31 août 2025·8 min de lecture
Minuteries SLA et escalades : modélisation de workflows maintenable
Apprenez à modéliser les minuteries SLA et les escalades avec des états clairs, des règles faciles à maintenir et des chemins d'escalade simples pour que vos applications de workflow restent faciles à modifier.
Pourquoi les règles basées sur le temps deviennent difficiles à maintenir
Les règles basées sur le temps commencent généralement simplement : « Si un ticket n'a pas de réponse en 2 heures, prévenir quelqu'un. » Puis le workflow s'élargit, les équipes ajoutent des exceptions, et soudain plus personne n'est sûr de ce qui se passe. C'est comme ça que les minuteries SLA et les escalades se transforment en labyrinthe.
Il aide de nommer clairement les éléments en mouvement.
Une minuterie est l'horloge que vous démarrez (ou planifiez) après un événement, comme « ticket passé à Waiting for Agent ». Une escalade est ce que vous faites quand cette horloge atteint un seuil, comme notifier un responsable, changer la priorité ou réaffecter le travail. Un breach est le fait enregistré qui dit « Nous avons manqué le SLA », que vous utilisez pour le reporting, les alertes et le suivi.
Les problèmes apparaissent lorsque la logique temporelle est éparpillée dans l'application : quelques vérifications dans le flux « mettre à jour le ticket », d'autres dans un job nocturne, et des règles ponctuelles ajoutées plus tard pour un client spécial. Chaque morceau a du sens seul, mais ensemble ils créent des surprises.
Symptômes typiques :
- Le même calcul de temps est recopié dans plusieurs flux, et les corrections n'atteignent pas toutes les copies.
- Les cas limites sont oubliés (pause, reprise, réaffectation, basculement de statut, week-ends vs heures ouvrables).
- Une règle se déclenche deux fois parce que deux chemins planifient des minuteries similaires.
- L'audit devient du guessing : on ne peut pas répondre à « pourquoi ceci a été escaladé ? » sans lire toute l'application.
- Les petits changements semblent risqués, donc les équipes ajoutent des exceptions au lieu de réparer le modèle.
L'objectif est un comportement prévisible et facile à modifier plus tard : une source de vérité claire pour le minutage SLA, des états de breach explicites que vous pouvez reporter, et des étapes d'escalade que vous pouvez ajuster sans chercher dans toute la logique visuelle.
Commencez par définir le SLA dont vous avez vraiment besoin
Avant de construire des minuteries, écrivez la promesse exacte que vous mesurez. Beaucoup de logique confuse vient de la tentative de couvrir toutes les règles temporelles possibles dès le départ.
Les types d'SLA courants se ressemblent mais mesurent des choses différentes :
- Première réponse : temps jusqu'à ce qu'un humain envoie la première réponse significative.
- Résolution : temps jusqu'à ce que le problème soit réellement clos.
- En attente du client : temps que vous ne voulez pas compter pendant que vous êtes bloqué.
- Handoff interne : durée pendant laquelle un ticket peut rester dans une file spécifique.
- SLA de réouverture : ce qui se passe lorsqu'un élément « clos » revient.
Ensuite, décidez de ce que « temps » signifie. Temps calendaire compte 24/7. Heures ouvrables comptent seulement les heures de bureau définies (par exemple Lun-Ven, 9h-18h). Si vous n'avez pas vraiment besoin des heures ouvrables, évitez-les au départ. Elles ajoutent des cas limites comme les jours fériés, les fuseaux horaires et les journées partielles.
Définissez ensuite précisément les pauses. Une pause n'est pas juste un « statut changé ». C'est une règle avec un propriétaire. Qui peut la mettre en pause (seul l'agent, le système, le client) ? Quels statuts la mettent en pause (Waiting on Customer, On Hold, Pending Approval) ? Qu'est-ce qui la reprend ? Quand elle reprend, continuez-vous à partir du temps restant ou redémarrez-vous la minuterie ?
Enfin, définissez ce que signifie un breach en termes produit. Un breach doit être une chose concrète que vous pouvez stocker et interroger, par exemple :
- un indicateur de breach (true/false)
- un horodatage de breach (quand la deadline a été manquée)
- un état de breach (Approaching, Breached, Resolved after breach)
Exemple : « First response SLA breached » peut signifier que le ticket reçoit un état Breached, un breached_at et un niveau d'escalade positionné à 1.
