22 août 2025·7 min de lecture
Déboguer les intégrations webhook : signatures, réessais, rejouement, journaux d'événements
Apprenez à déboguer les intégrations webhook : standardiser les signatures, gérer les réessais en toute sécurité, activer le rejouement et conserver des journaux d’événements facilement consultables.
Pourquoi les intégrations webhook deviennent une boîte noire
Un webhook, c’est simplement une application qui appelle la vôtre quand quelque chose se produit. Un fournisseur de paiements vous dit « payment succeeded », un outil de formulaires indique « nouvelle soumission », ou un CRM rapporte « deal updated ». Ça paraît simple jusqu'à ce que quelque chose casse et que vous réalisiez qu’il n’y a aucun écran à ouvrir, aucun historique évident, et aucun moyen sûr de rejouer ce qui s’est passé.
C’est pour ça que les problèmes de webhook sont si frustrants. La requête arrive (ou n’arrive pas). Votre système la traite (ou échoue). Le premier signal est souvent un ticket vague du type « les clients ne peuvent pas finaliser la commande » ou « le statut ne s’est pas mis à jour ». Si le fournisseur réessaye, vous pouvez obtenir des doublons. S’ils modifient un champ du payload, votre parser peut se casser pour certains comptes seulement.
Symptômes courants :
- Événements « manquants » où vous ne savez pas s’ils n’ont jamais été envoyés ou simplement non traités
- Livraisons en double qui créent des effets secondaires doublons (deux factures, deux emails, deux changements de statut)
- Changements de payload (nouveaux champs, champs manquants, mauvais types) qui échouent seulement parfois
- Vérifications de signature qui passent dans un environnement et échouent dans un autre
Une configuration webhook débuggable est l’inverse du tâtonnement. Elle est traçable (vous pouvez retrouver chaque livraison et ce que vous en avez fait), répétable (vous pouvez rejouer en toute sécurité un événement passé), et vérifiable (vous pouvez prouver l’authenticité et les résultats du traitement). Quand quelqu’un demande « qu’est-il arrivé à cet événement ? », vous devriez pouvoir répondre avec des preuves en quelques minutes.
Si vous construisez des applications sur une plateforme comme AppMaster, cette mentalité est d’autant plus importante. La logique visuelle change rapidement, mais vous avez toujours besoin d’un historique clair des événements et d’un rejouement sûr pour que les systèmes externes ne deviennent jamais une boîte noire.
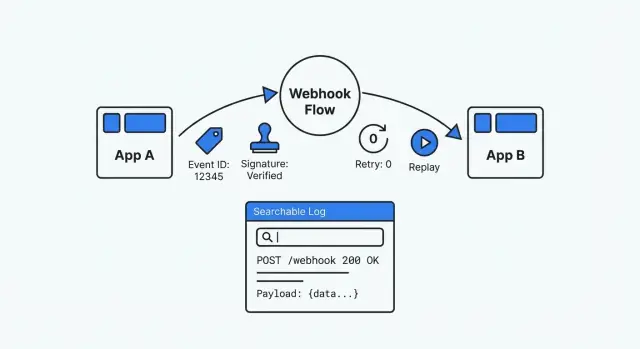
Les données minimales pour rendre les webhooks observables
Quand vous déboguez sous pression, vous avez besoin des mêmes bases à chaque fois : un enregistrement fiable, interrogeable et rejouable. Sans cela, chaque webhook devient une énigme isolée.
Décidez ce que signifie un seul « événement » webhook dans votre système. Traitez-le comme un reçu : une requête entrante = un événement stocké, même si le traitement survient plus tard.
Au minimum, stockez :
- Event ID : utilisez l’ID du fournisseur quand disponible ; sinon générez-en un.
- Données de réception de confiance : quand vous l’avez reçu, et qui l’a envoyé (nom du fournisseur, endpoint, IP si vous la conservez). Gardez
received_at séparé des timestamps dans le payload.
- Statut de traitement plus raison : utilisez un petit ensemble d’états (received, verified, handled, failed) et stockez une courte raison d’échec.
- Requête brute et vue parsée : sauvegardez le corps brut et les headers exactement tels que reçus (pour les audits et vérifications de signature), plus une vue JSON parsée pour la recherche et le support.
- Clés de corrélation : un ou deux champs par lesquels vous pouvez rechercher (order_id, invoice_id, user_id, ticket_id).
Exemple : un fournisseur de paiements envoie « payment_succeeded » mais votre client apparaît toujours impayé. Si votre journal d’événements inclut la requête brute, vous pouvez confirmer la signature et voir le montant exact et la devise. Si il inclut aussi invoice_id, le support peut retrouver l’événement depuis la facture, voir qu’il est bloqué en « failed », et fournir à l’ingénierie une raison d’erreur claire.
