry 3/5, timeout from provider, next attempt in 10m.”
ID korelacyjne to spoiwo. Jeśli klient mówi „na mojej karcie naliczono dwa razy”, musisz powiązać zdarzenia przepływu z ID obciążenia dostawcy i naszym wewnętrznym ID zamówienia. W AppMaster możesz to ustandaryzować w Business Process, generując i przekazując correlation IDs przez wywołania API i kroki messagingu, tak by dashboard i logi się zgadzały.
Gdy przepływ działa godzinami lub dniami, błędy są normalne. To, co zmienia normalne błędy w awarię, to dashboard, który pokazuje tylko „Failed” i nic więcej. Celem jest pomóc operatorowi odpowiedzieć szybko na trzy pytania: co się dzieje, dlaczego się tak dzieje i co można bezpiecznie zrobić dalej.
Zacznij od listy przepływów, która ułatwia znalezienie kilku istotnych elementów. Filtry zmniejszają panikę i hałas, bo każdy może szybko zawęzić widok.
Przydatne filtry to stan, wiek (czas rozpoczęcia i czas w bieżącym stanie), właściciel (zespół/klient/odpowiedzialny operator), typ (nazwa/wersja przepływu) i priorytet jeśli masz kroki widoczne dla klientów.
Pokaż „dlaczego” obok statusu zamiast chować to w logach. Pillka stanu pomaga, jeśli towarzyszy jej ostatni komunikat błędu, krótka kategoria błędu i planowana następna akcja systemu. Dwa pola robią większość roboty: ostatni błąd i czas następnego ponowienia. Jeśli next retry jest pusty, wyraźnie pokaż, czy przepływ czeka na człowieka, jest wstrzymany czy trwałe nie powiódł się.
Akcje operatora powinny być domyślnie bezpieczne. Kieruj ludzi do niskiego ryzyka najpierw, a ryzykowne akcje wyróżniaj:
To „Force continue” jest miejscem, gdzie powstaje najwięcej szkód. Jeśli je oferujesz, wypisz ryzyko prostym językiem: „To pomija weryfikację płatności i może stworzyć niezapłacone zamówienie.” Pokaż też, jakie dane zostaną zapisane, jeśli proces pójdzie dalej.
Audytuj wszystko, co robią operatorzy. Zapisuj kto, kiedy, stan przed/po i notkę z powodem. Jeśli budujesz wewnętrzne narzędzia w AppMaster, przechowuj ten ślad audytu jako tabelę i pokazuj go na stronie szczegółów przepływu, aby przekazy międzyosobowe były czytelne.
Ten wzorzec utrzymuje przepływy przewidywalne: każdy element zawsze ma jasny stan, każdy błąd ma swoje miejsce, a operatorzy mogą działać bez zgadywania.
Krok 1: Zdefiniuj stany i dozwolone przejścia. Spisz mały zestaw stanów zrozumiały dla człowieka (np. Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter). Następnie określ, które przejścia są legalne, aby praca nie dryfowała w limbo.
Krok 2: Podziel pracę na małe kroki z jasnymi wejściami i wyjściami. Każdy krok powinien przyjmować jedno dobrze zdefiniowane wejście i zwracać jedno wyjście (lub czytelny błąd). Jeśli potrzebujesz decyzji ludzkiej lub wywołania zewnętrznego, zrób z tego osobny krok, aby mógł się wstrzymać i wznowić czysto.
Krok 3: Dodaj politykę ponowień per krok. Wybierz limit prób, opóźnienie między nimi i powody zatrzymania, które nigdy nie będą retryowane (błędne dane, brak uprawnień, brak wymaganych pól). Przechowuj licznik ponowień per krok, aby operatorzy widzieli dokładnie, co jest zablokowane.
Krok 4: Zapewnij trwałość postępu po każdym kroku. Po zakończeniu kroku zapisz nowy stan i kluczowe wyniki. Po restarcie proces powinien kontynuować od ostatniego ukończonego kroku, a nie zaczynać od początku.
Krok 5: Kieruj do rekordu dead-letter i wspieraj ponowne przetworzenie. Gdy ponowienia się wyczerpią, przenieś element do stanu dead-letter i zachowaj pełen kontekst: wejścia, ostatni błąd, nazwa kroku, licznik prób i znaczniki czasu. Ponowne przetworzenie powinno być rozważne: napraw dane lub konfigurację przed ponownym włączeniem z określonego kroku.
Krok 6: Zdefiniuj pola dashboardu i akcje operatorskie. Dobry dashboard odpowiada na pytanie „co się zepsuło, gdzie i co mogę zrobić dalej?” W AppMaster możesz to zbudować jako prostą aplikację administracyjną opartą na tabelach przepływów.
Kluczowe pola i akcje do uwzględnienia:
Onboarding pracownika to dobry stres test. Miesza zatwierdzenia, systemy zewnętrzne i ludzi, którzy są offline. Prosty przebieg: HR wypełnia formularz nowej osoby, manager zatwierdza, IT tworzy konta, a nowa osoba dostaje wiadomość powitalną.
Uczyń stany czytelnymi. Gdy ktoś otworzy rekord, powinien od razu zobaczyć różnicę między „Waiting for approval” a „Retrying account setup”. Jedna linia jasności może zaoszczędzić godzinę zgadywania.
Czytelny zestaw stanów do pokazania w UI:
Ponawiania dotyczą kroków zależnych od sieci lub API zewnętrznych. Provisioning kont (email, SSO, Slack), wysyłka email/SMS i wywołania wewnętrznych API to dobre kandydaty do ponowień. Trzymaj licznik ponowień widoczny i ogranicz go (np. do pięciu prób z narastającymi opóźnieniami, potem stop).
