App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
Leer hoe je SLA-timers en escalaties modelleert met duidelijke staten, onderhoudbare regels en eenvoudige escalatiepaden zodat workflow-apps makkelijk te wijzigen blijven.
Regels op basis van tijd beginnen meestal eenvoudig: “Als een ticket 2 uur geen antwoord heeft, waarschuw iemand.” Dan groeit de workflow, teams voegen uitzonderingen toe en plots weet niemand meer precies wat er gebeurt. Zo veranderen SLA-timers en escalaties in een doolhof.
Het helpt om de bewegende delen duidelijk te benoemen.
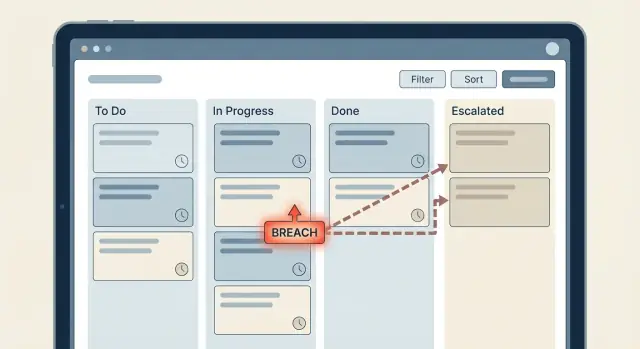
Een timer is de klok die je start (of plant) na een gebeurtenis, zoals “ticket naar Waiting for Agent.” Een escalatie is wat je doet wanneer die klok een drempel raakt, bijvoorbeeld het informeren van een lead, het veranderen van prioriteit of het herverdelen van werk. Een breach is het vastgelegde feit dat zegt: “We hebben de SLA gemist,” dat je gebruikt voor rapportage, alerts en follow-up.
Problemen ontstaan wanneer tijdslogica door de hele app verspreid raakt: een paar checks in de “update ticket” flow, nog meer checks in een nachtjob en ad-hoc regels toegevoegd later voor een speciale klant. Elk stukje is op zichzelf logisch, maar samen veroorzaken ze verrassingen.
Typische symptomen:
Het doel is voorspelbaar gedrag dat later makkelijk te veranderen blijft: één duidelijke bron van waarheid voor SLA-timing, expliciete breach-staten waarop je kunt rapporteren, en escalatiestappen die je kunt aanpassen zonder door visuele logica te moeten zoeken.
Voordat je timers bouwt, schrijf precies op welke belofte je meet. Veel rommelige logica ontstaat door te proberen alle mogelijke tijdregels meteen te dekken.
Veelvoorkomende SLA-typen klinken vergelijkbaar maar meten verschillende zaken:
Bepaal daarna wat “tijd” betekent. Kalendertijd telt 24/7. Werkuren tellen alleen gedefinieerde kantooruren (bijv. ma-vr, 9-18). Als je werkuren niet écht nodig hebt, vermijd ze in het begin. Ze voegen randgevallen toe zoals feestdagen, tijdzones en gedeeltelijke dagen.
Wees vervolgens specifiek over pauzes. Een pauze is niet alleen “status veranderd.” Het is een regel met een eigenaar. Wie mag pauzeren (alleen agent, alleen systeem, klantactie)? Welke statussen pauzeren (Waiting on Customer, On Hold, Pending Approval)? Wat hervat het? Wanneer het hervat, ga je door met de resterende tijd of start je de timer opnieuw?
Definieer tenslotte wat een breach productmatig betekent. Een breach moet een concreet ding zijn dat je kunt opslaan en queryen, zoals:
Voorbeeld: “First response SLA breached” kan betekenen dat het ticket de staat Breached krijgt, een breached_at timestamp en dat het escalatieniveau op 1 wordt gezet.
Als je wilt dat SLA-timers en escalaties leesbaar blijven, behandel SLA dan als een klein state machine. Wanneer de “waarheid” verspreid is over kleine checks (if now > due, if priority high, if last reply empty), wordt visuele logica snel rommelig en breken kleine veranderingen dingen.
