19 févr. 2025·8 min de lecture
Politiques de rétention des données pour applications professionnelles : fenêtres et workflows
Apprenez à concevoir des politiques de rétention pour applications professionnelles avec des fenêtres claires, de l’archivage, et des flux de suppression ou d’anonymisation qui préservent la valeur des rapports.
Quel problème une politique de rétention résout-elle réellement
Une politique de rétention est un ensemble clair de règles que votre app suit concernant les données : ce que vous conservez, combien de temps vous le conservez, où elles résident et ce qui se passe quand le délai est atteint. L’objectif n’est pas de « tout supprimer ». C’est de garder ce dont vous avez besoin pour faire fonctionner l’entreprise et expliquer des événements passés, tout en supprimant ce dont vous n’avez plus besoin.
Sans plan, trois problèmes apparaissent rapidement. Le stockage augmente discrètement jusqu’à coûter de l’argent. Le risque pour la vie privée et la sécurité augmente avec chaque copie supplémentaire de données personnelles. Et les rapports deviennent peu fiables quand d’anciens enregistrements ne correspondent plus à la logique actuelle, ou quand des personnes suppriment des éléments au coup par coup et que les tableaux de bord changent soudainement.
Une politique de rétention pratique équilibre opérations quotidiennes, preuves, et protection des clients :
- Opérations : les personnes peuvent encore faire leur travail.
- Preuve : vous pouvez expliquer une transaction plus tard.
- Clients : vous ne gardez pas de données personnelles plus longtemps que nécessaire.
La plupart des applications professionnelles ont les mêmes grandes zones de données, même si elles portent des noms différents : profils d’utilisateurs, transactions, journaux d’audit, messages et fichiers uploadés.
Une politique est en partie règles, en partie workflow, en partie outils. La règle peut dire « conserver les tickets de support pendant 2 ans ». Le workflow définit ce que cela signifie en pratique : déplacer les tickets plus anciens vers une zone d’archive, anonymiser les champs clients et enregistrer ce qui s’est passé. L’outillage rend cela répétable et auditable.
Si vous construisez votre app sur AppMaster, considérez la rétention comme un comportement produit, pas comme un nettoyage ponctuel. Les Business Processes planifiés peuvent archiver, supprimer ou anonymiser les données de la même manière à chaque exécution, donc les rapports restent cohérents et les gens font confiance aux chiffres.
Contraintes à clarifier avant de choisir des fenêtres temporelles
Avant de fixer des dates, clarifiez pourquoi vous conservez des données. Les décisions de rétention sont généralement dictées par les lois sur la vie privée, les contrats clients, et les règles d’audit ou fiscales. Sautez cette étape et vous garderez soit trop (plus de risques et de coûts), soit vous supprimerez quelque chose dont vous aurez ensuite besoin.
Commencez par séparer « must keep » de « nice to have ». Les données à garder absolument comprennent souvent les factures, les écritures comptables et les logs d’audit nécessaires pour prouver qui a fait quoi et quand. Les données « agréables à avoir » peuvent être d’anciens transcripts de chat, des historiques de clics détaillés ou des logs d’événements bruts utilisés seulement pour des analyses occasionnelles.
Les exigences varient aussi selon le pays et l’industrie. Un portail de support pour un fournisseur de santé a des contraintes très différentes d’un outil d’administration B2B. Même au sein d’une entreprise, des utilisateurs dans plusieurs pays peuvent signifier des règles différentes pour le même type d’enregistrement.
Rédigez les décisions en langage clair et assignez un responsable. « Nous gardons les tickets 24 mois » ne suffit pas. Définissez ce qui est inclus, ce qui est exclu, et ce qui se passe à la fin de la fenêtre (archiver, anonymiser, supprimer). Mettez une personne ou une équipe responsable pour que les mises à jour ne stagnent pas quand les produits ou les lois changent.
Obtenez des validations tôt, avant que l’ingénierie ne construise quoi que ce soit. Le juridique confirme les minima et obligations de suppression. La sécurité confirme les risques, contrôles d’accès et journaux. Le produit confirme ce que les utilisateurs ont encore besoin de voir. La finance confirme les besoins de tenue de registre.
