08 févr. 2025·7 min de lecture
Application de gestion des incidents pour équipes informatiques : workflows aux post-mortems
Concevez et construisez une application interne de gestion des incidents pour équipes IT avec flux de gravité, propriété claire, timelines et post-mortems centralisés.
Quel problème une application interne d'incidents résout-elle réellement
Lorsqu'une panne survient, la plupart des équipes prennent ce qui est ouvert : un fil de discussion, une chaîne d'e-mails, peut‑être un tableur que quelqu'un met à jour quand il a une minute. Sous pression, ce système casse toujours de la même façon : la responsabilité devient floue, les horodatages disparaissent et les décisions se perdent dans le défilement.
Une application simple de gestion d'incidents corrige les bases. Elle vous donne un seul endroit où l'incident vit, avec un propriétaire clair, un niveau de gravité sur lequel tout le monde est d'accord et une timeline de ce qui s'est passé et quand. Ce dossier unique compte parce que les mêmes questions reviennent à chaque incident : qui dirige ? Quand cela a-t-il commencé ? Quel est le statut actuel ? Qu'a-t-on déjà essayé ?
Sans ce dossier partagé, les transferts gaspillent du temps. Le support dit une chose aux clients pendant qu'ingénierie en fait une autre. Les responsables demandent des mises à jour qui éloignent les intervenants de la résolution. Ensuite, personne ne peut reconstruire la timeline en toute confiance, et le post-mortem devient de la spéculation.
L'objectif n'est pas de remplacer votre monitoring, votre chat ou votre système de tickets. Les alertes peuvent toujours démarrer ailleurs. Le but est de capturer la trace décisionnelle et de garder les humains alignés.
Les opérations IT et les ingénieurs on‑call l'utilisent pour coordonner la réponse. Le support l'utilise pour donner des mises à jour précises rapidement. Les managers l'utilisent pour suivre l'avancement sans interrompre les intervenants.
Scénario d'exemple : une panne P1 de l'alerte à la clôture
À 9h12, le monitoring signale une montée des erreurs 500 sur le portail client. Un agent support rapporte aussi : « L'authentification échoue pour la plupart des utilisateurs. » Le responsable IT on‑call ouvre un incident P1 dans l'application et attache la première alerte ainsi qu'une capture d'écran du support.
Avec un P1, le comportement change vite. Le propriétaire de l'incident fait venir le responsable backend, le propriétaire base de données et un référent support. Le travail non essentiel est mis en pause. Les déploiements planifiés s'arrêtent. L'équipe s'accorde sur une cadence de mises à jour (par exemple toutes les 15 minutes). Une conférence partagée démarre, mais le dossier d'incident reste la source de vérité.
À 9h18, quelqu'un demande : « Qu'est‑ce qui a changé ? » La timeline montre un déploiement à 8h57, mais elle ne précise pas quoi. Le responsable backend effectue quand même un rollback. Les erreurs baissent, puis reviennent. L'équipe suspecte alors la base de données.
La plupart des retards apparaissent à quelques endroits prévisibles : transferts peu clairs (« Je pensais que c'était toi qui vérifiais »), contexte manquant (changements récents, risques connus, propriétaire actuel) et mises à jour dispersées entre chat, tickets et e‑mails.
À 9h41, le propriétaire base de données trouve une requête lancée en boucle par un job planifié. Il désactive le job, redémarre le service affecté et confirme la récupération. La gravité est abaissée en P2 pour surveillance.
Une bonne clôture n'est pas « ça refonctionne ». C'est un dossier propre : une timeline minute par minute, la cause racine finale, qui a pris quelles décisions, ce qui a été mis en pause et les travaux de suivi avec propriétaires et dates d'échéance. C'est ainsi qu'un P1 stressant devient un apprentissage au lieu d'une douleur répétée.
