19 mai 2025·8 min de lecture
pgvector vs base vectorielle managée pour la recherche sémantique
Comparer pgvector et une base vectorielle managée pour la recherche sémantique : effort d’installation, montée en charge, support du filtrage et intégration dans une pile d’app métier typique.
Quel problème la recherche sémantique résout-elle dans une application métier
La recherche sémantique aide les gens à trouver la bonne réponse même s’ils n’utilisent pas les « bons » mots‑clés. Au lieu d’apparier des mots exacts, elle rapproche les sens. Quelqu’un qui tape « réinitialiser ma connexion » devrait quand même voir un article intitulé « Changer votre mot de passe et se reconnecter » parce que l’intention est la même.
La recherche par mots‑clés montre ses limites dans les apps métier parce que les vrais utilisateurs sont incohérents. Ils utilisent des abréviations, font des fautes, confondent des noms de produits et décrivent des symptômes plutôt que des termes officiels. Dans les FAQ, les tickets de support, les docs politiques et les guides d’intégration, le même problème revient sous de nombreuses tournures. Un moteur par mots‑clés retourne souvent rien d’utile, ou une longue liste qui oblige les gens à cliquer partout.
Les embeddings sont le bloc de construction habituel. Votre application transforme chaque document (un article, un ticket, une note produit) en vecteur, une longue liste de nombres qui représente le sens. Quand un utilisateur pose une question, vous embedez aussi la requête et vous cherchez les vecteurs les plus proches. Une « base vectorielle » est simplement l’endroit où vous stockez ces vecteurs et la façon dont vous les interrogez rapidement.
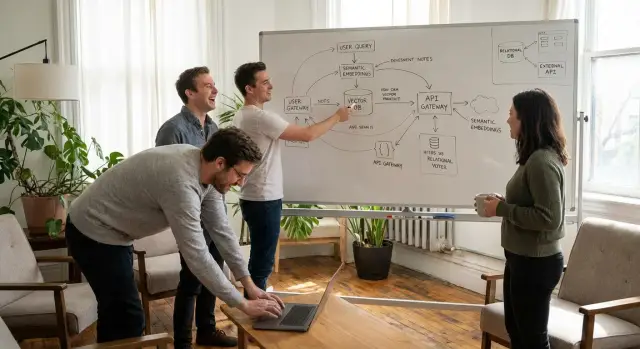
Dans une pile métier typique, la recherche sémantique touche quatre zones : le magasin de contenu (base de connaissances, docs, système de tickets), la pipeline d’embeddings (import et mises à jour quand le contenu change), l’expérience de requête (champ de recherche, réponses suggérées, assist d’agent) et les garde‑fous (permissions et métadonnées comme équipe, client, plan et région).
Pour la plupart des équipes, « suffisamment bon » vaut mieux que parfait. L’objectif pratique est d’obtenir une pertinence au premier essai, des réponses en moins d’une seconde et des coûts prévisibles à mesure que le contenu croît. Cet objectif compte plus que de débattre des outils.
Deux options courantes : pgvector et bases vectorielles managées
La plupart des équipes finissent par choisir entre deux schémas pour la recherche sémantique : tout garder dans PostgreSQL avec pgvector, ou ajouter un service vectoriel managé à côté de votre base principale. Le bon choix dépend moins de « ce qui est meilleur » que de l’endroit où vous voulez que la complexité vive.
pgvector est une extension PostgreSQL qui ajoute un type vectoriel et des index pour stocker des embeddings dans une table normale et exécuter des recherches de similarité avec du SQL. En pratique, votre table de documents peut inclure le texte, des métadonnées (customer_id, status, visibility) et une colonne d’embeddings. La recherche devient « embeder la requête, puis retourner les lignes dont les embeddings sont les plus proches ».
Une base vectorielle managée est un service hébergé conçu surtout pour les embeddings. Elle fournit généralement des API pour insérer des vecteurs et interroger par similarité, ainsi que des fonctionnalités opérationnelles que vous construiriez autrement vous‑même.