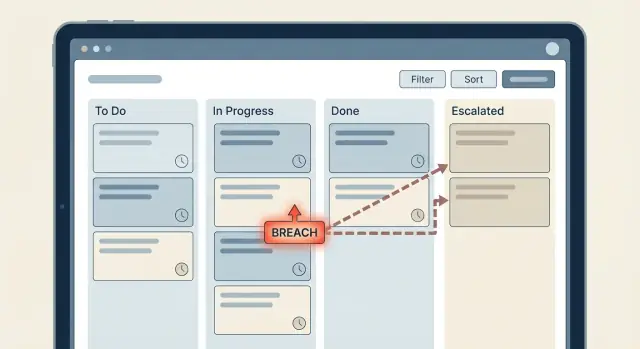
Modélisez le SLA comme des états explicites, pas des conditions dispersées
Si vous voulez que les minuteries SLA et les escalades restent lisibles, traitez le SLA comme une petite machine d'état. Quand la « vérité » est répartie dans de petites vérifications (if now > due, if priority is high, if last reply is empty), la logique visuelle devient vite confuse et les petits changements cassent les choses.
Commencez par un petit ensemble d'états SLA convenus que chaque étape du flux peut comprendre. Pour beaucoup d'équipes, cela couvre la plupart des cas :
- On track
- Warning
- Breached
- Paused
- Completed
Un seul flag breached = true/false est rarement suffisant. Il faut aussi savoir quel SLA a été violé (première réponse vs résolution), s'il est actuellement en pause et si vous avez déjà escaladé. Sans ce contexte, les gens commencent à réextraire du sens depuis les commentaires, les horodatages et les noms de statut. C'est là que la logique devient fragile.
Rendez l'état explicite et enregistrez les horodatages qui l'expliquent. Ensuite les décisions restent simples : votre évaluateur lit l'enregistrement, décide du nouvel état, et tout le reste réagit à cet état.
Champs utiles à stocker avec l'état :
started_at et due_at (quelle horloge tourne et quand elle est due ?)breached_at (quand a-t-on effectivement franchi la ligne ?)paused_at et paused_reason (pourquoi l'horloge s'est-elle arrêtée ?)breach_reason (quelle règle a déclenché le breach, en clair)last_escalation_level (pour ne pas notifier le même niveau deux fois)
Exemple : un ticket passe en « Waiting on customer ». Mettez l'état SLA sur Paused, enregistrez paused_reason = "waiting_on_customer" et arrêtez la minuterie. Quand le client répond, reprenez en définissant un nouveau started_at (ou en dépausant et en recalculant due_at). Finis les chasses aux conditions dispersées.
Concevoir une échelle d'escalade adaptée à votre organisation
Une échelle d'escalade est un plan clair de ce qui se passe quand une minuterie SLA est proche du breach ou a été dépassée. L'erreur est de reproduire l'organigramme dans le workflow. Vous voulez l'ensemble minimal d'étapes qui fait avancer un élément bloqué.
Un escalier simple couramment utilisé : l'agent assigné (Niveau 0) reçoit la première relance, puis le team lead (Niveau 1) est impliqué, et seulement ensuite cela remonte à un manager (Niveau 2). Ça fonctionne parce que ça commence là où le travail peut être fait, et n'augmente l'autorité que si nécessaire.
Pour garder les règles d'escalade maintenables, stockez les seuils d'escalade en tant que données, pas en conditions codées en dur. Mettez-les dans une table ou un objet de paramètres : « premier rappel après 30 minutes » ou « escalader au lead après 2 heures ». Quand les politiques changent, vous mettez à jour un seul endroit au lieu de modifier plusieurs workflows.
Garder les escalades utiles, pas bruyantes
Les escalades deviennent du spam quand elles se déclenchent trop souvent. Ajoutez des garde-fous pour que chaque étape ait un but :
- Une règle de retry (par exemple renvoyer au Niveau 0 une fois si aucune action n'est faite).
- Une fenêtre de cooldown (par exemple ne pas envoyer d'autres notifications pendant 60 minutes après un envoi).
- Une condition d'arrêt (annuler les escalades futures dès que l'élément passe à un statut conforme).
- Un niveau max (ne pas dépasser le Niveau 2 sauf déclenchement manuel).
