11 avr. 2025·8 min de lecture
Configuration d'observabilité minimale pour backends et API CRUD
Configuration d'observabilité minimale pour backends axés CRUD : logs structurés, métriques essentielles et alertes pratiques pour détecter tôt requêtes lentes, erreurs et pannes.
Quel problème résout l'observabilité dans les applications CRUD\n\nLes applications métier centrées sur le CRUD échouent souvent de façons ennuyeuses et coûteuses. Une page de liste devient plus lente chaque semaine, un bouton de sauvegarde se met parfois en timeout, et le support signale des « 500 aléatoires » que vous ne pouvez pas reproduire. Rien ne semble cassé en développement, mais la production paraît peu fiable.\n\nLe vrai coût n'est pas seulement l'incident. C'est le temps passé à deviner. Sans signaux clairs, les équipes sautent entre « ça doit être la base de données », « ça doit être le réseau » et « c'est sûrement cet endpoint », pendant que les utilisateurs attendent et que la confiance diminue.\n\nL'observabilité transforme ces suppositions en réponses. Simplement : vous pouvez regarder ce qui s'est passé et comprendre pourquoi. On y arrive avec trois types de signaux :\n\n- Logs : ce que l'app a décidé de faire (avec du contexte utile)\n- Métriques : comment le système se comporte dans le temps (latence, taux d'erreur, saturation)\n- Traces (optionnel) : où le temps a été passé entre services et la base de données\n\nPour les applications CRUD et les services API, il s'agit moins de tableaux de bord tape‑à‑l'œil que de diagnostics rapides. Quand un appel « Create invoice » ralentit, vous devez pouvoir dire si le retard vient d'une requête DB, d'une API en aval ou d'un worker surchargé en minutes, pas en heures.\n\nUne configuration minimale part des questions que vous devez vraiment pouvoir répondre un jour de panne :\n\n- Quel endpoint échoue ou est lent, et pour qui ?\n- Est‑ce un pic (trafic) ou une régression (nouvelle release) ?\n- La base de données est‑elle le goulot, ou l'app ?\n- Est‑ce que ça affecte les utilisateurs maintenant, ou est‑ce juste du remplissage de logs ?\n\nSi vous construisez des backends avec une stack générée (par exemple, AppMaster générant des services Go), la même règle s'applique : commencez petit, gardez les signaux cohérents, et n'ajoutez de nouvelles métriques ou alertes qu'après qu'un incident réel ait prouvé qu'elles auraient fait gagner du temps.\n\n## La configuration minimale : ce qu'il vous faut et ce que vous pouvez sauter\n\nUne configuration d'observabilité minimale repose sur trois piliers : logs, métriques et alertes. Les traces sont utiles, mais pour la plupart des apps CRUD métier, ce sont un bonus.\n\nL'objectif est simple. Vous devez savoir (1) quand les utilisateurs échouent, (2) pourquoi ils échouent, et (3) où dans le système cela se produit. Si vous ne pouvez pas répondre rapidement, vous perdrez du temps à deviner et à débattre sur ce qui a changé.\n\nL'ensemble minimal de signaux qui vous y mène ressemble généralement à ceci :\n\n- Logs structurés pour chaque requête et chaque job en arrière‑plan afin de pouvoir rechercher par request_id, utilisateur, endpoint et erreur.\n- Quelques métriques clés : débit de requêtes, taux d'erreur, latence et temps passé en base.\n- Alertes liées à l'impact utilisateur (pics d'erreurs ou réponses lentes soutenues), pas à chaque avertissement interne.\n\nIl aide aussi de séparer symptômes et causes. Un symptôme est ce que ressentent les utilisateurs : 500, timeouts, pages lentes. Une cause est ce qui crée cela : contention de locks, pool de connexions saturé, ou une requête lente après l'ajout d'un filtre. Alertez sur les symptômes et utilisez les signaux « cause » pour enquêter.\n\nUne règle pratique : choisissez un seul endroit pour voir les signaux importants. Passer d'un outil de logs à un outil de métriques puis à une boîte d'alerte distincte vous ralentit quand ça compte le plus.