Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
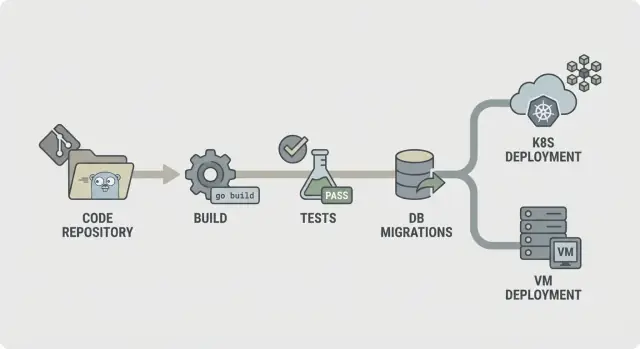
CI/CD dla backendów w Go: praktyczne kroki pipeline'u — build, testy, migracje i bezpieczne wdrożenia na Kubernetes lub VM z przewidywalnymi środowiskami.
Ręczne wdrożenia zawodzą w nudny, powtarzalny sposób. Ktoś buduje na laptopie z inną wersją Go, zapomina zmiennej środowiskowej, pomija migrację albo restartuje niewłaściwą usługę. Wersja „u mnie działa” nie działa w produkcji i dowiadujesz się o tym dopiero po zgłoszeniach od użytkowników.
Kod generowany nie usuwa potrzeby dyscypliny przy wydaniach. Gdy regenerujesz backend po zmianie wymagań, możesz wprowadzić nowe endpointy, nowe kształty danych lub nowe zależności, nawet jeśli nigdy nie dotykałeś kodu ręcznie. Właśnie wtedy chcesz, żeby pipeline działał jak bariera bezpieczeństwa: każda zmiana przechodzi te same kontrole, za każdym razem.
Przewidywalne środowiska oznaczają, że kroki budowania i wdrażania działają w warunkach, które możesz nazwać i powtórzyć. Kilka zasad obejmuje większość przypadków:
Celem CI/CD dla backendów w Go nie jest automatyzacja dla samej automatyzacji. To powtarzalne wydania z mniejszym stresem: regenerujesz, uruchamiasz pipeline i ufasz, że rezultat nadaje się do wdrożenia.
Jeśli używasz generatora takiego jak AppMaster, który produkuje backendy w Go, to ma jeszcze większe znaczenie. Regeneracja jest funkcją, ale jest bezpieczna tylko wtedy, gdy droga od zmiany do produkcji jest spójna, testowana i przewidywalna.
"Przewidywalne" oznacza, że takie samo wejście daje taki sam wynik, niezależnie od miejsca uruchomienia. Dla CI/CD backendów w Go zaczyna się to od zgody, co musi pozostać identyczne między dev, stagingiem i prodem.
Zwykle niepodważalne elementy to wersja Go, obraz bazowy systemu, flagi kompilacji i sposób ładowania konfiguracji. Jeśli coś z tego zmienia się w zależności od środowiska, pojawią się niespodzianki: różne zachowanie TLS, brakujące pakiety systemowe czy błędy występujące tylko w produkcji.
Najczęściej odchylenia środowisk pokazują się w tych miejscach:
Wybór między Kubernetes a VM-ami nie sprowadza się do tego, co jest „najlepsze”, a do tego, co twój zespół potrafi obsługiwać spokojnie.
Kubernetes pasuje, gdy potrzebujesz autoskalowania, rolling updates i ujednoliconego sposobu uruchamiania wielu usług. Pomaga też wymusić spójność, bo pody uruchamiane są z tych samych obrazów. VM-y mogą być właściwym wyborem, gdy masz jedną lub kilka usług, mały zespół i chcesz mniej ruchomych części.
Możesz trzymać ten sam pipeline nawet jeśli runtime'y się różnią, standaryzując artefakt i kontrakt wokół niego. Na przykład: zawsze buduj ten sam obraz kontenera w CI, uruchamiaj te same testy i publikuj ten sam pakiet migracji. Potem zmienia się tylko krok deploy: Kubernetes aplikuje nowy tag obrazu, a VM-y pobierają obraz i restartują usługę.