Décider qui prend la responsabilité après une escalade
Les notifications seules ne débloquent pas un travail si la responsabilité reste floue. Définissez les règles de propriété en amont : le ticket reste-t-il assigné à l'agent, est-il réaffecté au lead, ou va-t-il dans une file partagée ?
Exemple : après une escalade Niveau 1, réaffecter au team lead et mettre l'agent original en observateur. Ça clarifie qui doit agir ensuite et évite que l'élément rebondisse entre les mêmes personnes.
Un pattern maintenable : événements, évaluateur, actions
Lancer une application complète de ticketing
Générez backend, application web et mobile pour votre outil de support interne depuis un seul projet.
La manière la plus simple de garder les minuteries SLA et les escalades maintenables est de les traiter comme un petit système en trois parties : événements, évaluateur et actions. Cela empêche la logique temporelle de se répandre en dizaines de vérifications « if time > X ».
1) Événements : ne consigner que ce qui s'est passé
Les événements sont des faits simples qui ne devraient pas contenir de calculs de minuterie. Ils répondent à « qu'est-ce qui a changé ? » et non à « que doit-on en faire ? ». Événements typiques : ticket créé, agent a répondu, client a répondu, statut changé, pause/reprise manuelle.
Stockez-les comme des horodatages et des champs de statut (par exemple : created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
2) Évaluateur : un seul endroit qui calcule le temps et définit l'état
Créez une seule étape « évaluateur SLA » qui s'exécute après tout événement et selon une planification périodique. Cet évaluateur est le seul endroit qui calcule due_at et le temps restant. Il lit les faits actuels, recalcule les deadlines et écrit des champs d'état SLA explicites comme sla_response_state et sla_resolution_state.
C'est ici que la modélisation de l'état de breach reste claire : l'évaluateur définit des états tels que OK, AtRisk, Breached, au lieu de cacher la logique dans les notifications.
3) Actions : réagir aux changements d'état, pas aux calculs de temps
Les notifications, réaffectations et escalades ne doivent se déclencher qu'à un changement d'état (par exemple : OK -> AtRisk). Gardez l'envoi de messages séparé de la mise à jour de l'état SLA. Ainsi vous pouvez changer qui est notifié sans toucher aux calculs.
Pas à pas : construire minuteries et escalades dans la logique visuelle
Une configuration maintenable ressemble généralement à ceci : quelques champs sur l'enregistrement, une petite table de politique, et un évaluateur unique qui décide de la suite.
1) Préparez les données pour que la logique temporelle ait un seul domicile
Commencez par l'entité qui possède le SLA (ticket, commande, demande). Ajoutez des horodatages explicites et un champ « état SLA courant ». Restez sobre et prévisible.
Ajoutez ensuite une petite table de politique qui décrit les règles au lieu de les coder dans de nombreux flux. Une version simple est une ligne par priorité (P1, P2, P3) avec des colonnes pour les minutes cibles et les seuils d'escalade (par exemple : avertir à 80 %, breach à 100 %). C'est la différence entre changer un enregistrement et modifier cinq workflows.
2) Exécutez un évaluateur planifié, pas des dizaines de minuteries
Au lieu de créer des minuteries séparées partout, utilisez un seul processus planifié qui vérifie périodiquement les éléments (toutes les minutes pour des SLA stricts, toutes les 5 minutes pour beaucoup d'équipes). Le planificateur appelle un évaluateur qui :
- sélectionne les enregistrements encore actifs (non clos)
- calcule « maintenant vs due » et déduit le prochain état
- calcule le prochain moment de vérification (pour éviter des re-vérifications inutiles)
- écrit
sla_state et next_check_at
Ainsi, on débogue un évaluateur, pas des dizaines de minuteries.
3) Rendez les actions déclenchées sur bordure (uniquement au changement)
L'évaluateur devrait produire à la fois le nouvel état et indiquer s'il a changé. N'envoyez des messages ou ne créez des tâches que lors d'un mouvement d'état (par exemple ok -> warning, warning -> breached). Si l'enregistrement reste breached pendant une heure, vous ne voulez pas 12 notifications répétées.
Un pattern pratique : stocker sla_state et last_escalation_level, les comparer aux valeurs recalculées, et n'appeler la messagerie (email/SMS/Telegram) ou la création de tâche qu'en cas de différence.
Gérer les pauses, reprises et changements de statut
Notifier les bonnes personnes
Envoyez des escalades par email, SMS ou Telegram quand l'escalier progresse.
