Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Błędy w projektowaniu procesów przeciągnij-i-upuść mogą utrudniać zmiany i powodować awarie. Poznaj typowe antywzorce i praktyczne kroki refaktoryzacji.
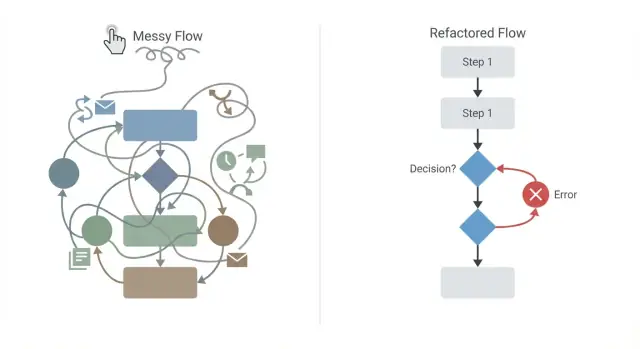
Edytory wizualne wydają się bezpieczne, bo widzisz cały diagram. Mimo to diagram może kłamać. Workflow może wyglądać schludnie, a zawieść w produkcji, gdy pojawią się prawdziwi użytkownicy, rzeczywiste dane i problemy z czasem.
Wiele problemów bierze się z traktowania diagramu jak listy kontrolnej, zamiast tego, czym on naprawdę jest: programu. Bloki dalej zawierają logikę. Tworzą stan, rozgałęziają się, ponawiają i wywołują skutki uboczne. Gdy te części nie są jawne, „małe” edycje mogą cicho zmieniać zachowanie.
Antywzorzec workflow to powtarzalny, szkodliwy kształt, który ciągle powoduje kłopoty. To nie pojedynczy błąd, to nawyk — np. ukrywanie ważnego stanu w zmiennej ustawionej w jednym rogu diagramu i używanej gdzie indziej, lub pozwolenie, żeby przepływ rósł aż nikt nie potrafi go zrozumieć.
Objawy są dobrze znane:
Zacznij od tanich i widocznych rzeczy: jaśniejsze nazwy, ściślejsze grupowanie, usuwanie martwych ścieżek i jawne pokazywanie wejść i wyjść każdego kroku. W narzędziach takich jak AppMaster często oznacza to utrzymanie Business Process skoncentrowanego na jednym zadaniu — każdy blok robi jedną rzecz i jawnie przekazuje dane.
Następnie zaplanuj głębsze refaktoryzacje: rozplątanie spaghetti flows, scentralizowanie decyzji i dodanie kompensacji dla częściowego sukcesu. Celem nie jest ładniejszy diagram, lecz workflow, który zachowuje się tak samo za każdym razem i pozostaje bezpieczny do zmiany, gdy wymagania się zmieniają.
Wiele wizualnych awarii workflow zaczyna się od jednego niewidocznego problemu: stanu, na którym polegasz, a którego nigdy jasno nie nazywasz.
Stan to wszystko, co workflow musi zapamiętać, by działać poprawnie. To zmienne (np. customer_id), flagi (np. is_verified), timery i retry, a także stan poza diagramem: wiersz w bazie, rekord CRM, status płatności czy wiadomość już wysłana.
Ukryty stan pojawia się, gdy ta „pamięć” żyje tam, gdzie się jej nie spodziewasz. Typowe przykłady to ustawienia węzłów, które działają jak zmienne, domyślne wartości, których nigdy nie ustawiłeś świadomie, albo skutki uboczne, które zmieniają dane bez wyraźnego tego zaznaczenia. Krok, który „sprawdza” coś, a jednocześnie aktualizuje pole statusu, to klasyczna pułapka.
Często wszystko działa, dopóki nie zrobisz drobnej zmiany. Przeniesiesz węzeł, użyjesz ponownie podprocesu, zmienisz domyślną wartość lub dodasz nową gałąź. Nagle workflow zaczyna działać „losowo”, bo jakaś zmienna została nadpisana, flaga nie została zresetowana, albo system zewnętrzny zwrócił nieco inny wynik.
Stan ma tendencję do ukrywania się w:
Uczyń stan jawnym i nazwanym. Jeśli jakaś wartość ma znaczenie później, zapisz ją w jasno nazwanej zmiennej, ustaw w jednym miejscu i zresetuj, gdy już nie będzie potrzebna.
