14 mars 2025·8 min de lecture
Tâches en arrière‑plan avec mises à jour de progression : modèles d'UI qui fonctionnent
Apprenez des modèles pratiques pour les tâches en arrière‑plan avec mises à jour de progression : files d'attente, modèle de statut, messages UI, actions annuler/réessayer et rapport d'erreurs.
Pourquoi les utilisateurs restent bloqués quand des tâches tournent en arrière‑plan
Les actions longues ne devraient pas bloquer l'interface. Les gens changent d'onglet, perdent la connexion, ferment leur ordinateur portable ou se demandent simplement si quelque chose se passe. Quand l'écran est figé, l'utilisateur devine — et deviner mène à des clics répétés, des soumissions en double et des tickets au support.
Un bon travail en arrière‑plan tient surtout à la confiance. Les utilisateurs veulent trois choses :
- Un statut clair (queued, running, done)
- Une idée du temps (même une estimation approximative)
- Une action évidente suivante (attendre, continuer, annuler, ou revenir plus tard)
Sans cela, le job peut très bien tourner, mais l'expérience paraît cassée.
Une confusion fréquente est de traiter une requête lente comme un vrai travail en arrière‑plan. Une requête lente est toujours un appel web qui fait attendre l'utilisateur. Le travail en arrière‑plan est différent : vous démarrez un job, renvoyez une confirmation immédiate, et le traitement lourd se passe ailleurs pendant que l'UI reste utilisable.
Exemple : un utilisateur importe un CSV de clients. Si l'UI bloque, il peut rafraîchir, re‑uploader et créer des doublons. Si l'import démarre en arrière‑plan et que l'UI affiche une carte de job avec progression et une option Annuler sûre, il peut continuer à travailler et revenir à un résultat clair.
Briques de base : jobs, files d'attente, workers et statut
Quand on parle de tâches en arrière‑plan avec mises à jour de progression, on pense généralement à quatre éléments qui coopèrent.
Un job est l'unité de travail : "importer ce CSV", "générer ce rapport" ou "envoyer 5 000 emails". Une file d'attente est la file d'attente où les jobs attendent d'être traités. Un worker prend des jobs dans la file et exécute le travail (un à la fois ou en parallèle).
Pour l'UI, l'élément le plus important est l'état du cycle de vie du job. Gardez les états peu nombreux et prévisibles :
- Queued : accepté, en attente d'un worker
- Running : en cours de traitement
- Done : terminé avec succès
- Failed : arrêté suite à une erreur
Chaque job a besoin d'un ID de job (référence unique). Quand l'utilisateur clique sur un bouton, renvoyez cet ID immédiatement et affichez une ligne « Tâche démarrée » dans un panneau de tâches.
Ensuite, il faut une façon de demander « Que se passe‑t‑il maintenant ? » C'est généralement un endpoint de statut (ou toute méthode de lecture) qui prend l'ID de job et renvoie l'état plus les détails de progression. L'UI l'utilise pour afficher le pourcentage, l'étape courante et les messages.
Enfin, le statut doit vivre dans un stockage durable, pas seulement en mémoire. Les workers plantent, les apps redémarrent et les utilisateurs rafraîchissent les pages. Le stockage durable rend les progrès et les résultats fiables. Au minimum, enregistrez :
- l'état courant et les timestamps
- la valeur de progression (pourcentage ou compte)
- un résumé du résultat (ce qui a été créé ou modifié)
- les détails d'erreur (pour le debug et des messages lisibles)
Si vous construisez sur une plateforme comme AppMaster, traitez la table de statut comme n'importe quel autre modèle de données : l'UI la lit par ID de job et le worker la met à jour au fil du job.
Choisir un pattern de file qui correspond à votre charge
Le pattern de file que vous choisissez change la manière dont l'application paraît « équitable » et prévisible. Si une tâche se retrouve derrière beaucoup d'autres, l'utilisateur la perçoit comme un retard aléatoire, même si le système est sain. Le choix de la file devient donc une décision UX, pas seulement d'infrastructure.
Une file simple basée sur la base de données suffit souvent quand le volume est faible, les jobs sont courts et vous tolérez quelques retries. C'est facile à mettre en place, simple à inspecter et tout reste au même endroit. Exemple : un admin lance un rapport nocturne pour une petite équipe. Si ça réessaie une fois, personne ne panique.