Les pauses sont l'endroit où les règles temporelles partent souvent en vrille. Si vous ne les modélisez pas clairement, votre SLA continuera à tourner quand il ne devrait pas, ou se réinitialisera quand quelqu'un clique sur le mauvais statut.
Une règle simple : un seul statut (ou un petit ensemble) met la minuterie en pause. Un choix courant est Waiting for customer. Quand un ticket passe dans ce statut, enregistrez un horodatage pause_started_at. Quand le client répond et que le ticket quitte ce statut, clôturez la pause en écrivant un pause_ended_at et en ajoutant la durée à paused_total_seconds.
Ne vous contentez pas d'un seul compteur. Capturez chaque fenêtre de pause (début, fin, qui ou quoi l'a déclenchée) pour avoir une piste d'audit. Plus tard, quand quelqu'un demande pourquoi un cas a breaché, vous pourrez montrer qu'il a passé 19 heures en attente du client.
La réaffectation et les changements de statut normaux ne devraient pas redémarrer l'horloge. Gardez les horodatages SLA séparés des champs de propriété. Par exemple, sla_started_at et sla_due_at doivent être définis une fois (à la création, ou quand la politique SLA change), tandis que la réaffectation n'update que assignee_id. Votre évaluateur peut alors calculer le temps écoulé comme : maintenant moins sla_started_at moins paused_total_seconds.
Règles pour garder les minuteries et escalades prévisibles :
- Mettre en pause uniquement sur des statuts explicites (comme Waiting for customer), pas sur des flags souples.
- Reprendre seulement en quittant ce statut, pas sur n'importe quel message entrant.
- Ne jamais réinitialiser le SLA lors d'une réaffectation ; traitez-la comme du routage, pas comme un nouveau cas.
- Autoriser des dérogations manuelles, mais exiger une raison et restreindre qui peut le faire.
- Logger chaque changement de statut et chaque fenêtre de pause.
Scénario exemple : ticket support avec SLA de réponse et de résolution
Gérer les pauses sans bricolages
Ajoutez des fenêtres de pause pour Waiting on Customer avec champs de début, fin et raison.
Une façon simple de tester votre conception est un ticket support avec deux SLA : première réponse en 30 minutes, et résolution complète en 8 heures. C'est là que la logique se casse souvent si elle est dispersée entre écrans et boutons.
Supposons que chaque ticket stocke : state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), plus des horodatages comme created_at, first_agent_reply_at, et resolved_at.
Une timeline réaliste :
- 09:00 Ticket créé (New). Les minuteries de réponse et de résolution démarrent.
- 09:10 Assigné à l'Agent A (toujours Pending pour les deux SLA).
- 09:25 Toujours pas de réponse de l'agent. La réponse atteint 25 minutes et passe en Warning.
- 09:40 Toujours pas de réponse. La réponse atteint 30 minutes et passe en Breached.
- 09:45 L'agent répond. La réponse devient Met (même si elle était Breached, conservez le record de breach et marquez Met pour le reporting).
- 10:30 Le client répond avec plus d'infos. Le ticket passe en InProgress, la résolution continue.
- 11:00 L'agent pose une question. Le ticket passe en WaitingOnCustomer et la minuterie de résolution se met en pause.
- 14:00 Le client répond. Le ticket revient en InProgress et la minuterie de résolution reprend.
- 16:30 Ticket résolu. La résolution devient Met si le temps actif total est inférieur à 8 heures, sinon Breached.
Pour les escalades, conservez une chaîne claire qui se déclenche sur les transitions d'état. Par exemple, quand response passe en Warning, notifiez l'agent assigné. Quand elle passe en Breached, notifiez le team lead et augmentez la priorité.
À chaque étape, mettez à jour le même petit ensemble de champs pour que tout reste simple à raisonner :
- Définir
response_status ou resolution_status sur Pending, Warning, Breached ou Met.
- Écrire les horodatages
*_warning_at et *_breach_at une fois, puis ne plus les écraser.
- Incrémenter
escalation_level (0, 1, 2) et définir escalated_to (Agent, Lead, Manager).
- Ajouter une ligne
sla_events au log avec le type d'événement et qui a été notifié.
- Si nécessaire, définir
priority et due_at pour que l'UI et les rapports reflètent l'escalade.
L'essentiel est que Warning et Breached soient des états explicites. Vous les voyez dans les données, pouvez les auditer, et changer l'escalier plus tard sans chasser des vérifications de minuterie cachées.
