App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
Soft delete vs hard delete: leer hoe je historie bewaart, gebroken verwijzingen voorkomt en toch voldoet aan privacyverplichtingen met duidelijke regels.
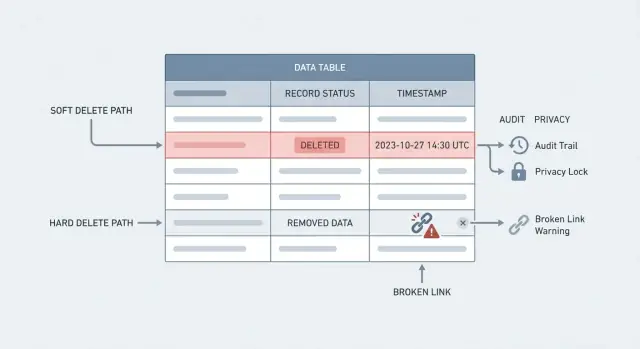
"Verwijderen" kan twee heel verschillende dingen betekenen. Ze door elkaar halen is hoe teams historie verliezen of privacyverzoeken niet kunnen uitvoeren.
Een hard delete is wat de meeste mensen zich voorstellen: de rij wordt uit de database verwijderd. Vraag je er later naar, dan is die weg. Dat is echte verwijdering, maar het kan ook verwijzingen breken (zoals een bestelling die naar een verwijderde klant wijst) tenzij je daar omheen ontwerpt.
Een soft delete houdt de rij, maar markeert deze als verwijderd, meestal met een veld zoals deleted_at of is_deleted. Je app behandelt het als verdwenen, maar de data blijft beschikbaar voor rapporten, support en audits.
De afweging bij soft delete vs hard delete is simpel: historie vs echte verwijdering. Soft delete beschermt historie en maakt "ongedaan maken" mogelijk. Hard delete vermindert wat je bewaart, wat telt voor privacy, beveiliging en wetgeving.
Verwijderingen beïnvloeden meer dan opslag. Ze veranderen wat je team later kan beantwoorden: een supportmedewerker die een klacht wil begrijpen, finance die wil reconciliëren, of compliance die wil controleren wie wat en wanneer wijzigde. Als data te vroeg verdwijnt, wijzigen rapporten, sluiten totalen niet meer aan en worden onderzoeken giswerk.
Een nuttig mentaal model:
In de praktijk kun je een gebruikersaccount soft-deleten om inloggen te voorkomen en bestelhistorie intact te houden, en daarna persoonlijke velden hard-deleten (of anonimiseren) na een bewaartermijn of een geverifieerd GDPR-recht-op-vergetelheid-verzoek.
Geen enkele tool neemt deze beslissing voor je. Zelfs als je bouwt met een no-code platform zoals AppMaster, is het echte werk beslissen per tabel wat “verwijderd” betekent en zorgen dat elk scherm, rapport en elke API dezelfde regel volgt.
De meeste teams merken deletes alleen als er iets misgaat. Een "simpele" verwijdering kan context, historie en je vermogen om uit te leggen wat er gebeurde wissen.
Hard deletes zijn riskant omdat ze moeilijk te herstellen zijn. Iemand klikt op de verkeerde knop, een geautomatiseerde taak heeft een bug, of een supportmedewerker volgt het verkeerde stappenplan. Zonder schone backups en een duidelijk herstelproces wordt dat verlies permanent, en de zakelijke impact is direct voelbaar.
Gebroken verwijzingen zijn de volgende verrassing. Je verwijdert een klant, maar hun bestellingen bestaan nog. Nu wijzen bestellingen naar niets, facturen kunnen geen naam tonen en een portal geeft fouten bij het laden van gerelateerde data. Zelfs met foreign key constraints kan de "oplossing" erger zijn: cascades kunnen veel meer wissen dan bedoeld.
Analytics en rapportage worden ook rommelig. Wanneer oude records verdwijnen, veranderen metrics retroactief. Vorige maand verschuift de conversieratio, de lifetime value daalt en trendlijnen krijgen gaten die niemand kan verklaren. Het team begint over cijfers te ruziën in plaats van beslissingen te nemen.
Support en compliance zijn waar het het meeste pijn doet. Klanten vragen: "Waarom is mij iets in rekening gebracht?" of "Wie heeft mijn plan veranderd?" Als het record weg is, kun je geen tijdlijn reconstrueren. Je verliest het auditspoor dat basisvragen zou beantwoorden zoals wat veranderde, wanneer en door wie.
