10 août 2025·8 min de lecture
Conception d’un hub d’intégration pour stacks SaaS en croissance
Apprenez à concevoir un hub d’intégration pour centraliser les identifiants, suivre l’état des synchronisations et gérer les erreurs de façon cohérente à mesure que votre stack SaaS s’étend.
Pourquoi les stacks SaaS en croissance deviennent vite désordonnées
Une stack SaaS commence souvent simplement : un CRM, un outil de facturation, une boîte de support. Puis l’équipe ajoute de l’automation marketing, un entrepôt de données, un second canal de support, et quelques outils de niche qui « ont juste besoin d’un petit sync ». Rapidement, vous vous retrouvez avec une toile de connexions point-à-point dont personne n’a la responsabilité complète.
Ce qui casse en premier n’est généralement pas les données. C’est la colle autour.
Les identifiants se retrouvent éparpillés dans des comptes personnels, des feuilles partagées et des variables d’environnement aléatoires. Les tokens expirent, des personnes partent, et soudain « l’intégration » dépend d’un identifiant introuvable. Même quand la sécurité est traitée correctement, la rotation des secrets devient pénible parce que chaque connexion a sa propre configuration et son propre endroit pour mettre à jour les choses.
La visibilité s’effondre ensuite. Chaque intégration rapporte l’état différemment (ou pas du tout). Un outil peut indiquer « connecté » tout en échouant silencieusement à synchroniser. Un autre envoie des emails vagues qui sont ignorés. Quand un commercial demande pourquoi un client n’a pas été provisionné, la réponse devient une chasse au trésor entre logs, tableaux de bord et fils de discussion.
La charge du support augmente rapidement parce que les pannes sont difficiles à diagnostiquer et faciles à reproduire. De petits problèmes comme les limites de taux, les changements de schéma et les retries partiels deviennent de longs incidents quand personne ne voit le chemin complet de « événement reçu » à « données arrivées ».
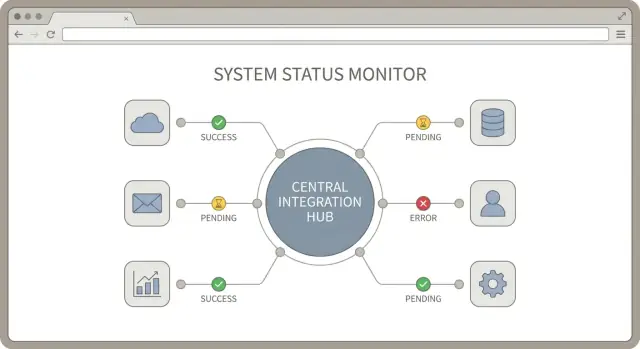
Un hub d’intégration est une idée simple : un endroit central où vos connexions aux services tiers sont gérées, surveillées et supportées. Une bonne conception de hub d’intégration crée des règles cohérentes pour l’authentification, le reporting du statut de synchronisation et la gestion des erreurs.
Un hub pratique vise quatre résultats : moins de pannes (patterns partagés de retry et validation), corrections plus rapides (tracing facile), accès plus sûr (propriété centrale des identifiants) et moins d’effort de support (alertes et messages standardisés).
Si vous construisez votre stack sur une plateforme comme AppMaster, l’objectif est le même : garder les opérations d’intégration suffisamment simples pour qu’un non-spécialiste comprenne ce qui se passe, et qu’un spécialiste puisse réparer vite quand ça coince.
Cartographiez votre inventaire d’intégrations et les flux de données
Avant de prendre des décisions d’intégration majeures, obtenez une image claire de ce que vous connectez déjà (ou prévoyez de connecter). C’est la partie que les gens sautent et qui crée des surprises plus tard.
Commencez par lister chaque service tiers dans votre stack, même les « petits ». Indiquez qui en est responsable (personne ou équipe) et si c’est en production, prévu ou expérimental.