Na przykład, w Business Process Editor AppMaster traktuj każdy ważny output jako zmienną pierwszej klasy, a nie coś, co „wiem”, że jest dostępne, bo węzeł się wcześniej wykonał. Mała zmiana, jak przemianowanie status na payment_status i ustawienie go dopiero po potwierdzeniu odpowiedzi płatności, może oszczędzić godzin debugowania, gdy flow zmieni się w przyszłości.
Spaghetti flow to proces wizualny, gdzie łącza krzyżują się wszędzie, kroki zawracają w zaskakujące miejsca, a warunki są zagnieżdżone tak głęboko, że nikt nie potrafi wytłumaczyć głównej ścieżki bez powiększania i przewijania. Jeśli twój diagram przypomina mapę metra naszkicowaną na serwetce, już płacisz cenę.
To utrudnia przeglądy. Ludzie przeoczają przypadki brzegowe, zatwierdzenia zajmują więcej czasu, a zmiana w jednym miejscu może coś zepsuć daleko. Podczas incydentu trudno odpowiedzieć na podstawowe pytania: „Który krok wykonał się jako ostatni?” albo „Dlaczego weszliśmy w tę gałąź?”.
Spaghetti zwykle rośnie z dobrych intencji: kopiowanie działającej gałęzi „tylko raz”, dodawanie szybkich poprawek pod presją, nakładanie obsługi wyjątków jako zagnieżdżone warunki, cofanie się do wcześniejszych kroków zamiast tworzenia wielokrotnego użytku subprocesu, albo mieszanie reguł biznesowych, formatowania danych i powiadomień w tym samym bloku.
Przykład: onboarding. Zaczyna się czysto, potem pojawiają się odrębne gałęzie dla darmowych triali, poleceń partnerskich, ręcznej weryfikacji i obsługi VIP. Po kilku sprintach diagram ma wiele powrotów do „Zbierz dokumenty” i kilka różnych miejsc wysyłających mail powitalny.
Zdrowszy cel jest prosty: jedna główna ścieżka dla przypadku powszechnego oraz czytelne ścieżki boczne dla wyjątków. W Business Process Editor AppMaster często oznacza to wyciągnięcie powtarzającej się logiki do wielokrotnego użytku subprocesu, nazwane gałęzie według intencji ("Wymaga ręcznej weryfikacji") i ograniczenie pętli.
Częsty wzorzec to długi łańcuch warunków: sprawdź A, potem znowu A, potem sprawdź B w trzech różnych miejscach. Zaczyna się od „jeszcze jednego warunku”, a workflow zamienia się w labirynt, gdzie drobne zmiany mają duże skutki uboczne.
Większe ryzyko to rozproszone reguły, które stopniowo się rozjeżdżają. Jedna ścieżka zatwierdza wniosek, bo wynik kredytowy jest wysoki. Inna blokuje ten sam wniosek, bo starszy krok nadal traktuje „brak numeru telefonu” jako twardy blok. Obie decyzje mogą być lokalnie uzasadnione, ale razem dają niespójne wyniki.
Gdy ta sama reguła powtarza się w całym diagramie, ludzie aktualizują jedną kopię i zapominają o innych. Z czasem powstają sprawdzenia, które wyglądają podobnie, ale nie są takie same: jedno mówi „country = US”, inne „country in (US, CA)”, a trzecie używa „currency = USD” jako zamiennika. Workflow dalej działa, ale przestaje być przewidywalny.
Dobry refactor to scalenie decyzji w jeden jasno nazwany krok decyzyjny, który zwraca mały zbiór wyników. W Business Process Editor AppMaster często oznacza to grupowanie powiązanych sprawdzeń w jednym bloku decyzyjnym i nadanie gałęzi znaczenia.
Utrzymuj proste wyniki, na przykład:
Następnie kieruj wszystko przez ten pojedynczy punkt decyzyjny zamiast rozsypywać mini-decyzje po całym flow. Gdy reguła się zmieni, aktualizujesz ją raz.