Les deux font le même travail de base : stocker des embeddings avec un ID et des métadonnées, trouver les voisins les plus proches pour une requête et retourner les meilleurs matches pour que votre app affiche des éléments pertinents.
La différence clé est le système d’enregistrement. Même si vous utilisez une base vectorielle managée, vous gardez presque toujours PostgreSQL pour les données métiers : comptes, permissions, facturation, état des workflows et journaux d’audit. Le store vectoriel devient une couche de récupération, pas l’endroit où tourne toute l’application.
Une architecture commune ressemble à ceci : gardez l’enregistrement faisant foi dans Postgres, stockez les embeddings soit dans Postgres (pgvector) soit dans le service vectoriel, exécutez une recherche de similarité pour obtenir des IDs correspondants, puis récupérez les lignes complètes depuis Postgres.
Si vous construisez des apps sur une plateforme comme AppMaster, PostgreSQL est déjà un foyer naturel pour les données structurées et les permissions. La question devient si la recherche par embeddings doit y vivre aussi, ou être dans un service spécialisé pendant que Postgres reste la source de vérité.
Effort d’installation : ce qu’il faut réellement faire
Les équipes choisissent souvent en fonction des fonctionnalités puis sont surprises par le travail quotidien. La vraie décision est l’endroit où vous voulez la complexité : dans votre configuration Postgres existante, ou dans un service séparé.
Avec pgvector, vous ajoutez la recherche vectorielle à la base que vous administrez déjà. L’installation est généralement simple, mais c’est toujours du travail de base de données, pas seulement du code applicatif.
Une configuration typique pgvector inclut l’activation de l’extension, l’ajout d’une colonne d’embeddings, la création d’un index adapté à votre modèle de requête (et son tuning ultérieur), la décision de la façon dont les embeddings se mettent à jour quand le contenu change, et l’écriture de requêtes de similarité qui appliquent aussi vos filtres normaux.
Avec une base vectorielle managée, vous créez un nouveau système à côté de votre base principale. Cela peut signifier moins de SQL, mais plus de colle d’intégration.
Une configuration managée typique inclut la création d’un index (dimensions et métrique de distance), l’intégration de clés API dans vos secrets, la construction d’un job d’ingestion pour pousser embeddings et métadonnées, le maintien d’un mapping d’ID stable entre enregistrements applicatifs et enregistrements vectors, et le verrouillage des accès réseau pour que seul votre backend puisse interroger.
Le CI/CD et les migrations diffèrent également. pgvector s’intègre naturellement à vos migrations existantes et à votre processus de review. Les services managés déplacent les changements entre code et paramètres d’admin, donc vous voudrez un processus clair pour les changements de configuration et pour la réindexation.
La propriété suit généralement le choix. pgvector s’appuie sur les devs applicatifs et sur qui que ce soit gérant Postgres (parfois un DBA). Un service managé est souvent détenu par une équipe plateforme, avec les devs applicatifs responsables de l’ingestion et de la logique de requête. C’est pour cela que cette décision porte autant sur la structure de l’équipe que sur la technologie.
Filtrage et permissions : le détail décisif
La recherche sémantique n’aide que si elle respecte ce que l’utilisateur est autorisé à voir. Dans une vraie application métier, chaque enregistrement a des métadonnées à côté de l’embedding : org_id, user_id, rôle, status (open, closed) et visibility (public, internal, private). Si votre couche de recherche ne peut pas filtrer proprement sur ces métadonnées, vous obtiendrez des résultats confus ou, pire, des fuites de données.
La plus grande différence pratique est filtrer avant vs après la recherche vectorielle. Filtrer après paraît simple (tout chercher, puis éliminer les lignes interdites), mais cela échoue de deux façons courantes. D’abord, les meilleurs matches peuvent être retirés, vous laissant des résultats moins bons. Ensuite, cela augmente le risque si une partie de la chaîne journalise, met en cache ou expose des résultats non filtrés.
Avec pgvector, les vecteurs vivent dans PostgreSQL à côté des métadonnées, donc vous pouvez appliquer les permissions dans la même requête SQL et laisser Postgres les faire respecter.