Exemple : vous pourriez garder les relevés de facturation 7 ans, garder les tickets 2 ans, et anonymiser les champs de profil utilisateur après la fermeture du compte tout en conservant des métriques agrégées. Dans AppMaster, ces règles écrites peuvent se mapper proprement à des processus planifiés et des accès basés sur les rôles, avec moins d’ambiguïté plus tard.
Cartographiez vos données par type, sensibilité et emplacement
Les politiques de rétention échouent quand les équipes décident « garder 2 ans » sans savoir ce que « ça » inclut. Construisez une carte simple des données que vous avez. Ne visez pas la perfection. Visez quelque chose qu’un lead support et un lead finance peuvent tous les deux comprendre.
Classer par type et sensibilité
Un jeu de départ pratique :
- Données client : profils, tickets, commandes, messages
- Données employé : dossiers RH, logs d’accès, infos dispositifs
- Données opérationnelles : workflows, événements système, journaux d’audit
- Données financières : factures, paiements, champs fiscaux
- Contenu et fichiers : uploads, exports, pièces jointes
Puis marquez la sensibilité en termes clairs : données personnelles (nom, email), financières (coordonnées bancaires, tokens de paiement), identifiants (hashs de mot de passe, clés API), ou données régulées (par exemple informations de santé). Si vous n’êtes pas sûr, étiquetez « potentiellement sensible » et traitez-les avec précaution jusqu’à confirmation.
Cartographier où elles résident et qui en dépend
« Où elles résident » dépasse généralement la base de données principale. Notez l’emplacement exact : tables de base de données, stockage de fichiers, logs email/SMS, outils analytics ou entrepôts de données. Notez aussi qui dépend de chaque jeu de données (support, ventes, finance, direction) et à quelle fréquence. Cela vous indique ce qui cassera si vous supprimez trop agressivement.
Une habitude utile : documentez l’objectif de chaque jeu de données en une phrase. Exemple : « Les tickets de support sont conservés pour résoudre les litiges et suivre les tendances de temps de réponse. »
Si vous construisez avec AppMaster, vous pouvez aligner cet inventaire avec ce qui est réellement déployé en revoyant vos modèles Data Designer, la gestion des fichiers et les intégrations activées.
Une fois la carte en place, la rétention devient une série de petits choix clairs plutôt qu’un grand pari unique.
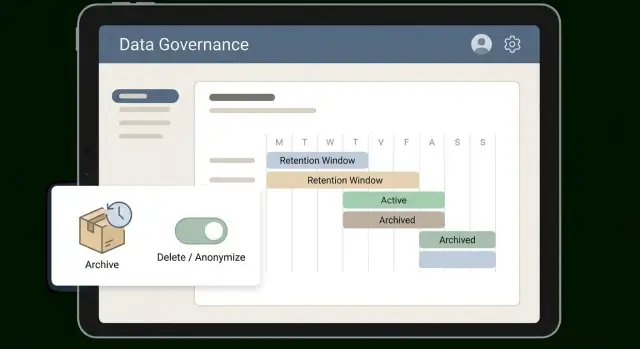
Une fenêtre ne fonctionne que si elle est facile à expliquer et encore plus facile à appliquer. Beaucoup d’équipes s’en sortent bien avec des paliers simples qui correspondent à l’usage des données : hot (utilisé quotidiennement), warm (utilisé parfois), cold (conservé comme preuve), puis suppression ou anonymisation. Ces paliers transforment une politique abstraite en routine.
Fixez des fenêtres par catégorie, pas un chiffre global. Les factures et enregistrements de paiement nécessitent généralement une longue période cold pour la fiscalité et l’audit. Les transcripts de support perdent souvent de la valeur rapidement.
Décidez aussi de ce qui déclenche le compte à rebours. « Garder 2 ans » est vide de sens à moins de définir « 2 ans depuis quoi ». Choisissez un déclencheur par catégorie, comme la date de création, la dernière activité client, la date de clôture du ticket, ou la fermeture du compte. Si les déclencheurs varient sans règles claires, les gens devineront et la rétention dérivera.
Rédigez les exceptions à l’avance pour que les équipes n’improvisent pas plus tard. Les exceptions courantes incluent blocage légal, rétrofacturation et enquêtes sur la fraude. Celles-ci doivent suspendre la suppression. Elles ne doivent pas créer de copies cachées.
