17 févr. 2025·8 min de lecture
CI/CD pour backends Go : construire, tester, migrer, déployer
CI/CD pour backends Go : étapes pratiques de pipeline pour la compilation, les tests, les migrations et des déploiements sûrs vers Kubernetes ou des machines virtuelles dans des environnements prévisibles.
Pourquoi le CI/CD compte pour les backends Go
Les déploiements manuels échouent de manière ennuyeuse et répétable. Quelqu’un construit sur son laptop avec une version de Go différente, oublie une variable d’environnement, saute une migration ou redémarre le mauvais service. Le release « marche chez moi », mais pas en production, et vous ne l’apprenez qu’une fois que les utilisateurs le ressentent.
Le code généré n’enlève pas le besoin de discipline de release. Quand vous régénérez un backend après avoir mis à jour des exigences, vous pouvez introduire de nouveaux endpoints, de nouvelles formes de données ou de nouvelles dépendances même si vous n’avez jamais touché le code à la main. C’est exactement le moment où vous voulez qu’un pipeline joue le rôle de garde-fou : chaque changement passe par les mêmes contrôles, à chaque fois.
Des environnements prévisibles signifient que vos étapes de build et de déploiement s’exécutent dans des conditions que vous pouvez nommer et répéter. Quelques règles couvrent l’essentiel :
- Verrouiller les versions (toolchain Go, images de base, paquets OS).
- Builder une fois, déployer le même artefact partout.
- Garder la configuration hors du binaire (vars d’environnement ou fichiers de config par environnement).
- Utiliser le même outil et processus de migration dans tous les environnements.
- Rendre les rollbacks réels : conserver l’artefact précédent et savoir ce qui arrive à la base.
L’objectif du CI/CD pour backends Go n’est pas l’automatisation pour elle-même. C’est des releases répétables avec moins de stress : régénérez, lancez le pipeline et ayez confiance que le résultat est déployable.
Si vous utilisez un générateur comme AppMaster qui produit des backends Go, cela compte encore plus. La régénération est une fonctionnalité, mais elle n’est sûre que si le chemin du changement vers la production est cohérent, testé et prévisible.
Choisissez votre runtime et définissez « prévisible » dès le départ
« Prévisible » signifie que la même entrée produit le même résultat, peu importe où vous l’exécutez. Pour le CI/CD des backends Go, cela commence par s’accorder sur ce qui doit rester identique entre dev, staging et prod.
Les éléments non négociables habituels sont la version de Go, votre image OS de base, les flags de build et la façon dont la configuration est chargée. Si l’un de ces éléments change selon l’environnement, vous aurez des surprises comme un comportement TLS différent, des paquets système manquants ou des bugs qui n’apparaissent qu’en production.
La dérive d’environnement se manifeste le plus souvent aux mêmes endroits :
- OS et bibliothèques système (versions de distro différentes, certificats CA manquants, différences de fuseau horaire)
- Valeurs de config (feature flags, timeouts, origines autorisées, URLs de services externes)
- Structure et réglages de la base (migrations, extensions, collation, limites de connexion)
- Gestion des secrets (où ils vivent, comment ils tournent, qui peut les lire)
- Hypothèses réseau (DNS, firewalls, discovery)
Choisir entre Kubernetes et des VMs dépend moins de ce qui est « meilleur » que de ce que votre équipe sait exécuter calmement.
Kubernetes convient quand vous avez besoin d’autoscaling, de rolling updates et d’une manière standard de faire tourner de nombreux services. Il aide aussi à imposer la cohérence parce que les pods démarrent depuis les mêmes images. Les VMs peuvent être le bon choix quand vous avez un ou quelques services, une petite équipe et que vous voulez moins de pièces mobiles.
Vous pouvez garder le pipeline identique même si les runtimes diffèrent en standardisant l’artefact et le contrat autour de celui-ci. Par exemple : construisez toujours la même image de conteneur dans le CI, exécutez les mêmes étapes de test et publiez le même bundle de migrations. Ensuite seule l’étape de déploiement change : Kubernetes applique un tag d’image, tandis que les VMs tirent l’image et redémarrent un service.