PostgreSQL : permissions et jointures natives
Si votre app utilise déjà Postgres, pgvector gagne souvent en simplicité : la recherche peut être « juste une requête de plus ». Vous pouvez faire des jointures entre tickets, clients et memberships, et utiliser la Row Level Security pour que la base elle‑même bloque les lignes non autorisées.
Un schéma courant est de réduire d’abord l’ensemble candidat avec des filtres org et status, puis d’exécuter la similarité vectorielle sur ce qui reste, éventuellement en mélangeant un matching par mots‑clés pour des identifiants exacts.
Base vectorielle managée : les filtres varient, les permissions restent à votre charge
La plupart des bases vectorielles managées supportent des filtres de métadonnées, mais le langage de filtrage peut être limité et les jointures n’existent pas. Vous dénormalisez typiquement les métadonnées dans chaque enregistrement vecteur et ré‑implémentez les contrôles d’accès dans votre application.
Pour une recherche hybride dans des apps métier, vous voulez généralement que tout fonctionne ensemble : filtres stricts (org, rôle, status, visibility), recherche par mot‑clé (termes exacts comme un numéro de facture), similarité vectorielle (sens), et règles de classement (booster les éléments récents ou ouverts).
Exemple : un portail support construit dans AppMaster peut garder tickets et permissions dans PostgreSQL, ce qui rend simple l’application de « l’agent voit seulement son org » tout en obtenant des correspondances sémantiques sur les résumés et réponses des tickets.
Devenir propriétaire du code source
Produisez du code prêt pour la production en Go, Vue3, Kotlin et SwiftUI.
La qualité de recherche est le mélange de pertinence (les résultats sont-ils utiles ?) et de vitesse (est‑ce que ça semble instantané ?). Avec pgvector comme avec une base managée, vous sacrifiez généralement un peu de pertinence pour une latence plus basse en utilisant des recherches approximatives. Ce compromis est souvent acceptable pour les apps métier, tant que vous le mesurez avec de vraies requêtes.
À haut niveau, vous ajustez trois choses : le modèle d’embeddings (ce que « sens » signifie), les paramètres d’index (à quel point le moteur cherche), et la couche de classement (comment ordonner les résultats une fois que vous ajoutez filtres, récence ou popularité).
Dans PostgreSQL avec pgvector, vous choisissez souvent un index comme IVFFlat ou HNSW. IVFFlat est plus rapide et léger à construire, mais il faut tuner le nombre de « lists » et il est préférable d’avoir suffisamment de données avant qu’il soit performant. HNSW donne souvent un meilleur rappel à faible latence, mais peut utiliser plus de mémoire et prendre plus de temps à construire. Les systèmes managés exposent des choix similaires, avec des noms et des valeurs par défaut différents.
Quelques tactiques comptent plus qu’on ne l’imagine : mettre en cache les requêtes populaires, regrouper les travaux quand c’est possible (par exemple précharger la page suivante), et considérer un flux en deux étapes où vous faites une recherche vectorielle rapide puis re‑classez les top 20–100 avec des signaux métier comme la récence ou le niveau client. Surveillez aussi les allers‑retours réseau : si la recherche est dans un service séparé, chaque requête ajoute un tour de réseau.
Pour mesurer la qualité, commencez petit et concret. Collectez 20 à 50 vraies questions d’utilisateurs, définissez ce qu’est une « bonne » réponse, et suivez le taux de hit top 3 et top 10, la latence médiane et p95, le pourcentage de requêtes sans bon résultat, et combien la qualité chute une fois les permissions et filtres appliqués.
C’est là que le choix cesse d’être théorique. La meilleure option est celle qui atteint votre cible de pertinence à une latence acceptée par les utilisateurs, avec un tuning que vous pouvez maintenir.
Problèmes de montée en charge et opérations continues
Beaucoup d’équipes commencent avec pgvector parce que tout reste au même endroit : données applicatives et embeddings. Pour de nombreuses apps métier, un seul nœud PostgreSQL suffit, surtout si vous avez des dizaines à quelques centaines de milliers de vecteurs et que la recherche n’est pas le principal moteur de trafic.