\n\n## Logs structurés lisibles sous pression\n\nQuand quelque chose casse, le chemin le plus rapide vers une réponse est souvent : « Quelle requête exacte a touché cet utilisateur ? » C'est pourquoi un ID de corrélation stable compte plus que presque tout autre ajustement de logs.\n\nChoisissez un nom de champ unique (souvent request_id) et traitez‑le comme obligatoire. Générez‑le à la périphérie (API gateway ou premier handler), transmettez‑le dans les appels internes, et incluez‑le dans chaque ligne de log. Pour les jobs en arrière‑plan, créez un request_id par exécution et stockez un parent_request_id quand un job a été déclenché par un appel API.\n\nLoggez en JSON, pas en texte libre. Cela rend les logs recherchables et cohérents quand vous êtes fatigué, stressé et que vous survolez.\n\nUn jeu simple de champs suffit pour la plupart des services API CRUD :\n\n- timestamp, level, service, env\n- request_id, route, method, status\n- duration_ms, db_query_count\n- tenant_id ou account_id (identifiants sûrs, pas de données personnelles)\n\nLes logs doivent vous aider à restreindre « quel client et quel écran », sans devenir une fuite de données. Évitez les noms, emails, téléphones, adresses, tokens ou corps de requête complets par défaut. Si vous avez besoin de détails plus profonds, loggez‑les uniquement à la demande et avec redaction.\n\nDeux champs payent rapidement dans les systèmes CRUD : duration_ms et db_query_count. Ils repèrent les handlers lents et les patterns N+1 accidentels avant même d'ajouter du tracing.\n\nDéfinissez des niveaux de logs pour que tout le monde les utilise de la même manière :\n\n- info : événements attendus (requête terminée, job démarré)\n- warn : inhabituel mais récupérable (requête lente, retry réussi)\n- error : requête ou job échoué (exception, timeout, dépendance en erreur)\n\nSi vous générez des backends avec une plateforme comme AppMaster, gardez les mêmes noms de champs entre les services générés afin que « recherche par request_id » fonctionne partout.\n\n## Métriques clés qui importent pour les backends et APIs CRUD\n\nLa plupart des incidents dans les apps CRUD ont une forme familière : un ou deux endpoints deviennent lents, la base se met à souffrir, et les utilisateurs voient des spinners ou des timeouts. Vos métriques doivent permettre de comprendre cette histoire en quelques minutes.\n\nUn ensemble minimal couvre généralement cinq axes :\n\n- Trafic : requêtes par seconde (par route ou au moins par service) et taux de requêtes par classe de statut (2xx, 4xx, 5xx)\n- Erreurs : taux de 5xx, compte des timeouts, et une métrique séparée pour les « erreurs métier » retournées en 4xx (pour ne pas pager pour des erreurs utilisateur)\n- Latence (percentiles) : p50 pour l'expérience typique et p95 (parfois p99) pour détecter que « quelque chose ne va pas »\n- Saturation : CPU et mémoire, plus la saturation spécifique à l'app (utilisation des workers, pression sur threads/goroutines si exposée)\n- Pression sur la base : p95 de durée des requêtes DB, connexions en use vs max du pool, et waits de locks (ou compte des requêtes en attente de locks)\n\nDeux détails rendent les métriques bien plus actionnables.\n\nD'abord, séparez les requêtes API interactives du travail en arrière‑plan. Un envoi d'email lent ou une boucle de retry de webhook peut monopoliser CPU, connexions DB ou réseau sortant et faire paraître l'API « aléatoirement lente ». Suivez les files, retries et durées de job comme séries temporelles séparées, même s'ils tournent dans le même backend.\n\nEnsuite, attachez toujours les métadonnées de version/build aux dashboards et alertes. Quand vous déployez un nouveau backend généré (par exemple après régénération de code avec un outil no‑code comme AppMaster), vous voulez répondre vite à la question : le taux d'erreur ou la p95 ont‑ils bondi juste après cette release ?\n\nUne règle simple : si une métrique ne peut pas vous dire quoi faire ensuite (rollback, scaler, corriger une requête, arrêter un job), elle n'a pas sa place dans l'ensemble minimal.