Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Zaplanuj i zbuduj aplikację do zarządzania incydentami dla zespołów IT z workflowami istotności, jasną własnością, osiami czasu i postmortemami w jednym wewnętrznym narzędziu.
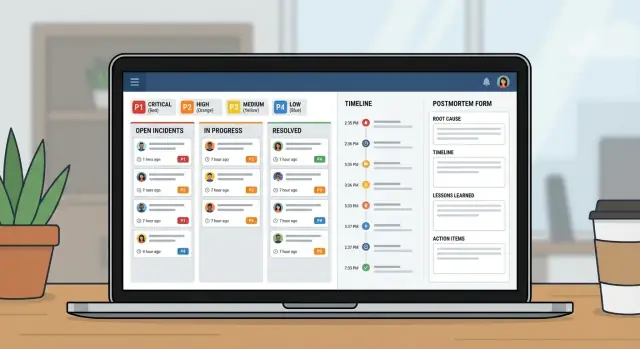
Gdy następuje awaria, większość zespołów sięga po to, co akurat jest pod ręką: wątek czatu, łańcuch e‑maili, może arkusz kalkulacyjny, który ktoś zaktualizuje „jak będzie chwila”. Pod presją ten zestaw zawodów zawodzi zawsze tak samo: odpowiedzialność się rozmywa, znaczniki czasu giną, a decyzje znikają w przewijaniu.
Prosta aplikacja do zarządzania incydentami naprawia podstawy. Daje jedno miejsce, w którym istnieje rekord incydentu — z jasnym właścicielem, poziomem istotności, na którym wszyscy się zgadzają, i osią czasu opisującą, co i kiedy się wydarzyło. Ten pojedynczy rekord ma znaczenie, bo te same pytania pojawiają się przy każdym incydencie: kto prowadzi? kiedy to się zaczęło? jaki jest aktualny status? co już próbowano?
Bez takiego wspólnego rekordu przekazania marnują czas. Support mówi klientom jedno, podczas gdy inżynieria robi coś innego. Menedżerowie proszą o aktualizacje i odrywają responderów od naprawy. Później nikt nie potrafi zrekonstruować osi czasu z zaufaniem, więc postmortem staje się zgadywanką.
Celem nie jest zastąpienie monitoringu, chatu czy systemu ticketowego. Alerty wciąż mogą zaczynać się gdzie indziej. Chodzi o przechwycenie śladu decyzji i utrzymanie porozumienia między ludźmi.
Operacje IT i inżynierowie on‑call używają go do koordynacji reakcji. Support korzysta, by szybko przekazywać dokładne informacje klientom. Menedżerowie widzą postęp bez przerywania pracy responderów.
O 9:12 monitoring sygnalizuje skok błędów 500 w portalu klienta. Agent supportu zgłasza również: „Logowanie nie działa dla większości użytkowników.” Lider on‑call IT otwiera incydent P1 w aplikacji i dopina pierwszy alert oraz zrzut ekranu od supportu.
Przy P1 zachowanie zmienia się szybko. Właściciel incydentu ściąga właściciela backendu, właściciela bazy danych i łącznika z supportu. Praca nieistotna wstrzymana. Zaplanowane wdrożenia zatrzymane. Zespół ustala rytm aktualizacji (np. co 15 minut). Rozpoczyna się wspólne połączenie, ale rekord incydentu pozostaje źródłem prawdy.
O 9:18 ktoś pyta: „Co się zmieniło?” Oś czasu pokazuje wdrożenie o 8:57, ale nie mówi, co zostało wdrożone. Właściciel backendu i tak wycofuje wdrożenie. Błędy spadają, po czym wracają. Zespół zaczyna podejrzewać bazę danych.
Większość opóźnień pojawia się w kilku przewidywalnych miejscach: niejasne przekazania („myślałem, że to ty to sprawdzasz”), brak kontekstu (ostatnie zmiany, znane ryzyka, aktualny właściciel) i rozsypane aktualizacje w czacie, ticketach i e‑mailach.
