Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Naucz się debugować integracje webhooków: standaryzuj podpisy, bezpiecznie obsługuj ponowienia, włącz odtwarzanie i prowadź łatwo przeszukiwalne dzienniki zdarzeń.
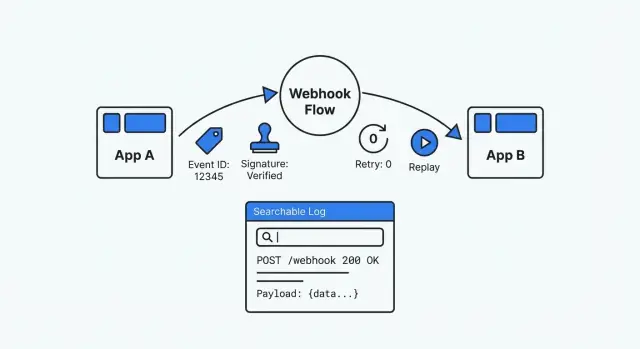
Webhook to po prostu jedna aplikacja wywołująca twoją aplikację gdy coś się zdarzy. Dostawca płatności mówi „payment succeeded”, narzędzie formularzy zgłasza „nowe zgłoszenie”, a CRM informuje „deal updated”. Wygląda prosto, dopóki coś nie przestanie działać i nie zdasz sobie sprawy, że nie ma ekranu do sprawdzenia, historii ani bezpiecznego sposobu na odtworzenie zdarzenia.
Dlatego problemy z webhookami są frustrujące. Żądanie przychodzi (albo nie). Twój system je przetwarza (albo zawodzi). Pierwszy sygnał to często niejasny ticket typu „klienci nie mogą zapłacić” lub „status się nie zaktualizował”. Jeśli dostawca ponawia, możesz dostać duplikaty. Jeśli zmienią pole w payloadzie, parser może się łamać tylko dla niektórych kont.
Typowe symptomy:
Debugowalna konfiguracja webhooków to przeciwieństwo zgadywania. Jest śledzalna (znajdziesz każde dostarczenie i co z nim zrobiłeś), powtarzalna (możesz bezpiecznie odtworzyć przeszłe zdarzenie) i weryfikowalna (możesz udowodnić autentyczność i wynik przetwarzania). Gdy ktoś zapyta „co się stało z tym zdarzeniem?”, powinieneś móc odpowiedzieć z dowodem w ciągu minut.
Jeśli budujesz aplikacje na platformie takiej jak AppMaster, to podejście ma jeszcze większe znaczenie. Logika wizualna zmienia się szybko, ale nadal potrzebujesz jasnej historii zdarzeń i bezpiecznego odtwarzania, żeby systemy zewnętrzne nigdy nie stały się czarną skrzynką.
Podczas debugowania pod presją potrzebujesz tych samych podstaw za każdym razem: zapisu, któremu możesz zaufać, którego możesz szukać i który możesz odtworzyć. Bez tego każdy webhook staje się jednostkową zagadką.
Zdecyduj, co w twoim systemie oznacza pojedyncze „zdarzenie” webhooka. Traktuj je jak paragon: jedno przychodzące żądanie równa się jednemu zapisowi zdarzenia, nawet jeśli przetwarzanie nastąpi później.
Przynajmniej przechowuj:
received_at oddzielnie od znaczników czasu wewnątrz payloadu.Przykład: dostawca płatności wysyła „payment_succeeded”, ale u klienta wciąż widać niezapłacone. Jeśli twój dziennik zdarzeń zawiera surowe żądanie, możesz potwierdzić podpis i zobaczyć dokładną kwotę i walutę. Jeśli zawiera też invoice_id, wsparcie znajdzie zdarzenie po fakturze, zobaczy że stoi w „failed” i przekaże inżynierii jasny powód błędu.
W AppMaster praktycznym podejściem jest tabela „WebhookEvent” w Data Designerze, z Business Process aktualizującym status w miarę ukończenia kolejnych kroków. Narzędzie nie jest sednem — sednem jest spójny zapis.
Jeśli każdy dostawca wysyła inną strukturę payloadu, twoje logi zawsze będą chaotyczne. Stabilna „koperta” zdarzenia przyspiesza debugowanie, bo możesz szukać tych samych pól za każdym razem, nawet gdy dane się zmieniają.
Przydatna koperta zwykle zawiera:
id (unikatowe ID zdarzenia)type (czytelna nazwa zdarzenia, np. invoice.paid)created_at (kiedy zdarzenie miało miejsce, nie kiedy je otrzymałeś)data (biznesowy payload)version (np. v1)Oto prosty przykład, który możesz logować i przechowywać bez zmian:
{
"id": "evt_01H...",
"type": "payment.failed",
"created_at": "2026-01-25T10:12:30Z",
"version": "v1",
"correlation": {"order_id": "A-10492", "customer_id": "C-883"},
"data": {"amount": 4990, "currency": "USD", "reason": "insufficient_funds"}
}
Wybierz jeden styl nazewnictwa (snake_case lub camelCase) i się go trzymaj. Bądź surowy co do typów: nie rób amount czasem stringiem, a czasem liczbą.