Praktyczny przykład: zespół regeneruje backend w Go z AppMaster i wdraża do stagingu na Kubernetes, ale w produkcji używa VM-ów. Jeśli obie strony pobierają dokładnie ten sam obraz i ładują konfigurację z tego samego typu magazynu sekretów, „różny runtime” staje się szczegółem wdrożenia, a nie źródłem błędów. Jeśli używasz AppMaster (appmaster.io), ten model dobrze pasuje, bo możesz wdrażać do zarządzanych chmur lub eksportować kod źródłowy i uruchomić ten sam pipeline na własnej infrastrukturze.
Przewidywalny pipeline jest prosty do opisania: sprawdź kod, zbuduj go, udowodnij, że działa, wyślij dokładnie to, co testowałeś, a potem wdrażaj w ten sam sposób za każdym razem. Ta jasność ma większe znaczenie, gdy backend jest regenerowany (np. z AppMaster), bo zmiany mogą dotykać wielu plików naraz i chcesz szybkiej, spójnej informacji zwrotnej.
Typowy flow CI/CD dla backendu w Go wygląda tak:
Ułóż to tak, żeby porażki zatrzymywały się jak najwcześniej. Jeśli lint nie przejdzie, nic więcej nie powinno się uruchamiać. Jeśli build się nie powiedzie, nie marnuj zasobów na startowanie baz dla testów integracyjnych. To obniża koszty i sprawia, że pipeline działa szybciej.
Nie każdy krok musi uruchamiać się przy każdym commicie. Częste rozdzielenie to:
Zdecyduj, co zachowujesz jako artefakty. Zwykle to skompilowany binarny plik lub obraz kontenera (to, co wdrażasz), plus logi migracji i raporty testów. Zachowanie ich ułatwia rollbacky i audyty, bo możesz wskazać dokładnie, co było testowane i promowane.
Etap build powinien odpowiadać na jedno pytanie: czy możemy wyprodukować ten sam binarny plik dziś, jutro i na innym runnerze. Jeśli to nie jest prawdą, każdy kolejny krok (testy, migracje, deploy) staje się trudniejszy do zaufania.
Zacznij od zablokowania środowiska. Użyj stałej wersji Go (np. 1.22.x) i stałego obrazu runnera (dystrybucja Linux i wersje pakietów). Unikaj tagów „latest”. Małe zmiany w libc, Git czy toolchainie Go mogą stworzyć błędy "u mnie działa", które są trudne do debugowania.
Cache modułów pomaga, ale tylko gdy traktujesz go jako przyspieszenie, a nie źródło prawdy. Cache'uj Go build cache i moduły, ale kluczuj go według go.sum (lub czyść na main, gdy zależności się zmieniają), żeby nowe zależności zawsze wymuszały czyste pobranie.
Dodaj szybkie bramki przed kompilacją. Niech będą szybkie, żeby deweloperzy ich nie omijali. Typowy zestaw to gofmt checks, go vet i (jeśli jest szybkie) staticcheck. Również zakończ niepowodzeniem, gdy brakuje lub są przestarzałe pliki generowane, co jest częstym problemem w regenerowanych kodach.
Kompiluj w sposób powtarzalny i wstrzykuj informacje o wersji. Flagi takie jak -trimpath pomagają, a -ldflags pozwala wstrzyknąć SHA commita i czas builda. Wyprodukuj pojedynczy, nazwany artefakt dla każdej usługi. To ułatwia śledzenie, co działa w Kubernetes albo na VM, szczególnie gdy backend jest regenerowany.
Testy pomagają tylko wtedy, gdy uruchamiają się tak samo za każdym razem. Najpierw dąż do szybkiej informacji zwrotnej, potem dodaj głębsze kontrole, które nadal kończą się w przewidywalnym czasie.
Zacznij od testów jednostkowych przy każdym commicie. Ustaw twardy timeout, żeby zawieszony test kończył się głośno zamiast wieszać cały pipeline. Zdecyduj też, co oznacza „wystarczające” pokrycie dla twojego zespołu. Pokrycie nie jest trofeum, ale minimalny próg pomaga zapobiec wolnemu pogorszeniu jakości.