Begin met een korte, afgesproken set SLA-staten die elke workflowstap kan begrijpen. Voor veel teams dekken deze de meeste gevallen:
Een enkele breached = true/false vlag is zelden genoeg. Je moet nog weten welke SLA gebroken is (first response vs resolution), of die momenteel gepauzeerd is en of je al geëscaleerd hebt. Zonder die context gaan mensen betekenis herleiden uit opmerkingen, tijdstempels en statusnamen. Daar wordt de logica fragiel.
Maak de staat expliciet en sla de tijdstempels op die het verklaren. Dan blijven beslissingen simpel: je evaluator leest het record, bepaalt de volgende staat en alles reageert op die staat.
Nuttige velden om op te slaan naast de staat:
started_at en due_at (welke klok draaien we en wanneer vervalt het?)breached_at (wanneer ging het echt over de grens?)paused_at en paused_reason (waarom stopte de klok?)breach_reason (welke regel de breach triggerde, in gewone taal)last_escalation_level (zodat je dezelfde laag niet twee keer informeert)Voorbeeld: een ticket gaat naar “Waiting on customer.” Zet de SLA-staat op Paused, registreer paused_reason = "waiting_on_customer" en stop de timer. Als de klant antwoordt, hervat je door started_at opnieuw te zetten (of de-pauzeren en due_at te herberekenen). Geen gezoek door veel voorwaarden.
Een escalatieladder is een duidelijk plan voor wat er gebeurt als een SLA-timer bijna breekt of al gebroken is. De fout is het kopiëren van het organogram naar de workflow. Je wilt de kleinste set stappen die een vastgelopen item weer in beweging krijgt.
Een simpele ladder die veel teams gebruiken: de toegewezen agent (Level 0) krijgt de eerste herinnering, daarna wordt de teamlead (Level 1) erbij gehaald en pas daarna de manager (Level 2). Het werkt omdat het begint waar het werk echt gedaan kan worden en autoriteit alleen escaleert als dat nodig is.
Om escalatieregels onderhoudbaar te houden, bewaar escalatiedrempels als data, niet als hardgecodeerde voorwaarden. Zet ze in een tabel of instellingenobject: “eerste herinnering na 30 minuten” of “escaleren naar lead na 2 uur.” Als beleid verandert, update je één plek in plaats van meerdere workflows te bewerken.
Escalaties veranderen in spam als ze te vaak afgaan. Voeg guardrails toe zodat elke stap een doel heeft:
Notificaties alleen lossen vastgelopen werk niet op als verantwoordelijkheid vaag blijft. Definieer eigendomsregels vooraf: blijft het ticket bij de agent, wordt het toegewezen aan de lead, of gaat het naar een gedeelde wachtrij?
Voorbeeld: na Level 1-escalatie wijs je het toe aan de teamlead en zet de oorspronkelijke agent als watcher. Dat maakt duidelijk wie nu moet handelen en voorkomt dat het item tussen mensen blijft stuiteren.
De makkelijkste manier om SLA-timers en escalaties onderhoudbaar te houden is ze te behandelen als een klein systeem met drie delen: events, een evaluator en acties. Dit voorkomt dat tijdslogica zich verspreidt over tientallen “if time > X”-checks.
Events zijn eenvoudige feiten die geen timerwiskunde moeten bevatten. Ze beantwoorden “wat veranderde?” niet “wat moeten we eraan doen?”. Typische events: ticket aangemaakt, agent geantwoord, klant geantwoord, status veranderd of een handmatige pauze/hervatting.
Sla deze op als tijdstempels en statusvelden (bijv. created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
Maak één “SLA evaluator”-stap die draait na elk event en op een periodieke planning. Deze evaluator is de enige plaats die due_at en resterende tijd berekent. Hij leest de huidige feiten, herberekent deadlines en schrijft expliciete SLA-staatvelden zoals sla_response_state en sla_resolution_state.