Vous atteignez les limites quand la recherche sémantique devient une action centrale (présente sur beaucoup de pages, dans chaque ticket, dans le chat), ou quand vous stockez des millions de vecteurs et exigez des temps de réponse serrés aux heures de pointe.
Signes courants qu’un Postgres unique peine : la latence p95 de recherche monte pendant des écritures normales, il faut choisir entre des index rapides et une vitesse d’écriture acceptable, les tâches de maintenance deviennent des « planifiez‑les la nuit », et vous avez besoin d’une montée en charge différente pour la recherche que pour le reste de la base.
Avec pgvector, la montée en charge implique souvent d’ajouter des replicas en lecture pour la charge de requêtes, de partitionner les tables, de tuner les index et de planifier les builds d’index et la croissance du stockage. C’est faisable, mais c’est un travail continu. Vous faites aussi des choix de conception comme garder les embeddings dans la même table que les données métiers ou les séparer pour réduire le bloat et les contentions de verrous.
Les bases vectorielles managées déplacent une grande partie de cela chez le fournisseur. Elles offrent souvent une montée en charge indépendante du compute et du stockage, du sharding intégré et une haute disponibilité plus simple. Le compromis est d’opérer deux systèmes (Postgres + le store vectoriel) et de garder métadonnées et permissions synchrones.
Le coût surprend plus souvent que la performance. Les gros postes sont le stockage (les vecteurs et les index grossissent vite), le volume de requêtes de pointe (souvent ce qui fixe la facture), la fréquence de mises à jour (ré-embedding et upserts) et le mouvement de données (appels supplémentaires quand votre app doit filtrer fortement).
Si vous hésitez entre pgvector et un service managé, choisissez la douleur que vous préférez : du tuning Postgres et de la planification capacitaire plus poussés, ou payer plus pour une montée en charge plus simple tout en gérant une dépendance supplémentaire.
Transformer les docs en réponses
Mettez en place une pipeline d’embeddings via les Business Processes et les intégrations IA d’AppMaster.
Les détails de sécurité décident souvent plus vite que les benchmarks de vitesse. Demandez tôt où les données seront stockées, qui peut y accéder et ce qui arrive en cas de panne.
Commencez par la résidence des données et l’accès. Les embeddings peuvent encore révéler du sens, et beaucoup d’équipes stockent aussi des extraits bruts pour le surlignage. Soyez clair sur quel système contiendra le texte brut (tickets, notes, documents) versus uniquement les embeddings. Décidez aussi qui, en interne, peut interroger directement le store et si vous avez besoin d’une séparation stricte entre production et accès analytique.
Contrôles à confirmer avant de construire
Posez ces questions pour chaque option :
- Comment les données sont‑elles chiffrées au repos et en transit, et pouvez‑vous gérer vos propres clés ?
- Quel est le plan de sauvegarde, à quelle fréquence les restaurations sont‑elles testées et quel objectif de temps de récupération vous faut‑il ?
- Disposez‑vous de logs d’audit pour les lectures et écritures, et pouvez‑vous alerter sur un volume de requêtes inhabituel ?
- Comment appliquez‑vous l’isolation multi‑locataire : bases séparées, schémas séparés ou règles au niveau des lignes ?
- Quelle est la politique de rétention pour le contenu supprimé, y compris embeddings et caches ?
La séparation multi‑locataire est celle qui embrouille le plus. Si un client ne doit jamais influencer un autre, vous avez besoin d’un scope fort de locataire dans chaque requête. Avec PostgreSQL, cela peut être appliqué via la Row‑Level Security et des patterns de requête soignés. Avec une base vectorielle managée, vous vous appuyez souvent sur des namespaces ou collections plus la logique applicative.