Obsługa dead-letter to problemy, które same się nie naprawią: brak managera na formularzu, nieprawidłowy adres email lub żądanie dostępu sprzeczne z polityką. Gdy przenosisz uruchomienie do dead-letter, zapisz kontekst: które pole nie przeszło walidacji, ostatnia odpowiedź API i kto może zatwierdzić override.
Operatorzy powinni mieć niewielki zestaw prostych akcji: naprawić dane (dodać managera, poprawić email), uruchomić ponownie jeden krok (nie cały przepływ) lub anulować czysto (i cofnąć częściowe zasoby jeśli trzeba).
W AppMaster możesz to zmodelować w Business Process Editorze, trzymać liczniki ponowień w danych i zbudować ekran operatorski w web UI builderze pokazujący stan, ostatni błąd i przycisk do ponowienia kroku.
Większość problemów z niezawodnością jest przewidywalna: krok uruchamia się dwa razy, ponowienia kręcą się o 2 w nocy, albo „utknięty” element nie ma pojęcia, co ostatnio się stało. Lista kontrolna zapobiega zgadywaniu.
Szybkie kontrole, które wykrywają większość problemów wcześnie:
Jeśli możesz poprawić tylko jedną rzecz — popraw widoczność. Wiele „błędów przepływów” to tak naprawdę „nie widzimy, co robi”. Twój dashboard powinien pokazywać, co się stało ostatnio, co stanie się następne i kiedy. Praktyczny widok operatorski zawiera bieżący stan, ostatni komunikat o błędzie, licznik prób, czas następnego ponowienia i jedną jasną akcję (retry now, mark as resolved lub send to manual review). Domyślnie trzymaj akcje bezpieczne: uruchom ponownie pojedynczy krok, nie cały przepływ.
Następne kroki:
Traktuj to jako żywą listę kontrolną. Za każdym razem, gdy dodajesz nowy krok, przeprowadź te kontrole przed wypuszczeniem do produkcji.
Długotrwałe przepływy pracy mogą działać przez wiele godzin i upaść pod koniec, pozostawiając częściowe zmiany. Polegają też na rzeczach, które mogą się zmienić w trakcie działania, jak dostępność usług zewnętrznych, ważność poświadczeń, kształt danych czy czas reakcji ludzi.
Utrzymaj mały, czytelny zestaw stanów, aby operator mógł je zrozumieć od razu. Dobry domyślny zestaw to na przykład: queued, running, waiting, succeeded i failed — z wyraźnym rozdzieleniem „waiting” od „running”, aby odróżnić zdrowe pauzy od zawieszeń.
Przechowuj dane, które czynią status użytecznym: bieżący stan, czas ostatniej zmiany, poprzedni stan oraz krótki, czytelny powód oczekiwania lub błędu. Przy ponowieniach dodaj licznik prób i planowany czas następnego ponowienia, żeby nikt nie musiał się domyślać, co nastąpi.
Pozwala to uniknąć fałszywych alarmów i przeoczonych incydentów. „Oczekiwanie na zatwierdzenie” może być normalne, a „działa od sześciu godzin” może oznaczać zawieszenie — traktowanie ich jako różnych stanów poprawia alertowanie i decyzje operatorów.
Ponawiaj błędy prawdopodobnie przejściowe, takie jak timeouty, limity szybkości czy krótkie przerwy w działaniu usług. Nie ponawiaj błędów ewidentnie trwałych: błędnych danych wejściowych, braków uprawnień czy odrzuconych kart płatniczych — powtarzanie takich prób tylko szkodzi.
Liczniki na poziomie kroku zapobiegają sytuacji, w której jedna zawodna integracja wyczerpuje wszystkie próby dla całego przepływu. Ułatwia to też diagnozę: widać dokładnie, który krok zawodzi i ile razy był już próbowany.
Wybierz prosty backoff dopasowany do ryzyka i zawsze ustaw limit, żeby oczekiwania nie rosły w nieskończoność. Zdecyduj też jasno, kiedy przestać: maksymalna liczba prób, maksymalny całkowity czas lub konkretne kody błędów, po których nie ma sensu próbować dalej. Zapisuj powód i czas następnego ponowienia, aby było jasne, co się stanie dalej.
Zakładaj, że każdy krok może uruchomić się ponownie z powodu retry, duplikatów webhooków czy odtworzeń. Najbezpieczniej jest generować stabilny klucz idempotencji dla kroków zmieniających stan zewnętrzny, zapisywać „step started” przed wywołaniem i natychmiast zapisywać wynik po sukcesie, by powtórzenia mogły ponownie użyć zapisanego rezultatu zamiast ponawiać akcję.
Dead-letter to element przepływu wyjęty z normalnej ścieżki po wyczerpaniu ponowień, żeby nie blokował reszty. Zapisuj wystarczający kontekst, aby ktoś później mógł odtworzyć problem: identyfikatory, dane wejściowe (lub bezpieczny snapshot), gdzie wystąpił błąd, historię prób i pełną odpowiedź zależności — nie tylko krótką wiadomość.
Najlepsze panele szybko pokazują, gdzie jest element, dlaczego tam jest i co się stanie dalej. Używaj spójnych pól: ID przepływu, bieżący krok, stan, czas w stanie, ostatni błąd i ID korelacyjne. Daj operatorom bezpieczne akcje domyślne, jak ponów pojedynczy krok, wstrzymaj/wznów, a ryzykowne akcje wyraźnie oznaczaj.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