La logique SLA devient confuse quand elle se disperse. Une vérification temporelle ajoutée à un bouton ici, une alerte conditionnelle là, et bientôt personne ne peut expliquer pourquoi un ticket a été escaladé. Gardez les minuteries et escalades SLA comme une petite pièce centrale de logique sur laquelle tous les écrans et actions se reposent.
Un piège courant est d'embarquer des vérifications temporelles à de nombreux endroits (UI, handlers API, actions manuelles). La solution est de calculer le statut SLA dans un évaluateur unique et de stocker le résultat sur l'enregistrement. Les écrans devront lire l'état, pas l'inventer.
Un autre piège est de laisser des minuteries utiliser des horloges différentes. Si le navigateur calcule « minutes depuis la création » mais que le backend utilise l'heure serveur, vous verrez des cas limites liés au sommeil, aux fuseaux horaires et aux changements d'heure. Préférez l'heure serveur pour tout ce qui déclenche une escalade.
Les notifications peuvent aussi devenir bruyantes rapidement. Si vous « vérifiez toutes les minutes et envoyez si en retard », les gens risquent d'être spammés chaque minute. Liez les messages aux transitions : « warning sent », « escalated », « breached ». Ainsi vous envoyez une fois par étape et pouvez auditer ce qui s'est passé.
La logique des heures ouvrables est une autre source de complexité accidentelle. Si chaque règle a son propre « si week-end alors… », les mises à jour deviennent pénibles. Placez le calcul des heures ouvrables dans une fonction unique (ou un bloc partagé) qui retourne les « minutes SLA consommées », et réutilisez-la.
Enfin, ne comptez pas uniquement sur le recalcul du breach. Stockez le moment où il s'est produit :
- Sauvegardez
breached_at la première fois que vous détectez un breach, et ne l'écrasez plus.
- Sauvegardez
escalation_level et last_escalated_at pour que les actions soient idempotentes.
- Sauvegardez
notified_warning_at (ou équivalent) pour éviter les alertes répétées.
Exemple : un ticket breach la SLA de réponse à 10:07. Si vous ne faites que recalculer, un changement de statut ou un bug pause/reprise peut faire sembler le breach survenu à 10:42. Avec breached_at = 10:07, le reporting et les postmortems restent cohérents.
Checklist rapide pour une logique SLA maintenable
Modéliser proprement deux SLA
Créez un workflow de support avec SLA de réponse et de résolution suivis séparément.
Avant d'ajouter minuteries et alertes, faites une passe avec pour objectif de rendre les règles lisibles dans un mois.
- Chaque SLA a des limites claires. Notez l'événement de démarrage, l'événement d'arrêt, les règles de pause et ce qui compte comme breach. Si vous ne pouvez pas pointer un événement unique qui démarre l'horloge, votre logique se dispersera en conditions aléatoires.
- Les escalades sont un escalier, pas un tas d'alertes. Pour chaque niveau d'escalade, définissez le seuil (30m, 2h, 1j), qui reçoit l'alerte, un cooldown et le niveau maximal.
- Les changements d'état sont loggés avec contexte. Quand un état SLA change (Running, Paused, Breached, Resolved), stockez qui l'a déclenché, quand et pourquoi.
- Les vérifications planifiées sont sûres à relancer. Votre évaluateur doit être idempotent : s'il s'exécute deux fois pour le même enregistrement, il ne doit pas créer d'escalades en double ni renvoyer les mêmes messages.
- Les notifications viennent des transitions, pas des calculs bruts. Envoyez des alertes quand l'état change, pas quand « now - created_at > X » est vrai.
Un test pratique : prenez un ticket proche du breach et rejouez sa timeline. Si vous ne pouvez pas expliquer ce qui arrivera à chaque changement de statut sans relire tout le workflow, votre modèle est trop dispersé.
Étapes suivantes : implémentez, observez, puis affinez
Construisez la plus petite tranche utile en premier. Choisissez un SLA (par exemple, première réponse) et un niveau d'escalade (par exemple, notifier le team lead). Vous apprendrez plus en une semaine d'utilisation réelle qu'avec une conception parfaite sur papier.
Conservez seuils et destinataires en tant que données, pas en logique. Mettez minutes et heures, règles heures ouvrables, qui reçoit la notification et quelle file possède le cas dans des tables ou enregistrements de config. Ainsi le workflow reste stable pendant que le business ajuste les chiffres et le routage.