Wersjonowanie to twoja siatka bezpieczeństwa. Gdy trzeba zmienić pola, opublikuj v2 zachowując działające v1 przez jakiś czas. To zapobiega incydentom wsparcia i ułatwia debugowanie migracji.
Podpisy chronią endpoint webhooka przed otwartymi drzwiami. Bez weryfikacji każdy, kto pozna URL, może wysłać fałszywe zdarzenia, a atakujący mogą próbować modyfikować prawdziwe żądania.
Najczęstszy wzorzec to podpis HMAC z tajnym kluczem. Nadawca podpisuje surowe body żądania (najlepiej) lub ciąg kanoniczny. Ty przeliczysz HMAC i porównasz. Wielu dostawców dołącza znacznik czasu do tego, co podpisują, żeby zablokować późniejsze odtwarzanie.
Procedura weryfikacji powinna być nudna i spójna:
Zadbaj o testowalność. Umieść weryfikację w jednej małej funkcji i napisz testy z znanymi poprawnymi i błędnymi przykładami. Częstym błędem jest podpisywanie sparsowanego JSON zamiast surowych bajtów.
Planuj rotację sekretów od pierwszego dnia. Wspieraj dwa aktywne sekrety podczas przejścia: najpierw spróbuj najnowszego, potem poprzedniego.
Gdy weryfikacja zawiedzie, loguj wystarczająco dużo, by debugować bez wycieku sekretów: nazwa dostawcy, znacznik czasu (i czy był za stary), wersja podpisu, request/correlation ID oraz krótki hash surowego body (nie samo body).
Ponawiania są normalne. Dostawcy ponawiają po timeoutach, problemach sieciowych lub błędach 5xx. Nawet jeśli twój system wykonał pracę, dostawca mógł nie otrzymać potwierdzenia na czas, więc to samo zdarzenie może pojawić się ponownie.
Zdecyduj z góry, jakie odpowiedzi oznaczają „ponawiaj” a jakie „zatrzymaj”. Wiele zespołów używa reguł typu:
Idempotencja oznacza, że możesz bezpiecznie obsłużyć to samo zdarzenie wielokrotnie bez powtarzania efektów ubocznych (podwójne obciążenie, duplikaty zamówień, wysyłanie dwóch maili). Traktuj webhooki jako dostarczanie co najmniej raz.
Praktyczny wzorzec: zapisz unikatowe ID każdego przychodzącego zdarzenia wraz z wynikiem przetwarzania. Przy ponownym dostarczeniu:
Dla wewnętrznych ponowień użyj wykładniczego backoffu i ogranicz liczbę prób. Po przekroczeniu limitu przenieś zdarzenie do stanu „needs review” z ostatnim błędem. W AppMaster mapuje się to klarownie na niewielką tabelę z ID zdarzeń i statusami oraz Business Process, który harmonogramuje ponowienia i kieruje powtarzające się niepowodzenia.
Ponowienia są automatyczne. Odtwarzanie jest intencjonalne.
Narzędzie do odtwarzania zmienia „myślę, że wysłano” w powtarzalny test z dokładnie tym samym payloadem. Jest też bezpieczne tylko gdy dwie rzeczy są prawdziwe: idempotencja i ścieżka audytu. Idempotencja zapobiega podwójnym obciążeniom, wysyłce i innym duplikatom. Ścieżka audytu pokazuje, co zostało odtworzone, kto to zrobił i co się stało.
Odtwarzanie pojedynczego zdarzenia to typowy przypadek wsparcia: jeden klient, jedno nieudane zdarzenie, ponowne dostarczenie po naprawie. Odtwarzanie zakresu czasu przydaje się podczas incydentów: awaria dostawcy w określonym oknie i potrzeba ponownego wysłania wszystkiego, co nie przeszło.
Utrzymuj prostotę wyboru: filtruj po typie zdarzenia, zakresie czasu i statusie (failed, timed out, lub delivered ale niepotwierdzone), a potem odtwórz pojedyncze zdarzenie lub batch.
Odtwarzanie powinno być potężne, ale nie niebezpieczne. Kilka zabezpieczeń pomaga:
Po odtworzeniu pokaż wynik obok oryginalnego zdarzenia: sukces, nadal błąd (z ostatnim błędem) lub zignorowane (duplikat wykryty przez idempotencję).
Gdy webhook łamie się w trakcie incydentu, potrzebujesz odpowiedzi w minutach. Dobry log opowiada jasną historię: co przyszło, co zrobiłeś i gdzie się zatrzymało.
Przechowuj surowe żądanie dokładnie tak, jak przyszło: znacznik czasu, ścieżka, metoda, nagłówki i surowe body. Ten surowy payload jest twoim źródłem prawdy, gdy dostawcy zmieniają pola lub twój parser źle odczytuje dane. Maskuj wartości wrażliwe przed zapisem (nagłówki Authorization, tokeny i wszelkie dane osobowe lub płatnicze, których nie potrzebujesz).