Un exemple pratique : une équipe régénère un backend Go avec AppMaster et déploie en staging sur Kubernetes mais utilise une VM en production pour l’instant. Si les deux tirent exactement la même image et chargent la config depuis le même type de magasin de secrets, « runtime différent » devient un détail de déploiement, pas une source de bugs. Si vous utilisez AppMaster (appmaster.io), ce modèle s’adapte bien car vous pouvez déployer vers des cibles cloud managées ou exporter le code source et exécuter le même pipeline sur votre infrastructure.
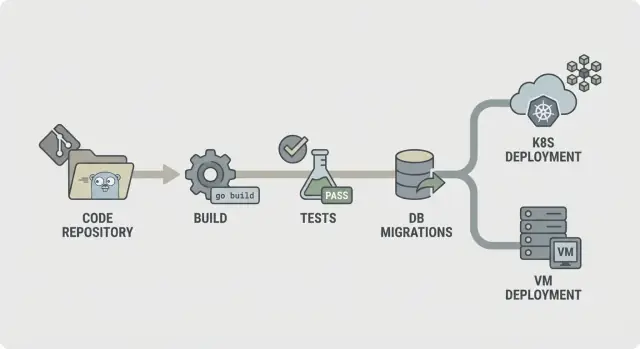
Une carte de pipeline simple que tout le monde comprend
Un pipeline prévisible est facile à décrire : vérifier le code, le construire, prouver que ça marche, livrer exactement ce que vous avez testé, puis le déployer de la même façon à chaque fois. Cette clarté compte encore plus quand votre backend est régénéré (par exemple depuis AppMaster), car les changements peuvent toucher de nombreux fichiers et vous voulez un retour rapide et cohérent.
Un flux CI/CD simple pour backends Go ressemble à ceci :
- Lint et contrôles basiques
- Build
- Tests unitaires
- Vérifications d’intégration
- Packaging (artefacts immuables)
- Migration (étape contrôlée)
- Déploiement
Structurez-le pour que les échecs s’arrêtent tôt. Si le lint échoue, rien d’autre ne doit démarrer. Si la compilation échoue, vous ne devriez pas perdre du temps à lancer des bases pour des tests d’intégration. Cela réduit les coûts et rend le pipeline rapide.
Toutes les étapes n’ont pas besoin de s’exécuter à chaque commit. Une séparation courante est :
- Chaque commit/PR : lint, build, tests unitaires
- Branche main : vérifications d’intégration, packaging
- Tags de release : migration, déploiement
Décidez ce que vous conservez comme artefacts. Généralement il s’agit du binaire compilé ou de l’image conteneur (ce que vous déployez), plus les logs de migration et rapports de test. Les conserver facilite les rollbacks et audits car vous pouvez pointer précisément vers ce qui a été testé et promu.
Étape par étape : un stage de build stable et reproductible
Un stage de build doit répondre à une question : peut-on produire le même binaire aujourd’hui, demain et sur un runner différent ? Si ce n’est pas le cas, chaque étape ultérieure (tests, migrations, déploiement) devient plus difficile à faire confiance.
Commencez par verrouiller l’environnement. Utilisez une version Go fixe (par exemple 1.22.x) et une image runner figée (distribution Linux et versions de paquets). Évitez les tags « latest ». De petits changements dans libc, Git ou la toolchain Go peuvent créer des erreurs « marche sur ma machine » difficiles à déboguer.
Le caching des modules aide, mais seulement si vous le traitez comme un gain de vitesse et non une source de vérité. Cachez le build cache Go et le cache de téléchargement des modules, mais cleflez-le par go.sum (ou videz-le sur main quand les deps changent) pour que de nouvelles dépendances déclenchent un téléchargement propre.