\n\n## Signaux de base de données : la cause fréquente des douleurs CRUD\n\nDans les apps CRUD, la base de données est souvent l'endroit où « ça devient lent » et devient une vraie douleur utilisateur. Une configuration minimale doit rendre évident quand le goulot est PostgreSQL (et quel type de problème DB c'est).\n\n### Que mesurer d'abord dans PostgreSQL\n\nVous n'avez pas besoin de dizaines de tableaux. Commencez par les signaux qui expliquent la plupart des incidents :\n\n- Taux de requêtes lentes et p95/p99 des temps de requêtes (plus les requêtes lentes principales)\n- Waits de locks et deadlocks (qui bloque qui)\n- Utilisation des connexions (connexions actives vs limite du pool, échecs de connexion)\n- Pression disque et I/O (latence, saturation, espace libre)\n- Lag de réplication (si vous avez des read replicas)\n\n### Séparer le temps applicatif du temps DB\n\nAjoutez un histogramme de timing des requêtes dans la couche API et taggez‑le avec l'endpoint ou le cas d'usage (par exemple : GET /customers, « recherche commandes », « mise à jour statut ticket »). Cela montre si un endpoint est lent parce qu'il exécute beaucoup de petites requêtes ou une grosse requête.\n\n### Détecter tôt les patterns N+1\n\nLes écrans CRUD déclenchent souvent des N+1 : une requête de liste, puis une requête par ligne pour récupérer des données liées. Surveillez les endpoints où le nombre de requêtes reste stable mais où db_query_count par requête augmente. Si vous générez des backends à partir de modèles et logique métier, c'est souvent là qu'on ajuste le pattern de fetch.\n\nSi vous avez déjà un cache, suivez le taux de hit. N'ajoutez pas un cache juste pour avoir de jolis graphiques.\n\nConsidérez les changements de schéma et les migrations comme des fenêtres à risque. Enregistrez quand elles commencent et finissent, puis surveillez les pics de locks, temps de requête et erreurs de connexion pendant cette fenêtre.\n\n## Alertes qui réveillent la bonne personne pour la bonne raison\n\nLes alertes doivent pointer vers un vrai problème utilisateur, pas un graphique occupé. Pour les apps CRUD, commencez par surveiller ce que ressentent les utilisateurs : erreurs et lenteurs.\n\nSi vous n'ajoutez que trois alertes au départ, faites‑les :\n\n- augmentation du taux de 5xx\n- p95 de latence soutenu\n- chute soudaine des requêtes réussies\n\nAprès ça, ajoutez quelques alertes « cause probable ». Les backends CRUD échouent souvent de façons prévisibles : la DB manque de connexions, une file d'attente de background s'accumule, ou un endpoint unique commence à timeout et traîne toute l'API vers le bas.\n\n### Seuils : ligne de base + marge, pas des suppositions\n\nHardcoder des nombres comme « p95 > 200ms » marche rarement entre environnements. Mesurez une semaine normale, puis placez l'alerte juste au‑dessus avec une marge de sécurité. Par exemple, si la p95 tourne habituellement entre 350–450ms en heures ouvrées, alertez à 700ms pendant 10 minutes. Si le 5xx est typiquement 0,1–0,3%, pager à 2% pendant 5 minutes.\n\nGardez les seuils stables. Ne les retouchez pas tous les jours. Ajustez‑les après un incident, quand vous pouvez relier les changements à des conséquences réelles.\n\n### Pager vs ticket : décidez avant d'en avoir besoin\n\nUtilisez deux niveaux de sévérité pour que les gens fassent confiance au signal :\n\n- Pager quand les utilisateurs sont bloqués ou que des données sont en risque (5xx élevé, timeouts API, pool de connexions DB presque épuisé).\n- Créer un ticket quand c'est dégradant mais pas urgent (créep lent de la p95, backlog de queue qui augmente, tendance à la hausse de l'espace disque).\n\nCoupez le son des alertes pendant les fenêtres attendues comme les déploiements et la maintenance planifiée.\n\nRendez les alertes actionnables. Incluez « quoi vérifier en premier » (endpoint principal, connexions DB, déploi récent) et « ce qui a changé » (nouvelle release, migration de schéma). Si vous utilisez AppMaster, notez quel backend ou module a été régénéré et déployé récemment, car c'est souvent la piste la plus rapide.