App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
Leer schemawijzigingen zonder downtime met additieve migraties, veilige backfills en gefaseerde rollouts die oudere clients tijdens releases werkend houden.
Zero-downtime schemawijzigingen betekenen niet dat er niets verandert. Het betekent dat gebruikers door kunnen werken terwijl je de database en de app bijwerkt, zonder dat workflows falen of geblokkeerd raken.
Downtime is elk moment waarop je systeem zich niet normaal gedraagt. Dat kan eruitzien als 500-fouten, API-timeouts, schermen die laden maar lege of verkeerde waarden tonen, achtergrondjobs die crashen, of een database die reads accepteert maar writes blokkeert omdat een lange migratie locks vasthoudt.
Een schemawijziging kan meer breken dan alleen de hoofdapp-UI. Veelvoorkomende foutpunten zijn API-clients die een oud response-formaat verwachten, achtergrondjobs die specifieke kolommen lezen of schrijven, rapporten die tabellen direct bevragen, third-party integraties en interne admin-scripts die “gisteren nog goed werkten.”
Oudere mobiele apps en gecachte clients zijn een veelvoorkomend probleem omdat je ze niet meteen kunt updaten. Sommige gebruikers houden een app-versie wekenlang. Anderen hebben wisselende connectiviteit en proberen oude verzoeken later opnieuw. Zelfs webclients kunnen zich gedragen als “oudere versies” wanneer een service worker, CDN of proxy-cache verouderde code of veronderstellingen vasthoudt.
Het echte doel is niet “één grote migratie die snel klaar is.” Het is een reeks kleine stappen waarbij elke stap op zichzelf werkt, zelfs als verschillende clients op verschillende versies zitten.
Een praktische definitie: je moet nieuwe code en nieuw schema in willekeurige volgorde kunnen uitrollen en het systeem moet nog steeds werken.
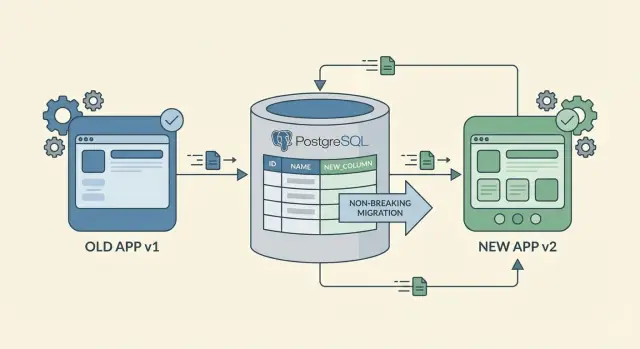
Die mindset helpt je de klassieke val te vermijden: een nieuwe app deployen die een nieuwe kolom verwacht voordat die kolom bestaat, of een nieuwe kolom toevoegen die oude code niet aankan. Plan wijzigingen zodat ze eerst additief zijn, rol ze gefaseerd uit en verwijder oude paden pas als je zeker weet dat niemand ze meer gebruikt.
De veiligste weg naar zero-downtime schemawijzigingen is toevoegen, niet vervangen. Een nieuwe kolom of een nieuwe tabel toevoegen breekt zelden iets omdat bestaande code de oude vorm kan blijven gebruiken.
Hernoemingen en verwijderingen zijn de risicovolle zetten. Een hernaam is in feite “voeg nieuw toe + verwijder oud,” en het verwijderen is waar oudere clients crashen. Als je moet hernoemen, behandel het dan als een tweestapwijziging: voeg eerst het nieuwe veld toe, houd het oude veld nog even, en verwijder het pas als je zeker weet dat er niks meer van afhangt.
Als je kolommen toevoegt, begin dan met nullable velden. Een nullable kolom laat oude code nog rijen inserten zonder iets van het nieuwe veld te weten. Als je uiteindelijk NOT NULL wilt, voeg het dan eerst als nullable toe, backfill, en handhaaf NOT NULL later. Defaults kunnen ook helpen, maar let op: het toevoegen van een default kan in sommige databases alsnog veel rijen aanraken, wat de wijziging vertraagt.
Indexen zijn een andere “veilig maar niet gratis” toevoeging. Ze kunnen reads versnellen, maar het bouwen en onderhouden van een index kan writes vertragen. Voeg indexen toe als je precies weet welke query er gebruik van zal maken en overweeg uitrol tijdens rustigere uren als je database druk is.