Veelvoorkomende faalpatronen rond soft delete vs hard delete:
Soft delete is meestal de veiligste keuze wanneer een record langetermijnwaarde heeft of verbonden is met andere data. In plaats van een rij te verwijderen, markeer je deze als verwijderd (bijvoorbeeld deleted_at of is_deleted) en verberg je het in normale weergaven. In een soft delete vs hard delete-beslissing reduceert deze standaard vaak verrassingen later.
Het blinkt uit waar je een auditspoor in databases nodig hebt. Operatieteams moeten vaak simpele vragen beantwoorden zoals "Wie wijzigde deze bestelling?" of "Waarom werd deze factuur geannuleerd?" Als je te vroeg hard delete, verlies je bewijs dat van belang is voor finance, support en compliance-rapportage.
Soft delete maakt ook "ongedaan maken" mogelijk. Admins kunnen een ticket herstellen dat per ongeluk gesloten werd, een gearchiveerd product terughalen of door gebruikers gegenereerde content herstellen na een vals spamrapport. Zulke herstelstromen zijn moeilijk te bieden als de data fysiek weg is.
Relaties zijn een andere grote reden. Hard het verwijderen van een ouderrij kan foreign key-constraints breken of verwarrende gaten in rapporten achterlaten. Met soft delete blijven joins stabiel en blijven historische totalen consistent (dagelijkse omzet, vervulde bestellingen, reactietijdstatistieken).
Soft delete is een sterke standaard voor bedrijfsrecords zoals supporttickets, berichten, bestellingen, facturen, auditlogs, activiteitsgeschiedenis en gebruikersprofielen (althans totdat je definitieve verwijdering bevestigt).
Voorbeeld: een supportmedewerker "verwijdert" een bestelnotitie met een fout. Met soft delete verdwijnt de notitie uit de normale UI, maar supervisors kunnen deze nog beoordelen bij een klacht en finance-rapporten blijven verklaarbaar.
Soft delete is een uitstekende standaard voor veel apps, maar er zijn momenten waarop het bewaren van data (zelfs verborgen) de verkeerde keuze is. Hard delete betekent dat het record echt wordt verwijderd, en soms is dat de enige optie die past bij juridische, veiligheids- of kostenvereisten.
Het duidelijkste geval is privacy en contractuele verplichtingen. Als iemand aanspraak maakt op het GDPR-recht op vergetelheid, of je contract belooft verwijdering na een bepaalde periode, telt "gemarkeerd als verwijderd" vaak niet. Je moet dan mogelijk de rij, gerelateerde kopieën en opgeslagen identifiers die naar de persoon wijzen verwijderen.
Beveiliging is een andere reden. Sommige data is te gevoelig om te bewaren: ruwe access tokens, wachtwoord-resetcodes, privésleutels, eenmalige verificatiecodes of onversleutelde secrets. Die bewaren voor historie is zelden de moeite waard.
Hard delete kan ook de juiste keuze zijn voor schaal. Als je enorme tabellen met oude events, logs of telemetrie hebt, groeit een soft delete ongemerkt je database en vertraagt queries. Een gepland purge-beleid houdt het systeem responsief en de kosten voorspelbaar.
Hard delete is vaak passend voor tijdelijke data (caches, sessies, concept-imports), kortlevende security-artifacts (reset tokens, OTPs, invite codes), test/demo-accounts en grote historische datasets waarvan alleen geaggregeerde statistieken nodig zijn.
Een praktische aanpak is bedrijfs- historie te scheiden van persoonlijke data. Bijvoorbeeld: bewaar facturen voor de boekhouding, maar hard-delete (of anonimiseer) de gebruikersprofielvelden die een persoon identificeren.
Als je team discussieert over soft delete vs hard delete, gebruik dan een eenvoudige toets: als het bewaren van de data juridisch of beveiligingsrisico creëert, wint hard delete (of onherroepelijke anonimisering).
Een soft delete werkt het beste wanneer het saai en voorspelbaar is. Het doel is simpel: het record blijft in de database, maar normale onderdelen van de app doen alsof het weg is.
Je ziet drie veelvoorkomende patronen: een deleted_at timestamp, een is_deleted-vlag of een statusenum. Veel teams geven de voorkeur aan deleted_at omdat het twee vragen tegelijk beantwoordt: is het verwijderd en wanneer gebeurde dat.