Samo surowe body to za mało. Przechowuj też sparsowany, przeszukiwalny widok: typ zdarzenia, zewnętrzne ID zdarzenia, identyfikatory klienta/konta, powiązane ID obiektów (invoice_id, order_id) i twój wewnętrzny correlation ID. To umożliwia wsparciu znalezienie „wszystkich zdarzeń dla klienta 8142” bez otwierania każdego payloadu.
Podczas przetwarzania trzymaj krótką oś czasu kroków z jednolitymi sformułowaniami, np.: „validated signature”, „mapped fields”, „checked idempotency”, „updated records”, „queued follow-ups”.
Retencja ma znaczenie. Przechowuj wystarczająco długo, by pokryć rzeczywiste opóźnienia i spory, ale nie chomikuj bez końca. Rozważ najpierw usuwanie lub anonimizację surowych payloadów, zostawiając lżejsze metadane dłużej.
Zbuduj receiver jak mały pipeline z jasnymi checkpointami. Każde żądanie staje się zapisanym zdarzeniem, każde uruchomienie przetwarzania staje się próbą, a każda porażka jest możliwa do wyszukania.
Traktuj endpoint HTTP tylko jako intake. Zrób minimalną pracę upfront, potem przenieś przetwarzanie do workerów, żeby timeouty nie zamieniały się w zagadkowe zachowanie.
W praktyce chcesz mieć dwa główne rekordy: jeden wiersz na zdarzenie webhook, i jeden wiersz na każdą próbę przetwarzania.
Solidny model zdarzeń obejmuje: event_id, provider, received_at, signature_status, payload_hash, payload_json (lub surowy payload), current_status, last_error, next_retry_at. Rekordy prób mogą przechowywać: attempt_number, started_at, finished_at, http_status (jeśli dotyczy), error_code, error_text.
Gdy dane istnieją, dodaj prostą stronę administracyjną, żeby wsparcie mogło szukać po event ID, customer ID lub zakresie czasu i filtrować po statusie. Trzymaj ją nudną i szybką.
Ustaw alerty na wzorce, nie na pojedyncze błędy. Na przykład: „dostawca nie powiódł 10 razy w 5 minut” lub „zdarzenie utkwiło w failed”.
Jeśli kontrolujesz stronę wysyłającą, ustandaryzuj trzy rzeczy: zawsze dołączaj ID zdarzenia, zawsze podpisuj payload w ten sam sposób i opublikuj politykę ponowień jasno. Zapobiega to długim wymianom maili, gdy partner mówi „wysłaliśmy”, a twój system nic nie pokazuje.
Typowy wzorzec to webhook Stripe, który robi dwie rzeczy: tworzy rekord Order, a potem wysyła potwierdzenie mailem/SMS. Brzmi prosto, aż jedno zdarzenie zawiedzie i nikt nie wie, czy klient został obciążony, czy zamówienie istnieje, albo czy potwierdzenie wysłano.
Realna porażka: rotujesz sekret podpisu Stripe. Przez kilka minut twój endpoint nadal weryfikuje ze starym sekretem, więc Stripe dostarcza zdarzenia, ale twój serwer odrzuca je 401/400. Dashboard pokazuje „webhook failed”, podczas gdy logi aplikacji mówią tylko „invalid signature”.
Dobre logi ujawniają przyczynę. Dla nieudanego zdarzenia rekord powinien pokazać stabilne ID zdarzenia i wystarczające szczegóły weryfikacji, by zlokalizować rozbieżność: wersja podpisu, timestamp podpisu, wynik weryfikacji i jasny powód odrzucenia (zły sekret vs dryf czasowy). Podczas rotacji przydatne jest też logowanie, który sekret był próbowany (np. „current” vs „previous”), nie sam sekret.
Gdy sekret zostanie naprawiony i zarówno „current” i „previous” są akceptowane przez krótki okres, nadal musisz obsłużyć zaległości. Narzędzie do odtwarzania zamienia to w szybkie zadanie:
Większość problemów z webhookami wydaje się tajemnicza, bo systemy zapisują tylko końcowy błąd. Traktuj każde dostarczenie jak mały raport incydentu: co przyszło, jakie podjąłeś decyzje i co się stało dalej.
Kilka powtarzających się błędów:
Praktyczne poprawki:
Jeśli używasz AppMaster, te elementy naturalnie pasują do platformy: tabela zdarzeń w Data Designerze, sterowany statusem Business Process do weryfikacji i przetwarzania oraz UI administracyjne do wyszukiwania i odtwarzania.
Dąż do tych podstaw za każdym razem:
Brak choćby jednego z tych elementów może wciąż zamienić integrację w czarną skrzynkę. Jeśli nie zapiszesz surowego payloadu, nie udowodnisz, co wysłał dostawca. Jeśli nieopisane są błędy podpisu, stracisz godziny na dyskusje, czyja to wina.
Jeśli chcesz zbudować to szybko bez ręcznego kodowania każdego elementu, AppMaster (appmaster.io) może pomóc ci złożyć model danych, przepływy przetwarzania i UI administracyjne w jednym miejscu, jednocześnie generując rzeczywisty kod źródłowy dla finalnej aplikacji.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