O 9:41 właściciel bazy danych znajduje zapętlone zapytanie uruchomione przez zadanie zaplanowane. Wyłączają to zadanie, restartują uszkodzoną usługę i potwierdzają przywrócenie. Istotność zostaje obniżona do P2 w celu monitoringu.
Dobre zamknięcie to nie „znów działa”. To czysty rekord: minuta po minucie oś czasu, ostateczna przyczyna źródłowa, kto podjął które decyzje, co zostało wstrzymane i prace follow‑up z właścicielami i terminami. Tak stresujące P1 zamienia się w naukę, zamiast w powtarzający się ból.
Dobre narzędzie do incydentów to w dużej mierze dobry model danych. Jeśli rekordy są niejasne, ludzie będą się kłócić o to, czym jest incydent, kiedy się zaczął i co nadal jest otwarte.
Trzymaj główne byty blisko tego, jak zespoły IT już rozmawiają:
Aby zapobiec przyszłym niejasnościom, nadaj Incydentowi kilka strukturalnych pól, które zawsze są wypełnione. Tekst swobodny pomaga, ale nie powinien być jedynym źródłem prawdy. Praktyczne minimum to: jasny tytuł, wpływ (co widzą użytkownicy), dotknięte serwisy, czas rozpoczęcia, aktualny status i istotność.
Relacje są ważniejsze niż dodatkowe pola. Jeden incydent powinien mieć wiele aktualizacji i wiele zadań oraz relację wiele‑do‑wielu z serwisami (bo awarie często dotykają wielu systemów). Postmortem powinno być powiązane jeden‑do‑jednego z incydentem, żeby była jedna finalna historia.
Przykład: incydent „Błędy przy kasie” łączy się z serwisami „Payments API” i „PostgreSQL”, ma aktualizacje co 15 minut i zadania typu „Wycofaj wdrożenie” oraz „Dodaj blokadę retry”. Później postmortem zapisuje przyczynę źródłową i tworzy długoterminowe zadania.
Gdy ludzie są zestresowani, potrzebują prostych etykiet, które znaczą to samo dla wszystkich. Zdefiniuj P1–P4 prostym językiem i pokaż definicję obok pola istotności.
Cele reakcji powinny być sformułowane jak zobowiązania. Prosty punkt wyjścia (dostosuj do swojej rzeczywistości):
| Istotność | Pierwsza reakcja (ack) | Pierwsza aktualizacja | Częstotliwość aktualizacji |
|---|---|---|---|
| P1 | 5 min | 15 min | co 30 min |
| P2 | 15 min | 30 min | co 60 min |
| P3 | 4 godziny | 1 dzień roboczy | codziennie |
| P4 | 2 dni robocze | 1 tydzień | co tydzień |
Utrzymuj zasady eskalacji mechaniczne. Jeśli P2 nie dotrzymuje rytmu aktualizacji lub wpływ rośnie, system powinien zasugerować przegląd istotności. Aby unikać chaosu, ogranicz, kto może zmieniać istotność (zwykle właściciel incydentu lub incident commander), jednocześnie pozwalając każdemu na żądanie przeglądu w komentarzu.
Szybka macierz wpływu pomaga zespołom szybko wybrać poziom istotności. Zapisz ją jako kilka wymaganych pól: liczba dotkniętych użytkowników, ryzyko przychodów, bezpieczeństwo, zgodność, oraz czy istnieje obejście.
Podczas incydentu ludzie nie potrzebują więcej opcji. Potrzebują małego zestawu stanów, które sprawiają, że następny krok jest oczywisty.
Zacznij od kroków, które już wykonujesz w spokojny dzień, a potem skróć listę. Jeśli masz więcej niż 6–7 stanów, zespoły będą się kłócić o słowa zamiast naprawiać problem.
