14 avr. 2025·8 min de lecture
Indexation pour panneaux d'administration : optimiser d'abord les filtres principaux
Indexation pour panneaux d'administration : optimisez les filtres que les utilisateurs cliquent le plus : statut, assigné, plages de dates et recherche textuelle, basés sur des schémas de requêtes réels.
Pourquoi les filtres des panneaux d'administration deviennent lents
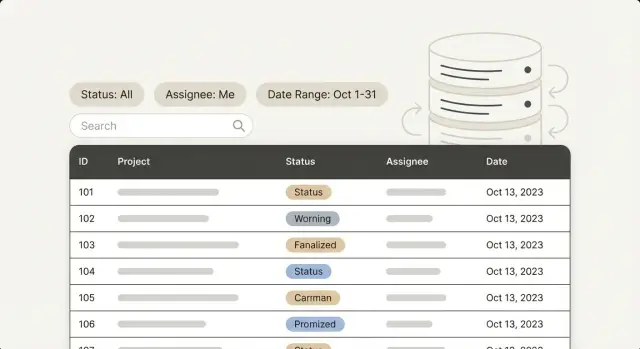
Les panneaux d'administration paraissent généralement rapides au départ. On ouvre une liste, on fait défiler, on clique sur un enregistrement, et on passe à autre chose. Le ralentissement apparaît quand les gens filtrent comme ils travaillent réellement : "Only open tickets", "Assigned to Maya", "Created last week", "Order ID contains 1047". Chaque clic déclenche une attente, et la liste devient collante.
La même table peut être rapide pour un filtre et douloureusement lente pour un autre. Un filtre de statut peut toucher une petite tranche de lignes et revenir vite. Un filtre "créé entre deux dates" peut forcer la base à lire une plage énorme. Un filtre d'assigné peut être rapide seul, puis ralentir dès que vous le combinez avec le statut et le tri.
Les index sont le raccourci qu'utilise une base pour trouver les lignes correspondantes sans lire la table entière. Mais les index ne sont pas gratuits. Ils prennent de la place et ralentissent un peu les insertions et mises à jour. En ajouter trop peut alourdir les écritures sans résoudre le vrai goulot.
Au lieu d'indexer tout, priorisez les filtres qui :
- sont utilisés constamment
- touchent beaucoup de lignes
- créent une attente perceptible
- peuvent être améliorés en toute sécurité avec des index simples et bien adaptés
Ce conseil reste volontairement ciblé. Les premières plaintes de performance sur les listes admin proviennent presque toujours des mêmes quatre types de filtres : status, assignee, plages de dates et champs textes. Une fois que vous comprenez pourquoi ils se comportent différemment, les étapes suivantes sont claires : regardez les requêtes réelles, ajoutez le plus petit index qui leur correspond, et vérifiez que vous avez amélioré le chemin lent sans créer de nouveaux problèmes.
Les motifs de requête derrière le travail admin réel
Les panneaux d'administration sont rarement lents à cause d'un seul grand rapport. Ils ralentissent parce que quelques écrans sont utilisés toute la journée, et ces écrans exécutent beaucoup de petites requêtes en boucle.
Les équipes Ops vivent généralement dans une poignée de files de travail : tickets, commandes, utilisateurs, approbations, demandes internes. Sur ces pages, les filtres se répètent :
- Status, car il reflète le workflow (New, Open, Pending, Done)
- Assignee, car les équipes ont besoin de "mes éléments" et "non assignés"
- Plages de dates, car quelqu'un demande toujours "que s'est-il passé la semaine dernière ?"
- Recherche, soit pour accéder à un élément connu (numéro de commande, email) soit pour balayer du texte (notes, aperçu)
Le travail côté base dépend de l'intention :
- "Parcourir les plus récents" est un motif de scan. Ça ressemble souvent à "montrer les derniers éléments, peut-être filtrés par statut, triés par created time" et c'est paginé.
- "Trouver un élément spécifique" est un motif de lookup. L'admin a déjà un ID, un email, un numéro de ticket ou une référence et s'attend à ce que la base saute directement à un petit ensemble de lignes.