Vous aurez généralement besoin d'un système de file dédié quand le débit augmente, les jobs deviennent lourds ou la fiabilité est indispensable. Les imports, le traitement vidéo, les notifications massives et tout workflow devant survivre aux redémarrages bénéficient d'une plus grande isolation, visibilité et de retries plus sûrs. Cela compte pour la progression visible par l'utilisateur, car les gens remarquent les mises à jour manquantes et les états bloqués.
La structure des files affecte aussi les priorités. Une seule file est plus simple, mais mélanger travail rapide et lent peut rendre les actions rapides lentes. Des files séparées aident quand vous avez du travail déclenché par l'utilisateur qui doit sembler instantané à côté d'un batch planifié qui peut attendre.
Fixez des limites de concurrence volontairement. Trop de parallélisme peut surcharger la base et donner une progression saccadée. Trop peu rend le système lent. Commencez avec une faible concurrence prévisible par file, puis augmentez seulement si vous pouvez maintenir des temps de complétion stables.
Concevoir un modèle de progression affichable dans l'UI
Si votre modèle de progression est vague, l'UI le sera aussi. Décidez ce que le système peut honnêtement rapporter, à quelle fréquence cela change et ce que les utilisateurs doivent faire avec cette information.
Un schéma simple que la plupart des jobs peuvent supporter ressemble à ceci :
- state : queued, running, succeeded, failed, canceled
- percent : 0–100 lorsque mesurable
- message : une phrase courte que l'utilisateur comprend
- timestamps : created, started, last_updated, finished
- result_summary : comptes comme processed, skipped, errors
Ensuite, définissez ce que signifie « progression ».
Le pourcentage marche quand il existe un dénominateur réel (lignes d'un fichier, emails à envoyer). Il est trompeur quand le travail est imprévisible (attente d'un tiers, calcul variable, requêtes coûteuses). Dans ces cas, une progression par étapes inspire plus de confiance car elle avance par morceaux clairs.
Règle pratique :
- Utilisez percent quand vous pouvez rapporter « X of Y ».
- Utilisez des steps quand la durée est inconnue (Validate file, Import, Rebuild indexes, Finalize).
- Utilisez une progression indéterminée quand aucun des deux n'est possible, mais gardez le message vivant.
Enregistrez les résultats partiels pendant l'exécution du job. L'UI pourra ainsi montrer quelque chose d'utile avant la fin, comme un compteur d'erreurs en direct ou un aperçu des modifications. Pour un import CSV, enregistrez rows_read, rows_created, rows_updated, rows_rejected et quelques derniers messages d'erreur.
Ceci est la base pour des tâches en arrière‑plan avec mises à jour de progression que les utilisateurs peuvent croire : l'UI reste calme, les chiffres avancent et le résumé « que s'est‑il passé ? » est prêt à la fin.
Livraison des mises à jour de progression : polling, push et hybride
Rendez l'annulation et la reprise sûres
Implémentez des flags d'annulation, des étapes idempotentes et des états clairs dans un flux visuel.
Faire remonter la progression du backend vers l'écran est souvent l'endroit où les implémentations échouent. Choisissez une méthode qui correspond à la fréquence des changements et au nombre d'utilisateurs qui regarderont.
Le polling est le plus simple : l'UI demande le statut toutes les N secondes. Un bon défaut est 2 à 5 secondes pendant que l'utilisateur regarde, puis s'atténuer avec le temps. Si le job dure plus d'une minute, passez à 10–30 secondes. Si l'onglet est en arrière‑plan, ralentissez encore.
Les pushs (WebSockets, server‑sent events ou notifications mobiles) sont utiles quand la progression change vite ou que l'utilisateur tient à une information « immédiate ». Le push est excellent pour l'immédiateté, mais il faut toujours un fallback quand la connexion tombe.
Une approche hybride fonctionne souvent le mieux : pollez vite au début (pour voir rapidement queued → running), puis ralentissez quand le job est stable. Si vous ajoutez du push, conservez un polling lent en filet de sécurité.
Quand les mises à jour s'arrêtent, traitez‑le comme un état à part entière. Affichez « Dernière mise à jour il y a 2 minutes » et proposez un rafraîchissement. Côté backend, marquez les jobs comme stale s'ils n'ont pas envoyé de heartbeat.