Ajoutez une porte rapide avant la compilation. Gardez-la courte pour que les développeurs ne la contournent pas. Une série typique : vérifications gofmt, go vet et (si c’est rapide) staticcheck. Échouez aussi si des fichiers générés manquent ou sont obsolètes, ce qui est courant dans des codebases régénérées.
Compilez de façon reproductible et incluez des infos de version. Des flags comme -trimpath aident, et vous pouvez définir -ldflags pour injecter le SHA du commit et l’heure de build. Produisez un artefact nommé unique par service. Cela facilite le traçage de ce qui tourne dans Kubernetes ou sur une VM, surtout quand votre backend est régénéré.
Étape par étape : des tests qui attrapent les problèmes avant le déploiement
Un artefact, plusieurs environnements
Construisez une fois, déployez partout : exportez le code source ou utilisez des cibles de déploiement managées.
Les tests n’aident que s’ils s’exécutent de la même façon à chaque fois. Visez d’abord un retour rapide, puis ajoutez des vérifications plus profondes qui restent dans un temps prévisible.
Commencez par les tests unitaires à chaque commit. Fixez un timeout strict pour qu’un test bloqué échoue bruyamment au lieu de suspendre tout le pipeline. Décidez aussi ce que « couverture suffisante » signifie pour votre équipe. La couverture n’est pas un trophée, mais une barre minimale aide à prévenir une dérive silencieuse de la qualité.
Un stage de tests stable inclut généralement :
- Exécuter
go test ./... avec un timeout par package et un timeout global de job.
- Considérer tout test atteignant le timeout comme un vrai bug à corriger, pas comme un « CI instable ».
- Fixer des attentes de couverture pour les packages critiques (auth, facturation, permissions), pas nécessairement pour tout le dépôt.
- Ajouter le détecteur de races pour le code qui gère la concurrence (queues, caches, workers en fan-out).
Le détecteur de races est précieux, mais il peut ralentir fortement les builds. Un bon compromis est de l’exécuter sur les pull requests et les builds nocturnes, ou seulement sur des packages sélectionnés au lieu de chaque push.
Les tests instables doivent faire échouer le build. Si vous devez mettre un test en quarantaine, gardez-le visible : déplacez-le dans un job séparé qui tourne et rapporte rouge, et exigez un propriétaire et une date limite pour la correction.
Conservez les sorties de test pour que le débogage n’exige pas de tout relancer. Sauvegardez les logs bruts plus un rapport simple (pass/fail, durée et tests les plus lents). Cela facilite la détection des régressions, surtout lorsque des changements régénérés touchent beaucoup de fichiers.
Vérifications d’intégration avec des dépendances réelles, sans builds lents
Construisez toute la pile produit
Générez backend, application web et applications mobiles natives depuis une même plateforme quand nécessaire.
Les tests unitaires vous disent que votre code marche isolément. Les vérifications d’intégration vous disent que le service se comporte correctement quand il démarre, se connecte à des services réels et traite de vraies requêtes. C’est le filet de sécurité qui attrape les problèmes n’apparaissant que quand tout est connecté.
Utilisez des dépendances éphémères quand votre code en a besoin pour démarrer ou répondre à des requêtes clés. Un PostgreSQL temporaire (et Redis si vous l’utilisez) lancé juste pour le job suffit généralement. Gardez des versions proches de la production, sans essayer de reproduire tous les détails de prod.
Une bonne étape d’intégration est volontairement petite :
- Démarrer le service avec des vars d’environnement proches de la production (mais avec des secrets de test)
- Vérifier un health check (par ex. /health renvoie 200)
- Appeler un ou deux endpoints critiques et vérifier les codes de statut et la forme des réponses
- Confirmer qu’il peut atteindre PostgreSQL (et Redis si nécessaire)
Pour vérifier les contrats d’API, concentrez-vous sur les endpoints dont la rupture serait la plus dommageable. Vous n’avez pas besoin d’une suite end-to-end complète. Quelques vérités request/response suffisent : champs requis rejetés avec 400, auth requise renvoie 401, et un chemin heureux renvoie 200 avec les clés JSON attendues.