Les panneaux admin combinent aussi les filtres de façon prévisible : "Open + Unassigned", "Pending + Assigned to me", ou "Completed in the last 30 days". Les index sont plus efficaces quand ils correspondent à ces formes de requêtes réelles, pas quand ils correspondent à une simple liste de colonnes.
Si vous construisez des outils admin dans AppMaster, ces motifs sont souvent visibles rien qu'en regardant les écrans de liste les plus utilisés et leurs filtres par défaut. C'est plus simple d'indexer ce qui alimente vraiment le travail quotidien, et non ce qui a l'air bien sur le papier.
Traitez l'indexation comme un triage. Ne commencez pas par indexer chaque colonne qui apparaît dans un menu de filtre. Commencez par les quelques requêtes qui tournent en permanence et qui irritent le plus.
Trouvez les filtres que les gens utilisent réellement
Optimiser un filtre que personne n'utilise, c'est du temps perdu. Pour repérer les vrais points chauds, combinez des signaux :
- Analytique UI : quels écrans reçoivent le plus de vues, quels filtres sont cliqués le plus
- Logs base/API : requêtes les plus fréquentes et les quelques pourcentages les plus lents
- Retours internes : "la recherche est lente" pointe souvent vers un écran précis
- La liste de départ par défaut : ce qui s'exécute dès qu'un admin ouvre le panneau
Dans beaucoup d'équipes, cette vue par défaut ressemble à "Open tickets" ou "New orders". Elle s'exécute à chaque rafraîchissement, changement d'onglet ou retour après une réponse.
Avant d'ajouter un index, regroupez vos requêtes communes selon leur comportement. La plupart des requêtes de liste admin entrent dans quelques catégories :
- Filtres d'égalité :
status = 'open', assignee_id = 42
- Filtres de plage :
created_at entre deux dates
- Tri et pagination :
ORDER BY created_at DESC et récupération de la page 2
- Recherches texte : exact match (order number), préfixe (email starts with), ou recherche contains
Notez la forme exacte pour chaque écran prioritaire, y compris le WHERE, le ORDER BY et la pagination. Deux requêtes qui semblent similaires dans l'UI peuvent se comporter très différemment côté base.
Choisissez un petit premier lot
Commencez par une cible prioritaire : la requête de liste par défaut qui charge en premier. Puis choisissez 2 ou 3 autres requêtes à haute fréquence. C'est souvent suffisant pour couper les plus gros délais sans transformer votre base en musée d'index.
Exemple : une équipe support ouvre une liste Tickets filtrée sur status = 'open', triée par newest, avec un filtre assignee et une plage de dates optionnels. Optimisez cette combinaison exacte en premier. Une fois rapide, passez à l'écran suivant selon l'usage.
Indexer le filtre status sans en faire trop
Le statut est un des premiers filtres ajoutés et l'un des plus faciles à mal indexer.
La plupart des champs status ont une faible cardinalité : quelques valeurs seulement (open, pending, closed). Un index aide surtout quand il peut réduire les résultats à une petite tranche de la table. Si 80% à 95% des lignes partagent le même status, un index sur status seul n'améliorera souvent pas grand-chose. La base devra toujours lire une grosse portion des lignes, et l'index ajoute une surcharge.
Vous ressentez généralement le bénéfice quand :
- un statut est rare (par exemple escalated)
- le statut est combiné avec une autre condition qui réduit fortement le jeu de résultats
- le statut + tri correspond à une vue de liste courante
Un motif courant est "montre-moi les éléments open, les plus récents d'abord." Dans ce cas, indexer le filtre et le tri ensemble bat souvent un index status seul.
Les combinaisons qui rapportent le plus vite :
status + updated_at (filtrer par statut, trier par changements récents)status + assignee_id (vues de files de travail)status + updated_at + assignee_id (uniquement si cette vue exacte est très utilisée)
Les index partiels sont un bon compromis quand un statut domine. Si "open" est la vue principale, indexez seulement les lignes open. L'index reste plus petit et le coût en écriture plus bas.