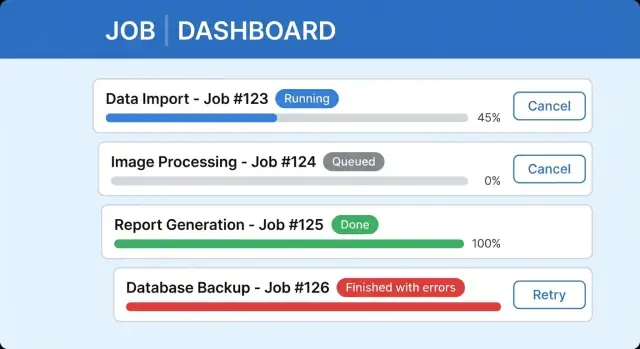
Modèles UI pour des tâches longues qui semblent claires
La clarté vient de deux choses : un petit ensemble d'états prévisibles et un texte qui dit à l'utilisateur ce qui va se passer ensuite.
Nommez les états dans l'UI, pas seulement dans le backend. Un job peut être queued (en attente), running (en cours), waiting for input (attend un choix), completed, completed with errors ou failed. Si les utilisateurs ne savent pas les distinguer, ils penseront que l'app est bloquée.
Placez un texte simple et utile à côté de l'indicateur de progression. « Importing 3,200 rows (1,140 processed) » est préférable à « Processing. » Ajoutez une phrase qui répond : puis‑je partir et que se passera‑t‑il ? Par exemple : « Vous pouvez fermer cette fenêtre. Nous continuerons l'import en arrière‑plan et vous préviendrons quand ce sera prêt. »
Là où la progression s'affiche doit correspondre au contexte de l'utilisateur :
- Un modal quand la tâche bloque l'étape suivante (par ex. générer un PDF de facture nécessaire maintenant).
- Un toast pour des tâches rapides qui ne doivent pas interrompre.
- Un indicateur inline dans une ligne de tableau pour des opérations par‑élément.
Pour tout ce qui dépasse une minute, ajoutez une page Jobs simple (ou panneau Activité) afin que les gens puissent retrouver le travail plus tard.
Une UI claire pour une tâche longue inclut généralement une étiquette de statut avec la dernière mise à jour, une barre de progression (ou des étapes) avec une ligne de détail, un comportement d'Annuler sûr et une zone de résultats avec résumé et action suivante. Gardez les jobs terminés faciles à retrouver pour que l'utilisateur ne soit pas forcé d'attendre sur un écran.
Annoncer « terminé avec des erreurs » sans embrouiller les utilisateurs
Prévenez les importations en double
Retournez instantanément des IDs de job et suivez les exécutions pour éviter les ré‑importations.
« Terminé » n'est pas toujours une victoire. Quand un job traite 9 500 enregistrements et que 120 échouent, l'utilisateur doit comprendre ce qui s'est passé sans lire des logs.
Traitez le succès partiel comme un résultat à part entière. Dans la ligne principale, montrez les deux côtés : « Imported 9,380 of 9,500. 120 failed. » Cela maintient la confiance car le système est honnête et confirme que du travail a été enregistré.
Ensuite, affichez un petit résumé d'erreurs actionnable : « Missing required field (63) » et « Invalid date format (41) ». À l'état final, « Completed with issues » est souvent plus clair que « Failed », parce que cela n'implique pas que rien n'a fonctionné.
Un rapport d'erreurs exportable transforme la confusion en liste de tâches. Restez simple : identifiant de ligne ou d'item, catégorie d'erreur, message lisible et nom du champ si pertinent.
Rendez l'action suivante évidente et proche du résumé : corriger les données et réessayer les éléments échoués, télécharger le rapport d'erreurs ou contacter le support si cela ressemble à un problème système.
Annuler et réessayer de façon fiable
Annuler et réessayer semblent simples, mais ils détruisent rapidement la confiance si l'UI dit une chose et le système en fait une autre. Définissez ce que Cancel signifie pour chaque type de job, puis reflétez‑le honnêtement dans l'interface.
Il y a généralement deux modes d'annulation valides :
- « Stop now » : le worker vérifie souvent un flag d'annulation et sort rapidement.