Stabilny etap testów zwykle obejmuje:
go test ./... z timeoutem na pakiet i globalnym timeoutem jobu.Race detector jest wartościowy, ale może spowalniać buildy. Dobrym kompromisem jest uruchamianie go na PR-ach i buildach nocnych albo tylko dla wybranych pakietów, zamiast przy każdym pushu.
Flaky testy powinny powodować niepowodzenie builda. Jeśli musisz kwarantannować test, trzymaj go widocznym: przenieś do oddzielnego jobu, który nadal uruchamia się i raportuje czerwono, i wymagaj właściciela oraz terminu naprawy.
Przechowuj output testów, żeby debugowanie nie wymagało ponownego uruchamiania wszystkiego. Zapisz surowe logi oraz prosty raport (pass/fail, czas trwania i najwolniejsze testy). Ułatwia to wykrywanie regresji, zwłaszcza gdy regenerowane zmiany dotykają wielu plików.
Testy jednostkowe mówią, że kod działa w izolacji. Sprawdzenia integracyjne mówią, że cały serwis zachowuje się poprawnie, gdy się uruchomi, połączy z rzeczywistymi usługami i obsłuży prawdziwe żądania. To siatka bezpieczeństwa, która łapie problemy widoczne dopiero po złożeniu wszystkiego razem.
Używaj efemerycznych zależności, gdy kod ich potrzebuje do startu lub odpowiedzi na kluczowe żądania. Tymczasowy PostgreSQL (i Redis, jeśli używasz) uruchomiony tylko na czas jobu zwykle wystarczy. Trzymaj wersje bliskie produkcji, ale nie próbuj kopiować każdego detalu produkcji.
Dobra faza integracyjna jest celowo mała:
Do sprawdzeń kontraktów API skup się na endpointach, których awaria byłaby najboleśniejsza. Nie potrzebujesz pełnego end-to-end suite’u. Kilka prawd dotyczących request/response wystarczy: wymagane pola powodują 400, brak autoryzacji zwraca 401, a happy-path zwraca 200 z oczekiwanymi kluczami JSON.
Aby utrzymać szybkość integracji, ogranicz zakres i kontroluj czas. Preferuj jedną bazę z małym zbiorem danych. Uruchamiaj tylko kilka żądań. Ustaw twarde timeouty, żeby zawieszony boot kończył się w sekundach, nie w minutach.
Jeśli regenerujesz backend (np. z AppMaster), te sprawdzenia mają większą wagę. Potwierdzają, że zregenerowany serwis nadal startuje i mówi API, jakiego oczekuje frontend.
Zacznij od wyboru, gdzie będą uruchamiane migracje. Uruchamianie ich w CI jest dobre do wczesnego wykrywania błędów, ale CI zwykle nie powinno dotykać produkcji. Większość zespołów uruchamia migracje podczas deployu (jako dedykowany krok) albo jako oddzielny job „migrate”, który musi się zakończyć zanim ruszy nowa wersja.
Praktyczną zasadą jest: buduj i testuj w CI, a migracje uruchamiaj jak najbliżej produkcji, z produkcyjnymi poświadczeniami i podobnymi limitami. W Kubernetes często jest to jednorazowy Job. Na VM-ach może to być skrypt w kroku release.
Kolejność ma większe znaczenie, niż ludzie się spodziewają. Używaj plików z timestampami (lub numeracją sekwencyjną) i wymuszaj „apply w kolejności, dokładnie raz”. Tam, gdzie to możliwe, rób migracje idempotentne, żeby retry nie tworzył duplikatów ani nie powodował awarii w połowie.
Uprość strategię migracji:
Dodaj bramkę bezpieczeństwa przed uruchomieniem czegokolwiek. Może to być blokada w bazie, żeby tylko jedna migracja działała naraz, plus polityka typu „żadne destrukcyjne zmiany bez akceptacji”. Na przykład pipeline może zakończyć się niepowodzeniem, jeśli migracja zawiera DROP TABLE lub DROP COLUMN, chyba że manualna bramka została zatwierdzona.
Rollback to twarda prawda: wiele zmian schematu nie jest odwracalnych. Jeśli usuniesz kolumnę, nie odzyskasz danych. Planuj rollback wokół poprawek naprzód: trzymaj down migration tylko wtedy, gdy jest naprawdę bezpieczna, i polegaj na backupach plus migracji forward, gdy nie jest.