Gardez les règles finales courtes et testables :
- Chats de support : anonymiser 6 mois après le dernier message sauf blocage légal
- Leads marketing : supprimer 12 mois après la dernière activité si aucun contrat n’existe
- Comptes clients : supprimer 30 jours après fermeture ; garder les factures 7 ans
- Logs de sécurité : garder 90 jours en hot, 12 mois en cold pour les enquêtes
- Tout enregistrement marqué
legal_hold=true : ne pas supprimer tant que la levée n’est pas effectuée
Stratégies d’archivage qui gardent les données utiles et moins coûteuses
Faites de la rétention une partie du produit
Intégrez des outils internes qui appliquent les règles de rétention dans l'app, pas dans des scripts de nettoyage ad hoc.
Une archive n’est pas une sauvegarde. Les backups servent à la récupération après erreurs ou pannes. Les archives sont délibérées : des données anciennes quittent vos tables hot et vont vers un stockage moins cher, mais restent disponibles pour audits, litiges et questions historiques.
La plupart des apps ont besoin des deux. Les backups sont fréquents et larges. Les archives sont sélectives et contrôlées, et vous ne récupérez généralement que ce dont vous avez besoin.
Choisissez un stockage moins cher mais toujours consultable
Un stockage moins cher n’aide que si les gens peuvent encore trouver ce dont ils ont besoin. Beaucoup d’équipes utilisent une base séparée ou un schéma optimisé pour les requêtes en lecture, ou exportent en fichiers plus une table d’index pour recherche. Si votre app est modélisée autour de PostgreSQL (y compris dans AppMaster), un schéma « archive » ou une base séparée peut garder les tables de production rapides tout en permettant des rapports autorisés sur les données archivées.
Avant de choisir le format, définissez ce que « consultable » signifie pour votre activité. Le support peut avoir besoin de rechercher par email ou ID de ticket. La finance peut avoir besoin de totaux par mois. Les audits peuvent nécessiter une traçabilité par ID de commande.
Décidez quoi archiver : enregistrements complets ou résumés
Les enregistrements complets préservent le détail, mais coûtent plus et augmentent le risque vie privée. Les résumés (totaux mensuels, comptes, changements d’état clés) sont moins coûteux et souvent suffisants pour le reporting.
Une approche pratique :
- Archivez les enregistrements complets pour les objets critiques d’audit (factures, remboursements, logs d’accès)
- Archivez des résumés pour des événements à fort volume (clics, vues de page, pings de capteurs)
- Gardez un petit échantillon de référence en hot (souvent les 30–90 derniers jours)
Planifiez les champs d’index à l’avance. Les plus communs : ID primaire, ID utilisateur/client, un bucket de date (mois), région et statut. Sans ces champs, les données archivées existent mais deviennent pénibles à récupérer.
Définissez aussi des règles de restauration : qui peut demander une restauration, qui l’approuve, où les données restaurées atterrissent, et les délais attendus. La restauration peut être lente volontairement si cela réduit le risque, mais elle doit rester prévisible.
Suppression vs anonymisation : choisir la bonne approche
Automatisez la rétention dans votre app
Modélisez les règles de rétention comme des champs de cycle de vie et exécutez-les selon un calendrier sans code personnalisé.
Les politiques de rétention imposent souvent un choix : supprimer des enregistrements, ou les conserver en supprimant les détails personnels. Les deux peuvent être appropriés, mais ils résolvent des problèmes différents.
La suppression hard efface physiquement l’enregistrement. Elle convient quand vous n’avez aucune raison légale ou commerciale de garder la donnée et que la conserver augmente le risque (par exemple, d’anciens transcripts de chat contenant des détails sensibles).
Le soft delete conserve la ligne mais la marque comme supprimée (souvent avec un timestamp deleted_at) et la cache des écrans et APIs normaux. Le soft delete est utile quand les utilisateurs s’attendent à une restauration ou quand des systèmes en aval pourraient encore référencer l’enregistrement. L’inconvénient est que les données soft-deleted existent toujours, consomment du stockage et peuvent fuir via des exports si vous n’y prêtez pas attention.
L’anonymisation conserve l’événement ou la transaction mais supprime ou remplace tout ce qui peut identifier une personne. Bien faite, l’anonymisation est irréversible. La pseudonymisation est différente : vous remplacez des identifiants (comme l’email) par un token mais conservez un mapping séparé qui permet la ré-identification. Cela aide pour les enquêtes frauduleuses, mais ce n’est pas de l’anonymat.