Ensuite, séparez les intégrations visibles par les clients des automatisations en arrière-plan. Une intégration côté utilisateur peut être « Connectez votre compte Salesforce. » Une automation interne peut être « Quand une facture est payée dans Stripe, passez le client en actif dans la base de données. » Ces cas ont des attentes de fiabilité différentes et échouent de façons différentes.
Puis cartographiez les flux de données en posant une question : qui a besoin des données pour faire son travail ? Produit peut avoir besoin d’événements d’usage pour l’onboarding. Ops a besoin du statut des comptes et du provisioning. Finance a besoin des factures, remboursements et champs fiscaux. Support a besoin des tickets, de l’historique des conversations et des correspondances d’identités. Ces besoins façonnent votre hub plus que les API des fournisseurs.
Enfin, fixez des attentes de délai pour chaque flux :
- Temps réel : actions déclenchées par l’utilisateur (connexion, déconnexion, mises à jour instantanées)
- Presque temps réel : quelques minutes acceptables (synchronisation de statut, mises à jour d’entitlements)
- Quotidien : reporting, backfills, exports finance
- À la demande : outils de support et actions admin
Exemple : une « facture payée » peut nécessiter un quasi temps réel pour le contrôle d’accès, mais quotidien pour les récapitulatifs financiers. Capturer cela tôt rend la standardisation du monitoring et du traitement des erreurs beaucoup plus facile.
Décidez ce que votre hub d’intégration doit faire
Une bonne conception commence par des limites. Si le hub essaie de tout faire, il devient le goulot d’étranglement. S’il fait trop peu, vous vous retrouvez avec une douzaine de scripts ad hoc qui se comportent tous différemment.
Écrivez ce que le hub possède et ce qu’il ne possède pas. Une séparation pratique est :
- Le hub gère la configuration des connexions, le stockage des identifiants, la planification et un contrat cohérent pour le statut et les erreurs.
- Les services en aval gèrent les décisions métier, comme quels clients doivent être facturés ou ce qui compte comme un lead qualifié.
Choisissez un point d’entrée unique pour toutes les intégrations et tenez-vous-y. Ce point d’entrée peut être une API (les autres systèmes appellent le hub) ou un exécuteur de jobs (le hub lance des pulls et pushes planifiés). Utiliser les deux est acceptable, mais seulement s’ils partagent le même pipeline interne afin que retries, logs et alertes se comportent de la même façon.
Quelques décisions gardent le hub focalisé : standardiser comment les intégrations sont déclenchées (webhook, planning, relance manuelle), s’accorder sur une forme de payload limite (même si les partenaires diffèrent), décider ce que vous persistez (événements bruts, enregistrements normalisés, les deux ou aucun), définir ce que signifie « terminé » (accepté, livré, confirmé), et assigner la responsabilité des particularités par partenaire.
Décidez où se font les transformations. Si vous normalisez les données dans le hub, les services en aval restent plus simples, mais le hub nécessite un versioning et des tests plus solides. Si vous gardez le hub léger et passez les payloads bruts, chaque service en aval doit apprendre chaque format partenaire. Beaucoup d’équipes trouvent un compromis : normaliser seulement les champs communs (IDs, timestamps, statut basique) et garder les règles de domaine en aval.
Préparez la multi-tenancy dès le départ. Décidez si l’unité d’isolation est le client, l’espace de travail ou l’organisation. Ce choix affecte les limites de taux, le stockage des identifiants et les backfills. Quand le token Salesforce d’un client expire, vous devriez suspendre uniquement les jobs de ce tenant, pas tout le pipeline. Des outils comme AppMaster peuvent aider à modéliser visuellement les tenants et workflows, mais les frontières doivent être explicites avant de construire.
Centralisez les identifiants sans créer un risque de sécurité
Un coffre d’identifiants peut soit rendre la vie calme, soit devenir un risque d’incident permanent. L’objectif est simple : un endroit unique pour stocker les accès, sans donner à chaque système ou collaborateur plus de pouvoir que nécessaire.