Fiabilité et modes de défaillance
Préparez‑vous à l’indisponibilité de la recherche. Si le store vectoriel tombe, que verront les utilisateurs ? Un comportement sûr est une bascule vers la recherche par mots‑clés ou l’affichage d’éléments récents uniquement, plutôt que de casser la page.
Exemple : dans un portail support construit avec AppMaster, vous pouvez garder les tickets dans PostgreSQL et traiter la recherche sémantique comme une fonctionnalité optionnelle. Si les embeddings ne répondent pas, le portail peut toujours afficher des listes de tickets et permettre une recherche exacte par mot‑clé pendant la récupération du service vectoriel.
Choisir votre déploiement
Déployez sur AppMaster Cloud, AWS, Azure, Google Cloud, ou exportez pour l’auto-hébergement.
La façon la plus sûre de décider est de lancer un petit pilote qui ressemble à votre app réelle, pas à un notebook de démo.
Commencez par écrire ce que vous cherchez et ce qui doit absolument être filtré. « Chercher nos docs » est vague. « Chercher les articles d’aide, les réponses de tickets et les manuels PDF, mais ne montrer que les éléments que l’utilisateur a le droit de voir » est une exigence réelle. Les permissions, l’ID tenant, la langue, la zone produit et les filtres « seulement le contenu publié » déterminent souvent le gagnant.
Ensuite, choisissez un modèle d’embeddings et un plan de rafraîchissement. Décidez ce qu’on embede (document entier, chunks ou les deux) et à quelle fréquence cela se met à jour (à chaque édition, nightly ou à la publication). Si le contenu change souvent, mesurez à quel point la ré‑embedding est pénible, pas seulement la vitesse des requêtes.
Puis construisez une API de recherche fine dans votre backend. Gardez‑la simple : un endpoint qui prend une requête plus des champs de filtre, retourne les meilleurs résultats et journalise ce qui s’est passé. Si vous construisez avec AppMaster, vous pouvez implémenter l’ingestion et le flux de mise à jour comme un service backend plus un Business Process qui appelle votre fournisseur d’embeddings, écrit vecteurs et métadonnées, et fait respecter les règles d’accès.
Lancez un pilote de deux semaines avec de vrais utilisateurs et de vraies tâches. Utilisez une poignée de questions courantes que les utilisateurs posent réellement, suivez le taux « réponse trouvée » et le temps jusqu’au premier résultat utile, révisez les mauvais résultats chaque semaine, surveillez le volume de ré‑embedding et la charge de requêtes, et testez les modes de panne comme les métadonnées manquantes ou les vecteurs périmés.
À la fin, décidez sur la base de preuves. Conservez pgvector s’il répond à vos besoins de qualité et de filtrage avec un travail d’ops acceptable. Passez au managé si la montée en charge et la fiabilité dominent. Ou utilisez une architecture hybride (PostgreSQL pour métadonnées et permissions, store vectoriel pour la récupération) si cela correspond mieux à votre stack.
Erreurs courantes que les équipes rencontrent
La plupart des erreurs apparaissent après que la première démo fonctionne. Une preuve de concept rapide peut sembler excellente, puis se briser quand vous ajoutez de vrais utilisateurs, de vraies données et de vraies règles.
Les problèmes qui causent le plus souvent une reprise sont :
- Supposer que les vecteurs gèrent le contrôle d’accès. La recherche par similarité ne sait pas qui peut voir quoi. Si votre app a des rôles, des équipes, des locataires ou des notes privées, vous avez toujours besoin de filtres de permissions stricts et de tests pour éviter toute fuite.
- Se fier à des démos « ça a l’air bien ». Quelques requêtes triées sur le volet ne constituent pas une évaluation. Sans un petit jeu de questions annotées et de résultats attendus, les régressions sont difficiles à repérer quand vous changez le chunking, les embeddings ou les index.
- Embeder des documents entiers en un seul vecteur. Les pages longues, les tickets et les PDF nécessitent généralement du chunking. Sans chunks, les résultats deviennent vagues. Sans versioning, on ne sait pas quelle version correspond à quel embedding.