Soyez explicite sur les données liées, car c’est là que les politiques échouent. Supprimer un enregistrement en laissant des pièces jointes, miniatures, caches, index de recherche ou copies analytics peut discrètement contrecarrer tout l’objectif.
Vous avez aussi besoin d’une preuve que la suppression a eu lieu. Gardez un simple reçu de suppression : ce qui a été supprimé ou anonymisé, quand le job a tourné, quel workflow l’a exécuté, et s’il a réussi. Dans AppMaster, cela peut être un Business Process qui écrit une entrée d’audit quand le job se termine.
Les rapports cassent quand vous supprimez ou anonymisez des enregistrements que vos tableaux de bord attendent de joindre au fil du temps. Avant de changer quoi que ce soit, notez les chiffres qui doivent rester comparables mois après mois. Sinon vous passerez votre temps à déboguer « pourquoi le graphique de l’année dernière a changé ? » après coup.
Commencez par une courte liste de métriques à conserver :
- Revenu et remboursements par jour, semaine, mois
- Usage produit : utilisateurs actifs, nombre d’événements, adoption des fonctionnalités
- SLA : temps de réponse, temps de résolution, uptime
- Entonnoir et taux de conversion
- Volume support : tickets, catégories, âge du backlog
Ensuite, repensez ce que vous stockez pour le reporting afin d’éviter les identifiants personnels. L’approche la plus sûre est l’agrégation. Plutôt que de garder chaque ligne brute indéfiniment, conservez des totaux journaliers, des cohortes hebdomadaires et des comptes qui ne peuvent pas être tracés jusqu’à une personne. Par exemple, conservez « tickets créés par jour par catégorie » et « temps de première réponse médian par semaine » même si vous supprimez ensuite le contenu original du ticket.
Garder des clés analytiques stables sans conserver d’identités
Certaines analyses ont encore besoin d’un moyen stable de regrouper le comportement dans le temps. Utilisez une clé analytique de substitution qui n’est pas directement identifiable (par exemple un UUID aléatoire utilisé uniquement pour l’analytics), et supprimez ou verrouillez tout mapping vers l’ID utilisateur réel une fois la fenêtre de rétention passée.
Séparez aussi les tables opérationnelles des tables de reporting quand vous le pouvez. Les données opérationnelles changent et sont supprimées. Les tables de reporting devraient être des snapshots append-only ou des agrégats.
Définir ce qui change après anonymisation
L’anonymisation a des conséquences. Documentez ce qui changera pour que les équipes ne soient pas surprises :
- Les analyses à l’échelle utilisateur peuvent cesser après une certaine date
- Les segments historiques peuvent devenir « inconnu » si des attributs sont supprimés
- La déduplication peut changer si vous retirez email ou téléphone
- Certains audits peuvent encore nécessiter des timestamps et des IDs non personnels
Si vous construisez dans AppMaster, traitez l’anonymisation comme un workflow : écrivez d’abord les agrégats, vérifiez les sorties de reporting, puis anonymisez les champs dans les enregistrements sources.
Étape par étape : implémentez la politique comme de vrais workflows
Construisez un portail prêt pour la rétention
Lancez un portail client avec des cycles de vie de données prévisibles, traçabilité et rapports stables.
Une politique de rétention fonctionne seulement quand elle devient un comportement logiciel normal. Traitez-la comme toute autre fonctionnalité : définissez les entrées, définissez les actions, et rendez les résultats visibles.
Commencez par une matrice d’une page. Pour chaque type de données, notez la fenêtre de rétention, le déclencheur et ce qui se passe ensuite (conserver, archiver, supprimer, anonymiser). Si les gens ne peuvent pas l’expliquer en une minute, elle ne sera pas suivie.
Ajoutez des états de cycle de vie clairs pour que les enregistrements ne « disparaissent » pas mystérieusement. La plupart des apps s’en sortent avec trois états : actif, archivé et en attente de suppression. Stockez l’état sur l’enregistrement lui-même, pas seulement dans un tableur.
Une séquence d’implémentation pratique :
- Créez la matrice de rétention et placez-la là où produit, juridique et ops peuvent la trouver.
