App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
Leer welke operationele dashboard-metrics inzicht geven in doorvoer, backlog en SLA. Kies wat je meet, hoe je aggregeert en welke grafieken actie stimuleren.
Een operationeel dashboard is geen muur vol grafieken. Het is een gedeelde weergave die een team helpt sneller dezelfde beslissingen te nemen, zonder te discussiëren over wiens cijfers “kloppen”. Als het niet verandert wat iemand daarna doet, is het versiering.
De taak is om een kleine set herhaalde beslissingen te ondersteunen. De meeste teams komen elke week op dezelfde terug:
Verschillende mensen gebruiken hetzelfde dashboard anders. Een ploegleider aan de frontlinie kijkt er mogelijk dagelijks op om te beslissen wat vandaag aandacht krijgt. Een manager kijkt er wekelijks naar om trends te zien, bezetting te onderbouwen en verrassingen te voorkomen. Eén view bedient zelden beiden goed; je hebt meestal een lead-view en een manager-view nodig.
“Mooi ogende grafieken” falen op een eenvoudige manier: ze tonen activiteit, geen controle. Een grafiek kan indrukwekkend lijken terwijl hij verbergt dat werk zich ophoopt, veroudert en beloften mist. Het dashboard moet problemen vroeg laten zien, niet ze achteraf verklaren.
Definieer wat “goed” eruitziet voordat je visuals kiest. Voor de meeste operationele teams is goed saai:
Een klein voorbeeld: een supportteam ziet dat “tickets gesloten” stijgt en viert dat. Maar de backlog veroudert en de oudste items schuiven voorbij de SLA. Een nuttig dashboard laat die spanning direct zien, zodat de leiding nieuwe aanvragen kan pauzeren, een specialist kan herverdelen of blockers kan escaleren.
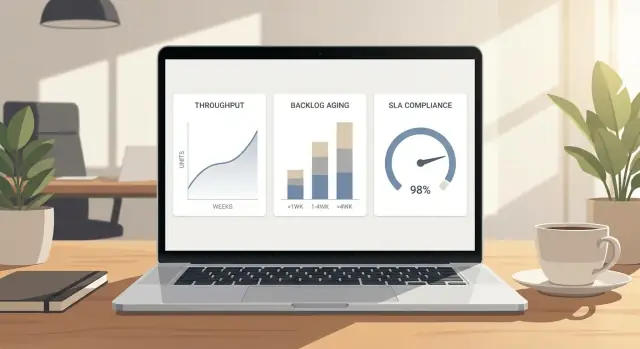
De meeste operationele dashboard-metrics vallen in drie bakken: wat je afmaakt, wat wacht, en of je je beloften nakomt.
Doorvoer is hoeveel werk in een periode op “klaar” komt. Belangrijk is dat “klaar” echt moet zijn, niet half. Voor een supportteam kan “klaar” betekenen dat het ticket is opgelost en gesloten. Voor een ops-team kan “klaar” betekenen dat het verzoek is geleverd, geverifieerd en overgedragen. Als je werk meetelt dat nog fixes nodig heeft, overschat je capaciteit en mis je problemen totdat ze pijn doen.
Backlog is het werk dat wacht om gestart of afgerond te worden. De omvang alleen is niet genoeg, want 40 nieuwe items die vandaag binnenkwamen is heel anders dan 40 items die al weken liggen te wachten. Backlog wordt bruikbaar wanneer je leeftijd toevoegt, zoals “hoe lang items hebben gewacht” of “hoeveel ouder zijn dan X dagen”. Dat vertelt of je een tijdelijke piek hebt of een groeiende blokkade.
SLA is de belofte die je doet over tijd. Het kan intern zijn (naar een ander team) of extern (naar klanten). SLA's koppelen meestal aan een paar klokken:
Deze drie metrics verbinden direct. Doorvoer is het afvoerputje. Backlog is het water in het bad. SLA is wat er met wachttijd gebeurt terwijl het bad vollopen of leegloopt. Als backlog sneller groeit dan doorvoer, zitten items langer en stijgen SLA-breaches. Als doorvoer stijgt zonder intake te veranderen, krimpt backlog en verbetert SLA.
Een simpel voorbeeld: je team sluit ongeveer 25 verzoeken per dag. Drie dagen lang stijgt de instroom naar 40 per dag na een productupdate. De backlog neemt met ongeveer 45 items toe en de oudste items beginnen je 48-uurs resolutie-SLA te overschrijden. Een goed dashboard maakt die oorzaak-en-gevolg duidelijk zodat je vroeg kunt handelen: pauzeer niet-urgente taken, stuur een specialist om, of pas tijdelijk de intake aan.
Een nuttig dashboard begint met de vragen die mensen stellen als het misgaat, niet met welke data het makkelijkst te halen is. Begin met het opschrijven van de beslissingen die het dashboard moet ondersteunen.