- Ignorer les mises à jour et suppressions. Les apps réelles éditent et suppriment du contenu. Si vous ne ré‑embedez pas à la mise à jour et ne nettoyez pas à la suppression, vous servirez des correspondances périmées qui pointent vers du texte manquant ou obsolète.
- Trop tuner la performance avant de verrouiller l’UX. Des équipes passent des jours sur les réglages d’index en oubliant des bases comme les filtres de métadonnées, de bons extraits (snippets) et une solution de secours par mot‑clé quand la requête est très spécifique.
Un simple test « day‑2 » détecte tôt ces problèmes : ajoutez une nouvelle règle de permission, mettez à jour 20 items, supprimez 5, puis reposez les mêmes 10 questions d’évaluation. Si vous construisez sur une plateforme comme AppMaster, planifiez ces vérifications avec votre logique métier et votre modèle de données, pas en postface.
Scénario d’exemple : recherche sémantique dans un portail d’assistance
Construire l’API de recherche
Créez des endpoints backend sécurisés et une interface de recherche sans repartir de zéro.
Une entreprise SaaS de taille moyenne gère un portail d’assistance avec deux contenus principaux : tickets clients et articles du centre d’aide. Ils veulent une barre de recherche qui comprenne le sens, de sorte que taper « impossible de me connecter après avoir changé de téléphone » fasse remonter le bon article et des tickets similaires.
Les non‑négociables sont pratiques : chaque client ne doit voir que ses propres tickets, les agents doivent pouvoir filtrer par statut (open, pending, solved), et les résultats doivent sembler instantanés car des suggestions s’affichent au fur et à mesure de la saisie.
Option A : pgvector dans le même PostgreSQL
Si le portail stocke déjà tickets et articles dans PostgreSQL (fréquent si vous utilisez une stack avec Postgres, comme AppMaster), ajouter pgvector peut être un premier pas propre. Vous gardez embeddings, métadonnées et permissions au même endroit, donc « seulement les tickets pour customer_123 » devient une clause WHERE normale.
Cela marche bien quand votre jeu de données est modeste (dizaines ou centaines de milliers d’items), votre équipe sait tuner les index et plans de requêtes Postgres, et vous voulez moins de pièces mobiles avec un contrôle d’accès plus simple.
Le compromis est que la recherche vectorielle peut entrer en concurrence avec la charge transactionnelle. En croissance, vous devrez peut‑être ajouter de la capacité, soigner vos index ou même séparer Postgres pour protéger les écritures de tickets et les SLA.
Option B : base vectorielle managée pour les embeddings, PostgreSQL pour les métadonnées
Avec une base vectorielle managée, vous stockez typiquement les embeddings et un ID là‑dessus, puis conservez la « vérité » (status du ticket, customer_id, permissions) dans PostgreSQL. En pratique, les équipes filtrent soit d’abord en Postgres puis recherchent les IDs éligibles, soit elles recherchent d’abord et revérifient les permissions avant d’afficher les résultats.
Cette option gagne souvent quand la croissance est incertaine ou quand l’équipe ne veut pas passer du temps à soigner les performances. Mais le flux de permissions demande une vraie attention, sinon vous risquez des fuites entre clients.
Un choix pratique est de démarrer avec pgvector si vous avez besoin d’un filtrage serré et d’opérations simples, et de prévoir une migration vers un service managé si vous attendez une croissance rapide, un volume de requêtes élevé, ou si vous ne pouvez pas tolérer que la recherche ralentisse votre base principale.
Checklist rapide et prochaines étapes
Si vous êtes bloqué, arrêtez de débattre des fonctionnalités et écrivez ce que votre app doit faire au jour 1. Les vraies exigences apparaissent souvent lors d’un petit pilote avec de vrais utilisateurs et de vraies données.
Ces questions décident plus vite que les benchmarks :
- Quels filtres sont non négociables (tenant, rôle, région, statut, plage temporelle) ?
- Quelle taille aura l’index dans 6 à 12 mois (items et embeddings) ?
- Quelle latence paraît instantanée pour vos utilisateurs, y compris en pointe ?