Dans AppMaster, une approche pratique est une table “WebhookEvent” dans le Data Designer, avec un Business Process qui met à jour le statut à chaque étape. L’outil n’est pas l’objet : c’est l’enregistrement cohérent qui compte.
Standardiser la structure des événements pour que les logs soient lisibles
Si chaque fournisseur envoie une forme de payload différente, vos logs paraîtront toujours désordonnés. Une enveloppe d’événement stable accélère le débogage car vous pouvez scanner les mêmes champs à chaque fois, même quand les données changent.
Une enveloppe utile inclut typiquement :
id (ID unique de l’événement)type (nom clair d’événement comme invoice.paid)created_at (quand l’événement est survenu, pas quand vous l’avez reçu)data (le payload métier)version (par exemple v1)
Voici un exemple simple que vous pouvez logger et stocker tel quel:
{
"id": "evt_01H...",
"type": "payment.failed",
"created_at": "2026-01-25T10:12:30Z",
"version": "v1",
"correlation": {"order_id": "A-10492", "customer_id": "C-883"},
"data": {"amount": 4990, "currency": "USD", "reason": "insufficient_funds"}
}
Choisissez un style de nommage (snake_case ou camelCase) et respectez-le. Soyez strict sur les types aussi : ne faites pas de amount une chaîne de caractères parfois et un nombre d’autres fois.
Le versioning est votre filet de sécurité. Quand vous devez changer des champs, publiez v2 tout en gardant v1 opérationnel pendant un certain temps. Ça évite des incidents support et facilite grandement le débogage des mises à jour.
Vérification de signature : cohérente et testable
Les signatures empêchent que votre endpoint webhook devienne une porte ouverte. Sans vérification, n’importe qui connaissant votre URL peut envoyer de faux événements, et des attaquants peuvent tenter d’altérer de vraies requêtes.
Le pattern le plus courant est une signature HMAC avec un secret partagé. L’émetteur signe le corps brut de la requête (idéal) ou une chaîne canonique. Vous recalculrez le HMAC et comparerez. Beaucoup de fournisseurs incluent un timestamp dans ce qu’ils signent pour éviter les rejouements ultérieurs.
Une routine de vérification doit être ennuyeusement simple et cohérente :
- Lisez le corps brut exactement comme reçu (avant parsing JSON).
- Recalculez la signature en utilisant l’algorithme du fournisseur et votre secret.
- Comparez avec une fonction en temps constant.
- Rejetez les timestamps trop anciens (utilisez une fenêtre courte, quelques minutes).
- Fail closed : si quelque chose manque ou est mal formé, traitez comme invalide.
Rendez-la testable. Placez la vérification dans une petite fonction et écrivez des tests avec des échantillons connus bons et mauvais. Une perte de temps commune est de signer le JSON parsé au lieu des octets bruts.
Prévoyez la rotation des secrets dès le premier jour. Supportez deux secrets actifs pendant les transitions : essayez le plus récent d’abord, puis retombez sur le secret précédent.
Quand la vérification échoue, loggez suffisamment pour déboguer sans divulguer les secrets : nom du fournisseur, timestamp (et s’il était trop ancien), version de la signature, request/correlation ID, et un petit hash du corps brut (pas le corps lui-même).
Réessais et idempotence sans effets secondaires en double
Déployer ou exporter le code source
Déployez sur votre cloud ou exportez du vrai code source quand vous avez besoin d'un contrôle total.
Les réessais sont normaux. Les fournisseurs réessaient en cas de timeouts, soucis réseau ou réponses 5xx. Même si votre système a effectué le travail, le fournisseur peut ne pas avoir reçu votre réponse à temps, donc le même événement peut arriver de nouveau.
Décidez à l’avance quelles réponses signifient « réessayer » vs « arrêter ». Beaucoup d’équipes utilisent des règles comme :
- 2xx : accepté, arrêter les réessais
- 4xx : problème de configuration ou requête, généralement arrêter les réessais
- 408/429/5xx : échec temporaire ou limitation, réessayer
L’idempotence signifie que vous pouvez traiter le même événement plusieurs fois sans répéter les effets secondaires (facturer deux fois, créer des commandes en double, envoyer deux emails). Traitez les webhooks comme une livraison at-least-once.
Un modèle pratique est de stocker l’ID unique de chaque événement entrant avec le résultat du traitement. À une livraison répétée :
- S’il a été réussi, renvoyez 2xx et ne faites rien.
- S’il a échoué, relancez le traitement interne (ou renvoyez un statut réessayable).
- S’il est en cours, évitez le travail parallèle et renvoyez une courte réponse « accepted ».