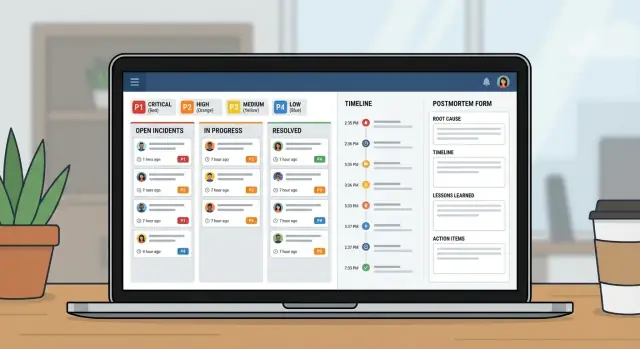
Modèle de données : la structure la plus simple qui fonctionne encore
Un bon outil d'incident repose essentiellement sur un bon modèle de données. Si les enregistrements sont vagues, les gens se disputeront sur ce qu'est l'incident, quand il a commencé et ce qui est encore ouvert.
Gardez les entités centrales proches du vocabulaire des équipes IT :
- Incident : le conteneur de ce qui s'est passé
- Service : ce que l'entreprise exploite (API, base de données, VPN, facturation)
- Utilisateur : intervenants et parties prenantes
- Mise à jour : notes courtes de statut au fil du temps
- Tâche : travaux concrets pendant et après l'incident
- Post-mortem : un compte rendu lié à l'incident, avec éléments d'action
Pour éviter la confusion ensuite, donnez à l'Incident quelques champs structurés toujours remplis. Le texte libre aide, mais ne doit pas être la seule source de vérité. Un minimum pratique : un titre clair, l'impact (ce que ressentent les utilisateurs), les services affectés, l'heure de début, le statut actuel et la gravité.
Les relations importent plus que les champs supplémentaires. Un incident doit avoir de nombreuses mises à jour et tâches, plus un lien many‑to‑many vers les services (les pannes touchent souvent plusieurs systèmes). Un post‑mortem doit être en one‑to‑one avec un incident, pour qu'il n'y ait qu'une histoire finale.
Exemple : un incident « Erreurs à la validation » est lié aux services « Payments API » et « PostgreSQL », a des mises à jour toutes les 15 minutes et des tâches comme « Rollback du déploiement » et « Ajouter un garde‑fou de retry ». Plus tard, le post‑mortem capture la cause racine et crée des tâches à plus long terme.
Niveaux de gravité et cibles de réponse
Quand les gens sont stressés, ils ont besoin d'étiquettes simples qui signifient la même chose pour tous. Définissez P1 à P4 en langage clair et affichez la définition juste à côté du champ de gravité.
- P1 (Critique) : Service central en panne ou risque de perte de données. Nombreux utilisateurs bloqués.
- P2 (Élevé) : Fonction majeure cassée, mais il existe un contournement ou la portée est limitée.
- P3 (Moyen) : Problème non urgent, petit groupe affecté, faible impact business.
- P4 (Faible) : Bug cosmétique ou mineur, à planifier plus tard.
Les cibles de réponse doivent se lire comme des engagements. Un basique simple (à adapter selon votre réalité) :
| Gravité | Première réponse (ack) | Première mise à jour | Fréquence des mises à jour |
|---|
| P1 | 5 min | 15 min | toutes les 30 min |
| P2 | 15 min | 30 min | toutes les 60 min |
| P3 | 4 heures | 1 jour ouvré | quotidien |
| P4 | 2 jours ouvrés | 1 semaine | hebdomadaire |
Gardez les règles d'escalade mécaniques. Si un P2 dépasse sa cadence de mise à jour ou si l'impact augmente, le système doit suggérer une révision de la gravité. Pour éviter les oscillations, limitez qui peut changer la gravité (souvent le propriétaire de l'incident ou l'incident commander), tout en permettant à quiconque de demander une révision via un commentaire.
Une matrice d'impact rapide aide aussi les équipes à choisir la gravité rapidement. Capturez‑la sous forme de quelques champs requis : utilisateurs affectés, risque de revenu, sécurité, conformité et existence d'un contournement.
États de workflow qui guident les gens sous stress
Choisissez comment vous le livrez
Déployez sur AppMaster Cloud ou votre cloud, ou exportez le code source pour l'auto-hébergement.
Pendant un incident, les gens n'ont pas besoin de plus d'options. Ils ont besoin d'un petit ensemble d'états qui rendent l'étape suivante évidente.
Commencez par les étapes que vous suivez déjà les jours calmes, puis gardez la liste courte. Si vous avez plus de 6 ou 7 états, les équipes se disputeront sur la formulation au lieu de résoudre le problème.