- Qui possède le budget et l’on‑call ?
- Où doit vivre la source de vérité : tables PostgreSQL ou index externe ?
Préparez aussi le changement. Les embeddings ne sont pas « set and forget ». Le texte change, les modèles évoluent et la pertinence dérive jusqu’à ce que quelqu’un se plaigne. Décidez d’emblée comment gérer les mises à jour, comment détecter la dérive et quoi surveiller (latence de requête, taux d’erreur, rappel sur un petit jeu test et recherches « sans résultat »).
Si vous voulez avancer vite sur l’app complète autour de la recherche, AppMaster peut être un bon choix : il vous donne la modélisation PostgreSQL, la logique backend et l’UI web ou mobile dans un seul flux no‑code, et vous pouvez ajouter la recherche sémantique une fois le cœur appli établi.
FAQ
La recherche sémantique renvoie des résultats utiles même si les mots de l’utilisateur ne correspondent pas exactement au texte du document. Elle est particulièrement utile quand les gens font des fautes, utilisent des abréviations ou décrivent des symptômes plutôt que les termes officiels, ce qui arrive souvent dans les portails de support, les outils internes et les bases de connaissances.
Choisissez pgvector quand vous voulez moins de composants, un filtrage strict basé sur le SQL, et que vos données et trafics restent modestes. C’est souvent la voie la plus rapide vers une recherche sécurisée et respectueuse des permissions parce que vecteurs et métadonnées cohabitent dans les mêmes requêtes PostgreSQL.
Une base vectorielle managée convient quand vous prévoyez une croissance rapide du nombre de vecteurs ou du volume de requêtes, ou quand vous voulez que la montée en charge et la disponibilité soient gérées hors de votre base principale. Vous échangerez une opération simplifiée contre un travail d’intégration supplémentaire et une gestion attentive des permissions.
Un embedding transforme du texte en un vecteur numérique qui représente le sens. Une base vectorielle (ou pgvector dans PostgreSQL) stocke ces vecteurs et trouve rapidement ceux qui sont les plus proches de l’embedding de la requête de l’utilisateur, ce qui permet d’obtenir des résultats « similaires par intention ».
Filtrer après la recherche vectorielle a tendance à supprimer les meilleures correspondances et peut laisser l’utilisateur avec des résultats médiocres ou une page vide. De plus, cela augmente le risque d’exposition accidentelle via des logs, caches ou outils de debug : il est donc plus sûr d’appliquer les filtres de locataire et de rôle le plus tôt possible.
Avec pgvector, vous appliquez les permissions, les jointures et la Row Level Security dans la même requête SQL qui effectue la recherche par similarité. Ainsi, PostgreSQL peut garantir de ne jamais retourner des lignes interdites, car l’enforcement se fait là où les données résident.
La plupart des bases vectorielles managées supportent des filtres de métadonnées, mais elles ne gèrent pas les jointures et le langage de filtrage peut être limité. Vous finissez souvent par dénormaliser les métadonnées liées aux permissions dans chaque enregistrement vecteur et par ré-appliquer les vérifications d’autorisation côté application.
Le chunking consiste à diviser de longs documents en parties plus petites avant d’embeder, ce qui améliore la précision parce que chaque vecteur représente une idée ciblée. Les embeddings de document entier peuvent convenir pour des éléments courts, mais pour de longs tickets, politiques ou PDF, il faut généralement chunker et suivre les versions.
Planifiez les mises à jour dès le départ : ré-embed à la publication ou à l’édition pour le contenu qui change souvent, et supprimez toujours les vecteurs quand l’enregistrement source est supprimé. Sans cela, vous servirez des correspondances obsolètes pointant vers du texte disparu ou périmé.
Un pilote pratique utilise de vraies requêtes et des filtres stricts, mesure la pertinence et la latence, et teste les cas de panne comme les métadonnées manquantes ou les vecteurs obsolètes. Choisissez l’option qui retourne de bons résultats en tête de liste sous vos règles de permission, avec des coûts et un travail opérationnel que votre équipe peut assumer.