- « Stop after this step » : l'étape en cours se termine, puis le job s'arrête avant l'étape suivante.
Dans l'UI, montrez un état intermédiaire comme « Cancel requested » pour éviter que les utilisateurs cliquent sans cesse.
Rendez l'annulation sûre en concevant le travail pour qu'il soit répétable. Si un job écrit des données, préférez les opérations idempotentes (sécures à exécuter plusieurs fois) et faites des nettoyages si nécessaire. Par exemple, pour un import CSV qui crée des enregistrements, enregistrez un job‑run ID pour pouvoir revoir ce qui a changé dans l'exécution n°123.
La reprise (Retry) nécessite la même clarté. Reprendre la même instance de job a du sens quand elle peut reprendre. Créer une nouvelle instance est plus sûr quand on veut un run propre avec un nouveau timestamp et une piste d'audit. Dans tous les cas, expliquez ce qui sera refait et ce qui ne le sera pas.
Garde‑fous pour que l'annulation et la reprise restent prévisibles :
- Limitez les retries et affichez le compte.
- Empêchez les doublons en désactivant Retry tant qu'un job est en cours.
- Demandez confirmation quand réessayer peut dupliquer des effets secondaires (emails, paiements, exports).
- Affichez la dernière erreur et la dernière étape réussie dans un panneau de détails.
Pas à pas : un flux de bout en bout du clic à la complétion
Livrez une UI d'import CSV
Combinez le traitement backend et une carte de progression UI dans le même projet AppMaster.
Un bon flux de bout en bout commence par une règle : l'UI ne doit jamais attendre le travail lui‑même. Elle doit n'attendre qu'un ID de job.
Le flux (du clic utilisateur à l'état final)
-
L'utilisateur lance la tâche, l'API répond vite. Quand l'utilisateur clique sur Import ou Generate report, votre serveur crée immédiatement un enregistrement de job et renvoie un ID unique.
-
Enfilez le travail et définissez le premier statut. Mettez l'ID de job dans une file et réglez le statut sur queued avec progress 0 %. L'UI a ainsi quelque chose de concret à afficher avant qu'un worker ne prenne le job.
-
Le worker exécute et rapporte la progression. Quand un worker démarre, mettez le statut sur running, enregistrez une heure de début et mettez à jour la progression par petits bonds honnêtes. Si vous ne pouvez pas mesurer un pourcentage, affichez des étapes comme Parsing, Validating, Saving.
-
L'UI garde l'utilisateur orienté. L'UI poll ou s'abonne aux mises à jour et rend les états clairement. Affichez un court message (ce qui se passe maintenant) et seulement les actions pertinentes dans l'instant.
-
Finalisez avec un résultat durable. À la fin, enregistrez le finish time, la sortie (référence de téléchargement, IDs créés, comptes résumés) et les détails d'erreur. Supportez « finished‑with‑errors » comme issue à part, pas comme un vague succès.
Règles d'annulation et de reprise
L'annulation doit être explicite : la requête Cancel demande l'annulation, puis le worker accuse réception et marque canceled. Le retry doit créer un nouvel ID de job, garder l'original en historique et expliquer ce qui sera re‑traité.
Scénario exemple : import CSV avec progression et échecs partiels
Transformez le polling en modèle
Définissez un endpoint de statut simple et un rythme de rafraîchissement UI qui reste réactif.
Un cas commun est l'import CSV. Imaginez un CRM où une personne en ops upload customers.csv avec 8 420 lignes.
Juste après l'upload, l'UI doit passer de « J'ai cliqué sur un bouton » à « un job existe et vous pouvez partir. » Une simple carte de job sur une page Imports fonctionne bien :
- Upload reçu : « Fichier reçu. Validation des colonnes... »
- Queued : « En attente d'un worker disponible (2 jobs devant). »
- Running : « Importing customers : 3 180 of 8 420 processed (38 %). »
- Wrapping up : « Sauvegarde des résultats et génération du rapport... »
Pendant l'exécution, montrez un nombre de progression fiable (lignes traitées) et une courte ligne de statut (ce qu'il fait maintenant). Si l'utilisateur navigue ailleurs, conservez le job visible dans une zone Récents.
Ajoutons maintenant des échecs partiels. À la fin, évitez une bannière Failed si la majorité des lignes a été traitée. Utilisez Finished with issues avec une séparation claire :
Imported 8 102 customers. Skipped 318 rows.