Als je al meerdere lifecycle-states hebt (active, pending, suspended), kan een statusenum nog steeds werken, maar houd “deleted” gescheiden van “archived” en “deactivated.” Dat zijn verschillendies:
Soft delete vs hard delete loopt vaak vast op unieke velden zoals e-mail, gebruikersnaam of ordernummer. Als een gebruiker "verwijderd" is maar hun e-mail nog uniek is opgeslagen, kan dezelfde persoon zich niet opnieuw registreren.
Twee veelvoorkomende oplossingen: maak uniekheid alleen van toepassing op niet-verwijderde rijen, of herschrijf de waarde bij verwijdering (bijv. voeg een random suffix toe). Welke je kiest hangt af van privacy- en auditbehoeften.
Bepaal welke doelgroepen wat mogen zien. Een veelgebruikt regelsysteem is: reguliere gebruikers zien nooit verwijderde records, support/admin gebruikers kunnen ze zien met een duidelijke label, en exports/rapporten bevatten ze alleen op verzoek.
Vertrouw niet op "iedereen onthoudt de filter". Leg de regel op één plek vast: views, default queries of je data access layer. Als je in AppMaster bouwt, betekent dat meestal het filter inbouwen in hoe je endpoints en business processes data ophalen, zodat verwijderde rijen niet per ongeluk terugkomen op een nieuw scherm.
Schrijf de betekenissen op in een korte interne notitie (of schema-opmerkingen). Je toekomstige zelf zal je bedanken als “deleted”, “archived” en “deactivated” in dezelfde meeting opduiken.
Verwijderingen breken apps het vaakst via relaties. Een record staat zelden op zichzelf: gebruikers hebben bestellingen, tickets hebben reacties, projecten hebben bestanden. Het lastige deel in soft delete vs hard delete is referenties consistent houden terwijl het product nog steeds doet alsof het item "weg" is.
Foreign keys beschermen je tegen gebroken referenties, maar elke optie heeft een andere betekenis:
Als je soft delete gebruikt, is RESTRICT vaak de veiligste standaard. Je houdt de rij, dus sleutels blijven geldig en je voorkomt dat kinderen naar niets wijzen.
Soft delete betekent meestal dat je foreign keys niet verandert. In plaats daarvan filter je verwijderde ouders in de app en in rapporten. Als een klant soft-deleted is, moeten facturen nog steeds juist joinen, maar schermen mogen de klant niet in dropdowns tonen.
Voor attachments, opmerkingen en activiteitslogs bepaal je wat “verwijderen” voor de gebruiker betekent. Sommige teams houden de omhulling maar verwijderen de risicovolle delen: vervang attachment-content door een placeholder als privacy dat vereist, markeer opmerkingen als van een verwijderde gebruiker (of anonimiseer de auteur) en houd activiteitslogs onveranderlijk.
Joins en rapportage hebben een duidelijke regel nodig: moeten verwijderde rijen worden meegenomen? Veel teams houden twee standaardqueries: één "alleen actief" en één "inclusief verwijderde", zodat support en rapportage niets belangrijks per ongeluk verbergen.
Een praktisch beleid gebruikt vaak soft delete voor dagelijkse fouten en hard delete voor juridische of privacybehoeften. Als je het als één keuze (soft delete vs hard delete) behandelt, mis je het middengebied: bewaar historie een tijd, en purgeer wat echt weg moet.
Begin met het sorteren van data in een paar buckets. "Gebruikersprofiel" data is persoonlijk, "transacties" zijn financiële records en "logs" zijn systeemgeschiedenis. Elke bucket heeft andere regels nodig.
Een kort plan dat voor de meeste teams werkt:
Stel dat een klant vraagt zijn account te sluiten. Soft delete het gebruikersrecord direct zodat hij niet meer kan inloggen en je verwijst geen relaties kapot. Anonimiseer daarna persoonlijke velden die niet mogen blijven (naam, e-mail, telefoon), terwijl je niet-persoonlijke transactiedata voor boekhouding bewaart. Tenslotte verwijdert een geplande purge-job wat na de wachttijd nog persoonlijk is.