Pour garder les intégrations assez rapides pour tourner souvent, limitez la portée et contrôlez le temps. Préférez une base unique avec un dataset minimal. Exécutez seulement quelques requêtes. Fixez des timeouts stricts pour qu’un démarrage bloqué échoue en secondes, pas en minutes.
Si vous régénérez votre backend (par exemple avec AppMaster), ces vérifications prennent plus d’importance. Elles confirment que le service régénéré démarre proprement et parle toujours l’API attendue par votre application web ou mobile.
Migrations de base : ordre sûr, gates et réalité du rollback
Commencez par choisir où s’exécutent les migrations. Les lancer en CI est utile pour détecter les erreurs tôt, mais le CI ne devrait généralement pas toucher la production. La plupart des équipes exécutent les migrations pendant le déploiement (comme étape dédiée) ou via un job « migrate » séparé qui doit se terminer avant le démarrage de la nouvelle version.
Une règle pratique : build et tests en CI, puis exécuter les migrations aussi près de la production que possible, avec des credentials de production et des limites proches de la prod. Sur Kubernetes, c’est souvent un Job one-off. Sur des VMs, cela peut être une commande scriptée dans l’étape de release.
L’ordre compte plus qu’on ne le pense. Utilisez des fichiers horodatés (ou des numéros séquentiels) et faites respecter « appliquer dans l’ordre, une seule fois ». Rendre les migrations idempotentes quand c’est possible aide, ainsi une rééxécution ne créé pas de doublons ni ne plante à mi-chemin.
Gardez la stratégie de migration simple :
- Préférez d’abord les changements additifs (nouvelles tables/colonnes, colonnes nullable, nouveaux index).
- Déployez du code capable de gérer l’ancien et le nouveau schéma pour une release.
- Ensuite seulement, retirez ou durcissez des contraintes (drop de colonnes, NOT NULL).
- Rendre les opérations longues sûres (par ex. créer des index en mode concurrent quand c’est supporté).
Ajoutez une gate de sécurité avant toute exécution. Cela peut être un verrou en base pour qu’une seule migration tourne à la fois, plus une politique comme « pas de changements destructifs sans approbation ». Par exemple, échouez le pipeline si une migration contient DROP TABLE ou DROP COLUMN sauf si une validation manuelle est approuvée.
Le rollback est la dure vérité : beaucoup de changements de schéma ne sont pas réversibles. Si vous supprimez une colonne, vous ne pouvez pas récupérer les données. Planifiez les rollbacks autour de corrections vers l’avant : ne garder le down migration que quand elle est vraiment sûre, et comptez sur des backups plus une migration forward quand elle ne l’est pas.
Associez chaque migration à un plan de récupération : que faire si elle échoue à mi-chemin et que faire si l’app doit revenir en arrière. Si vous générez des backends Go (par exemple avec AppMaster), traitez les migrations comme faisant partie du contrat de release pour que code régénéré et schéma restent synchronisés.
Packaging et configuration : des artefacts dignes de confiance
Simplifiez la logique métier du backend
Ajoutez la logique métier avec des workflows glisser-déposer au lieu de coder chaque changement à la main.
Un pipeline ne paraît prévisible que lorsque ce que vous déployez est toujours ce que vous avez testé. Cela tient au packaging et à la configuration. Traitez la sortie du build comme un artefact scellé et gardez toutes les différences d’environnement en dehors de celui-ci.
Le packaging suit en général deux voies. Une image conteneur est le choix par défaut si vous déployez sur Kubernetes, car elle fige la couche OS et rend les rollouts cohérents. Un bundle VM peut être tout aussi fiable si vous avez besoin de VMs, tant qu’il inclut le binaire compilé plus l’ensemble minimal de fichiers nécessaires au runtime (par ex. certs CA, templates ou assets statiques), et que vous le déployez de la même façon à chaque fois.