Un ensemble pratique :
- New : alerte reçue, pas encore confirmée
- Acknowledged : quelqu'un en est responsable, première réponse lancée
- Investigating : impact confirmé, cause probable réduite
- Mitigating : actions en cours pour réduire l'impact
- Monitoring : le service semble stable, on surveille une rechute
- Resolved : service rétabli, prêt pour revue
Chaque statut a besoin de règles d'entrée et de sortie claires. Par exemple :
- On ne peut pas passer à Acknowledged tant qu'un propriétaire n'est pas défini et qu'une prochaine action n'est pas écrite en une phrase.
- On ne peut pas passer à Mitigating tant qu'il n'existe pas au moins une tâche concrète d'atténuation (rollback, désactivation d'un feature flag, ajout de capacité).
Utilisez les transitions pour imposer les champs que les gens oublient. Une règle commune : on ne peut pas clôturer un incident sans un court résumé de la cause racine et au moins un élément de suivi. Si « RCA: TBD » est autorisé, cela a tendance à le rester.
La page d'incident doit répondre à trois questions en un coup d'œil : qui en est propriétaire, quelle est l'action suivante et quand la dernière mise à jour a‑t‑elle été postée.
Assignation et règles d'escalade
Quand un incident devient bruyant, la façon la plus rapide de perdre du temps est une responsabilité floue. Votre app doit désigner une personne clairement responsable, tout en facilitant l'aide des autres.
Un schéma simple qui tient la route :
- Propriétaire principal : pilote la réponse, publie les mises à jour, décide des étapes suivantes
- Aides : prennent des tâches (diagnostic, rollback, communication) et rendent compte
- Approbatuer : un lead qui peut approuver des actions risquées
L'assignation doit être explicite et auditable. Suivez qui a défini le propriétaire, qui l'a accepté et chaque changement ultérieur. L'"acceptation" compte, car assigner quelqu'un qui dort ou est hors ligne n'est pas une vraie propriété.
L'assignation on‑call vs basée sur l'équipe dépend souvent de la gravité. Pour P1/P2, par défaut utilisez la rotation on‑call pour qu'il y ait toujours un propriétaire nommé. Pour les gravités plus faibles, l'assignation par équipe peut fonctionner, mais exigez quand même un propriétaire principal dans un délai court.
Prévoyez les vacances et indisponibilités dans votre processus humain, pas seulement dans vos systèmes. Si la personne assignée est marquée indisponible, redirigez vers un on‑call secondaire ou un lead d'équipe. Gardez cela automatique, mais visible pour pouvoir corriger rapidement.
L'escalade doit se déclencher à la fois sur la gravité et le silence. Un point de départ utile :
- P1 : escalade si pas d'acceptation du propriétaire en 5 minutes
- P1/P2 : escalade si pas de mise à jour en 15 à 30 minutes
- Toute gravité : escalade si l'état reste « Investigating » au‑delà de la cible de réponse
Timelines, mises à jour et notifications
Obtenez le bon modèle de données
Concevez incidents, services, mises à jour, tâches et post-mortems avec un schéma structuré.
Une bonne timeline est une mémoire partagée. Pendant un incident, le contexte disparaît vite. Si vous capturez les bons moments en un seul endroit, les transferts deviennent plus faciles et le post‑mortem est en grande partie rédigé avant même d'ouvrir un document.
Ce que la timeline doit capturer
Rendez la timeline opinionnée. Ne la transformez pas en journal de chat. La plupart des équipes s'appuient sur un petit ensemble d'entrées : détection, accusé de réception, étapes clés d'atténuation, restauration et clôture.
Chaque entrée a besoin d'un horodatage, d'un auteur et d'une courte description en langage clair. Quelqu'un qui arrive tard doit pouvoir lire cinq entrées et comprendre la situation.
Types de mises à jour qui clarifient
Différentes mises à jour servent différents publics. Il est utile que les entrées aient un type, par exemple note interne (détails bruts), mise à jour orientée client (formulation sûre), décision (pourquoi l'option A a été choisie) et transfert (ce que la personne suivante doit savoir).
Les rappels doivent suivre la gravité, pas les préférences personnelles. Si le minuteur sonne, alertez d'abord le propriétaire actuel, puis escaladez si c'est manqué de façon répétée.