- Ajoutez des champs de cycle de vie (statut plus dates comme
archived_at et delete_after) et mettez à jour écrans et APIs pour les respecter.
- Implémentez des jobs planifiés (quotidien est courant) : un job archive, un autre purge ou anonymise ce qui est passé la deadline.
- Ajoutez un chemin d’exception : qui peut mettre en pause la suppression, pour combien de temps, et quelle raison doit être enregistrée.
- Testez sur une copie proche de la production, puis comparez les rapports clés (comptes, totaux, entonnoirs) avant et après.
Exemple : les tickets de support peuvent rester actifs 90 jours, puis passer en archive pendant 18 mois, puis être anonymisés. Le workflow marque les tickets comme archivés, déplace les grosses pièces jointes vers un stockage moins cher, garde les IDs et timestamps, et remplace noms et emails par des valeurs anonymes.
Dans AppMaster, les états de cycle de vie peuvent vivre dans Data Designer, et la logique d’archive/purge peut s’exécuter comme Business Processes planifiés. L’objectif est des exécutions répétables avec des logs clairs faciles à auditer.
Erreurs courantes qui provoquent perte de données ou rapports cassés
La plupart des échecs de rétention ne viennent pas du choix de la fenêtre. Ils surviennent quand la suppression touche les mauvaises tables, oublie des fichiers liés, ou modifie des clés dont les rapports dépendent.
Un scénario courant : l’équipe support supprime « d’anciens tickets » mais oublie les pièces jointes stockées dans une table séparée ou un file store. Plus tard, un auditeur demande la preuve d’un remboursement. Le texte du ticket existe, mais les captures d’écran ont disparu.
Autres pièges fréquents :
- Supprimer un enregistrement principal tout en laissant des tables secondaires (pièces jointes, commentaires, logs d’audit) orphelines
- Purger des événements bruts dont la finance, la sécurité ou la conformité a encore besoin pour rapprocher des totaux
- S’appuyer indéfiniment sur le soft delete, ce qui fait grossir la base et permet aux données supprimées d’apparaître encore dans des exports
- Changer des identifiants lors de l’anonymisation (comme
user_id) sans mettre à jour dashboards, jointures et requêtes sauvegardées
- Ne pas avoir de propriétaire pour les exceptions et les blocages légaux, ce qui pousse les gens à contourner les règles
Une autre casse fréquente concerne les rapports construits sur des clés liées à la personne. Écraser le nom et l’email va souvent, mais remplacer l’ID interne peut scinder silencieusement l’historique d’une même personne en plusieurs identités, et des métriques comme les MAU ou le lifetime value dériveront.
Deux corrections aident la plupart des équipes. D’abord, définissez des clés de reporting stables qui ne changent jamais (par exemple un ID de compte interne) et gardez-les séparées des champs personnels qui seront anonymisés ou supprimés. Ensuite, implémentez la suppression comme un workflow complet qui parcourt toutes les données liées, y compris fichiers et logs. Dans AppMaster, cela se mappe souvent à un Business Process qui part d’un utilisateur ou d’un compte, collecte les dépendances, puis supprime ou anonymise dans un ordre sûr.
Enfin, décidez qui peut mettre en pause une suppression pour un blocage légal et comment cette pause est enregistrée. Si personne ne gère les exceptions, la politique sera appliquée de façon inconsistante.
Vérifications rapides avant d’activer quoi que ce soit
Archivez sans casser les recherches
Planifiez des tâches d'archivage qui gardent les tables hot rapides tout en préservant ce dont audits et support ont besoin.
Avant de lancer des jobs de suppression ou d’archivage, faites une vérification de réalité. La plupart des échecs arrivent parce que personne ne sait qui possède les données, où les copies sont stockées, ou comment les rapports en dépendent.
Une politique de rétention a besoin de responsabilités claires et d’un plan testable, pas seulement d’un document.
Checklist pré-lancement
- Assignez un propriétaire pour chaque jeu de données (une personne qui peut approuver les changements et répondre aux questions).
- Confirmez que chaque catégorie de données a une fenêtre de rétention et un déclencheur (exemple : « 90 jours après la clôture du ticket » ou « 2 ans après la dernière connexion »).