\n\n## SLO simples pour les apps métier (et comment ils orientent les alertes)\n\nUne configuration minimale devient plus simple quand vous décidez ce que signifie « assez bon ». C'est l'objet des SLO : des objectifs clairs qui transforment la surveillance vague en alertes spécifiques.\n\nCommencez par des SLI qui reflètent ce que ressentent les utilisateurs : disponibilité (les utilisateurs peuvent terminer des requêtes), latence (vitesse d'exécution des actions) et taux d'erreur (fréquence des échecs).\n\nDéfinissez les SLO par groupe d'endpoints, pas route par route. Pour les apps CRUD, grouper garde les choses lisibles : lecture (GET/list/search), écriture (create/update/delete), et auth (login/refresh). Cela évite une centaine de SLO minuscules que personne ne maintient.\n\nExemples d'SLO adaptés aux attentes typiques :\n\n- Application interne CRUD (portal admin) : 99,5% de disponibilité par mois, 95% des lectures sous 800 ms, 95% des écritures sous 1,5 s, taux d'erreur < 0,5%.\n- API publique : 99,9% de disponibilité par mois, 99% des lectures sous 400 ms, 99% des écritures sous 800 ms, taux d'erreur < 0,1%.\n\nLes budgets d'erreur sont le temps « mauvais » autorisé dans l'SLO. Un SLO de 99,9% mensuel laisse environ 43 minutes d'indisponibilité. Si vous consommez ce budget rapidement, suspendez les changements risqués jusqu'à rétablissement.\n\nUtilisez les SLO pour décider ce qui mérite une alerte vs un trend sur un tableau de bord. Alertez quand vous brûlez le budget d'erreur vite (les utilisateurs échouent activement), pas quand une métrique est juste un peu pire qu'hier.\n\nSi vous générez des backends rapidement (par exemple, AppMaster générant un service Go), les SLO gardent l'attention sur l'impact utilisateur même si l'implémentation change en dessous.\n\n## Étape par étape : monter une observabilité minimale en une journée\n\nCommencez par la partie du système que les utilisateurs touchent le plus. Choisissez les appels API et les jobs qui, s'ils sont lents ou cassés, donnent l'impression que l'app entière est en panne.\n\nNotez vos endpoints principaux et travaux en arrière‑plan. Pour une app CRUD métier, c'est souvent login, list/search, create/update, et un job d'export ou d'import. Si vous avez bâti le backend avec AppMaster, incluez vos endpoints générés et les Business Process qui tournent en horaires ou via webhooks.\n\n### Plan d'une journée\n\n- Heure 1 : Choisissez vos 5 endpoints principaux et 1–2 jobs en arrière‑plan. Notez ce que « bien » signifie : latence typique, taux d'erreur attendu, temps DB normal.\n- Heures 2–3 : Ajoutez des logs structurés avec des champs cohérents : request_id, user_id (si dispo), endpoint, status_code, latency_ms, db_time_ms, et un court error_code pour les échecs connus.\n- Heures 3–4 : Ajoutez les métriques de base : requêtes par seconde, p95 de latence, taux 4xx, taux 5xx, et timings DB (durée des requêtes et saturation du pool si disponible).\n- Heures 4–6 : Construisez trois tableaux de bord : une vue d'ensemble (santé en un coup d'œil), une vue API détaillée (découpage par endpoint), et une vue base de données (requêtes lentes, locks, utilisation des connexions).\n- Heures 6–8 : Ajoutez des alertes, provoquez une panne contrôlée, et confirmez que l'alerte est actionnable.\n\nGardez les alertes peu nombreuses et ciblées. Vous voulez des alertes qui pointent l'impact utilisateur, pas « quelque chose a changé ».\n\n### Alertes de départ (5–8 au total)\n\nUn ensemble de départ solide : p95 API trop élevé, taux 5xx soutenu, pic soudain de 4xx (souvent auth ou changements de validation), échecs de jobs background, requêtes DB lentes, connexions DB proches de la limite, et espace disque faible (si self‑hosted).\n\nEnsuite, rédigez un mini runbook par alerte. Une page suffit : quoi vérifier en premier (panneaux du dashboard et champs de log clés), causes probables (locks DB, index manquant, requête lente), et la première action sûre (redémarrer un worker bloqué, rollback d'un changement, mettre en pause un job lourd).