Expliquez les principales raisons en mots simples : format d'email invalide, champ requis manquant comme company, doublons d'IDs externes. Permettez de télécharger ou consulter une table d'erreurs avec le numéro de ligne, le nom et le champ exact à corriger.
Retry doit être sûr et ciblé. L'action primaire peut être Retry failed rows, créant un nouveau job qui ne re‑traite que les 318 lignes ignorées après correction. Conservez le job original en lecture seule pour garder l'historique fidèle.
Enfin, facilitez la recherche des résultats plus tard. Chaque import devrait avoir un résumé stable : qui l'a lancé, quand, nom du fichier, comptes (imported, skipped) et un moyen d'ouvrir le rapport d'erreurs.
Erreurs courantes qui embrouillent la progression et les retries
La façon la plus rapide de perdre la confiance est d'afficher des chiffres qui ne sont pas réels. Une barre à 0 % pendant deux minutes puis un saut à 90 % donne l'impression d'un coup de bluff. Si vous ne connaissez pas le vrai pourcentage, montrez des étapes (Queued, Processing, Finalizing) ou « X of Y items processed ».
Un autre problème fréquent est de stocker la progression seulement en mémoire. Si le worker redémarre, l'UI « oublie » le job ou réinitialise la progression. Sauvegardez l'état du job dans un stockage durable et faites en sorte que l'UI lise depuis cette unique source de vérité.
L'UX du retry casse aussi quand un utilisateur peut lancer plusieurs fois le même job. Si le bouton Import CSV reste actif, quelqu'un clique deux fois et crée des doublons. Les retries deviennent alors confus car on ne sait plus quelle exécution corriger.
Erreurs récurrentes :
- pourcentage factice qui ne correspond pas au travail réel
- dumps d'erreur techniques montrés aux utilisateurs (stack traces, codes)
- pas de gestion des timeouts, doublons ou idempotence
- retry qui crée un nouveau job sans expliquer ce qu'il fera
- annulation qui ne change que l'UI et pas le comportement du worker
Un petit mais important détail : séparez le message utilisateur du détail développeur. Affichez « 12 lignes ont échoué à la validation » à l'utilisateur et conservez la trace technique dans les logs.
Checklist rapide avant de mettre en production des jobs en arrière‑plan
Déployez votre système de jobs partout
Exécutez sur AppMaster Cloud ou exportez le code source pour votre propre infrastructure.
Avant la release, vérifiez les parties que les utilisateurs remarquent : clarté, confiance et récupération.
Chaque job doit exposer un snapshot que vous pouvez afficher partout : state (queued, running, succeeded, failed, canceled), progression (0–100 ou étapes), un court message, timestamps (created, started, finished) et un pointeur de résultat (où se trouvent la sortie ou le rapport).
Rendez les états UI évidents et cohérents. Les utilisateurs ont besoin d'un endroit fiable pour trouver les jobs actuels et passés, plus des étiquettes claires quand ils reviennent ("Completed yesterday", "Still running"). Un panneau Recent jobs évite souvent les clics répétés et le travail en double.
Définissez des règles d'annulation et de reprise en termes simples. Décidez ce que Cancel signifie pour chaque type de job, si le retry est autorisé et ce qui est réutilisé (mêmes inputs, nouvel ID). Testez ensuite les cas limites comme annuler juste avant la complétion.
Considérez les échecs partiels comme un véritable résultat. Affichez un court résumé ("Imported 97, skipped 3") et fournissez un rapport actionnable que l'utilisateur peut utiliser immédiatement.
Planifiez la récupération. Les jobs doivent survivre aux redémarrages, et les jobs bloqués doivent aboutir à un état clair avec des conseils ("Réessayer" ou "Contacter le support avec l'ID du job").
Prochaines étapes : implémenter un workflow puis étendre
Choisissez un workflow dont les utilisateurs se plaignent déjà : imports CSV, exports de rapports, envois massifs d'emails ou traitement d'images. Commencez petit et prouvez les bases : un job est créé, il s'exécute, il rapporte son statut et l'utilisateur peut le retrouver plus tard.
Une simple page d'historique des jobs est souvent le plus grand gain de qualité. Elle donne aux gens un endroit où revenir au lieu de fixer un spinner.