De meeste teams moeten deze wekelijks beantwoorden:
Beperk jezelf daarna tot 1 à 2 primaire measures per gebied. Dat houdt de pagina leesbaar en maakt “wat telt” duidelijk.
Voeg één leading indicator toe zodat je de grafiek niet verkeerd leest. Een daling in doorvoer kan betekenen dat werk langzamer gaat, maar het kan ook minder binnenkomst betekenen. Meet nieuwe aanmaken (arrivals) naast doorvoer.
Bepaal tenslotte waarop je moet segmenteren. Slices veranderen één gemiddelde in een kaart van waar te handelen. Veelvoorkomende zijn team, queue, klantniveau en prioriteit. Houd alleen slices die passen bij eigenaarschap en escalatiepaden.
Een concreet voorbeeld: als de algemene SLA goed lijkt maar je splitst op prioriteit, vind je misschien dat P1-werk twee keer zo vaak breached wordt als de rest. Dat wijst op een andere fix dan “sneller werken”: on-call dekking, onduidelijke P1-definities, of trage overdrachten tussen queues.
De meeste dashboard-discussies gaan niet over cijfers, maar over woorden. Als twee teams verschillende dingen bedoelen met “klaar” of “gebroken”, zien je metrics er precies uit en zijn toch fout.
Begin met het definiëren van de events die je meet. Schrijf ze als simpele regels die iedereen op dezelfde manier kan toepassen, ook op een drukke dag.
Kies een kleine set events en koppel elk event aan een helder systemmoment, meestal een timestamp-wijziging:
Definieer ook wat telt als gebroken voor SLA-rapportage. Gaat de SLA-klok van “created naar first response”, “created naar done”, of “started naar done”? Beslis of de klok pauzeert tijdens blokkeringen en welke blokkaderedenen meetellen.
Herwerk is waar teams per ongeluk de cijfers manipuleren. Kies één aanpak en houd je eraan.
Als een ticket heropend wordt, tel je het dan als hetzelfde item (met extra doorlooptijd) of als een nieuw item (een nieuwe created-datum)? Het als hetzelfde item tellen geeft meestal betere kwaliteitszichtbaarheid, maar kan doorvoer lager doen lijken. Het als nieuw tellen kan de echte kosten van fouten verbergen.
Een praktische tussenweg is één werkunit houden, maar een aparte “heropen-telling” en “herwerktijd” bijhouden zodat de hoofdflow eerlijk blijft.
Stem nu af wat je werkunit en statusregels zijn. Een “ticket”, “order”, “verzoek” of “taak” kan allemaal werken, maar alleen als iedereen hetzelfde bedoelt. Bijvoorbeeld: als een order splitst in drie zendingen, is dat één unit (order) of drie units (zendingen)? Doorvoer en backlog veranderen op basis van die keuze.
Documenteer de minimale velden die je systeem moet vastleggen, anders staat je dashboard vol met lege velden en gissingen:
Aggregatie is waar nuttige dashboards vaak misgaan. Je comprimeert rommelige realiteit tot een paar cijfers en vraagt je vervolgens af waarom de “goede” lijn niet klopt met wat het team elke dag voelt. Het doel is geen mooiere grafiek, maar een eerlijke samenvatting die risico blijft tonen.
Begin met tijdsbuckets die passen bij de beslissingen die je maakt. Dagelijkse weergaven helpen operators vandaag opstapelingen te zien. Wekelijkse weergaven tonen of een wijziging echt hielp. Maandelijkse rollups zijn beter voor planning en bezetting, maar kunnen korte pieken verbergen die SLA's breken.
Voor tijdsgebonden measures (doorlooptijd, tijd tot eerste reactie, tijd tot oplossing) vertrouw niet op gemiddelden. Enkele zeer lange gevallen kunnen ze vertekenen en enkele zeer korte gevallen kunnen het beter laten lijken dan het is. Mediaan en percentielen vertellen het verhaal waar teams om geven: wat typisch is (p50) en wat pijnlijk is (p90).
Een eenvoudig patroon dat werkt:
Segmentatie is de andere hendel. Eén algemene lijn is prima voor leiderschap, maar het mag niet de enige weergave zijn. Splits op één of twee dimensies die passen bij hoe werk echt stroomt, zoals queue, prioriteit, regio, product of kanaal (email, chat, telefoon). Houd het compact. Als je op vijf dimensies tegelijk splitst, krijg je kleine groepen en rumoerige grafieken.
Randgevallen zijn waar teams zichzelf per ongeluk voorliegen. Beslis vooraf hoe je gepauzeerd werk, “wacht op klant”, feestdagen en buiten-kantoorvensters behandelt. Als je SLA-klok stopt wanneer je op een klant wacht, moet je dashboard diezelfde regel weerspiegelen of je jaagt problemen na die niet echt zijn.