Pour les réessais internes, utilisez un backoff exponentiel et plafonnez les tentatives. Après le plafond, passez l’événement en état « needs review » avec la dernière erreur. Dans AppMaster, cela se mappe naturellement à une petite table pour les IDs d’événements et statuts, plus un Business Process qui programme les réessais et route les échecs répétés.
Outils de rejouement qui aident l'assistance à réparer vite
Les réessais sont automatiques. Le rejouement est intentionnel.
Un outil de rejouement transforme « on pense que ça a été envoyé » en un test répétable avec exactement le même payload. Il n’est sûr que si deux choses sont vraies : idempotence et piste d’audit. L’idempotence évite la double facturation, l’envoi en double ou l’expédition multiple. La piste d’audit montre ce qui a été rejoué, par qui, et ce qui s’est passé.
Single-event replay vs time-range replay
Le rejouement d’un seul événement est le cas courant du support : un client, un événement échoué, le renvoyer après correction. Le rejouement par plage temporelle sert pour des incidents : une panne fournisseur sur une fenêtre donnée et il faut renvoyer tout ce qui a échoué.
Gardez la sélection simple : filtrez par type d’événement, plage temporelle et statut (failed, timed out, ou livré mais non accusé de réception), puis rejouez un événement ou un lot.
Garde-fous qui empêchent les accidents
Le rejouement doit être puissant mais pas dangereux. Quelques garde-fous aident :
- Contrôles d'accès basés sur les rôles
- Limites de taux par destination
- Note de raison requise stockée avec l’enregistrement d’audit
- Approbation facultative pour les gros lots
- Mode dry-run qui valide sans envoyer
Après un rejouement, affichez les résultats à côté de l’événement original : succès, toujours en échec (avec la dernière erreur), ou ignoré (doublon détecté via l’idempotence).
Journaux d'événements utiles pendant les incidents
Gérer les réessais sans doublons
Dédupliquez par ID d'événement et évitez que les réessais ne créent des factures ou emails en double.
Quand un webhook casse pendant un incident, vous avez besoin de réponses en quelques minutes. Un bon log raconte une histoire claire : ce qui est arrivé, ce que vous en avez fait, et où ça s’est arrêté.
Stockez la requête brute exactement telle que reçue : timestamp, chemin, méthode, headers, et corps brut. Ce payload brut est votre vérité de référence quand les fournisseurs changent des champs ou que votre parser mal interprète des données. Masquez les valeurs sensibles avant de sauvegarder (headers Authorization, tokens, et toute donnée personnelle ou de paiement non nécessaire).
Les données brutes seules ne suffisent pas. Stockez aussi une vue parsée et interrogeable : type d’événement, ID externe, identifiants client/compte, IDs d’objets liés (invoice_id, order_id), et votre ID de corrélation interne. C’est ce qui permet au support de trouver « tous les événements pour le client 8142 » sans ouvrir chaque payload.
Pendant le traitement, conservez une courte timeline d’étapes avec un libellé cohérent, par exemple : « validated signature », « mapped fields », « checked idempotency », « updated records », « queued follow-ups ».
La rétention compte. Gardez assez d’historique pour couvrir les retards et litiges réels, mais ne stockez pas indéfiniment. Envisagez de supprimer ou anonymiser d’abord les payloads bruts tout en conservant des métadonnées légères plus longtemps.
Étape par étape : construire un pipeline webhook débogable
Standardiser les événements entre fournisseurs
Définissez une enveloppe d'événement unique avec types, versions et champs de corrélation pour un support à long terme.
Construisez le récepteur comme un petit pipeline avec des points de contrôle clairs. Chaque requête devient un événement stocké, chaque run de traitement devient une tentative, et chaque échec devient interrogeable.
Receiver pipeline
Traitez le endpoint HTTP comme une simple ingestion. Faites le minimum en amont, puis déplacez le traitement vers un worker pour éviter que des timeouts ne créent des comportements mystérieux.
- Capturez les headers, le corps brut, le timestamp de réception et le fournisseur.
- Vérifiez la signature (ou stockez un statut clair « failed verification »).
- Mettez en file le traitement en le clé par un event ID stable.
- Traitez dans un worker avec vérifications d’idempotence et actions métier.
- Enregistrez le résultat final (succès/échec) et un message d’erreur utile.
En pratique, vous voudrez deux enregistrements principaux : une ligne par événement webhook, et une ligne par tentative de traitement.
Un modèle d’événement solide inclut : event_id, provider, received_at, signature_status, payload_hash, payload_json (ou payload brut), current_status, last_error, next_retry_at. Les enregistrements de tentative peuvent stocker : attempt_number, started_at, finished_at, http_status (si applicable), error_code, error_text.
Une fois les données en place, ajoutez une petite page admin pour que le support puisse chercher par event ID, customer ID ou plage temporelle, et filtrer par statut. Gardez-la sobre et rapide.