La configuration doit être externe, pas incrustée dans le binaire. Utilisez des variables d’environnement pour la plupart des réglages (ports, hôte DB, feature flags). N’utilisez un fichier de config que pour des valeurs longues ou structurées et gardez-le spécifique à l’environnement. Si vous utilisez un service de config, traitez-le comme une dépendance : permissions verrouillées, logs d’audit et plan de secours clair.
Les secrets sont la ligne à ne pas franchir. Ils n’ont pas leur place dans le repo, dans l’image ou dans les logs CI. Évitez d’imprimer des connection strings au démarrage. Conservez les secrets dans le store de secrets CI et injectez-les au moment du déploiement.
Pour rendre les artefacts traçables, intégrez l’identité dans chaque build : taggez les artefacts avec une version et le commit hash, incluez des métadonnées de build (version, commit, heure de build) dans un endpoint d’info, et enregistrez le tag de l’artefact dans votre journal de déploiement. Facilitez la réponse à « qu’est-ce qui tourne » via une commande ou un tableau de bord.
Si vous générez des backends Go (par exemple avec AppMaster), cette discipline compte encore plus : la régénération est sûre quand vos règles de nommage d’artefacts et de config rendent chaque release reproductible.
Déployer sur Kubernetes ou VMs sans surprises
La plupart des échecs de déploiement ne viennent pas d’un « mauvais code ». Ils viennent d’environnements mal appariés : config différente, secrets manquants ou service qui démarre mais n’est pas réellement prêt. Le but est simple : déployer le même artefact partout, et ne changer que la configuration.
Kubernetes : considérez les déploiements comme des rollouts contrôlés
Sur Kubernetes, visez un rollout contrôlé. Utilisez des rolling updates pour remplacer progressivement les pods, et ajoutez des checks de readiness et liveness pour que la plateforme sache quand envoyer du trafic et quand redémarrer un conteneur bloqué. Les requests et limits sont importants aussi, car un service Go qui fonctionne sur un gros runner CI peut se faire OOM-killer sur un nœud plus petit.
Garder la config et les secrets hors de l’image. Construisez une image par commit, puis injectez les réglages spécifiques à l’environnement au moment du déploiement (ConfigMaps, Secrets ou votre gestionnaire de secrets). Ainsi staging et production exécutent les mêmes bits.
VMs : systemd vous offre l’essentiel
Si vous déployez sur machines virtuelles, systemd peut être votre « mini-orchestrateur ». Créez une unité avec un working directory clair, un fichier d’environnement et une politique de redémarrage. Rendez les logs prévisibles en envoyant stdout/stderr vers votre collecteur ou journald, afin que les incidents ne tournent pas en chasse au SSH.
Vous pouvez toujours faire des rollouts sûrs sans cluster. Un simple blue/green fonctionne : gardez deux répertoires (ou deux VMs), changez le load balancer et gardez la version précédente prête pour un rollback rapide. Le canary est similaire : envoyez une petite part du trafic vers la nouvelle version avant d’engager complètement.
Avant de marquer un déploiement « terminé », exécutez la même vérification de fumée partout :
- Confirmer que le endpoint de health renvoie OK et que les dépendances sont atteignables
- Effectuer une petite action réelle (par ex. créer et lire un enregistrement de test)
- Vérifier que la version/build ID correspond au commit
- Si la vérification échoue, rollback et alerter
Si vous régénérez des backends (par exemple un backend Go AppMaster), cette approche reste stable : buildez une fois, déployez l’artefact et laissez la config d’environnement gérer les différences, pas des scripts ad-hoc.
Erreurs courantes qui rendent les pipelines peu fiables
Lancez des outils internes rapidement
Expédiez des outils internes, panneaux d'administration et portails clients avec de vraies API et permissions.
La plupart des releases cassées ne proviennent pas de « mauvais code ». Elles surviennent quand le pipeline se comporte différemment d’une exécution à l’autre. Si vous voulez que le CI/CD pour backends Go soit calme et prévisible, surveillez ces schémas.