Praktyczny zestaw:
Każdy status potrzebuje jasnych reguł wejścia i wyjścia. Na przykład:
Używaj przejść, aby wymuszać pola, które ludzie zapominają. Powszechna zasada: nie zamykaj incydentu bez krótkiego podsumowania przyczyny źródłowej i przynajmniej jednego zadania follow‑up. Jeśli dopuszczasz „RCA: TBD”, zwykle tak zostaje.
Strona incydentu powinna odpowiadać na trzy pytania na pierwszy rzut oka: kto jest właścicielem, jakie jest następne działanie i kiedy opublikowano ostatnią aktualizację.
Gdy incydent jest głośny, najszybszym sposobem na stracenie czasu jest niejasna odpowiedzialność. Twoja aplikacja powinna wyznaczać jedną osobę jako wyraźnie odpowiedzialną, a jednocześnie ułatwiać innym pomoc.
Prosty wzorzec, który się sprawdza:
Przydział powinien być jawny i audytowalny. Śledź, kto ustawił właściciela, kto to zaakceptował i każdą późniejszą zmianę. „Zaakceptowano” ma znaczenie, bo przypisanie kogoś, kto śpi lub jest offline, nie jest prawdziwym właścicielstwem.
Przydział on‑call vs przypisanie zespołowe zależy zwykle od istotności. Dla P1/P2 domyślnie używaj rotacji on‑call, by zawsze był nazwany właściciel. Dla niższych istotności przypisanie zespołowe może wystarczyć, ale wciąż wymaga jednego głównego właściciela w krótkim czasie.
Planuj urlopy i przerwy w dostępności w procesie ludzkim, nie tylko w systemach. Jeśli przypisana osoba jest oznaczona jako niedostępna, przekaż do zastępczej rotacji on‑call lub lidera zespołu. Utrzymuj to automatyczne, ale widoczne, aby można to szybko skorygować.
Eskalacja powinna uruchamiać się zarówno w zależności od istotności, jak i milczenia. Użyteczny punkt wyjścia:
Dobra oś czasu to wspólna pamięć. Podczas incydentu kontekst znika szybko. Jeśli uchwycisz właściwe momenty w jednym miejscu, przekazania będą łatwiejsze, a postmortem w dużej mierze napisane zanim ktoś otworzy dokument.
Utrzymuj oś czasu stanowczą. Nie zamieniaj jej w log czatu. Większość zespołów polega na niewielkim zestawie wpisów: wykrycie, potwierdzenie, kluczowe kroki mitigacyjne, przywrócenie i zamknięcie.
Każdy wpis potrzebuje znacznika czasu, autora i krótkiego, prostego opisu. Ktoś dołączający później powinien przeczytać pięć wpisów i zrozumieć, co się dzieje.
Różne aktualizacje służą różnym odbiorcom. Pomaga, gdy wpisy mają typ, np. notatka wewnętrzna (suche szczegóły), aktualizacja dla klienta (ostrożne sformułowanie), decyzja (dlaczego wybrano opcję A) i przekazanie (co następna osoba musi wiedzieć).
Przypomnienia powinny podążać za istotnością, nie za osobistymi preferencjami. Jeśli timer osiągnie limit, najpierw przypomnij obecnemu właścicielowi, a potem eskaluj, jeśli jest powtarzane pominięcie.
Powiadomienia powinny być celowane i przewidywalne. Wystarczy prosty zestaw zasad: powiadom przy tworzeniu, przy zmianie istotności, przy przywróceniu i gdy aktualizacje są przeterminowane. Unikaj powiadamiania całej firmy przy każdej zmianie.
Postmortem ma dwa zadania: wyjaśnić, co się stało prostym językiem, oraz sprawić, by ta sama awaria była mniej prawdopodobna następnym razem.
Utrzymuj zapis krótki i wymuszaj konwersję w działania. Praktyczna struktura: podsumowanie, wpływ na klientów, przyczyna źródłowa, naprawy zastosowane i zadania follow‑up.