Hier blijft breach-statemodellering schoon: de evaluator zet staten zoals OK, AtRisk, Breached in plaats van logica te verbergen in notificaties.
Notificaties, toewijzingen en escalaties moeten alleen triggeren wanneer een staat verandert (bijv. OK -> AtRisk). Houd het verzenden van berichten gescheiden van het updaten van SLA-staat. Dan kun je aanpassen wie op de hoogte wordt gebracht zonder de berekeningen aan te raken.
Een onderhoudbare setup ziet er meestal zo uit: een paar velden op het record, een klein beleidstabelletje en één evaluator die bepaalt wat er vervolgens gebeurt.
Begin met de entiteit die de SLA bezit (ticket, order, request). Voeg expliciete tijdstempels en één “huidige SLA-staat” veld toe. Houd het saai en voorspelbaar.
Voeg daarna een klein beleidstabel toe die regels beschrijft in plaats van ze hard te coderen in meerdere flows. Een simpele versie is één regel per prioriteit (P1, P2, P3) met kolommen voor target-minuten en escalatiedrempels (bijv. waarschuwen op 80%, breach op 100%). Dit is het verschil tussen het wijzigen van één record versus het bewerken van vijf workflows.
In plaats van overal aparte timers te maken, gebruik je één periodiek proces dat items periodiek controleert (elke minuut voor strikte SLA's, elke 5 minuten voor veel teams). De scheduler roept één evaluator aan die:
sla_state en next_check_at wegschrijftDit maakt SLA-timers en escalaties makkelijker te begrijpen omdat je één evaluator debugt, niet veel timers.
De evaluator moet zowel de nieuwe staat als of deze veranderde outputten. Verstuur alleen berichten of taken wanneer de staat verschuift (bijv. ok -> warning, warning -> breached). Als een record een uur in breached blijft, wil je geen 12 herhaalde notificaties.
Een praktisch patroon: sla sla_state en last_escalation_level op, vergelijk ze met de nieuw berekende waarden en roep dan pas messaging (e-mail/SMS/Telegram) of maak een interne taak.
Pauzes zijn waar tijdsregels meestal rommelig worden. Als je ze niet duidelijk modelleert, blijft je SLA ofwel doorgaan wanneer dat niet hoort, of reset het wanneer iemand per ongeluk op de verkeerde status klikt.
Een simpele regel: slechts één status (of een kleine set) pauzeert de klok. Een veelvoorkomende keuze is Waiting for customer. Wanneer een ticket in die status gaat, sla je een pause_started_at timestamp op. Wanneer de klant reageert en het ticket die status verlaat, sluit je de pauze door pause_ended_at te schrijven en de duur toe te voegen aan paused_total_seconds.
Houd ieder pauzevenster vast (start, einde, wie of wat het triggerde) zodat je later een audittrail hebt. Als iemand vraagt waarom een zaak breached, kun je laten zien dat het 19 uur op de klant heeft gewacht.
Herschikking en normale statuswijzigingen moeten de klok niet opnieuw starten. Houd SLA-tijdstempels gescheiden van eigendomvelden. Bijvoorbeeld, sla_started_at en sla_due_at worden één keer gezet (bij creatie, of wanneer het SLA-beleid wijzigt), terwijl herallocatie alleen assignee_id bijwerkt. Je evaluator kan dan verstreken tijd berekenen als: nu minus sla_started_at minus paused_total_seconds.
Regels die SLA-timers en escalaties voorspelbaar houden:
Een eenvoudige manier om je ontwerp te testen is een supportticket met twee SLA's: first response in 30 minuten en volledige resolutie in 8 uur. Dit is waar logica vaak breekt als het verspreid zit over schermen en knoppen.
Ga ervan uit dat elk ticket opslaat: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), plus tijdstempels zoals created_at, first_agent_reply_at en resolved_at.