OAuth et les clés API apparaissent à différents endroits. OAuth est courant pour les applications orientées utilisateur comme Google, Slack, Microsoft et beaucoup de CRMs. Un utilisateur approuve l’accès, et vous stockez un access token plus un refresh token. Les clés API sont plus fréquentes pour les outils serveur-à-serveur et les API anciennes. Elles peuvent être longues, ce qui rend le stockage sûr et la rotation encore plus importants.
Stockez tout chiffré et scopez au bon tenant. Dans un produit multi-client, considérez les identifiants comme des données client. Gardez une isolation stricte pour qu’un token du Tenant A ne puisse jamais être utilisé pour le Tenant B, même par erreur. Conservez aussi les métadonnées dont vous aurez besoin plus tard : à quelle connexion il appartient, quand il expire et quels droits ont été accordés.
Règles pratiques qui évitent la plupart des problèmes :
- Utilisez les scopes au moindre privilège. Demandez uniquement les permissions nécessaires aujourd’hui.
- Ne mettez pas d’identifiants dans les logs, messages d’erreur ou captures d’écran de support.
- Faites tourner les clés quand c’est possible et suivez quels systèmes utilisent encore l’ancienne clé.
- Séparez les environnements. Ne réutilisez jamais des identifiants de production en staging.
- Limitez qui peut voir ou ré-autoriser une connexion dans votre UI d’administration.
Préparez la rafraîchissement et la révocation sans casser la synchronisation. Pour OAuth, le refresh doit se faire automatiquement en arrière-plan, et votre hub doit gérer le cas « token expired » en rafraîchissant une fois et en réessayant en toute sécurité. Pour la révocation (utilisateur déconnecte, équipe sécurité désactive une app, ou scopes changent), arrêtez la sync, marquez la connexion comme needs_auth et conservez une piste d’audit claire de ce qui s’est passé.
Si vous construisez votre hub dans AppMaster, traitez les identifiants comme un modèle de données protégé, gardez l’accès en logique backend-only, et n’exposez que l’état connecté/déconnecté à l’UI. Les opérateurs peuvent corriger une connexion sans jamais voir le secret.
Rendre le statut de sync visible et cohérent
Add durable background processing
Queue work, set timeouts, and keep slow providers from blocking other syncs.
Quand vous connectez beaucoup d’outils, « est-ce que ça marche ? » devient une question quotidienne. La solution n’est pas plus de logs. C’est un petit ensemble cohérent de signaux de sync qui se ressemblent pour chaque intégration. Une bonne conception traite le statut comme une fonctionnalité à part entière.
Commencez par définir une courte liste d’états de connexion et utilisez-les partout : UI d’administration, alertes et notes de support. Gardez les noms simples pour qu’un non-technique puisse agir.
- connected : les identifiants sont valides et la sync tourne
- needs_auth : l’utilisateur doit ré-authoriser (token expiré, accès révoqué)
- paused : arrêté intentionnellement (maintenance, demande client)
- failing : erreurs répétées et intervention humaine requise
Suivez trois timestamps par connexion : début du dernier sync, dernier succès de sync et dernier temps d’erreur. Ils racontent rapidement une histoire sans creuser.
Une petite vue par intégration aide le support à aller vite. Chaque page de connexion doit montrer l’état actuel, ces timestamps et le dernier message d’erreur dans un format propre pour l’utilisateur (pas de traces de pile). Ajoutez une courte ligne d’action recommandée comme « Re-auth required » ou « Rate limit, retrying. »
Ajoutez quelques signaux santé qui prédisent les problèmes avant que les utilisateurs ne les remarquent : taille du backlog, nombre de retries, hits de rate limit et dernier débit réussi (environ combien d’éléments ont été synchronisés lors de la dernière exécution).
Exemple : votre sync CRM est connected, mais le backlog augmente et les hits de rate limit grimpent. Ce n’est pas encore une panne, mais c’est un signe clair de réduire la fréquence de sync ou de batcher les requêtes. Si vous construisez votre hub dans AppMaster, ces champs de statut se mappent proprement dans un modèle Data Designer et dans une UI de support simple que votre équipe peut utiliser au quotidien.