Een simpele regelset voor additieve database-migraties:
Behandel zero-downtime schemawijzigingen als een rollout, niet als één enkele deploy. Het doel is om oude en nieuwe app-versies naast elkaar te laten draaien terwijl de database geleidelijk naar de nieuwe vorm beweegt.
Een praktische volgorde:
Voorbeeld: je introduceert full_name maar oudere clients sturen nog first_name en last_name. De backend kan voor een periode full_name construeren bij writes, bestaande gebruikers backfillen en later standaard full_name lezen terwijl je nog steeds oude payloads ondersteunt. Pas na duidelijke adoptie drop je de oude velden.
Een backfill vult een nieuwe kolom of tabel voor bestaande rijen. Het is vaak het riskantste deel van zero-downtime schemawijzigingen omdat het zware database-load, lange locks en verwarrend "half-gemigreerd" gedrag kan veroorzaken.
Begin met het kiezen hoe je de backfill uitvoert. Voor kleine datasets volstaat soms een eenmalig handmatig runbook. Voor grotere datasets heeft een background worker of geplande taak de voorkeur die herhaald kan draaien en veilig kan stoppen.
Batch het werk zodat je de druk op de database onder controle houdt. Update geen miljoenen rijen in één transactie. Streef naar voorspelbare chunkgroottes en korte pauzes tussen batches zodat normaal gebruikersverkeer vloeiend blijft.
Een praktisch patroon:
Maak de job restartable. Sla een simpele voortgangsmarker op in een aparte tabel en ontwerp de job zo dat herstarten geen data corrumpeert. Idempotente updates (bijv. update waar new_field IS NULL) zijn je vriend.
Valideer onderweg. Houd bij hoeveel rijen nog de nieuwe waarde missen en voeg een paar sanity checks toe. Bijvoorbeeld: geen negatieve saldi, timestamps binnen verwacht bereik, status in een toegestane set. Controleer steekproefsgewijs echte records.
Bepaal wat de app moet doen terwijl de backfill incompleet is. Een veilige optie is fallback-reads: als het nieuwe veld null is, bereken of lees de oude waarde. Voorbeeld: je voegt een nieuw preferred_language-veld toe. Totdat de backfill klaar is, kan de API de bestaande taal uit de profielinstellingen teruggeven wanneer preferred_language leeg is, en pas later het nieuwe veld verplichten.
Wanneer je een schemawijziging uitrolt, heb je zelden controle over alle clients. Webgebruikers updaten snel, terwijl oudere mobiele builds weken actief kunnen blijven. Daarom zijn achterwaarts compatibele API's belangrijk, zelfs als je database-migratie "veilig" is.
Behandel nieuwe data eerst als optioneel. Voeg nieuwe velden toe aan requests en responses, maar eis ze niet direct. Als een oudere client het nieuwe veld niet stuurt, moet de server het verzoek nog steeds accepteren en zich hetzelfde gedragen als gisteren.
Vermijd het veranderen van de betekenis van bestaande velden. Een hernaam kan oké zijn als je de oude naam ook blijft ondersteunen. Het hergebruiken van een veld voor een nieuwe betekenis is waar subtiele breuken ontstaan.
Server-side defaults zijn je vangnet. Wanneer je een nieuwe kolom zoals preferred_language introduceert, stel een default in op de server wanneer het ontbreekt. De API-response kan het nieuwe veld bevatten; oudere clients negeren het gewoon.
Compatibiliteitsregels die de meeste outages voorkomen:
Voorbeeld: je voegt company_size toe aan een signup-flow. De backend kan een default zoals "unknown" zetten als het veld ontbreekt. Nieuwere clients sturen de echte waarde, oude clients blijven werken en dashboards blijven leesbaar.
Als je platform de applicatie regenereert, krijg je een schone rebuild van code en configuratie. Dat helpt bij zero-downtime schemawijzigingen omdat je kleine, additieve stappen kunt maken en vaak kunt redeployen in plaats van patches maanden mee te dragen.
De sleutel is één bron van waarheid. Als het databaseschema op de ene plek verandert en businesslogica ergens anders, ontstaat drift snel. Bepaal waar wijzigingen worden gedefinieerd en behandel alles anders als gegenereerde output.