\n\n## Erreurs courantes qui rendent la surveillance bruyante ou inutile\n\nLa façon la plus rapide de gâcher une configuration minimale est de traiter la supervision comme une case à cocher. Les apps CRUD échouent souvent de façons prévisibles (requêtes DB lentes, timeouts, mauvaises releases), donc vos signaux doivent rester concentrés là‑dessus.\n\nL'échec le plus courant est la fatigue d'alerte : trop d'alertes, trop peu d'actions. Si vous pager sur chaque pic, les gens arrêtent de faire confiance aux alertes en deux semaines. Une bonne règle : une alerte doit pointer vers une correction probable, pas juste « quelque chose a changé ».\n\nUne autre erreur classique est l'absence d'IDs de corrélation. Si vous ne pouvez pas relier un log d'erreur, une requête lente et une requête DB à une même requête, vous perdez des heures. Assurez‑vous que chaque requête reçoit un request_id (et incluez‑le dans les logs, traces si vous en avez, et éventuellement dans les réponses quand c'est sûr).\n\n### Ce qui crée généralement du bruit\n\nLes systèmes bruyants partagent souvent les mêmes problèmes :\n\n- Une alerte mélange 4xx et 5xx, donc erreurs client et erreurs serveur paraissent identiques.\n- Les métriques ne suivent que des moyennes, cachant la latence tail (p95 ou p99) où les utilisateurs souffrent.\n- Les logs contiennent par erreur des données sensibles (mots de passe, tokens, corps de requête complets).\n- Les alertes se déclenchent sur des symptômes sans contexte (CPU élevé) au lieu de l'impact utilisateur (taux d'erreur, latence).\n- Les déploiements sont invisibles, donc les régressions semblent des échecs aléatoires.\n\nLes apps CRUD sont particulièrement vulnérables au « piège de la moyenne ». Une seule requête lente peut rendre 5% des requêtes pénibles tandis que la moyenne paraît correcte. La latence tail et le taux d'erreur donnent une image plus claire.\n\nAjoutez des marqueurs de déploiement. Que vous livriez depuis CI ou que vous régénériez du code avec AppMaster, enregistrez la version et l'heure de déploiement comme événement et dans vos logs.\n\n## Vérifications rapides : une checklist minimale d'observabilité\n\nVotre configuration fonctionne quand vous pouvez répondre à quelques questions rapidement, sans fouiller les tableaux de bord pendant 20 minutes. Si vous n'obtenez pas un « oui/non » rapidement, il vous manque un signal clé ou vos vues sont trop dispersées.\n\n### Vérifications rapides en incident\n\nVous devriez pouvoir faire la plupart en moins d'une minute :\n\n- Pouvez‑vous dire si les utilisateurs échouent en ce moment (oui/non) depuis une seule vue d'erreur (5xx, timeouts, jobs échoués) ?\n- Pouvez‑vous repérer le groupe d'endpoints le plus lent et sa p95, et voir si ça empire ?\n- Pouvez‑vous séparer le temps applicatif du temps DB pour une requête (handler time, DB query time, appels externes) ?\n- Pouvez‑vous voir si la base est proche des limites de connexion ou de CPU, et si des requêtes font la queue ?\n- Si une alerte s'est déclenchée, suggère‑t‑elle une action suivante (rollback, scaler, vérifier connexions DB, inspecter un endpoint), pas seulement « latence élevée » ?\n\nLes logs doivent être à la fois sûrs et utiles. Ils doivent contenir assez de contexte pour suivre une requête défaillante entre services, sans divulguer de données personnelles.\n\n### Test de cohérence des logs\n\nChoisissez un échec récent et ouvrez ses logs. Vérifiez que vous avez request_id, endpoint, code de statut, duration, et un message d'erreur clair. Confirmez aussi que vous ne loggez pas de tokens bruts, mots de passe, détails de paiement ou champs personnels.\n\nSi vous créez des backends CRUD avec AppMaster, visez une seule « vue d'incident » qui combine ces contrôles : erreurs, p95 par endpoint, et santé DB. Cela couvre à lui seul la plupart des pannes réelles des apps métier.\n\n## Exemple : diagnostiquer un écran CRUD lent avec les bons signaux\n\nUn portail admin interne marche bien toute la matinée, puis devient notablement lent lors d'une heure de pic. Les utilisateurs se plaignent que l'ouverture de la liste « Orders » et la sauvegarde des modifications prennent 10–20 secondes.