Concevoir le flux de synchronisation pas à pas
Une sync fiable tient plus à des étapes répétables qu’à une logique sophistiquée. Commencez par un modèle d’exécution clair, puis ajoutez de la complexité seulement là où c’est nécessaire.
La plupart des équipes utilisent un mix, mais chaque connecteur devrait avoir un déclencheur principal pour en faciliter la compréhension :
- Événements (webhooks) pour les changements proches du temps réel
- Jobs pour les actions qui doivent s’exécuter jusqu’au bout (comme « créer facture, puis marquer payée »)
- Pulls planifiés pour les systèmes qui ne peuvent pas pousser, ou pour des backfills de sécurité
Si vous construisez dans AppMaster, cela se mappe souvent à un endpoint webhook, un process en arrière-plan et une tâche planifiée, tous alimentant le même pipeline interne.
2) Normaliser d’abord, puis traiter
Les fournisseurs appellent souvent la même chose différemment (customerId vs contact_id, chaînes de statut, formats de date). Convertissez chaque payload entrant en un format interne avant d’appliquer des règles métier. Cela simplifie le reste du hub et rend les changements de connecteur moins douloureux.
3) Rendre chaque écriture idempotente
Les retries sont normaux. Votre hub doit pouvoir exécuter la même action deux fois sans créer de doublons. Une approche commune est de stocker un ID externe et une « last processed version » (horodatage, numéro de séquence ou event ID). Si vous voyez le même élément à nouveau, vous le sautez ou le mettez à jour en toute sécurité.
4) Mettre le travail en file et limiter l’attente
Les API tierces peuvent être lentes ou se bloquer. Placez les tâches normalisées sur une file durable, puis traitez-les avec des timeouts explicites. Si un appel prend trop de temps, échouez-le, enregistrez la raison et retentez plus tard au lieu de tout bloquer.
5) Respecter volontairement les limites de taux
Gérez les limites avec à la fois backoff et throttling par connecteur. Backoff sur les réponses 429/5xx avec un calendrier de retry plafonné, définissez des limites de concurrence séparées par connecteur (CRM n’est pas facturation), et ajoutez du jitter pour éviter les rafales de retry.
Exemple : un « nouvelle facture payée » arrive du billing via webhook, est normalisée et mise en file, puis crée ou met à jour le compte correspondant dans votre CRM. Si le CRM vous limite, ce connecteur ralentit sans retarder la sync des tickets de support.
Gestion des erreurs que votre équipe peut réellement supporter
Map tenants and connection state
Model tenants, connections, and sync states in a database schema you can evolve safely.
Un hub qui « échoue parfois » est pire que pas de hub du tout. La solution est une manière partagée de décrire les erreurs, décider de la suite et dire aux administrateurs non techniques quoi faire.
Commencez par une forme d’erreur standard que chaque connecteur retourne, même si les payloads tiers diffèrent. Cela maintient l’UI, les alertes et les playbooks de support cohérents.
- code : identifiant stable (par exemple
RATE_LIMIT)
- message : résumé court et lisible
- retryable : true/false
- context : méta-données sûres (nom de l’intégration, endpoint, ID d’enregistrement)
- provider_details : extrait assaini pour le dépannage
Puis classez les échecs en quelques catégories (gardez-les petites) : auth, validation, timeout, rate limit et outage.
Attachez des règles de retry claires à chaque catégorie. Les rate limits ont des retries différés avec backoff. Les timeouts peuvent retenter rapidement un petit nombre de fois. La validation est manuelle jusqu’à correction des données. L’auth met la connexion en pause et demande à un admin de reconnecter.
Conservez les réponses brutes des tiers, mais enregistrez-les en toute sécurité. Redigez les secrets (tokens, clés API, données de carte complètes) avant de sauvegarder. Si cela peut accorder un accès, ça n’a pas sa place dans les logs.
Rédigez deux messages par erreur : un pour les admins et un pour les ingénieurs. Un message d’admin peut être : « Salesforce connection expired. Reconnect to resume syncing. » La vue ingénieur peut inclure la réponse assainie, l’ID de requête et l’étape qui a échoué. C’est là qu’un hub cohérent paye, que vous implémentiez les flux en code ou avec un outil visuel comme AppMaster Business Process Editor.