Prévoyez tôt une vue de tableau de bord simple. Pas besoin d'un gros système analytique, juste une vision partagée de l'état actuel : on track, warning, breached, escalated.
Si vous construisez cela dans un outil no-code, choisissez une plateforme qui permet de modéliser données, logique et évaluateurs planifiés au même endroit. Par exemple, AppMaster (appmaster.io) prend en charge la modélisation de base de données, les processus métiers visuels et la génération d'apps prêtes pour la production, ce qui s'aligne bien sur le pattern « événements, évaluateur, actions ».
Affinez prudemment en itérant dans cet ordre :
- Ajoutez un niveau d'escalade supplémentaire seulement après que le Niveau 1 fonctionne bien
- Passez d'un SLA à deux (réponse et résolution)
- Ajoutez des règles de pause/reprise (waiting on customer, on hold)
- Affinez les notifications (dédoublonnage, heures calmes, destinataires corrects)
- Révisez chaque semaine : ajustez les seuils dans les données, pas en reconfigurant le flow
Quand vous êtes prêt, construisez d'abord une petite version, puis faites-la croître avec des retours réels et de vrais tickets.
FAQ
Commencez par une définition claire de la promesse que vous mesurez (par exemple première réponse ou résolution) et notez exactement les événements de démarrage, d'arrêt et de pause. Ensuite, centralisez le calcul du temps dans un évaluateur unique qui définit des états SLA explicites au lieu de parsemer des vérifications « if now > X » dans de nombreux workflows.
Une minuterie est l'horloge que vous démarrez ou planifiez après un événement, comme le changement de statut d'un ticket. Une escalade est l'action prise quand un seuil est atteint (par exemple notifier un responsable ou changer la priorité). Un breach est le fait enregistré que le SLA a été manqué, que vous pouvez exploiter pour le reporting.
La première réponse mesure le temps jusqu'à la première réponse humaine significative, tandis que la résolution mesure le temps jusqu'à la fermeture effective du problème. Ils réagissent différemment aux pauses et aux réouvertures, donc les modéliser séparément simplifie les règles et améliore la précision des rapports.
Par défaut, utilisez le temps calendaire car il est plus simple et plus facile à déboguer. N'ajoutez des règles en heures ouvrables que si vous en avez vraiment besoin, car les heures ouvrables introduisent des complexités supplémentaires (jours fériés, fuseaux horaires, calculs de demi-journée).
Modélisez les pauses comme des états explicites liés à des statuts précis (par exemple Waiting on Customer) et enregistrez quand la pause a commencé et quand elle s'est terminée. Au moment de la reprise, continuez soit avec le temps restant, soit recalculer la due dans un seul endroit ; ne laissez pas des basculements de statut aléatoires réinitialiser l'horloge.
Un simple champ breached = true/false masque du contexte important, comme quel SLA a été violé, s'il est en pause, ou si une escalade a déjà eu lieu. Des états explicites tels que On track, Warning, Breached, Paused et Completed rendent le système prévisible et plus facile à auditer et à modifier.
Conservez des horodatages qui expliquent l'état, tels que started_at, due_at, breached_at, et des champs de pause comme paused_at et paused_reason. Stockez aussi le suivi des escalades comme last_escalation_level afin de ne pas notifier le même niveau deux fois.
Créez un escalier réduit qui commence par la personne qui peut agir, puis escalade vers un lead, puis vers un manager seulement si nécessaire. Conservez seuils et destinataires en tant que données (par exemple dans une table de politique) pour que changer le timing d'escalade n'oblige pas à modifier plusieurs workflows.
Attachez les notifications aux transitions d'état comme OK -> Warning ou Warning -> Breached, pas aux vérifications « toujours en retard ». Ajoutez des garde-fous simples comme des fenêtres de cooldown et des conditions d'arrêt pour envoyer un message par étape au lieu de répéter des alertes à chaque exécution planifiée.
Utilisez le pattern événements, évaluateur, actions : les événements enregistrent des faits, l'évaluateur calcule les échéances et définit l'état SLA, et les actions ne réagissent qu'aux changements d'état. Dans AppMaster, vous pouvez modéliser les données, construire l'évaluateur comme un processus visuel et déclencher notifications ou réaffectations à partir des mises à jour d'état tout en centralisant les calculs temporels.