Przykład: workflow weryfikacji rejestracji sprawdza format e-maila w trzech miejscach (przed OTP, po OTP i przed stworzeniem konta). Przenieś całą walidację do jednego kroku „Validate request”. Jeśli wynik to „Needs info”, skieruj do jednego kroku wiadomości, który dokładnie informuje użytkownika, czego brakuje, zamiast kończyć później ogólnym błędem.
Jednym z najdroższych błędów jest zakładanie, że workflow albo całkowicie się powiedzie, albo całkowicie zawiedzie. Rzeczywiste procesy często odnoszą sukces w połowie drogi. Jeśli późniejszy krok padnie, zostajesz z bałaganem: pieniądze pobrane, wiadomości wysłane, rekordy utworzone, ale brak czystego sposobu wycofania.
Przykład: obciążasz kartę klienta, a potem próbujesz utworzyć zamówienie. Płatność się udaje, ale tworzenie zamówienia nie powiodło się, bo serwis magazynowy nie odpowiedział. Teraz support dostaje wściekłego maila, księgowość widzi opłatę, a w systemie nie ma pasującego zamówienia do realizacji.
Kompensacja to ścieżka „cofnij” (lub „upewnij się, że jest bezpiecznie”), która uruchamia się, gdy coś zawiedzie po częściowym sukcesie. Nie musi być perfekcyjna, ale musi być celowa. Typowe podejścia to odwrócenie akcji (refund, anuluj, usuń szkic), przekonwertowanie wyniku do bezpiecznego stanu (oznacz „Płatność pobrana, realizacja w toku”), skierowanie do ręcznej weryfikacji z kontekstem oraz użycie sprawdzeń idempotencji, żeby ponowne próby nie powodowały podwójnych obciążeń czy podwójnych wysyłek.
Gdzie umieścić kompensację ma znaczenie. Nie chowaj całego czyszczenia w jednym „error” boxie na końcu diagramu. Umieść go obok ryzykownego kroku, gdy nadal masz potrzebne dane (ID płatności, token rezerwacji, ID żądania zewnętrznego). W AppMaster zwykle oznacza to zapisanie tych ID zaraz po wywołaniu i rozgałęzienie od razu na success vs failure.
Przydatna zasada: każdy krok, który rozmawia z systemem zewnętrznym, powinien odpowiedzieć na dwa pytania zanim przejdziesz dalej: „Co zmieniliśmy?” i „Jak to cofnąć lub ograniczyć, jeśli następny krok zawiedzie?”
Wiele awarii pojawia się w momencie, gdy workflow wychodzi poza twój system. Wywołania zewnętrzne zawodzą w nieprzewidywalny sposób: powolne odpowiedzi, chwilowe niedostępności, duplikaty żądań i częściowe sukcesy. Jeśli diagram zakłada „wywołanie się powiodło” i idzie dalej, użytkownicy w końcu zobaczą brakujące dane, podwójne obciążenia lub powiadomienia w złym momencie.
Zacznij od oznaczenia kroków, które mogą zawieść z przyczyn od ciebie niezależnych: API zewnętrzne, płatności i refundy (np. Stripe), wiadomości (e-mail/SMS, Telegram), operacje na plikach i usługi chmurowe.
Dwa typowe błędy to brak timeoutów i ślepe retry. Bez timeoutu jedno wolne żądanie może zablokować cały proces. Z retry bez zasad możesz pogorszyć sprawę, np. wysyłając tę samą wiadomość trzykrotnie lub tworząc duplikaty w systemie trzeciej strony.
Tu idempotencja ma znaczenie. Mówiąc prosto, operacja idempotentna jest bezpieczna do ponownego wywołania. Jeśli workflow powtórzy krok, nie powinna powstać druga opłata, drugie zamówienie czy drugi e-mail powitalny.
Praktyczne rozwiązanie to zapisanie klucza żądania i statusu przed wywołaniem. W Business Process Editor AppMaster może to być proste: zapisz rekord jak „payment_attempt: key=XYZ, status=pending”, a po odpowiedzi zaktualizuj go na „success” lub „failed”. Jeśli workflow trafi na ten krok ponownie, sprawdź ten rekord i zdecyduj, co robić.