Choisissez d'abord une méthode de livraison de progression. Le polling suffit pour une v1. Réglez l'intervalle pour être gentil avec le backend, mais assez rapide pour sembler vivant.
Un ordre pratique de construction pour éviter les réécritures :
- implémentez d'abord les états et transitions de job (queued, running, succeeded, failed, finished-with-errors)
- ajoutez une page d'historique des jobs avec des filtres basiques (24 dernières heures, seulement mes jobs)
- ajoutez des nombres de progression seulement quand vous pouvez les garder honnêtes
- ajoutez l'annulation seulement après garantir un nettoyage cohérent
- ajoutez le retry seulement quand le job est idempotent
Si vous construisez sans écrire de code, une plateforme no‑code comme AppMaster peut aider en vous permettant de modéliser une table de statut de job (PostgreSQL) et de la mettre à jour depuis des workflows, puis d'afficher ce statut sur web et mobile. Pour les équipes voulant un endroit unique pour construire backend, UI et logique en arrière‑plan, AppMaster (appmaster.io) est conçu pour des applications complètes, pas seulement des formulaires ou des pages.
FAQ
Un job en arrière‑plan démarre rapidement et retourne immédiatement un ID de job, ce qui permet à l'interface de rester utilisable. Une requête lente force l'utilisateur à attendre la même requête web jusqu'à la fin, ce qui entraîne des rafraîchissements, des doubles clics et des soumissions en double.
Gardez‑le simple : queued, running, done et failed, plus canceled si vous supportez l'annulation. Ajoutez un résultat séparé comme « done with issues » lorsque la majorité du travail a réussi mais que certains éléments ont échoué, afin que l'utilisateur ne pense pas que tout est perdu.
Retournez immédiatement un ID de job unique après que l'utilisateur lance l'action, puis affichez une ligne ou une carte de tâche utilisant cet ID. L'interface doit lire le statut par ID de job pour que l'utilisateur puisse rafraîchir, changer d'onglet ou revenir plus tard sans perdre la trace.
Stockez le statut du job dans une table de base de données durable, pas seulement en mémoire. Sauvegardez l'état courant, les timestamps, la valeur de progression, un court message utilisateur et un résumé de résultat ou d'erreur afin que l'interface puisse toujours reconstruire la même vue après un redémarrage.
Utilisez le pourcentage uniquement quand vous pouvez honnêtement rapporter « X de Y ». Si vous ne pouvez pas mesurer un véritable dénominateur, montrez une progression par étapes comme « Validating », « Importing », « Finalizing » et gardez le message à jour pour que l'utilisateur perçoive un avancement.
Le polling est le plus simple et fonctionne bien pour la plupart des applications : commencez autour de 2–5 secondes pendant que l'utilisateur regarde, puis ralentissez pour les jobs longs ou les onglets en arrière‑plan. Les pushs donnent une immédiateté, mais prévoyez toujours un fallback car les connexions tombent et les utilisateurs changent d'écran.
Affichez que les mises à jour sont anciennes au lieu de faire comme si le job était toujours actif, par exemple « Dernière mise à jour il y a 2 minutes », et proposez un rafraîchissement manuel. Côté backend, détectez les heartbeats manquants et basculez le job dans un état clair avec des consignes, comme retenter ou contacter le support avec l'ID du job.
Indiquez clairement si l'utilisateur peut continuer son travail, quitter la page ou annuler en toute sécurité. Pour les tâches de plus d'une minute, une vue Jobs ou Activité dédiée aide l'utilisateur à retrouver les résultats plus tard au lieu de rester bloqué devant un seul spinner.
Traitez‑le comme un résultat à part entière et affichez les deux côtés clairement, par exemple « Imported 9,380 of 9,500. 120 failed. ». Fournissez ensuite un petit résumé d'erreurs actionnable que l'utilisateur peut corriger sans lire les logs, et conservez les détails techniques dans les journaux internes plutôt qu'à l'écran.
Définissez ce que signifie Annuler pour chaque type de job et affichez‑le honnêtement, y compris un état intermédiaire « cancel requested » pour éviter les clics répétés. Rendez le travail idempotent quand c'est possible, limitez les tentatives, et décidez si la reprise reprend le même job ou crée un nouvel ID avec une piste d'audit propre.