- Prouvez que vous pouvez retrouver le même enregistrement partout où il apparaît : base de données, stockage de fichiers, exports, logs, copies analytics et backups.
- Vérifiez que les archives restent utiles : gardez des champs minimaux pour recherche et jointures (IDs, dates, statut) et documentez ce qui est supprimé.
- Assurez-vous de pouvoir produire des preuves : ce qui a été supprimé ou anonymisé, quand cela a été exécuté, et quelle règle a été suivie.
Une validation simple est une exécution à blanc : prenez un petit lot (par exemple les anciens cas d’un client), exécutez le workflow dans un environnement de test, puis comparez les rapports clés avant et après.
À quoi doit ressembler la « preuve »
Stockez la preuve d’une façon qui ne réintroduit pas de données personnelles :
- Logs des runs de jobs avec horodatages, nom de règle et comptes
- Une table d’audit immuable avec les IDs d’enregistrement et l’action effectuée (supprimé ou anonymisé)
- Une courte liste d’exception pour les éléments sous blocage légal
- Un snapshot de rapport montrant les métriques que vous attendez rester stables
Si vous construisez sur AppMaster, ces vérifications se traduisent directement en implémentation : champs de rétention dans Data Designer, jobs planifiés dans le Business Process Editor, et sorties d’audit claires.
Exemple : plan de rétention pour un portail client qui conserve la valeur des rapports
Configurez votre matrice de rétention
Cartographiez vos tables et fichiers dans Data Designer, puis alignez chaque jeu de données sur des fenêtres de rétention claires.
Imaginez un portail client qui stocke des tickets de support, factures et remboursements, et des logs d’activité bruts (connexions, vues de page, appels API). Le but est de réduire le risque et le coût de stockage sans casser la facturation, les audits ou le reporting des tendances.
Commencez par séparer ce que vous devez garder de ce que vous utilisez juste pour le support quotidien.
Un planning de rétention simple pourrait être :
- Tickets de support : garder le contenu complet 18 mois après clôture
- Factures et enregistrements de paiement : garder 7 ans
- Logs d’activité bruts : garder 30 jours
- Événements d’audit sécurité (changements admin, mises à jour de permissions) : garder 12 mois
Ajoutez une étape d’archive pour les tickets anciens. Plutôt que de garder chaque message indéfiniment dans les tables principales, déplacez les tickets clos de plus de 18 mois dans une zone d’archive avec un petit résumé consultable : ID du ticket, dates, domaine produit, tags, code de résolution et un court extrait de la dernière note agent. Cela garde le contexte sans conserver tous les détails personnels.
Pour les comptes fermés, préférez l’anonymisation à la suppression lorsque vous avez encore besoin de tendances. Remplacez les identifiants personnels (nom, email, adresse) par des tokens aléatoires, mais conservez des champs non-identifiants comme le type d’abonnement et les totaux mensuels. Stockez les métriques d’usage agrégées (DAU, tickets par mois, revenu par mois) dans une table de reporting séparée qui ne contient jamais de données personnelles.
Le reporting mensuel changera, mais il ne devra pas devenir moins fiable si vous l’avez planifié :
- Les tendances de volume de tickets restent intactes car elles proviennent des tags et codes de résolution, pas du texte complet
- Le reporting de revenu reste stable car les factures sont conservées
- Les tendances long terme d’usage peuvent provenir d’agrégats, pas des logs bruts
- Les cohortes peuvent passer d’identités individuelles à des tokens au niveau compte
Dans AppMaster, les étapes d’archive et d’anonymisation peuvent s’exécuter comme Business Processes planifiés, donc la politique s’exécute de la même façon à chaque fois.
Une politique de rétention fonctionne quand les gens peuvent la suivre et que le système l’applique de façon cohérente. Commencez par une matrice de rétention simple : chaque jeu de données, propriétaire, fenêtre, déclencheur, action suivante (archiver, supprimer, anonymiser) et validation. Revoyez-la avec le juridique, la sécurité, la finance et l’équipe qui gère les tickets client.
N’automatisez pas tout d’un coup. Choisissez un jeu de données de bout en bout, idéalement quelque chose de courant comme les tickets de support ou les logs de connexion. Rendez le workflow réel, exécutez-le pendant une semaine et confirmez que le reporting correspond aux attentes métier. Puis étendez au jeu de données suivant en réutilisant le même schéma.