Follow‑upy są sednem. Nie zostawiaj ich jako akapitu na końcu. Zamień każdy follow‑up w zadanie śledzone z właścicielem i terminem, nawet jeśli termin to „następny sprint”. To różnica między „powinniśmy poprawić monitoring” a „Alex doda alert saturacji połączeń DB do piątku”.
Tagi czynią postmortemy przydatnymi później. Dodaj 1–3 motywy do każdego incydentu (brak monitoringu, wdrożenie, pojemność, proces). Po miesiącu możesz odpowiedzieć na podstawowe pytania, np. czy większość P1 wynika z wydań czy braków alertów.
Dowody powinny być łatwe do załączenia, nie obowiązkowe. Wspieraj pola opcjonalne na zrzuty ekranu, fragmenty logów i odniesienia do systemów zewnętrznych (ID ticketów, wątki czatu, numery spraw u dostawcy). Utrzymuj to lekkie, żeby ludzie rzeczywiście to wypełniali.
Traktuj to jak mały produkt, nie arkusz z dodatkowymi kolumnami. Dobra aplikacja do incydentów to w rzeczywistości trzy widoki: co się dzieje teraz, co zrobić dalej i czego się nauczyć po wszystkim.
Zacznij od szkicu ekranów, które ludzie otwierają pod presją:
Zbuduj model danych i uprawnienia razem. Jeśli każdy może edytować wszystko, historia staje się chaotyczna. Powszechne podejście: szeroki dostęp do podglądu dla IT, kontrolowane zmiany stanu/istotności, responderzy mogą dodawać aktualizacje, a postmortem ma wyraźnego właściciela do zatwierdzenia.
Potem dodaj reguły workflow, które zapobiegają pół‑wypełnionym incydentom. Wymagane pola powinny zależeć od stanu. Możesz pozwolić, by „New” miało tylko tytuł i zgłaszającego, ale wymagać w „Mitigating” streszczenia wpływu, a w „Resolved” — podsumowania przyczyny źródłowej plus przynajmniej jednego zadania follow‑up.
Na koniec testuj, odtwarzając 2–3 przeszłe incydenty. Niech jedna osoba zagra incident commandera, a druga respondera. Szybko zobaczysz, które statusy są niejasne, które pola pomijane i gdzie potrzebne są lepsze wartości domyślne.
Większość systemów incydentowych zawodzi z prostych powodów: ludzie nie pamiętają reguł pod presją, a aplikacja nie przechowuje faktów potrzebnych później.
Jeśli masz sześć poziomów istotności i dziesięć stanów, ludzie będą zgadywać. Trzymaj się 3–4 istotności i stanów skupionych na tym, co ktoś powinien zrobić dalej.
Kiedy wszyscy „patrzą”, nikt nie prowadzi. Wymagaj jednego nazwanego właściciela, zanim incydent ruszy dalej, i spraw, by przekazania były jawne.
Jeżeli „co się stało kiedy” opiera się na historii czatu, postmortemy zamieniają się w kłótnię. Automatycznie rejestruj czasy otwarcia, potwierdzenia, mitigacji i zamknięcia, i trzymaj wpisy osi czasu krótkie.
Unikaj też zamykania z niejasnymi notatkami przyczyny typu „problem z siecią”. Wymagaj jednego jasnego stwierdzenia przyczyny źródłowej i przynajmniej jednego konkretnego następnego kroku.
Zanim wdrożysz to w całej organizacji IT, przetestuj podstawy pod presją. Jeśli ludzie nie znajdą odpowiedniego przycisku w pierwsze dwie minuty, wrócą do wątków czatu i arkuszy.
Skoncentruj się na krótkiej liście kontroli przy starcie: role i uprawnienia, jasne definicje istotności, wymuszona własność, reguły przypomnień i ścieżka eskalacji przy niedotrzymaniu celów reakcji.
Pilotażuj z jednym zespołem i kilkoma serwisami, które generują częste alerty. Uruchom przez dwa tygodnie, potem dostosuj na podstawie prawdziwych incydentów.