-- PostgreSQL example: index only open rows, optimized for newest-first lists
CREATE INDEX CONCURRENTLY tickets_open_updated_idx
ON tickets (updated_at DESC)
WHERE status = 'open';
Un test pratique : exécutez la requête admin lente avec et sans le filtre status. Si elle est lente dans les deux cas, un index status seul ne la sauvera pas. Concentrez-vous sur le tri et le second filtre qui réduisent réellement la liste.
Filtrage par assignee : index d'égalité et combos fréquents
Construisez votre panneau d'administration plus vite
Créez un panneau d'administration rapide avec des workflows, filtres et pagination réels en quelques minutes.
Dans la plupart des panneaux admin, assignee est un ID utilisateur stocké sur l'enregistrement : une clé étrangère comme assignee_id. C'est un filtre d'égalité classique, souvent un succès rapide avec un index simple.
Assignee apparaît aussi avec d'autres filtres car il correspond à la façon de travailler. Un responsable support peut filtrer sur "Assigned to Alex" puis restreindre à "Open" pour voir ce qui reste à traiter. Si cette vue est lente, il faut souvent plus qu'un index mono-colonne.
Un bon point de départ est un index composite qui correspond au combo commun :
(assignee_id, status) pour "mes éléments ouverts"(assignee_id, status, updated_at) si la liste est aussi triée par activité récente
L'ordre compte dans les index composites. Mettez d'abord les filtres d'égalité (souvent assignee_id, puis status), et placez la colonne de tri ou de plage en dernier (updated_at). Cela correspond à ce que la base peut utiliser efficacement.
Les éléments non assignés posent souvent problème. Beaucoup de systèmes représentent "unassigned" par NULL dans assignee_id, et les managers filtrent cela fréquemment. Selon votre base et la forme de la requête, les NULL peuvent modifier le plan au point où un index qui fonctionne bien pour les items assignés devient inefficace pour les non-assignés.
Si unassigned est un flux important, choisissez une approche claire et testez :
- Gardez
assignee_id nullable, mais assurez-vous que WHERE assignee_id IS NULL est testé et indexé si nécessaire.
- Utilisez une valeur dédiée (comme un utilisateur spécial "Unassigned") seulement si cela colle à votre modèle.
- Ajoutez un index partiel pour les lignes non assignées si votre base le permet.
Si vous construisez un panneau admin dans AppMaster, journalisez les filtres et tris exacts que votre équipe utilise le plus, puis reproduisez ces motifs avec un petit ensemble d'index bien choisis au lieu d'indexer chaque champ disponible.
Plages de dates : indexer en fonction des usages
Transformez les filtres en vraies écrans
Modélisez vos tables dans PostgreSQL et publiez des vues listes qui correspondent à la façon dont les équipes travaillent réellement.
Les filtres de date apparaissent souvent sous forme de presets rapides comme "last 7 days" ou "last 30 days", plus un sélecteur custom avec une date de début et de fin. Ils paraissent simples, mais peuvent déclencher des travaux très différents sur de grandes tables.
D'abord, soyez clair sur la colonne timestamp que les gens entendent. Utilisez :
created_at pour les vues "nouveaux éléments"updated_at pour les vues "modifications récentes"
Mettez un index btree normal sur cette colonne. Sans cela, chaque clic "last 30 days" peut devenir un scan complet de la table.
Les presets ressemblent souvent à created_at >= now() - interval '30 days'. C'est une condition de plage, et un index sur created_at peut être utilisé efficacement. Si l'UI trie aussi par newest, faire correspondre la direction du tri (par exemple created_at DESC en PostgreSQL) peut aider sur les listes très utilisées.
Quand les plages de dates se combinent avec d'autres filtres (status, assignee), soyez sélectif. Les index composites sont excellents quand le combo est courant. Sinon, ils ajoutent un coût en écriture sans retour.
Règles pratiques :
- Si la plupart des vues filtrent d'abord par status puis par date,
(status, created_at) peut aider.
- Si le status est optionnel mais que la date est toujours présente, gardez un simple index
created_at et évitez trop de composites.