Les notifications doivent être ciblées et prévisibles. Un petit jeu de règles suffit : notifier à la création, au changement de gravité, à la restauration et aux mises à jour en retard. Évitez de notifier toute l'entreprise pour chaque changement.
Post-mortems qui aboutissent à du suivi réel
Rendez les workflows d'incident exécutables
Transformez vos gravités, états et champs obligatoires en règles de workflow réelles.
Un post-mortem doit faire deux choses : expliquer ce qui s'est passé en langage clair et rendre la même défaillance moins probable la fois suivante.
Gardez le compte rendu court et forcez‑le à produire des actions. Une structure pratique comprend : résumé, impact client, cause racine, correctifs appliqués et suivis.
Les suivis sont l'essentiel. Ne les laissez pas en fin de paragraphe. Transformez chaque suivi en une tâche tracée avec un propriétaire et une date d'échéance, même si l'échéance est « sprint suivant ». C'est ce qui différencie « on devrait améliorer le monitoring » de « Alex ajoute une alerte de saturation de connexions DB d'ici vendredi ».
Les tags rendent les post-mortems utiles ultérieurement. Ajoutez 1 à 3 thèmes à chaque incident (lacune de monitoring, déploiement, capacité, process). Après un mois, vous pourrez répondre à des questions basiques comme si la plupart des P1 proviennent de releases ou d'alertes manquantes.
Les preuves devraient être faciles à attacher, pas obligatoires. Prévoyez des champs optionnels pour captures d'écran, extraits de logs et références à des systèmes externes (IDs de ticket, fils de discussion, numéros de dossier fournisseur). Gardez‑le léger pour que les gens le remplissent réellement.
Pas à pas : construire le mini‑système en tant qu'application interne
Considérez cela comme un petit produit, pas un tableur avec des colonnes en plus. Une bonne application d'incidents est en réalité trois vues : ce qui se passe maintenant, quoi faire ensuite et ce qu'il faut apprendre après.
Commencez par esquisser les écrans que les gens ouvriront sous pression :
- File (Queue) : incidents ouverts avec quelques filtres (Open, Needs update, Waiting on vendor, Closed)
- Page incident : gravité, propriétaire, statut actuel, timeline, tâches et dernière mise à jour
- Page post-mortem : impact, cause racine, éléments d'action, propriétaires
Construisez le modèle de données et les permissions ensemble. Si tout le monde peut tout éditer, l'historique devient confus. Une approche courante : accès large en lecture pour l'IT, changements contrôlés d'état/gravité, les intervenants peuvent ajouter des mises à jour et un propriétaire unique pour l'approbation du post-mortem.
Ajoutez ensuite des règles de workflow qui évitent les incidents à moitié remplis. Les champs obligatoires doivent dépendre de l'état. Vous pouvez autoriser « New » avec juste titre et rapporteur, mais exiger qu'« Mitigating » inclue un résumé d'impact, et exiger qu'« Resolved » contienne un résumé de la cause racine plus au moins un suivi.
Enfin, testez en rejouant 2 à 3 incidents passés. Faites jouer un rôle d'incident commander et un rôle de répondant. Vous verrez vite quels états sont flous, quels champs les gens sautent et où il faut de meilleurs défauts.
Donnez aux intervenants une file claire
Affichez incidents ouverts, besoins de mise à jour et en attente de fournisseur dans une vue focalisée.
La plupart des systèmes d'incident échouent pour des raisons simples : les gens n'arrivent pas à se souvenir des règles quand ils sont stressés, et l'app ne capture pas les faits dont vous aurez besoin ensuite.
Erreur 1 : Trop de niveaux de gravité ou d'états
Si vous avez six niveaux de gravité et dix états, les gens devineront. Gardez 3 à 4 gravités et concentrez les états sur ce que quelqu'un doit faire ensuite.
Erreur 2 : Pas de propriétaire unique
Quand tout le monde « surveille », personne ne pilote. Exigez un propriétaire nommé avant de permettre la progression de l'incident et rendez les transferts explicites.
Erreur 3 : Timelines en lesquelles on ne peut pas avoir confiance
Si « ce qui s'est passé quand » dépend du chat, les post-mortems deviennent des débats. Capturez automatiquement les horodatages d'ouverture, d'accusé de réception, d'atténuation et de résolution, et gardez les entrées de timeline courtes.