Solidny wzorzec wygląda tak:
Częsty błąd to pojedynczy krok, który cicho robi cztery rzeczy: waliduje input, liczy wartości, zapisuje do bazy i powiadamia ludzi. Wydaje się to efektywne, ale zmiany stają się ryzykowne. Gdy coś się zepsuje, nie wiesz, która część zawiniła i nie możesz bezpiecznie użyć jej gdzie indziej.
Krok jest przeładowany, gdy jego nazwa jest niejasna (np. „Handle order”) i nie potrafisz opisać jego outputu w jednym zdaniu. Kolejnym znakiem jest długa lista wejść, które są używane tylko przez „jakąś część” kroku.
Przeładowane kroki często mieszają:
Podziel duży krok na mniejsze, nazwane bloki, gdzie każdy blok ma jedno zadanie i jasne wejście oraz wyjście. Prosty wzorzec nazewnictwa pomaga: czasowniki dla kroków (Validate Address, Calculate Total, Create Invoice, Send Confirmation) i rzeczowniki dla obiektów danych.
Używaj spójnych nazw dla wejść i wyjść. Na przykład preferuj „OrderDraft” (przed zapisem) i „OrderRecord” (po zapisie) zamiast „order1/order2” czy „payload/result”. Dzięki temu diagram będzie czytelny nawet po miesiącach.
Gdy powtarza się wzorzec, wyciągnij go do wielokrotnego użytku subflow. W Business Process Editor AppMaster często wygląda to jak przeniesienie „Validate -> Normalize -> Persist” do współdzielonego bloku używanego przez wiele workflowów.
Przykład: workflow onboardingu, który „tworzy użytkownika, ustawia uprawnienia, wysyła mail i zapisuje audit” może stać się czterema krokami plus wielokrotnego użytku subflow „Write Audit Event”. To upraszcza testowanie, zmniejsza ryzyko zmian i ogranicza niespodzianki.
Większość problemów z workflow bierze się z doklejania „jeszcze jednej” reguły lub łącza, aż nikt nie potrafi przewidzieć, co się stanie. Refaktoryzacja polega na przywróceniu czytelności i pokazaniu wszystkich skutków ubocznych i przypadków błędów.
Zacznij od narysowania ścieżki happy path jako jednej jasnej linii od początku do końca. Jeśli główny cel to „zatwierdź zamówienie”, ta linia powinna pokazywać tylko niezbędne kroki, gdy wszystko idzie dobrze.
Następnie działaj w małych krokach:
payment_status lepsze niż flag2)Szybki sposób na znalezienie ukrytej złożoności to pytanie: „Co się stanie, jeśli ten krok wykona się dwa razy?” Jeśli odpowiedź brzmi „możemy podwójnie obciążyć” lub „możemy wysłać dwa maile”, potrzebujesz jaśniejszego stanu i idempotentnego zachowania.
Przykład: workflow onboardingu tworzy konto, przypisuje plan, pobiera opłatę przez Stripe i wysyła wiadomość powitalną. Jeśli pobranie się udało, ale wysyłka maila padła, nie chcesz, by płacący użytkownik został bez dostępu. Dodaj ścieżkę kompensacyjną obok: oznacz użytkownika jako pending_welcome, ponów wysyłkę, a jeśli ponowienia zawiodą, zrefunduj i cofnij plan.
W AppMaster porządki te są łatwiejsze, gdy utrzymujesz Business Process Editor płytki: małe kroki, jasne nazwy zmiennych i subflowy typu „Charge payment” czy „Send notification” do ponownego użycia.
Refaktoryzacja powinna upraszczać i uczynić proces bezpieczniejszym do zmiany. Ale niektóre poprawki dodają nową złożoność, zwłaszcza pod presją czasu.
Jedną pułapką jest trzymanie starych ścieżek „na wszelki wypadek” bez wyraźnego przełącznika, znacznika wersji czy daty wycofania. Ludzie testują stary tor, support się do niego odwołuje i wkrótce utrzymujesz dwa procesy. Jeśli potrzebujesz stopniowego rolloutu, zrób to jawnie: nazwij nową ścieżkę, zaplanuj bramkę, która ją przepuszcza, i ustal datę usunięcia starej.