- Ne créez pas chaque combinaison. Chaque nouvel index augmente le stockage et ralentit les écritures.
Les fuseaux horaires et les bornes provoquent beaucoup de bugs de "données manquantes". Si les utilisateurs choisissent des dates (sans heure), décidez comment interpréter la date de fin. Un pattern sûr est début inclusif et fin exclusive : created_at >= start et created_at < end_next_day. Stockez les timestamps en UTC et convertissez les saisies utilisateur en UTC avant la requête.
Exemple : un admin choisit du 10 janvier au 12 janvier et s'attend à voir les éléments du 12 janvier entier. Si votre requête utilise <= '2026-01-12 00:00', vous perdez presque tout le 12 janvier. L'index est correct, mais la logique de bornes est fausse.
Champs texte : recherche exacte vs recherche contains
La recherche texte est souvent le point où les panneaux admin ralentissent, parce que les gens attendent qu'une seule zone trouve tout. La première amélioration est de séparer deux besoins différents : correspondance exacte (rapide et prévisible) vs recherche par contenu (flexible mais plus coûteuse).
Les champs en correspondance exacte incluent order ID, ticket number, email, téléphone ou une référence externe. Ils sont parfaits pour des index classiques. Si les admins collent souvent un ID ou un email, un simple index plus une requête d'égalité rendront l'opération instantanée.
La recherche par contenu survient quand quelqu'un tape un fragment comme "refund" ou "john" et s'attend à trouver des correspondances dans noms, notes et descriptions. C'est souvent implémenté en LIKE %term%. Le wildcard initial empêche un index btree normal de restreindre la recherche, donc la base scanne beaucoup de lignes.
Façons pratiques de réaliser une recherche sans surcharger la base :
- Faites de la recherche exacte une voie prioritaire (ID, email, username) et indiquez-le clairement.
- Pour la recherche "commence par" (
term%), un index standard peut aider et suffit souvent pour les noms.
- N'ajoutez la recherche contains que si les logs ou les plaintes montrent que c'est nécessaire.
- Quand vous l'implémentez, utilisez l'outil adapté (recherche full-text PostgreSQL ou index trigram) au lieu d'espérer qu'un index normal résoudra
LIKE %term%.
Les règles d'entrée comptent plus que la plupart des équipes ne le pensent. Elles réduisent la charge et rendent les résultats cohérents :
- Fixez une longueur minimale pour la recherche contains (par ex. 3+ caractères).
- Normalisez la casse ou utilisez des comparaisons insensibles à la casse de manière cohérente.
- Trim les espaces en début/fin et réduisez les espaces multiples.
- Traitez emails et IDs comme des correspondances exactes par défaut, même s'ils sont saisis dans une barre de recherche générale.
- Si un terme est trop large, invitez l'utilisateur à préciser plutôt que d'exécuter une requête énorme.
Petit exemple : un manager recherche "ann" pour trouver un client. Si votre système exécute LIKE %ann% sur notes, noms et adresses, il peut scanner des milliers d'enregistrements. Si vous vérifiez d'abord les champs exacts (email ou customer ID), puis basculez vers un index texte plus sophistiqué seulement si nécessaire, la recherche reste rapide sans transformer chaque requête en entraînement pour la base.
Un workflow étape par étape pour ajouter des index en sécurité
Concevez données et UI ensemble
Concevez les données, l'interface et la logique ensemble pour que les corrections de performance restent liées à l'usage réel.
Les index sont faciles à ajouter et faciles à regretter. Un workflow sûr vous garde concentré sur les filtres que vos admins utilisent et évite les index "peut-être utiles" qui ralentissent ensuite les écritures.
Commencez par l'usage réel. Récupérez les requêtes principales de deux façons :
- les requêtes les plus fréquentes
- les requêtes les plus lentes
Pour les panneaux admin, il s'agit en général de pages de liste avec filtres et tri.