\n\nVous commencez par les signaux de haut niveau. Le dashboard API montre que la p95 des endpoints de lecture est passée d'environ 300 ms à 4–6 s, tandis que le taux d'erreur reste faible. En même temps, le panneau base de données montre des connexions actives proches de la limite du pool et une montée des waits de locks. Le CPU des nœuds backend est normal, ce qui n'indique pas un problème de calcul.\n\nEnsuite, vous choisissez une requête lente et suivez son parcours dans les logs. Filtrez par endpoint (par exemple GET /orders) et triez par durée. Prenez un request_id d'une requête à 6s et cherchez‑le dans tous les services. Vous voyez que le handler a fini rapidement, mais la ligne de log DB pour ce même request_id montre une requête de 5,4s avec rows=50 et un grand lock_wait_ms.\n\nVous pouvez maintenant énoncer la cause avec confiance : le ralentissement se situe dans le chemin base de données (requête lente ou contention de locks), pas le réseau ni le CPU backend. C'est le bénéfice d'une configuration minimale : vous restreignez la recherche plus vite.\n\nCorrectifs typiques, par ordre de sécurité :\n\n- Ajouter ou ajuster un index pour le filtre/tri utilisé sur l'écran de liste.\n- Éliminer les N+1 en récupérant les données liées en une seule requête ou via un join.\n- Ajuster le pool de connexions pour ne pas étouffer la DB sous charge.\n- Ajouter un cache seulement pour les données stables et très lues (et documenter les règles d'invalidation).\n\nFermez la boucle avec une alerte ciblée. Pager uniquement quand la p95 pour le groupe d'endpoints reste au‑dessus du seuil pendant 10 minutes ET l'utilisation des connexions DB est au‑dessus de (par exemple) 80%. Cette combinaison évite le bruit et détecte plus tôt ce problème la prochaine fois.\n\n## Prochaines étapes : rester minimal, puis améliorer avec des incidents réels\n\nUne configuration minimale doit être ennuyeuse dès le premier jour. Si vous commencez avec trop de tableaux de bord et d'alertes, vous les réglerez sans cesse et manquerez quand même les vrais problèmes.\n\nConsidérez chaque incident comme un retour d'information. Après le correctif, demandez : qu'est‑ce qui aurait permis de repérer ça plus vite et de le diagnostiquer plus aisément ? Ajoutez seulement ça.\n\nStandardisez tôt, même si vous n'avez qu'un service aujourd'hui. Utilisez les mêmes noms de champs dans les logs et les mêmes noms de métriques partout afin que les nouveaux services correspondent au pattern sans débat. Cela rend aussi les tableaux de bord réutilisables.\n\nUne petite discipline de release rapporte vite :\n\n- Ajoutez un marqueur de déploiement (version, environnement, commit/build ID) pour voir si les problèmes ont commencé après une release.\n- Rédigez un mini runbook pour les 3 alertes principales : signification, premières vérifications et qui en est responsable.\n- Gardez un « golden » dashboard avec l'essentiel pour chaque service.\n\nSi vous générez des backends avec AppMaster, planifier vos champs d'observabilité et métriques clés avant de générer les services aide : chaque nouvelle API sortira avec des logs structurés et des signaux santé cohérents par défaut. Si vous voulez un point de départ pour bâtir ces backends, AppMaster (appmaster.io) est conçu pour générer des backends, web et apps mobiles prêts pour la production tout en gardant l'implémentation cohérente au fil des changements.\n\nChoisissez une amélioration à la fois, basée sur ce qui a réellement fait mal :\n\n- Ajouter le timing des requêtes DB (et logger les requêtes lentes avec contexte).\n- Affiner les alertes pour qu'elles pointent l'impact utilisateur, pas seulement la consommation de ressources.\n- Rendre un tableau de bord plus clair (renommer graphiques, ajouter des seuils, supprimer des panneaux inutiles).\n\nRépétez ce cycle après chaque incident réel. En quelques semaines, vous obtiendrez une surveillance adaptée à votre app CRUD et à votre trafic API plutôt qu’un modèle générique.