Schémas d’erreurs qui causent des surprises
Lancer des migrations automatiquement à chaque déploiement sans garde-fous est classique. Une migration qui verrouille une table peut mettre hors-service un service très sollicité. Mettez les migrations derrière une étape explicite, exigez une approbation pour la production et assurez-vous qu’on peut les relancer en toute sécurité.
Utiliser des tags latest ou des images de base non verrouillées est une autre façon d’introduire des échecs mystérieux. Verrouillez les images Docker et les versions de Go pour éviter la dérive de l’environnement de build.
Partager une base entre environnements « temporairement » tend à devenir permanent, et c’est ainsi que des données de test fuient en staging et des scripts de staging touchent la production. Séparez les bases (et les credentials) par environnement, même si le schéma est identique.
L’absence de health checks et de readiness permet à un déploiement de « réussir » alors que le service est cassé, et le trafic est routé trop tôt. Ajoutez des checks qui reflètent le comportement réel : l’app peut-elle démarrer, se connecter à la DB et servir une requête ?
Enfin, une propriété floue des secrets, de la config et des accès transforme les releases en devinettes. Quelqu’un doit être responsable de la création, rotation et injection des secrets.
Un échec réaliste : une équipe merge un changement, le pipeline déploie et une migration automatique s’exécute en premier. Elle passe en staging (petites données), mais timeoute en production (données volumineuses). Avec des images verrouillées, une séparation d’environnements et une étape de migration gateée, le déploiement se serait arrêté sans risque.
Si vous générez des backends Go (par exemple avec AppMaster), ces règles pèsent encore plus car la régénération peut toucher de nombreux fichiers à la fois. Des entrées prévisibles et des gates explicites empêchent les « gros » changements de devenir des releases risquées.
Checklist rapide pour un CI/CD prévisible
Conservez un code propre lors de la régénération
Évitez la dette technique en régénérant proprement l'application au fur et à mesure que le schéma et les endpoints évoluent.
Utilisez ceci comme contrôle instinctif pour le CI/CD de backends Go. Si vous pouvez répondre « oui » clairement à chaque point, les releases deviennent plus simples.
- Verrouillez l’environnement, pas seulement le code. Pinnez la version de Go et l’image de build, et utilisez la même configuration localement et en CI.
- Faites tourner le pipeline avec 3 commandes simples. Une commande build, une lance les tests, une produit l’artefact déployable.
- Traitez les migrations comme du code de production. Exigez des logs pour chaque exécution et documentez ce que « rollback » signifie pour votre app.
- Produisez des artefacts immuables traçables. Buildez une fois, taggez avec le commit SHA et promouvez sans rebuild.
- Déployez avec des checks qui échouent vite. Ajoutez readiness/liveness et un petit test de fumée sur chaque déploiement.
Limitez et auditez l’accès à la production. Le CI doit déployer en utilisant un compte service dédié, les secrets doivent être gérés centralement, et toute action manuelle en production doit laisser une trace claire (qui, quoi, quand).
Un exemple réaliste et des prochaines étapes à lancer cette semaine
Une petite équipe ops de quatre personnes publie une fois par semaine. Elle régénère souvent son backend Go parce que l’équipe produit affine régulièrement les workflows. Leur objectif : moins de corrections nocturnes et des releases sans surprise.
Un changement typique du vendredi : ajouter un nouveau champ à customers (changement de schéma) et mettre à jour l’API qui l’écrit (changement de code). Le pipeline traite tout cela comme une seule release. Il construit un artefact, exécute les tests contre cet artefact exact, puis applique les migrations et déploie. Ainsi la base n’est jamais en avance sur le code qui l’attend, et le code n’est jamais déployé sans son schéma correspondant.
Quand un changement de schéma est inclus, le pipeline ajoute une gate de sécurité. Il vérifie que la migration est additive (par exemple ajout d’une colonne nullable) et marque les actions risquées (suppression de colonne ou réécriture d’une grosse table). Si la migration est risquée, la release s’arrête avant la production. L’équipe réécrit la migration pour la rendre plus sûre ou planifie une fenêtre prévue.