Sparuj każdą migrację z planem odzyskiwania: co zrobić, jeśli przerwie się w połowie, i co zrobić, jeśli trzeba się cofnąć aplikację. Jeśli generujesz backendy w Go (np. z AppMaster), traktuj migracje jako część kontraktu wydania, żeby regenerowany kod i schemat były zsynchronizowane.
Pipeline jest przewidywalny tylko wtedy, gdy to, co wdrażasz, jest zawsze tym, co testowałeś. Chodzi o pakowanie i konfigurację. Traktuj wynik budowania jako zapieczętowany artefakt i trzymaj wszystkie różnice środowiskowe poza nim.
Pakowanie to zwykle jedna z dwóch dróg. Obraz kontenera jest domyślny, jeśli wdrażasz do Kubernetes, bo przypina warstwę OS i ujednolica rollouty. Bundel na VM może być równie niezawodny, jeśli zawiera skompilowany binarny plik oraz niewielki zestaw plików potrzebnych w czasie działania (np. CA certy, szablony, zasoby statyczne) i wdrażasz go za każdym razem w ten sam sposób.
Konfiguracja powinna być zewnętrzna, nie wbudowana w binarkę. Używaj zmiennych środowiskowych do większości ustawień (porty, host DB, feature flagi). Plik konfiguracyjny tylko wtedy, gdy wartości są długie lub złożone, i trzymaj go per-środowisko. Jeśli używasz serwisu konfiguracji, traktuj go jak zależność: zablokowane uprawnienia, logi audytu i wyraźny plan awaryjny.
Sekrety to linia, której nie przekraczasz. Nie trafiają do repo, obrazu ani logów CI. Unikaj drukowania connection stringów przy starcie. Trzymaj sekrety w magazynie sekretów CI i wstrzykuj je w czasie wdrożenia.
Aby artefakty były możliwe do śledzenia, wbuduj tożsamość w każdy build: taguj artefakty wersją plus SHA commita, dołącz metadane builda (wersja, commit, czas builda) w endpointzie info i zapisuj tag artefaktu w logu wdrożenia. Ułatwia to odpowiedź na pytanie „co dokładnie działa” z jednego polecenia lub pulpitu.
Jeśli generujesz backendy w Go (np. z AppMaster), ta dyscyplina ma jeszcze większe znaczenie: regeneracja jest bezpieczna, gdy nazewnictwo artefaktów i zasady konfiguracji sprawiają, że każde wydanie da się odtworzyć.
Większość porażek wdrożeń to nie "zły kod". To niedopasowanie środowisk: inna konfiguracja, brakujące sekrety lub serwis, który startuje, ale nie jest gotowy. Cel jest prosty: wdrażaj ten sam artefakt wszędzie, i zmieniaj tylko konfigurację.
Na Kubernetes dąż do kontrolowanego rollouta. Używaj rolling updates, żeby wymieniać pody stopniowo, i dodaj readiness oraz liveness checks, żeby platforma wiedziała, kiedy kierować ruch i kiedy restartować zawieszony kontener. Requests i limits mają znaczenie, bo usługa Go, która działa na dużym runnerze CI, może być OOM-owana na małym nodzie.
Trzymaj config i sekrety poza obrazem. Buduj jeden obraz na commit, potem wstrzykuj ustawienia specyficzne dla środowiska w czasie deployu (ConfigMaps, Secrets lub manager sekretów). Dzięki temu staging i produkcja uruchamiają te same fragmenty kodu.
Jeśli wdrażasz na maszynach wirtualnych, systemd może być twoim „mini-orchestrator”. Stwórz unit file z jasnym working directory, plikiem środowiskowym i polityką restartu. Uczyń logi przewidywalnymi, wysyłając stdout/stderr do kolektora logów lub journald, żeby incydenty nie zmieniały się w polowanie przez SSH.
Wciąż możesz robić bezpieczne rollouty bez klastra. Proste blue/green działanie wystarczy: trzymaj dwie katalogi (lub dwie VM), przełączaj load balancer i miej poprzednią wersję gotową do szybkiego rollbacku. Canary jest podobny: kieruj mały procent ruchu do nowej wersji przed ostatecznym przełączeniem.