FAQ
Commencez à ajouter de l'observabilité quand les problèmes en production prennent plus de temps à expliquer qu'à réparer. Si vous voyez des « 500 aléatoires », des pages de listes lentes ou des timeouts impossibles à reproduire, un petit ensemble de logs structurés, métriques et alertes cohérentes vous évitera des heures de conjectures.
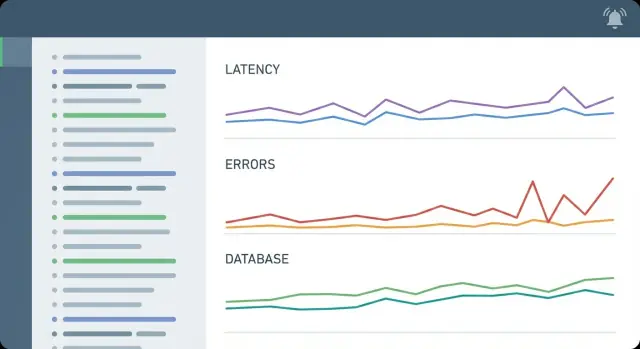
Le monitoring vous dit *qu'*il y a un problème, tandis que l'observabilité aide à comprendre pourquoi il est arrivé grâce à des signaux riches en contexte que vous pouvez corréler. Pour les APIs CRUD, l'objectif pratique est un diagnostic rapide : quel endpoint, quel utilisateur/tenant, et si le temps a été passé dans l'application ou dans la base de données.
Commencez par des logs de requête structurés, une poignée de métriques essentielles et quelques alertes orientées impact utilisateur. Le tracing peut attendre dans beaucoup d'applications CRUD si vous loguez déjà duration_ms, db_time_ms (ou équivalent) et un request_id stable cherché partout.
Utilisez un seul champ de corrélation comme request_id et incluez‑le dans chaque ligne de log de requête et chaque exécution de job en arrière‑plan. Générez‑le au bord (API gateway ou premier handler), transmettez‑le dans les appels internes et assurez‑vous de pouvoir rechercher les logs par cet ID pour reconstruire rapidement une requête lente ou échouée.
Loggez timestamp, level, service, env, route, method, status, duration_ms et des identifiants sûrs comme tenant_id ou account_id. Évitez par défaut de logger des données personnelles, des tokens ou des corps de requête complets ; si vous avez besoin de détails, ne les ajoutez que pour des erreurs spécifiques et avec redaction.
Suivez le taux de requêtes, le taux de 5xx, les percentiles de latence (au moins p50 et p95) et la saturation de base (CPU/mémoire et toute pression sur workers ou files). Ajoutez tôt le temps passé en base et l'utilisation du pool de connexions, car beaucoup d'incidents CRUD viennent d'une contention de la base ou d'une saturation du pool.
Parce qu'elles révèlent la queue lente que ressentent les utilisateurs. Les moyennes peuvent sembler correctes alors que le p95 est catastrophique pour une portion significative de requêtes, ce qui fait que des écrans CRUD paraissent « lentement aléatoires » sans erreurs évidentes.
Surveillez le taux de requêtes lentes et les percentiles de durée, les waits de locks/deadlocks, et l'utilisation des connexions par rapport aux limites du pool. Ces signaux indiquent si la base est le goulot d'étranglement et si le problème est la performance des requêtes, la contention ou un manque de connexions sous charge.
Commencez par des alertes sur les symptômes utilisateurs : taux soutenu de 5xx, p95 de latence soutenu, et une chute soudaine des requêtes réussies. Ajoutez ensuite des alertes orientées cause (comme des connexions DB proches de la limite ou un backlog de jobs) pour que le signal d'astreinte reste digne de confiance et actionnable.
Attachez les métadonnées de version/build aux logs, tableaux de bord et alertes, et enregistrez des marqueurs de déploiement pour voir quand un changement a été publié. Avec des backends générés (comme des services Go générés par AppMaster), c'est particulièrement important car régénérations et redéploiements peuvent être fréquents et vous voudrez vérifier rapidement si une regression a commencé juste après une release.