Support-friendly connection pages
Give support a clear view of needs_auth, paused, failing, and connected states.
Beaucoup de projets d’intégration échouent pour des raisons banales. Le hub marche en démo, puis s’effondre quand vous ajoutez plus de tenants, plus de types de données et plus de cas limites.
Un grand piège est de mélanger la logique de connexion et la logique métier. Quand « comment parler à l’API » se trouve dans le même chemin que « ce que signifie un enregistrement client », chaque nouvelle règle risque de casser le connecteur. Gardez les adapters concentrés sur l’auth, le paging, les limites de taux et le mapping. Gardez les règles métier dans une couche séparée que vous pouvez tester sans toucher aux APIs tierces.
Un autre problème fréquent est de traiter l’état tenant comme global. Dans un produit B2B, chaque tenant a besoin de ses tokens, curseurs et checkpoints de sync. Si vous stockez « dernière sync » dans un endroit partagé, un client peut écraser l’autre et vous obtenez des mises à jour manquantes ou des fuites de données inter-tenants.
Cinq pièges récurrents et la correction simple :
- Logique de connexion et logique métier mêlées. Fix : créer une frontière d’adapter claire (connect, fetch, push, transform), puis exécuter les règles métier après l’adapter.
- Tokens stockés une fois et réutilisés entre tenants. Fix : stocker identifiants et refresh tokens par tenant et les faire tourner en toute sécurité.
- Retries qui tournent indéfiniment. Fix : retries plafonnés avec backoff et arrêt après une limite claire.
- Chaque erreur traitée comme retryable. Fix : classifier les erreurs et remonter immédiatement les problèmes d’auth.
- Pas de piste d’audit. Fix : écrire des logs d’audit indiquant qui a synchronisé quoi, quand et pourquoi ça a échoué, incluant les IDs de requête et les IDs externes.
Les retries méritent une attention particulière. Si un appel de création timeoute, retenter peut créer des doublons à moins d’utiliser des clés d’idempotence ou une stratégie d’upsert robuste. Si l’API tierce ne supporte pas l’idempotence, suivez un registre local d’écritures pour détecter et éviter les répétitions.
N’omettez pas les logs d’audit. Quand le support demande pourquoi un enregistrement manque, vous devez pouvoir répondre en quelques minutes, pas deviner. Même si vous construisez votre hub avec un outil visuel comme AppMaster, faites des logs et l’état par-tenant des éléments de première classe.
Checklist rapide pour un hub d’intégration fiable
Un bon hub d’intégration est ennuyeux au meilleur sens : il connecte, rapporte clairement sa santé et échoue de façons compréhensibles par votre équipe.
Sécurité et bases de connexion
Commencez par vérifier comment chaque intégration s’authentifie et ce que vous faites de ces identifiants. Demandez le jeu minimal de permissions permettant au job de tourner (lecture seule quand c’est possible). Stockez les secrets dans un coffre dédié ou un store chiffré et faites-les tourner sans modifications de code. Assurez-vous que logs et messages d’erreur n’incluent jamais tokens, clés API, refresh tokens ou headers bruts.
Une fois les identifiants sécurisés, confirmez que chaque connexion client a une source de vérité unique et claire.
Visibilité, retries et préparation du support
La clarté opérationnelle est ce qui rend les intégrations gérables quand vous avez des dizaines de clients et de nombreux services tiers.
Suivez l’état de connexion par client (connected, needs_auth, paused, failing) et exposez-le dans l’UI d’administration. Enregistrez un timestamp du dernier succès par objet ou par job de sync, pas seulement « on a lancé quelque chose hier ». R rendez l’erreur la plus récente facile à trouver avec du contexte : quel client, quelle intégration, quelle étape, quelle requête externe et ce qui s’est passé ensuite.