Ensuite, capturez la forme exacte de la requête telle que la base la voit. Notez le WHERE et le ORDER BY précis, y compris la direction du tri et les combinaisons courantes (par exemple : status = 'open' AND assignee_id = 42 ORDER BY created_at DESC). De petites différences peuvent changer quel index aide.
Utilisez une boucle simple :
- Choisissez une requête lente et un changement d'index à essayer.
- Ajoutez ou ajustez un seul index.
- Re-mesurez avec les mêmes filtres et le même tri.
- Vérifiez que les insertions et mises à jour ne sont pas sensiblement plus lentes.
- Conservez le changement seulement s'il améliore clairement la requête ciblée.
La pagination mérite un test séparé. La pagination par offset (OFFSET 20000) devient souvent plus lente en profondeur, même avec des index. Si les utilisateurs vont régulièrement sur des pages très profondes, envisagez la pagination par curseur ("show items before this timestamp/id") pour que l'index fasse un travail constant sur de grandes tables.
Enfin, gardez un petit registre pour que la liste d'index reste compréhensible des mois plus tard : nom de l'index, table, colonnes (et ordre) et la requête qu'il supporte.
Erreurs courantes d'indexation dans les panneaux admin
Optimisez le chemin doré
Prototypez d'abord la vue liste la plus utilisée, puis affinez les index selon la forme réelle des requêtes.
Le moyen le plus rapide de rendre un panneau admin lent est d'ajouter des index sans vérifier comment les gens filtrent, trient et paginent réellement. Les index coûtent de l'espace et du travail à chaque insertion et mise à jour.
Erreurs qui reviennent le plus
Ces motifs causent la plupart des problèmes :
- Indexer chaque colonne "au cas où"
- Créer un index composite avec le mauvais ordre de colonnes
- Ignorer le tri et la pagination
- S'attendre à ce qu'un index normal résolve un
LIKE '%term%'
- Laisser des index anciens après des changements d'UI
Un scénario courant : une équipe support filtre les tickets par Status = Open, trie par updated time et parcourt les résultats. Si vous n'ajoutez qu'un index sur status, la base peut encore devoir rassembler tous les tickets open et les trier. Un index qui correspond au filtre et au tri ensemble peut retourner la page 1 rapidement.
Moyens rapides de repérer ces problèmes
Avant et après des changements UI admin, faites une courte revue :
- Listez les principaux filtres et le tri par défaut, puis confirmez qu'il existe un index correspondant au pattern
WHERE + ORDER BY.
- Recherchez les wildcards en début (
LIKE '%term%') et décidez si la recherche contains est vraiment nécessaire.
- Cherchez les index dupliqués ou qui se chevauchent.
- Suivez les index non utilisés pendant un moment puis supprimez-les quand vous êtes sûr qu'ils ne servent plus.
Si vous construisez des panneaux admin dans AppMaster sur PostgreSQL, faites de cette revue une partie du déploiement des nouveaux écrans. Les bons index suivent souvent directement les filtres et ordres de tri que votre UI utilise réellement.
Vérifications rapides et étapes suivantes
Avant d'ajouter plus d'index, vérifiez que ceux que vous avez déjà aident les filtres exacts que les gens utilisent chaque jour. Un bon panneau admin paraît instantané sur les chemins courants, pas sur des recherches rares.
Quelques vérifications couvrent la plupart des cas :
- Ouvrez les combinaisons de filtres les plus courantes (status, assignee, plage de dates, plus tri par défaut) et confirmez qu'elles restent rapides à mesure que la table grossit.
- Pour chaque vue lente, vérifiez que la requête utilise un index correspondant à la fois à
WHERE et ORDER BY, pas seulement à une partie.
- Gardez la liste d'index assez petite pour pouvoir expliquer en une phrase l'utilité de chaque index.
- Surveillez les actions fortement écriture (create, update, changement de status). Si elles ralentissent après l'ajout d'index, vous en avez peut-être trop ou des index se chevauchent.
- Décidez ce que "recherche" signifie dans votre UI : correspondance exacte, préfixe ou contains. Votre plan d'indexation doit refléter ce choix.