Tymczasowe flagi to kolejny powolny wyciek. Flaga utworzona dla debugowania lub migracji na tydzień często staje się stała, a każda nowa zmiana musi ją uwzględniać. Traktuj flagi jak rzeczy łatwo psujące się: dokumentuj cel, przypisz właściciela i ustaw termin usunięcia.
Trzecią pułapką jest dodawanie wyjątków typu "jednorazowy" zamiast poprawy modelu. Jeśli ciągle dokładasz „specjalne” węzły, diagram rośnie na boki, a reguły stają się nieprzewidywalne. Gdy ten sam wyjątek pojawia się dwa razy, zwykle oznacza to, że trzeba zaktualizować model danych lub stan procesu.
Na koniec: nie chowaj reguł biznesowych w niepowiązanych węzłach tylko po to, żeby coś działało. To kusi w edytorach wizualnych, ale później nikt nie wie, gdzie znaleźć regułę.
Znaki ostrzegawcze:
Przykład: jeśli klienci VIP potrzebują innego zatwierdzania, nie dodawaj ukrytych sprawdzeń w trzech miejscach. Dodaj jasną decyzję „Customer type” raz i kieruj dalej z niej.
Większość problemów wychodzi tuż przed uruchomieniem: ktoś uruchamia flow na prawdziwych danych, a diagram robi coś, czego nikt nie potrafi wytłumaczyć.
Przejdź przepływ na głos. Jeśli happy path wymaga długiego tłumaczenia, prawdopodobnie diagram ma ukryty stan, zdublowane reguły lub za dużo gałęzi, które powinny być pogrupowane.
Uruchom flow na trzech przypadkach: normalny sukces, prawdopodobna porażka (np. odrzucenie płatności) i dziwny przypadek brzegowy (brak opcjonalnych danych). Obserwuj kroki, które „trochę działają” i zostawiają system w połowie gotowy.
W Business Process Editor AppMaster to często prowadzi do czystego refaktoru: wyciągnij powtarzające się sprawdzenia do jednego wspólnego kroku, uczyń skutki uboczne jawne i dodaj wyraźne ścieżki kompensacyjne obok każdego ryzykownego wywołania.
Wyobraź sobie workflow onboardingu klienta, który robi trzy rzeczy: weryfikuje tożsamość, tworzy konto i uruchamia płatną subskrypcję. Brzmi prosto, ale często staje się procesem, który „zwykle działa”, aż coś zawiedzie.
Pierwsza wersja rośnie krok po kroku. Pojawia się checkbox „Verified”, potem flaga „NeedsReview”, a potem kolejne flagi. Sprawdzenia „jeśli zweryfikowany” pojawiają się w wielu miejscach, bo każda nowa funkcja dokłada swoją gałąź.
Wkrótce workflow wygląda tak: verify identity, create user, charge card, send welcome email, create workspace, potem wracamy, żeby jeszcze raz sprawdzić weryfikację, bo późniejszy krok tego wymaga. Jeśli charging się powiedzie, a tworzenie workspace zawiedzie, nie ma rollbacku — klient został obciążony, a konto jest w połowie utworzone.
Czystszy projekt zaczyna się od jawnego i kontrolowanego stanu. Zastąp rozproszone flagi jedną explicytną statusem onboardingu (np.: Draft, Verified, Subscribed, Active, Failed). Umieść logikę „czy kontynuować?” w jednym punkcie decyzyjnym.
Cele refaktoru, które szybko likwidują ból:
Po tym, modeluj dane i workflow razem. Jeśli Subscribed jest true, zapisz ID subskrypcji, ID płatności i odpowiedź providera w jednym miejscu, aby kompensacja mogła działać bez zgadywania.
Na koniec testuj przypadki błędów celowo: timeouty weryfikacji, sukces płatności, ale błąd maila, błędy tworzenia workspace oraz zdublowane webhooki.
Jeśli budujesz te workflowy w AppMaster, pomaga utrzymanie logiki biznesowej w wielokrotnego użytku Business Processes i pozwolenie platformie na regenerację czystego kodu w miarę zmiany wymagań, aby stare gałęzie nie zalegały. Jeśli chcesz szybko prototypować refactor (backend, web i mobilne części w jednym miejscu), AppMaster na appmaster.io jest zaprojektowany do tego typu end-to-end budowy workflowów.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