Limitez les retries (nombre max de tentatives et fenêtre de coupure) et concevez les écritures pour être idempotentes afin que les relances n’entraînent pas de doublons. Fixez un objectif de support : quelqu’un de l’équipe doit pouvoir localiser la dernière défaillance et ses détails en moins de deux minutes sans lire du code.
Si vous développez rapidement l’UI et le suivi de statut du hub, une plateforme comme AppMaster peut vous aider à livrer un dashboard interne et la logique de workflow vite, tout en générant du code prêt pour la production.
Un exemple réaliste : trois intégrations, un seul hub
Start with one pilot connector
Turn one real integration into a working pipeline before you add the next ten.
Imaginez un produit SaaS qui nécessite trois intégrations communes : Stripe pour les événements de facturation, HubSpot pour les transferts commerciaux, et Zendesk pour les tickets de support. Plutôt que de connecter chaque outil directement à votre application, passez-les par un hub d’intégration unique.
L’onboarding commence dans le panneau d’administration. Un admin clique « Connect Stripe », « Connect HubSpot » et « Connect Zendesk ». Chaque connecteur stocke les identifiants dans le hub, pas dans des scripts ou des postes d’employés. Ensuite le hub lance une importation initiale :
- Stripe : clients, abonnements, factures (et setup des webhooks pour les nouveaux événements)
- HubSpot : entreprises, contacts, transactions
- Zendesk : organisations, utilisateurs, tickets récents
Après l’import, la première sync démarre. Le hub écrit un enregistrement de sync pour chaque connecteur afin que tout le monde voie la même histoire. Une vue admin simple répond à la plupart des questions : état de la connexion, dernier succès de sync, job en cours (import, sync, idle), résumé d’erreur et code, et prochaine exécution planifiée.
Maintenant c’est une heure chargée et Stripe vous limite. Au lieu d’échouer tout le système, le connecteur Stripe marque le job comme retrying, enregistre la progression partielle (par exemple « factures jusqu’à 10:40 ») et fait du backoff. HubSpot et Zendesk continuent de synchroniser.
Le support reçoit un ticket : « La facturation semble obsolète. » Ils ouvrent le hub et voient Stripe en failing avec une erreur de rate limit. La résolution est procédurale :
- Re-auth Stripe seulement si le token est vraiment invalide
- Rejouer le dernier job échoué depuis le checkpoint enregistré
- Confirmer le succès en vérifiant le dernier timestamp de sync et un spot-check (une facture, un abonnement)
Si vous construisez sur une plateforme comme AppMaster, ce flux se mappe proprement à une logique visuelle (états de jobs, retries, écrans admin) tout en générant du code backend réel pour la production.
Étapes suivantes : construire itérativement et garder les opérations simples
Une bonne conception de hub d’intégration consiste moins à tout construire d’un coup qu’à rendre chaque nouvelle connexion prévisible. Commencez par un petit ensemble de règles partagées que chaque connecteur doit suivre, même si la première version paraît « trop simple ».
Commencez par la cohérence : états standards pour les jobs de sync (pending, running, succeeded, failed), un petit ensemble de catégories d’erreurs (auth, rate limit, validation, outage en amont, unknown) et des logs d’audit qui répondent à qui a lancé quoi, quand et avec quels enregistrements. Si vous ne pouvez pas faire confiance aux statuts et aux logs, tableaux de bord et alertes ne seront que du bruit.
Ajoutez les connecteurs un par un en utilisant les mêmes templates et conventions. Chaque connecteur doit réutiliser le même flux d’identifiants, les mêmes règles de retry et la même manière d’écrire les mises à jour de statut. Cette répétition est ce qui rend le hub supportable quand vous avez dix intégrations au lieu de trois.
Un plan de déploiement pratique :
- Choisir 1 tenant pilote avec un usage réel et des critères de succès clairs
- Construire 1 connecteur de bout en bout, incluant statut et logs
- Lancer pendant une semaine, corriger les 3 modes d’échec principaux, puis documenter les règles
- Ajouter le connecteur suivant en réutilisant les mêmes règles, pas des correctifs ad hoc
- Étendre aux autres tenants progressivement, avec un plan de rollback simple
Introduisez les dashboards et alertes seulement après que les données de statut sous-jacentes sont correctes. Commencez par un écran qui montre le dernier sync, le dernier résultat, la prochaine exécution et le dernier message d’erreur avec catégorie.