Si les tests échouent, rien n’avance. Il en va de même si les migrations échouent en pré-prod. Le pipeline ne doit pas essayer de forcer les changements « juste cette fois ».
Un ensemble simple d’étapes suivantes qui fonctionne pour la plupart des équipes :
- Commencez avec un seul environnement (un déploiement dev que vous pouvez réinitialiser en toute sécurité).
- Faites en sorte que le pipeline produise toujours un artefact versionné.
- Exécutez les migrations automatiquement en dev, mais exigez une approbation en production.
- Ajoutez staging seulement après que dev est stable quelques semaines.
- Ajoutez une gate production nécessitant tests verts et un déploiement staging réussi.
Si vous générez des backends avec AppMaster, maintenez la régénération dans les mêmes étapes du pipeline : régénérer, builder, tester, migrer dans un environnement sûr, puis déployer. Traitez le code généré comme n’importe quel autre code source. Chaque release doit être reproductible depuis une version taggée, avec les mêmes étapes à chaque fois.
FAQ
Verrouillez la version de Go et l’environnement de build pour que les mêmes entrées produisent toujours le même binaire ou la même image. Cela élimine les différences « ça marche sur ma machine » et facilite la reproduction et la correction des erreurs.
La régénération peut modifier les endpoints, les modèles de données et les dépendances même si personne n’a édité le code à la main. Un pipeline fait passer ces changements par les mêmes contrôles à chaque fois, de sorte que la régénération reste sûre plutôt que risquée.
Construisez une fois, puis promouvez exactement le même artefact en dev, staging et prod. Si vous rebuild par environnement, vous risquez d’expédier quelque chose que vous n’avez jamais testé, même si le commit est identique.
Exécutez des gardes rapides sur chaque pull request : formatage, vérifications statiques basiques, build et tests unitaires avec des timeouts. Gardez-le assez rapide pour que les gens ne le contournent pas, et assez strict pour que les changements cassés s’arrêtent tôt.
Utilisez une petite étape d’intégration qui démarre le service avec une configuration proche de la production et qui se connecte à des dépendances réelles comme PostgreSQL. L’objectif est de détecter « ça compile mais ne démarre pas » et les ruptures évidentes de contrat sans transformer CI en une suite end-to-end de plusieurs heures.
Traitez les migrations comme une étape contrôlée de la release, pas comme quelque chose qui s’exécute implicitement à chaque déploiement. Exécutez-les avec des logs clairs et un verrou d’exécution unique, et soyez réaliste sur le rollback : beaucoup de changements de schéma nécessitent des corrections vers l’avant ou des backups plutôt qu’un simple undo.
Ajoutez des checks de readiness pour que le trafic n’atteigne les nouveaux pods que lorsque le service est vraiment prêt, et des checks de liveness pour redémarrer les conteneurs bloqués. Fixez aussi des requests/limits réalistes afin qu’un service passant en CI ne soit pas tué pour consommation mémoire excessive en production.
Un simple unit systemd plus un script de release cohérent suffisent souvent pour des déploiements calmes sur VMs. Conservez le même modèle d’artefact qu’avec des conteneurs quand c’est possible, et ajoutez un petit test de fumée post-déploiement pour qu’un « redémarrage réussi » ne masque pas un service cassé.
Ne stockez jamais les secrets dans le repo, l’artefact de build ou les logs. Injectez-les au moment du déploiement depuis un magasin de secrets géré, limitez qui peut les lire et faites de la rotation une tâche routinière plutôt qu’un plan d’urgence.
Placez la régénération dans les mêmes étapes que tout autre changement : régénérer, construire, tester, packager, puis migrer et déployer avec des gates. Si vous utilisez AppMaster pour générer votre backend Go, cela vous permet d’avancer vite sans deviner ce qui a changé et d’intégrer la régénération au flux no-code en toute confiance.