Teams komen in de problemen niet omdat ze de verkeerde aanpak kiezen, maar omdat ze die ongelijk toepassen. Een veelvoorkomend patroon is “soft delete vs hard delete” op papier, maar “verberg het op één scherm en vergeet de rest” in de praktijk.
Een eenvoudige fout: je verbergt verwijderde records in de UI, maar ze verschijnen nog via de API, CSV-exports, admin-tools of data-sync jobs. Gebruikers merken snel wanneer een "verwijderde" klant in een mailingslijst of mobiele zoekresultaten verschijnt.
Rapporten en zoeken zijn een andere valkuil. Als rapportqueries niet consistent verwijderde rijen filteren, driften totalen af en worden dashboards onbetrouwbaar. De ergste gevallen zijn achtergrondjobs die items opnieuw indexeren of opnieuw verzenden omdat ze niet dezelfde regels toepassen.
Hard deletes kunnen ook te ver gaan. Eén cascade-delete kan bestellingen, facturen, berichten en logs wissen die je eigenlijk nodig had voor een audittrail. Als je moet hard-deleten, wees expliciet over wat mag verdwijnen en wat bewaard of geanonimiseerd moet worden.
Unieke constraints veroorzaken subtiele problemen met soft delete. Als een gebruiker zijn account verwijdert en zich later opnieuw probeert aan te melden met dezelfde e-mail, kan aanmelding falen als het oude record de unieke e-mail nog vasthoudt. Plan hiervoor vroeg.
Compliance-teams vragen: kun je bewijzen dat verwijdering plaatsvond en wanneer? "We denken dat het verwijderd is" haalt zelden een dataretentie-review. Houd een verwijderingstimestamp, wie/ wat het initieerde en een onveranderlijke logentry bij.
Voordat je live gaat, sanity-check het volledige oppervlak: API, exports, zoekfunctie, rapporten en achtergrondjobs. Controleer cascades tabel voor tabel en bevestig dat gebruikers unieke data zoals e-mail of gebruikersnaam kunnen opnieuw aanmaken als dat onderdeel is van je productbelofte.
Voordat je soft delete vs hard delete kiest, verifieer het echte gedrag van je app, niet alleen het schema.
Test dan de privacyroute end-to-end. Kun je een GDPR-verzoek tot verwijdering vervullen over kopieën, exports, zoekindexen, analytics-tabellen en integraties, niet alleen de hoofd-database?
Een praktische manier om dit te valideren is één "verwijder gebruiker" dry run in staging en volg de datatrail.
Een klant vraagt: “Verwijder mijn account.” Jij hebt ook facturen die voor de boekhouding en chargeback-controles moeten blijven. Dit is waar soft delete vs hard delete praktisch wordt: je kunt toegang en persoonlijke gegevens verwijderen terwijl je zakelijke transacties bewaart.
Scheid "het account" van "het facturatie-record." Het account gaat over login en identiteit. Het facturatierecord gaat over een transactie die al heeft plaatsgevonden.
Een nette aanpak:
Supporttickets en berichten zitten er vaak tussenin. Als berichtinhoud persoonlijke gegevens bevat, moet je mogelijk delen van de tekst redigeren, attachments verwijderen en de ticket-shell (tijdstempels, categorie, oplossing) bewaren voor kwaliteitsbewaking. Als je product berichten verstuurt (e-mail/SMS, Telegram), verwijder dan ook uitgaande identifiers zodat de persoon niet opnieuw gecontacteerd wordt.
Wat kan support nog zien? Meestal factuurnummers, datums, bedragen, status en een notitie dat de gebruiker verwijderd is en wanneer. Wat ze niet kunnen zien is alles dat de persoon identificeert: login-e-mail, volledige naam, adressen, opgeslagen betalingsgegevens of actieve sessies.
Verwijderingsbeslissingen blijven alleen plakken als ze opgeschreven zijn en op dezelfde manier in het product worden toegepast. Behandel soft delete vs hard delete eerst als een beleidsvraag, niet als een programmeertruc.
Begin met een eenvoudig gegevensbehoudsbeleid dat iedereen in het team kan lezen. Het moet zeggen wat je bewaart, hoe lang je het bewaart en waarom. “Waarom” is belangrijk omdat het bepaalt wat wint als twee doelen botsen (bijv. supporthistorie vs privacyverzoeken).
Een goed uitgangspunt is vaak: soft delete voor dagelijkse bedrijfsrecords (orders, tickets, projecten), hard delete voor écht gevoelige data (tokens, secrets) en alles wat je niet zou moeten bewaren.