Si vous préférez une approche no-code, vous pouvez modéliser les données, construire la logique de sync et exposer des écrans de statut dans AppMaster, puis déployer sur votre cloud ou exporter le code source. Gardez la première version ennuyeuse et observable, puis améliorez la performance et les cas limites une fois les opérations stables.
FAQ
Commencez par un inventaire simple : chaque outil tiers, qui en est responsable, et s’il est en production ou prévu. Notez ensuite les données qui circulent entre les systèmes et pourquoi elles importent pour chaque équipe (support, finance, ops). Cette cartographie vous dira ce qui doit être en temps réel, ce qui peut être quotidien, et ce qui demande la surveillance la plus stricte.
Le hub doit gérer la plomberie partagée : configuration des connexions, stockage des identifiants, planification/déclencheurs, reporting d’état cohérent et gestion uniforme des erreurs. Les décisions métier doivent rester en dehors du hub afin de ne pas modifier le code des connecteurs à chaque changement de règles produit.
Choisissez un point d’entrée principal par connecteur pour faciliter le diagnostic. Les webhooks conviennent au temps quasi réel, les pulls planifiés servent quand le fournisseur ne peut pas pousser, et les workflows par job sont utiles quand il faut exécuter des étapes dans l’ordre. Quelle que soit l’option, gardez les mêmes règles de retry, de logs et de mise à jour d’état.
Considérez les identifiants comme des données clients et stockez-les chiffrés avec une isolation stricte par tenant. N’exposez jamais les tokens dans les logs, les écrans UI ou les captures d’écran de support, et n’utilisez pas les secrets de production en staging. Conservez aussi les métadonnées utiles : date d’expiration, scopes, et à quel client/connexion appartient le token.
OAuth est préférable lorsque des clients connectent leurs comptes et que vous voulez un accès révocable et limité par scope. Les clés API peuvent convenir pour les intégrations serveur-à-serveur mais sont souvent longues et demandent une rotation et un contrôle d’accès stricts. Si possible, privilégiez OAuth pour les connexions côté utilisateur.
Séparez l’état par tenant : tokens, curseurs, checkpoints, compteurs de retry et progression des backfills. Une panne pour un tenant doit seulement suspendre les jobs de ce tenant, pas l’ensemble du connecteur. Cette isolation évite les fuites de données entre clients et simplifie la résolution des incidents.
Affichez un petit ensemble d’états clairs et identiques pour tous les connecteurs, par exemple : connected, needs_auth, paused, failing. Conservez trois timestamps par connexion : début du dernier sync, dernier succès et dernier erreur. Avec ces signaux, la plupart des questions « est-ce que ça marche ? » trouvent réponse sans aller regarder les logs.
Rendez chaque écriture idempotente pour que les retries n’entraînent pas de doublons. En pratique, gardez un ID externe et un markeur « last processed » (horodatage, séquence ou event ID) et faites des upserts plutôt que des créations aveugles. Si le fournisseur ne supporte pas l’idempotence, conservez un registre local d’écriture pour détecter les répétitions.
Gérez les limites volontairement : throttling par connecteur, backoff sur 429 et erreurs transitoires, et ajout de jitter pour éviter des pics de retries. Placez le travail sur une file durable avec des timeouts afin que des appels lents n’empêchent pas d’autres intégrations de tourner. L’objectif : ralentir un connecteur sans bloquer tout le hub.
Modélisez connexions, tenants et champs d’état dans AppMaster Data Designer, puis implémentez les workflows de sync dans le Business Process Editor. Gardez les identifiants en logique backend-only et n’exposez que des statuts et actions sûres dans l’UI. Vous pouvez ainsi livrer un dashboard opérationnel rapidement tout en générant du code prêt pour la production.