Duidelijke namen verminderen ongelukken tijdens gefaseerde rollouts. Als je een nieuw veld introduceert, maak dan duidelijk welk veld veilig is voor oude clients en welk veld het nieuwe pad is. Bijvoorbeeld: een nieuwe kolom status_v2 is veiliger dan status_new omdat het zes maanden later nog steeds zinvol is.
Zelfs als wijzigingen additief zijn, kan een rebuild verborgen koppelingen blootleggen. Controleer na elke regeneratie en deploy een kleine set kritieke flows:
Plan de migratiestappen voordat je je editor opent: voeg het nieuwe veld toe, deploy met beide velden ondersteund, backfill, schakel reads, en retireer het oude pad later. Die volgorde houdt schema, logica en gegenereerde code synchroon zodat wijzigingen klein, reviewbaar en omkeerbaar blijven.
De meeste outages bij zero-downtime schemawijzigingen worden niet veroorzaakt door "zware" databaseacties. Ze ontstaan door het veranderen van het contract tussen database, API en clients in de verkeerde volgorde.
Veelvoorkomende valkuilen en veiligere zetten:
Als je je app regenereert is het verleidelijk om namen en constraints in één keer op te ruimen. Weersta die drang. Opruimen is de laatste stap, niet de eerste.
Een goede regel: als een wijziging niet veilig naar voren en terug kan worden gerold, is het niet klaar voor productie.
Zero-downtime schemawijzigingen slagen of falen op twee dingen: wat je bewaakt en hoe snel je kunt stoppen.
Volg signalen die echte gebruikersimpact reflecteren, niet alleen "de deploy is afgerond":
Als je dual writes doet (zowel naar oude als nieuwe kolommen/tabellen schrijven), voeg dan tijdelijke logging toe die de twee vergelijkt. Houd het beperkt: log alleen wanneer waarden verschillen, include record-ID en een korte reden-code, en sample als volume hoog is. Maak een reminder om deze logging na migratie te verwijderen zodat het geen permanente ruis wordt.
Rollback moet realistisch zijn. Meestal rol je de code terug en laat je het additieve schema staan.
Een praktisch rollback-runbook:
Voor backfills bouw je een stop-knop die je in seconden kunt omzetten (featureflag, configwaarde, job-pauze). Communiceer ook de fasen van tevoren: wanneer dual writes starten, wanneer backfill draait, wanneer reads omschakelen en wat "stop" betekent zodat niemand improvised onder druk.
Net voordat je een schemawijziging uitrolt, pauzeer en doorloop deze snelle check. Het vangt kleine aannames die met gemixte clientversies tot outages leiden.
Als je een regenererend platform gebruikt, voeg dan nog één sanity check toe: genereer en deploy een build van exact het model waar je naar migreert en bevestig dat de gegenereerde API en businesslogica nog steeds tolereren dat oude records bestaan. Een veelvoorkomende fout is aannemen dat het nieuwe schema ook direct nieuwe vereiste logica impliceert.
Schrijf ook twee snelle acties op die je neemt als iets na deploy mis lijkt: wat je monitort (errors, timeouts, backfill-voortgang) en wat je eerste terugdraai-actie is (featureflag uit, backfill pauzeren, server-release revert). Dat maakt van "we reageren snel" een echt plan.
Je runt een order-app. Je hebt een nieuw veld nodig, delivery_window, en het wordt vereist voor nieuwe businessregels. Het probleem is dat oudere iOS- en Android-builds nog in gebruik zijn en die sturen dat veld niet voor dagen of weken. Als je de database het meteen verplicht, gaan die clients falen.
Een veilige weg:
delivery_window voor oude rijen in via een regel (afleiden uit verzendmethode of default naar "anytime" totdat de klant het aanpast).delivery_window te lezen, maar val terug op de afgeleide waarde als het ontbreekt.Wat gebruikers tijdens elke fase ervaren blijft saai (dat is het doel):
Een eenvoudige monitoring-gate voor elke stap: volg het percentage nieuwe orders waarbij delivery_window niet-null is. Wanneer dat consistent hoog blijft (en validatiefouten voor "ontbrekend veld" bijna nul zijn), is het meestal veilig om van backfill naar afdwingen over te gaan.
Een eenmalige zorgvuldige rollout is geen strategie. Behandel schemawijzigingen als routine: dezelfde stappen, dezelfde naamgeving, dezelfde goedkeuringen. Dan blijft de volgende additieve wijziging saai, ook als de app druk is en clients op verschillende versies zitten.