Een realistische tijdlijn:
Voor escalaties, houd één duidelijke keten die triggert op statusovergangen. Bijvoorbeeld: wanneer response Warning wordt, waarschuw de toegewezen agent. Wanneer het Breached wordt, informeer de teamlead en verhoog de prioriteit.
Update bij elke stap dezelfde kleine set velden zodat het eenvoudig te begrijpen blijft:
response_status of resolution_status op Pending, Warning, Breached of Met.*_warning_at en *_breach_at tijdstempels één keer en overschrijf ze niet.escalation_level (0, 1, 2) en zet escalated_to (Agent, Lead, Manager).sla_events logrij toe met het eventtype en wie geïnformeerd werd.priority en due_at zodat UI en rapporten de escalatie tonen.Het belangrijkste is dat Warning en Breached expliciete staten zijn. Je ziet ze in de data, kunt ze auditen en later de ladder aanpassen zonder verborgen timerchecks te moeten doorzoeken.
SLA-logica wordt rommelig als het zich verspreidt. Een snelle tijdscheck toegevoegd aan een knop hier, een conditionele alert daar, en al snel kan niemand uitleggen waarom een ticket escalatie kreeg. Houd SLA-timers en escalaties als een klein, centraal stuk logica waar elk scherm en elke actie op vertrouwt.
Een veelvoorkomende valkuil is het inbedden van tijdchecks op veel plaatsen (UI-schermen, API-handlers, handmatige acties). De oplossing is om SLA-status in één evaluator te berekenen en het resultaat op het record op te slaan. Schermen moeten status lezen, niet verzinnen.
Een andere valkuil is verschillende klokken gebruiken. Als de browser “minuten sinds gemaakt” berekent maar de backend servertijd gebruikt, zie je randgevallen rond slaap, tijdzones en zomertijdwisselingen. Geef de voorkeur aan servertijd voor alles wat een escalatie triggert.
Notificaties kunnen ook snel luidruchtig worden. Als je “elke minuut checken en versturen als overdue”, kunnen mensen elke minuut gemaild worden. Koppel berichten aan transities: “warning sent”, “escalated”, “breached”. Dan stuur je één keer per stap en kun je auditen wat er gebeurde.
Business-hours logica is ook een bron van onbedoelde complexiteit. Als elke regel haar eigen “if weekend then…” tak heeft, worden updates pijnlijk. Zet business-hours berekening in één functie (of gedeelde blok) die “SLA-minuten verbruikt tot nu” teruggeeft en hergebruik die.
Ten slotte: reken een breach niet steeds opnieuw uit. Sla het moment vast waarop het gebeurde:
breached_at de eerste keer dat je een breach detecteert en overschrijf die niet.escalation_level en last_escalated_at zodat acties idempotent zijn.notified_warning_at (of iets vergelijkbaars) om herhaalde alerts te voorkomen.Voorbeeld: een ticket bereikt “Response SLA breached” om 10:07. Als je alleen opnieuw berekent, kan een latere statuswijziging of een pauze/hervat-bug het lijken alsof de breach om 10:42 gebeurde. Met breached_at = 10:07 blijven rapportage en postmortems consistent.
Voordat je timers en alerts toevoegt, doe één pass met het doel regels over een maand nog leesbaar te houden.
Een praktische test: kies één ticket dat bijna breekt en speel zijn tijdlijn af. Als je niet kunt uitleggen wat er bij elke statuswijziging zal gebeuren zonder de hele workflow te lezen, is je model te verspreid.
Bouw eerst de kleinste nuttige slice. Kies één SLA (bijv. first response) en één escalatieniveau (bijv. informeer de teamlead). Je leert meer van een week echt gebruik dan van een perfect ontwerp op papier.
Bewaar drempels en ontvangers als data, niet als logica. Zet minuten en uren, werkurenregels, wie wordt geïnformeerd en welke wachtrij de zaak bezit in tabellen of configrecords. Dan blijft de workflow stabiel terwijl het bedrijf cijfers en routeering bijstelt.