Zanim uznasz deploy za „ukończony”, uruchom te same post-deployowe sprawdzenia wszędzie:
Jeśli regenerujesz backendy (np. z AppMaster), podejście to pozostaje stabilne: build raz, wdrażaj artefakt i pozwól, by konfiguracja środowiska powodowała różnice, a nie ad-hoc skrypty.
Większość złych wydań nie wynika z "złego kodu". Dzieje się tak, gdy pipeline zachowuje się inaczej z runu na run. Jeśli chcesz, żeby CI/CD dla backendów w Go był spokojny i przewidywalny, uważaj na te wzorce.
Automatyczne uruchamianie migracji przy każdym deployu bez bramek to klasyk. Migracja blokująca tabelę może wyłączyć obciążoną usługę. Postaw migracje za wyraźnym krokiem, wymagaj akceptacji dla produkcji i upewnij się, że można je bezpiecznie uruchomić ponownie.
Używanie tagów latest lub niezablokowanych obrazów bazowych to inny łatwy sposób na tajemnicze awarie. Zablokuj obrazy Docker i wersje Go, żeby środowisko buildu nie dryfowało.
Tymczasowe współdzielenie jednej bazy między środowiskami często staje się trwałe i prowadzi do wycieków danych testowych do stagingu oraz do tego, że skrypty testowe trafiają na produkcję. Separuj bazy (i dane uwierzytelniające) per środowisko, nawet jeśli schemat jest ten sam.
Brak health i readiness checks pozwala deployowi „powieść się”, choć usługa jest zepsuta, a ruch trafia za wcześnie. Dodaj checks, które odzwierciedlają prawdziwe zachowanie: czy aplikacja startuje, łączy się z bazą i obsługuje żądanie.
Wreszcie, niejasna odpowiedzialność za sekrety, konfigurację i dostęp zamienia wydania w zgadywanie. Ktoś musi odpowiadać za tworzenie, rotację i wstrzykiwanie sekretów.
Realistyczna awaria: zespół merguje zmianę, pipeline wdraża, a automatyczna migracja uruchamia się jako pierwsza. Kończy się w stagingu (mało danych), ale time-outuje w produkcji (dużo danych). Z zablokowanymi obrazami, separacją środowisk i bramką migracji deploy zatrzymałby się bezpiecznie.
Jeśli generujesz backendy w Go (np. z AppMaster), te zasady mają większe znaczenie, bo regeneracja może dotykać wielu plików naraz. Przewidywalne wejścia i wyraźne bramki powstrzymują „duże” zmiany przed staniem się ryzykownymi.
Użyj tego jako kontrolki zdrowia dla CI/CD backendów w Go. Jeśli na każde pytanie możesz odpowiedzieć jasno "tak", wydania będą łatwiejsze.
Ogranicz dostęp do produkcji i zachowuj audyt. CI powinien deployować przy użyciu dedykowanego service accounta, sekrety powinny być zarządzane centralnie, a każda ręczna akcja na produkcji powinna zostawiać jasny ślad (kto, co, kiedy).
Mały zespół opsowy czteroosobowy wypuszcza releasy raz w tygodniu. Często regenerują backend w Go, bo product team ciągle udoskonala workflowy. Cel jest prosty: mniej nocnych poprawek i wydania, które nie zaskakują.
Typowa piątkowa zmiana: dodają nowe pole do customers (zmiana schematu) i aktualizują API, które je zapisuje (zmiana kodu). Pipeline traktuje to jako jedno wydanie. Buduje jeden artefakt, uruchamia testy przeciwko dokładnie temu artefaktowi, a dopiero potem stosuje migracje i wdraża. W ten sposób baza nigdy nie jest przed kodem, który jej oczekuje, a kod nie trafia bez pasującego schematu.
Gdy zmiana schematu jest zawarta, pipeline dodaje bramkę bezpieczeństwa. Sprawdza, czy migracja jest addytywna (np. dodanie nullable column) i oznacza ryzykowne działania (jak drop column lub przepisywanie dużej tabeli). Jeśli migracja jest ryzykowna, release zatrzymuje się przed produkcją. Zespół albo przepisuje migrację na bezpieczniejszą, albo planuje okno serwisowe.