Une étape pratique suivante est d'écrire vos chemins dorés en phrases simples, par exemple : "Les agents Support filtrent les tickets ouverts, assignés à moi, 7 derniers jours, triés par newest." Utilisez ces phrases pour concevoir un petit ensemble d'index qui les supportent clairement.
Si vous en êtes encore au début, il est utile de modéliser vos données et filtres par défaut avant de créer trop d'écrans. Avec AppMaster (appmaster.io), vous pouvez itérer rapidement sur les vues admin, puis ajouter les quelques index qui correspondent à l'usage réel une fois que les chemins chauds sont évidents.
FAQ
Commencez par les requêtes qui tournent en continu : la vue liste par défaut que les admins voient en premier, plus les 2–3 filtres qu'ils utilisent toute la journée. Mesurez la fréquence et la gêne (les requêtes les plus lentes et les plus utilisées), puis indexez uniquement ce qui réduit clairement le temps d'attente sur ces formes de requêtes précises.
Parce que différents filtres imposent des travaux différents. Certains filtres réduisent fortement le nombre de lignes retournées, tandis que d'autres touchent une grande plage ou nécessitent de trier des ensembles volumineux ; une requête peut profiter d'un index alors qu'une autre finira par scanner et trier beaucoup de données.
Pas toujours. Si la majorité des lignes partagent la même valeur de statut, un index sur status seul ne change souvent pas grand-chose. Il aide davantage quand le statut est rare, ou quand vous indexez le statut conjointement avec le tri ou un autre filtre qui réduit réellement les résultats.
Utilisez un index composite qui correspond exactement aux actions des utilisateurs, par exemple filtrer par status et trier par activité récente. En PostgreSQL, un index partiel peut être une bonne solution quand un statut domine, car il garde l'index petit et ciblé sur le flux de travail courant.
Un simple index sur assignee_id est souvent gagnant car c'est un filtre d'égalité. Si « mes éléments ouverts » est un flux de travail clé, un index composite commençant par assignee_id puis status (et éventuellement la colonne de tri) performe généralement mieux que des index mono-colonne séparés.
Souvent NULL est utilisé pour « unassigned », et WHERE assignee_id IS NULL peut se comporter différemment de WHERE assignee_id = 123. Si les files non assignées sont importantes, testez cette requête précisément et choisissez une stratégie d'index adaptée, souvent un index partiel ciblant les lignes non assignées si la base le permet.
Ajoutez un index btree sur la colonne de timestamp que les gens filtrent réellement : created_at pour les vues « nouveaux éléments », updated_at pour les vues « modifications récentes ». Si vous triez aussi par les plus récents, un index qui correspond à la direction du tri (created_at DESC) peut aider sur les vues très utilisées, mais limitez les composites aux combinaisons réellement fréquentes.
La plupart des bugs viennent des bornes de date, pas des index. Un modèle sûr est start inclusif et end exclusif : convertir les dates choisies par l'utilisateur en UTC et requêter >= start et < end_next_day. Ainsi vous n'excluez pas tout ce qui s'est passé plus tard le jour de fin.
Parce qu'une recherche « contains » comme LIKE %term% ne peut pas utiliser un index btree normal pour sauter directement aux correspondances, elle scanne donc beaucoup de lignes. Traitez d'abord les recherches exactes (ID, email, numéro de commande) comme voie rapide, et n'ajoutez une recherche par contenu que si nécessaire, en utilisant un outil adapté (par exemple full-text ou trigrammes en PostgreSQL).
Trop d'index augmentent l'espace de stockage et ralentissent les insertions et mises à jour, et vous pouvez toujours rater le goulot d'étranglement réel si l'index ne correspond pas au pattern WHERE + ORDER BY. Une boucle plus sûre est de changer un index à la fois, re-mesurer la requête lente visée, et ne garder que les changements qui améliorent clairement le chemin chaud.
Si vous construisez des écrans admin dans AppMaster, journalisez les filtres et tris exacts que votre équipe utilise le plus, puis ajoutez un petit ensemble d'index qui reflètent ces vues réelles au lieu d'indexer chaque champ disponible.