Plan vroeg een eenvoudige dashboardweergave. Je hebt geen groot analytics-systeem nodig, gewoon een gedeeld beeld van wat er nu gebeurt: on track, warning, breached, escalated.
Als je dit bouwt in een no-code workflow-app, helpt het om een platform te kiezen dat data modelleren, logica en geplande evaluators op één plek toestaat. Bijvoorbeeld, AppMaster (appmaster.io) ondersteunt databasemodellering, visuele bedrijfsprocessen en het genereren van productieklare apps, wat goed past bij het patroon “events, evaluator, actions”.
Verfijn veilig door iteratief te werk te gaan in deze volgorde:
Wanneer je er klaar voor bent, bouw eerst een kleine versie en groei daarna met echte feedback en echte tickets.
Begin met een duidelijke definitie van de belofte die je meet, zoals first response of resolution, en schrijf precies op wat start, stopt en pauzeert. Centraliseer vervolgens de tijdsberekeningen in één evaluator die expliciete SLA-staten instelt in plaats van overal “if now > X”-checks te verspreiden.
Een timer is de klok die je start of inplant na een gebeurtenis, zoals een ticket dat naar een nieuwe status gaat. Een escalatie is de actie die je neemt als een drempel wordt bereikt, bijvoorbeeld het informeren van een lead of het veranderen van prioriteit. Een breach is het vastgelegde feit dat de SLA is gemist, waarmee je later kunt rapporteren.
First response meet de tijd tot de eerste betekenisvolle menselijke reactie, terwijl resolution de tijd meet tot het probleem echt gesloten is. Ze gedragen zich anders rond pauzes en heropeningen, dus ze apart modelleren houdt je regels eenvoudiger en je rapportage nauwkeurig.
Gebruik standaard kalender tijd (24/7) omdat dat het eenvoudigst en het gemakkelijkst te debuggen is. Voeg alleen working-time regels toe als je ze echt nodig hebt, want kantooruren introduceren extra complexiteit zoals feestdagen, tijdzones en gedeeltelijke dagen.
Modelleer pauzes als expliciete statussen gekoppeld aan specifieke statussen, zoals Waiting on Customer, en sla op wanneer de pauze begon en eindigde. Bij hervatten ga je verder met de resterende tijd of bereken je de due-tijd opnieuw op één plek—laat willekeurige statuswissels de klok niet resetten.
Een enkele boolean breached = true/false verbergt belangrijke context, zoals welke SLA het betreft, of deze gepauzeerd is en of er al geëscaleerd is. Expliciete staten zoals On track, Warning, Breached, Paused en Completed maken het systeem voorspelbaar en makkelijker te auditen en te wijzigen.
Bewaar tijdstempels die de staat verklaren, zoals started_at, due_at, breached_at en pauveervelden zoals paused_at en paused_reason. Sla ook escalatietracking op zoals last_escalation_level zodat je niet dezelfde laag twee keer op de hoogte brengt.
Maak een kleine ladder die begint bij degene die kan handelen, dan naar een lead escaleert en alleen naar een manager gaat als het echt nodig is. Bewaar drempels en ontvangers als data (bijv. in een beleidstabel) zodat het aanpassen van escalatietiming geen aanpassing van meerdere workflows vereist.
Koppel notificaties aan statusovergangen zoals OK -> Warning of Warning -> Breached, niet aan 'nog steeds te laat'-checks. Voeg eenvoudige guardrails toe zoals cooldowns en stopcondities zodat je één bericht per stap verstuurt in plaats van herhaalde meldingen bij elke run.
Gebruik het patroon events, een enkele evaluator en acties: events leggen feiten vast, de evaluator berekent deadlines en zet de SLA-staat, en acties reageren alleen op statuswijzigingen. In AppMaster kun je data modelleren, de evaluator als visueel bedrijfsproces bouwen en notificaties of toewijzingen triggeren vanuit die statusupdates, terwijl de tijdslogica gecentraliseerd blijft.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