Mettez des alertes sur des motifs, pas sur des échecs isolés. Par exemple : « le fournisseur XXX a échoué 10 fois en 5 minutes » ou « événement bloqué en failed ».
Sender expectations
Si vous contrôlez le côté envoi, standardisez trois choses : inclure toujours un event ID, signer toujours le payload de la même façon, et publier une politique de réessai en langage clair. Ça évite les aller-retour quand un partenaire dit « on l’a envoyé » et que votre système n’affiche rien.
Exemple : webhook de paiements du statut 'failed' à 'fixed' avec rejouement
Un schéma courant est un webhook Stripe qui fait deux choses : crée un enregistrement Order, puis envoie un reçu par email/SMS. Ça paraît simple jusqu’à ce qu’un événement échoue et que personne ne sache si le client a été facturé, si la commande existe, ou si le reçu a été envoyé.
Voici un échec réaliste : vous faites une rotation de votre secret de signature Stripe. Pendant quelques minutes, votre endpoint vérifie encore avec l’ancien secret, donc Stripe envoie les événements mais votre serveur les rejette avec un 401/400. Le tableau de bord affiche « webhook failed », tandis que vos logs applicatifs ne disent que « invalid signature ».
De bons logs rendent la cause évidente. Pour l’événement échoué, l’enregistrement devrait afficher un event ID stable plus suffisamment de détails de vérification pour pointer le décalage : version de signature, timestamp de la signature, résultat de la vérification, et une raison claire du rejet (mauvais secret vs dérive de timestamp). Pendant la rotation, il est aussi utile de logger quel secret a été tenté (par exemple « current » vs « previous »), pas le secret brut.
Une fois le secret corrigé et que « current » et « previous » sont acceptés pour une courte fenêtre, il faut encore gérer l’arriéré. Un outil de rejouement transforme cela en une tâche rapide :
- Trouver l’événement par event_id.
- Confirmer que la raison d’échec est résolue.
- Rejouer l’événement.
- Vérifier l’idempotence : la commande est créée une seule fois, le reçu est envoyé une seule fois.
- Ajouter le résultat du rejouement et les timestamps au ticket.
Réduire la dette technique dans les intégrations
Changez la logique rapidement et régénérez du code Go, Vue et mobile propre au fur et à mesure que vos intégrations évoluent.
La plupart des problèmes webhook semblent mystérieux parce que les systèmes n’enregistrent que l’erreur finale. Traitez chaque livraison comme un petit rapport d’incident : ce qui est arrivé, ce que vous avez décidé, et ce qui s’est passé ensuite.
Quelques erreurs récurrentes :
- Logger seulement les exceptions au lieu du cycle de vie complet (received, verified, queued, processed, failed, retried)
- Sauvegarder les payloads et headers complets sans masquage, puis découvrir que vous avez capturé des secrets ou des données personnelles
- Traiter les réessais comme de nouveaux événements, provoquant double facturation ou messages en double
- Renvoyer 200 OK avant que l’événement ne soit durablement stocké, de sorte que les tableaux de bord semblent verts alors que le travail meurt ensuite
Corrections pratiques :
- Stockez un enregistrement de requête minimal et interrogeable plus les changements de statut.
- Masquez par défaut les champs sensibles et restreignez l’accès aux payloads bruts.
- Faites respecter l’idempotence au niveau de la base de données, pas seulement dans le code.
- Accusez réception seulement après que l’événement est stocké en toute sécurité.
- Construisez le rejouement comme un flux supporté, pas comme un script ponctuel.
Si vous utilisez AppMaster, ces éléments s’intègrent naturellement à la plateforme : une table d’événements dans le Data Designer, un Business Process piloté par statuts pour la vérification et le traitement, et une UI admin pour la recherche et le rejouement.
Checklist rapide et prochaines étapes
Visez les mêmes bases à chaque fois :
- Chaque événement a un event_id unique, et vous stockez le payload brut tel que reçu.
- La vérification de signature s’exécute sur chaque requête, et les échecs incluent une raison claire.
- Les réessais sont prévisibles, et les handlers sont idempotents.
- Le rejouement est restreint aux rôles autorisés et laisse une piste d’audit.
- Les logs sont interrogeables par event_id, provider id, statut et période, avec un court résumé « ce qui s’est passé ».
En manquer un seul peut encore transformer une intégration en boîte noire. Si vous ne stockez pas le payload brut, vous ne pouvez pas prouver ce que le fournisseur a envoyé. Si les échecs de signature ne sont pas spécifiques, vous perdrez des heures à vous disputer sur la responsabilité.
Si vous voulez construire ça rapidement sans coder chaque composant à la main, AppMaster (appmaster.io) peut vous aider à assembler le modèle de données, les flux de traitement et l’UI admin en un seul endroit, tout en générant du vrai code source pour l’application finale.