Jeśli testy zawodzą, nic nie przechodzi dalej. To samo, gdy migracje zawodzą w pre-produkcji. Pipeline nie powinien próbować przepychać zmian „tylko tym razem”.
Proste następne kroki, które działają dla większości zespołów:
Jeśli generujesz backendy z AppMaster, trzymaj regenerację w tych samych etapach pipeline’u: regenerate, build, test, migrate w bezpiecznym środowisku, następnie deploy. Traktuj generowany kod jak każdy inny kod źródłowy. Każde wydanie powinno być odtwarzalne z otagowanej wersji, z tymi samymi krokami za każdym razem.
Zafiksuj wersję Go i środowisko budowania tak, aby te same wejścia zawsze dawały ten sam binarny plik lub obraz. To eliminuje różnice "u mnie działa" i ułatwia odtwarzanie oraz naprawianie błędów.
Regeneracja może zmieniać endpointy, modele bazy i zależności, nawet jeśli nikt nie edytował kodu ręcznie. Pipeline sprawia, że te zmiany przechodzą przez te same kontrole za każdym razem, dzięki czemu regeneracja pozostaje bezpieczna zamiast ryzykownej.
Buduj raz, a potem promuj ten sam artefakt przez dev, staging i produkcję. Jeśli będziesz przebudowywać per środowisko, łatwo wysłać coś, czego nigdy nie przetestowałeś, nawet gdy to ten sam commit.
Na każdy PR uruchamiaj szybkie bramki: formatowanie, podstawowe statyczne sprawdzenia, build i testy jednostkowe z timeoutami. Niech będą wystarczająco szybkie, by ludzie ich nie omijali, i wystarczająco surowe, by błędy kończyły proces wcześnie.
Użyj małej fazy integracyjnej, która uruchamia serwis z konfiguracją podobną do produkcyjnej i łączy się z rzeczywistymi zależnościami jak PostgreSQL. Celem jest wykryć „kompiluje się, ale nie startuje” oraz oczywiste złamania kontraktu bez zamieniania CI w wielogodzinną serię testów E2E.
Traktuj migracje jako kontrolowany krok wydania, a nie coś, co uruchamia się automatycznie przy każdym deployu. Uruchamiaj je z czytelnymi logami i mechanizmem jednokrotnego wykonania, a przyjmuj do wiadomości, że wiele zmian schematu wymaga naprawy do przodu lub przywrócenia z backupu, nie zawsze prostego "undo".
Brak readiness checks jest częstą przyczyną: deploy „udaje sukces”, ale serwis nie jest gotowy i ruch trafia do niewłaściwych instancji. Dodaj readiness, aby ruch trafiał dopiero do faktycznie gotowych podów, oraz liveness, żeby platforma restartowała zablokowane kontenery. Dobrze ustawione zasoby (requests/limits) zapobiegają OOM killom.
Prosty unit systemd z przejrzystym plikiem środowiskowym i polityką restartu często wystarcza do spokojnych wdrożeń na VM-ach. Zachowaj ten sam model artefaktu co dla kontenerów, kiedy to możliwe, i dodaj mały test dymny po wdrożeniu, żeby "udane restart" nie ukrywało błędów.
Nigdy nie umieszczaj sekretów w repozytorium, obrazie czy logach CI. Wstrzykuj je w czasie wdrożenia z zarządzanego magazynu sekretów, ogranicz dostęp, i traktuj rotację jako rutynowy proces, a nie pożar do gaszenia.
Umieść regenerację w tych samych etapach pipeline’u co inne zmiany: regenerate, build, test, package, a potem migrate i deploy z bramkami. Jeśli używasz AppMaster do generowania backendu w Go, to podejście pozwala działać szybko, nie zgadując, co się zmieniło, i pewniej wdrażać zmiany.
Zablokuj środowisko (wersja Go, obraz builda), trzy proste komendy (build, test, produce artifact), traktuj migracje jak kod produkcyjny z logami i planem rollbacku, produkuj niemodyfikowalne artefakty z commit SHA, i dodaj checks, które szybko zawodzą (readiness/liveness i krótki test dymny). Ogranicz dostęp do produkcji i loguj wszystkie ręczne działania.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