Houd het playbook kort. Het moet antwoord geven op: wat voegen we toe, hoe shippen we het veilig en wanneer verwijderen we het oude.
Een simpel sjabloon:
Begin met een low-risk tabel (een nieuw optioneel statusveld, een notitieveld) en doorloop het volledige playbook end-to-end: additieve wijziging, backfill, gemixte clientversies en dan cleanup. Die oefening legt gaten in monitoring, batching en communicatie bloot voordat je een groot redesign probeert.
Een gewoonte die langdurige rommel voorkomt: behandel "verwijder later"-items als echt werk. Wanneer je een tijdelijke kolom, compatibiliteitscode of dual-write-logic toevoegt, maak meteen een cleanup-ticket met een eigenaar en datum. Houd een klein "compatibility debt"-notitie in de release-docs zodat het zichtbaar blijft.
Als je met AppMaster bouwt, kun je regeneratie als onderdeel van het veiligheidsproces behandelen: modelleer het additieve schema, update businesslogica zodat het zowel oude als nieuwe velden ondersteunt tijdens de transitie en regenereer zodat de broncode schoon blijft naarmate vereisten veranderen. Als je wilt zien hoe deze workflow past in een no-code setup die toch echte sourcecode produceert, is AppMaster (appmaster.io) ontworpen rond die stijl van iteratieve, gefaseerde levering.
Het doel is geen perfectie. Het doel is herhaalbaarheid: elke migratie heeft een plan, een meting en een uitweg.
Zero-downtime betekent dat gebruikers normaal kunnen blijven werken terwijl je het schema wijzigt en code uitrolt. Dat omvat het vermijden van zichtbare uitval, maar ook het voorkomen van stille breuken zoals lege schermen, foute waarden, crashes van taken of writes die geblokkeerd worden door lange locks.
Omdat veel onderdelen van je systeem afhankelijk zijn van de vorm van de database, niet alleen van de hoofd-UI. Achtergrondjobs, rapporten, admin-scripts, integraties en oudere mobiele apps kunnen nog lang oude velden verwachten of sturen nadat je nieuwe code hebt uitgerold.
Oudere mobiele builds kunnen weken actief blijven en sommige clients proberen oude verzoeken later opnieuw. Je API moet dus een tijd lang zowel oude als nieuwe payloads accepteren zodat gemixte versies naast elkaar kunnen bestaan zonder fouten.
Additieve wijzigingen breken meestal geen bestaande code omdat het oude schema blijft bestaan. Hernoemen en verwijderen zijn risicovol omdat ze iets weghalen dat oudere clients nog lezen of schrijven, wat leidt tot crashes of geweigerde verzoeken.
Maak de kolom eerst nullable zodat oude code nog rijen kan invoegen. Backfill bestaande rijen in batches en pas NOT NULL pas toe als de dekking hoog is en nieuwe writes consistent zijn.
Behandel het als een rollout: voeg compatibel schema toe, deploy code die beide versies ondersteunt, backfill in kleine batches, schakel reads met fallback en verwijder het oude veld pas als je kunt bewijzen dat het ongebruikt is. Elke stap moet op zichzelf veilig zijn.
Draai het in kleine batches met korte transacties zodat je geen tabellen locked of de load laat pieken. Maak het restartable en idempotent door alleen rijen bij te werken die de nieuwe waarde missen en houd voortgang bij zodat je veilig kunt pauzeren en hervatten.
Maak nieuwe velden eerst optioneel en pas server-side defaults toe als ze ontbreken. Houd oud gedrag stabiel, verander de betekenis van bestaande velden niet en test beide paden: “nieuwe client stuurt het” en “oude client laat het weg.”
Meestal rol je applicatiecode terug, niet het schema. Houd de additieve kolommen/tabellen, schakel nieuwe reads eerst uit, daarna nieuwe writes, en pauzeer backfills totdat metrics stabiel zijn zodat je snel kunt herstellen zonder dataverlies.
Houd gebruikers-signalen in de gaten zoals foutpercentages, trage queries, write-latency, queue-diepte en database CPU/IO na elke fase. Ga pas door naar de volgende stap als de metrics stabiel zijn en de dekking voor het nieuwe veld hoog is; plan cleanup als echt werk, niet als iets later.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