Als het beleid duidelijk is, bouw de flows die het afdwingen: een "prullenbak"-weergave voor herstel, een "purge queue" voor onomkeerbare verwijdering na checks, en een auditweergave die toont wie wat deed en wanneer. Maak "purge" moeilijker dan "delete" zodat het niet per ongeluk gebruikt wordt.
Als je dit in AppMaster implementeert (appmaster.io), helpt het soft-delete-velden in de Data Designer te modelleren en delete-, restore- en purge-logica te centraliseren in één Business Process, zodat dezelfde regels gelden voor schermen en API-endpoints.
Een hard delete verwijdert de rij fysiek uit de database, zodat toekomstige queries die niet kunnen vinden. Een soft delete houdt de rij aan, maar markeert deze als verwijderd (vaak met deleted_at), zodat je app het in normale schermen verbergt terwijl de historie behouden blijft voor support, audits en rapportage.
Gebruik soft delete standaard voor bedrijfsrecords die je later mogelijk moet kunnen verklaren, zoals orders, facturen, tickets, berichten en accountactiviteit. Het vermindert onbedoeld dataverlies, behoudt relaties en maakt een veilige “ongedaan maken” mogelijk zonder uit back-ups te moeten herstellen.
Hard delete is het beste wanneer het bewaren van de data privacy- of beveiligingsrisico's oplevert, of wanneer bewaarteregels echte verwijdering vereisen. Typische voorbeelden zijn wachtwoord-reset-tokens, eenmalige codes, sessies, API-tokens en persoonsgegevens die na een geverifieerd verzoek of bewaartermijn gewist moeten worden.
Een deleted_at timestamp is een veelgebruikte keuze omdat het zowel aangeeft dat het record is verwijderd als wanneer dat gebeurde. Het ondersteunt praktische workflows zoals bewaartermijnen (bijv. purge na 30 dagen) en auditvragen (“wanneer is dit verwijderd?”) zonder aparte logs alleen voor timing.
Unieke velden zoals e-mail of gebruikersnaam blokkeren vaak opnieuw aanmelden als de “verwijderde” rij nog steeds de unieke waarde bevat. Een gebruikelijke oplossing is uniekheid alleen af te dwingen voor niet-verwijderde rijen, of de unieke waarde bij verwijdering te herschrijven (bijv. met een random suffix), afhankelijk van je privacy- en auditbehoeften.
Hard het verwijderen van een ouderrecord kan kinderen verweesd achterlaten (zoals orders) of cascades triggeren die veel meer verwijderen dan bedoeld. Soft delete vermijdt meestal gebroken referenties omdat sleutels geldig blijven, maar je hebt nog steeds consistente filtering nodig zodat verwijderde ouders niet in dropdowns of klantzichtbare joins verschijnen.
Als je historische rijen hard verwijdert, kunnen eerdere totalen veranderen, trends gaten krijgen en kunnen financiële cijfers niet meer overeenkomen met wat mensen eerder zagen. Soft delete helpt historie te behouden, maar alleen als rapportage- en analytics-queries duidelijk aangeven of ze verwijderde rijen meenemen en die regel consequent toepassen.
“Soft deleted” is vaak niet voldoende voor een recht-op-vergetelheid-verzoek onder GDPR omdat persoonsgegevens nog in de database en backups kunnen bestaan. Een praktische aanpak is direct toegang intrekken, daarna persoonsgegevens hard verwijderen of onherroepelijk anonimiseren en alleen niet-persoonlijke transactiegebeurtenissen bewaren die je voor boekhouding of geschillen nodig hebt.
Het herstellen moet het record terugbrengen in een veilige, geldige staat zonder gevoelige items te herstellen die weg moeten blijven, zoals sessies of reset-tokens. Er moeten ook duidelijke regels zijn voor gerelateerde data, zodat je niet een account herstelt terwijl vereiste relaties of permissies ontbreken.
Centraliseer delete-, herstel- en purge-gedrag zodat elke API, scherm, export en achtergrondjob dezelfde filterregel toepast. In AppMaster doe je dit meestal door soft-delete-velden in de Data Designer toe te voegen en de logica één keer in een Business Process te implementeren zodat nieuwe endpoints niet per ongeluk verwijderde data blootgeven.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