Jeśli chcesz zbudować to jako jedną wewnętrzną aplikację bez łączenia arkuszy i oddzielnych narzędzi, AppMaster (appmaster.io) jest jedną z opcji. Pozwala stworzyć model danych, reguły workflow oraz interfejsy web/mobilne w jednym miejscu, co dobrze pasuje do kolejki incydentów, strony incydentu i śledzenia postmortemów.
Zastępuje rozproszone aktualizacje jednym wspólnym rekordem, który szybko odpowiada na podstawowe pytania: kto jest właścicielem incydentu, co widzą użytkownicy, co już próbowano i co robić dalej. To zmniejsza straty czasu na przekazania, sprzeczne komunikaty i prośby „podsumuj, proszę”.
Otwórz incydent, gdy uznasz, że problem ma realny wpływ na klientów lub biznes — nawet jeżeli przyczyna nie jest jeszcze jasna. Możesz zacząć od roboczego tytułu i wpisu „wpływ: nieznany”, a potem doprecyzować dane, gdy potwierdzisz skalę i istotność.
Utrzymaj mały, ustrukturyzowany zestaw pól: jasny tytuł, streszczenie wpływu, dotknięte serwisy, czas rozpoczęcia, aktualny status, poziom istotności i pojedynczy właściciel. Dodawaj aktualizacje i zadania w miarę rozwoju sytuacji, ale nie polegaj jedynie na tekście swobodnym dla kluczowych faktów.
Użyj 3–4 poziomów z prostymi definicjami, które nie będą wywoływać dyskusji. Dobry domyślny podział to: P1 — awaria krytyczna lub ryzyko utraty danych; P2 — poważna funkcja niedostępna, ale istnieje obejście lub ograniczony zasięg; P3 — mniejszy wpływ; P4 — kosmetyczny lub drobny błąd.
Śledź cele, które czują się jak zobowiązania: czas do potwierdzenia (ack), czas do pierwszej aktualizacji i częstotliwość aktualizacji. Wyzwalaj przypomnienia i eskalacje, gdy rytm aktualizacji zostanie przerwany — w incydentach „milczenie” często jest realnym problemem.
Postaraj się o około sześć stanów: New, Acknowledged, Investigating, Mitigating, Monitoring i Resolved. Każdy stan powinien jasno wskazywać następny krok, a przejścia wymuszać pola, które ludzie zapominają uzupełnić pod presją, np. właściciela przed Acknowledged lub podsumowania przyczyny przed zamknięciem.
Wymagaj jednego głównego właściciela, odpowiedzialnego za prowadzenie reakcji i publikowanie aktualizacji. Rejestruj akceptację właściciela, aby nie „przypisać” osoby, która jest offline, i zapisuj każde przekazanie jako zdarzenie, żeby następna osoba nie zaczynała od zera.
Zawieraj tylko kluczowe momenty: wykrycie, potwierdzenie, kluczowe decyzje, kroki mitigacyjne, przywrócenie i zamknięcie — każdy wpis z datą i autorem. Traktuj oś czasu jako współdzieloną pamięć, nie jako zapis czatu, aby osoba dołączająca późno mogła szybko nadrobić brakujące informacje.
Bądź zwięzły i ukierunkowany na działania: co się stało, wpływ na klientów, przyczyna źródłowa, co zmieniono podczas mitigacji i pozycje follow-up z właścicielami i terminami. Sama treść jest użyteczna, ale to śledzone zadania zapobiegają powtórce incydentu.
Tak. Jeśli odwzorujesz incydenty, aktualizacje, zadania, serwisy i postmortemy jako prawdziwe dane i wymuszysz reguły workflow w aplikacji, można uniknąć rozproszenia między arkuszami i osobnymi narzędziami. AppMaster (appmaster.io) pozwala budować model danych, interfejsy web/mobilne i walidacje stanów w jednym miejscu.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