Rendez l’automatisation observable. La surveillance de base couvre généralement :
- Échecs de jobs (est-ce que l’archive ou la purge a tourné et terminé ?)
- Croissance des archives (tendance de stockage)
- Arriéré de suppression (éléments éligibles mais non traités)
- Dérive des rapports (métriques clés changeant après les runs de rétention)
Planifiez aussi l’aspect utilisateur. Décidez ce que les utilisateurs peuvent demander (export, suppression, correction), qui l’approuve et ce que le système fait. Donnez au support un court script interne : quelles données sont affectées, combien de temps cela prend, et ce qui ne peut pas être récupéré après suppression.
Si vous voulez implémenter cela sans écrire de code personnalisé, AppMaster (appmaster.io) est une solution pratique pour l’automatisation de la rétention car vous pouvez modéliser des champs de cycle de vie dans Data Designer et exécuter des Business Processes planifiés d’archivage et d’anonymisation avec journalisation d’audit. Commencez par un jeu de données, rendez-le fiable, puis reproduisez le schéma sur le reste de l’application.
FAQ
Une politique de rétention empêche la croissance incontrôlée des données et les habitudes risquées du type « gardons tout ». Elle définit des règles prévisibles sur ce que vous conservez, pendant combien de temps, et ce qui se passe à la fin pour que les coûts, les risques liés à la vie privée et les surprises dans les rapports n’augmentent pas avec le temps.
Commencez par pourquoi les données existent et qui en a besoin : opérations, audits/fiscalité, et protection client. Choisissez des fenêtres simples par type de données (factures, tickets, logs, fichiers) et obtenez une validation précoce de la part du juridique, de la sécurité, des finances et du produit pour éviter de construire des workflows qu’il faudra ensuite défaire.
Définissez un déclencheur clair par catégorie, par exemple la date de clôture du ticket, la dernière activité ou la fermeture du compte. Si le déclencheur est flou, différentes équipes l’interpréteront différemment et la rétention dérivera, ce qui fait que « 2 ans » peut signifier cinq choses différentes en pratique.
Utilisez un flag ou un état de blocage légal qui met en pause l'archivage/l'anonymisation/la suppression pour des enregistrements spécifiques, et rendez ce blocage visible et traçable. L’objectif est de suspendre le workflow normal sans créer de copies cachées que personne ne peut suivre ou expliquer plus tard.
Une sauvegarde (backup) sert à la récupération après sinistre ou erreur : elle est large et fréquente. Une archive est un déplacement délibéré de données anciennes hors des tables hot vers un stockage moins cher et contrôlé, mais toujours récupérable pour des audits, litiges ou questions historiques.
Supprimez quand vous n’avez vraiment plus de raison de garder les données et qu’elles présentent un risque en existant. Anonymisez quand vous avez encore besoin de l’événement ou de la transaction pour des tendances ou des preuves, mais pouvez retirer définitivement les champs personnels pour qu’elles ne soient plus liées à une personne.
Le soft delete est utile pour la restauration et pour éviter les références cassées, mais ce n’est pas une suppression réelle. Les lignes soft-deleted occupent toujours de l’espace et peuvent fuiter dans des exports, analytics ou vues admin si chaque requête et workflow ne les filtre pas systématiquement.
Protégez le reporting en stockant des métriques long terme sous forme d’agrégats ou de snapshots qui ne dépendent pas d’identifiants personnels. Si des tableaux de bord font des jointures sur des champs que vous comptez écraser (comme l’email), repensez d’abord le modèle de reporting pour que les graphiques historiques ne changent pas après l’exécution de la rétention.
Considérez la rétention comme une fonctionnalité produit : champs de cycle de vie sur les enregistrements, tâches planifiées pour archiver puis purger/anonymiser, et entrées d’audit qui prouvent ce qui s’est passé. Dans AppMaster, cela se traduit naturellement par des champs dans Data Designer et des Business Processes planifiés qui exécutent la même logique à chaque fois.
Faites une petite exécution à blanc sur un environnement de test proche de la production et comparez les totaux clés avant et après. Vérifiez aussi que vous pouvez tracer un enregistrement partout où il existe (tables, stockage de fichiers, exports, logs) et capturez un reçu de suppression/anonymisation avec horodatages, nom de règle et compteurs.