Évitez aussi de clore avec des notes vagues de cause racine comme « problème réseau ». Exigez une phrase claire de cause racine plus au moins un pas concret suivant.
Checklist de lancement et prochaines étapes
Avant de déployer à toute l'organisation IT, testez les fondamentaux sous stress. Si les gens ne trouvent pas le bon bouton en deux minutes, ils retourneront aux fils de discussion et aux tableurs.
Concentrez‑vous sur un petit ensemble de vérifications de lancement : rôles et permissions, définitions claires des gravités, propriété imposée, règles de rappel et chemin d'escalade quand les cibles de réponse sont manquées.
Pilotez avec une équipe et quelques services qui génèrent des alertes fréquentes. Utilisez‑le pendant deux semaines, puis ajustez selon les incidents réels.
Si vous voulez construire cela comme un outil interne unique sans assembler tableurs et applis séparées, AppMaster (appmaster.io) est une option. Il permet de créer un modèle de données, des règles de workflow et des interfaces web/mobile au même endroit, ce qui convient bien à une file d'incidents, à une page d'incident et au suivi des post-mortems.
FAQ
Remplace les mises à jour éparpillées par un enregistrement partagé qui répond vite aux questions essentielles : qui est responsable, ce que voient les utilisateurs, ce qui a été tenté et quelle est la suite. Cela réduit le temps perdu lors des transferts, les messages contradictoires et les interruptions "peux-tu résumer ?".
Ouvrez l'incident dès que vous pensez qu'il y a un impact réel pour les clients ou l'entreprise, même si la cause n'est pas encore claire. Vous pouvez l'ouvrir avec un titre provisoire et « impact inconnu », puis préciser au fur et à mesure que vous confirmez la gravité et l'étendue.
Gardez-le petit et structuré : un titre clair, un résumé d'impact, les services affectés, l'heure de début, le statut actuel, la gravité et un propriétaire unique. Ajoutez des mises à jour et des tâches au fil de l'incident, mais ne comptez pas uniquement sur du texte libre pour les faits essentiels.
Utilisez 3 à 4 niveaux avec des significations simples qui n'appellent pas de débat. Par défaut : P1 pour panne critique ou risque de perte de données, P2 pour impact majeur avec contournement possible ou portée limitée, P3 pour problèmes à moindre impact et P4 pour problèmes cosmétiques ou mineurs.
Suivez des cibles qui ressemblent à des engagements : temps d'accusé de réception, temps avant la première mise à jour et cadence des mises à jour. Déclenchez ensuite des rappels et des escalades quand la cadence est manquée, car le silence est souvent l'échec réel pendant un incident.
Visez environ six états : New, Acknowledged, Investigating, Mitigating, Monitoring et Resolved. Chaque état doit rendre l'étape suivante évidente, et les transitions doivent imposer ce que les gens oublient sous stress, par exemple exiger un propriétaire avant Acknowledged ou un résumé de cause racine avant la clôture.
Exigez un propriétaire principal responsable de piloter la réponse et de publier les mises à jour. Suivez l'acceptation explicitement afin de ne pas "assigner" quelqu'un qui est hors ligne, et enregistrez les transferts de responsabilité pour que la personne suivante ne recommence pas l'enquête depuis zéro.
Capturez seulement les moments importants : détection, accusé de réception, décisions clés, actions d'atténuation, restauration et clôture, chacun avec horodatage et auteur. Traitez la timeline comme une mémoire partagée, pas comme un transcript de chat, afin qu'une personne arrivée tard puisse comprendre la situation en quelques entrées.
Restez concis et axé sur l'action : ce qui s'est passé, impact client, cause racine, ce qui a été changé pendant l'atténuation et éléments de suivi avec propriétaires et dates d'échéance. Le compte rendu est utile, mais ce sont les tâches suivies qui empêchent la répétition du même incident.
Oui, si vous modélisez incidents, mises à jour, tâches, services et post-mortems comme de vraies données et appliquez des règles de workflow dans l'app. Avec AppMaster (appmaster.io), les équipes peuvent créer ce modèle de données ainsi que des écrans web/mobile et des validations d'état en un seul endroit, pour éviter de retomber dans les feuilles de calcul sous pression.