Een praktische aanpak is twee klokken zij-aan-zij publiceren: kalender-tijd en bedrijfstijd. Kalender-tijd is wat klanten ervaren. Bedrijfstijd is wat je team kan controleren.
Tot slot, controleer elke aggregatie met een kleine steekproef echte tickets of orders. Als de p90 er goed uitziet maar operators tien vastzittende items kunnen noemen, verbergt je groepering of klokregels de pijn.
Goede metrics doen één ding goed: ze wijzen naar wat je volgende stap moet zijn. Als een grafiek mensen laat discussiëren over definities of een cijfer laat vieren zonder gedrag te veranderen, is het waarschijnlijk uitstraling.
Een lijngrafiek voor doorvoer (werkitems afgerond per dag of week) wordt nuttiger met context. Zet een target-band op de grafiek, geen enkele doelregel, zodat mensen kunnen zien wanneer prestaties wezenlijk afwijken.
Voeg binnenkomsten (nieuwe items aangemaakt) toe op dezelfde tijdas. Als doorvoer goed lijkt maar binnenkomsten stijgen, zie je het moment dat het systeem achterop begint te raken.
Houd het leesbaar:
Een enkele backlog-telling verbergt het echte probleem: oud werk. Gebruik aging-buckets die passen bij wanneer je team pijn voelt. Een veelgebruikte set is 0-2 dagen, 3-7, 8-14, 15+.
Een gestapelde balk per week werkt goed omdat het laat zien of de backlog ouder wordt, zelfs als het totale volume stabiel blijft. Als het segment 15+ optrekt, heb je een prioriterings- of capaciteitsprobleem, niet “gewoon een drukke week”.
SLA-naleving in de tijd (wekelijks of maandelijks) beantwoordt de vraag “Houden we de belofte?” Maar het zegt niet wat je vandaag moet doen.
Koppel het aan een breach-queue: het aantal open items dat binnen de SLA-venster zit maar bijna breached. Bijvoorbeeld, toon “items die binnen 24 uur vervallen” en “al gebroken” als twee kleine tellers naast de trend. Dat verandert een abstract percentage in een dagelijkse actielijst.
Een praktisch scenario: na een nieuwe productlancering stijgt de instroom. Doorvoer blijft stabiel, maar backlog-aging groeit in de 8-14 en 15+ buckets. Tegelijkertijd springt de breach-queue omhoog. Je kunt direct handelen: werk herverdelen, intake versmallen of on-call dekking aanpassen.
Een dashboard-spec moet op twee pagina's passen: één pagina voor wat mensen zien, één pagina voor hoe de cijfers worden berekend. Als het langer is, probeert het meestal te veel problemen tegelijk op te lossen.
Schets de layout eerst op papier. Schrijf voor elk paneel één dagelijkse vraag die het moet beantwoorden. Als je de vraag niet in één zin kunt formuleren, verandert de grafiek in een “leuk om naar te kijken” metric.
Een eenvoudige structuur die bruikbaar blijft:
Vervolgens definieer je elke metric in één zin en lijst je de velden die je nodig hebt om hem te berekenen. Houd formules expliciet, zoals: “Doorlooptijd is closed_at minus started_at, gemeten in uren, exclusief items in Waiting-status.” Schrijf de exacte statuswaarden, datumvelden en welke tabel of systeem de bron van de waarheid is.
Voeg drempels en alerts toe terwijl je nog schrijft, niet na de lancering. Een grafiek zonder actie is slechts een rapport. Voor elke drempel specificeer je:
Plan drill-downpaden zodat mensen in onder een minuut van trend naar oorzaak komen. Een praktisch flow is: trendlijn (week) -> queue-weergave (vandaag) -> itemlijst (top-overtreders) -> itemdetail (geschiedenis en eigenaar). Als je niet kunt doorklikken naar individuele items, krijg je argumenten in plaats van oplossingen.
Voordat je uitrolt, valideer met drie echte weken historische data. Kies één rustige week en één rommelige week. Controleer of totalen overeenkomen met bekende uitkomsten en steek 10 items end-to-end na om timestamps, statusovergangen en uitsluitingen te bevestigen.
Een supportteam rolt een grote productupdate uit op maandag. Op woensdag beginnen klanten dezelfde “hoe doe ik…” vraag te stellen, plus enkele nieuwe bugmeldingen. Het team voelt zich drukker, maar niemand kan zeggen of dit een tijdelijke piek of een SLA-ramp is.
Hun dashboard is simpel: één view per queue (Billing, Bugs, How-to). Het volgt binnenkomsten (nieuwe tickets), doorvoer (opgeloste tickets), backloggrootte, backlog-aging en SLA-risico (hoeveel tickets waarschijnlijk zullen breachen op basis van leeftijd en resterende tijd).
Na de update tonen de metrics:
Dit lijkt geen algemeen prestatieprobleem. Het ziet eruit als een routing- en focusprobleem. Het dashboard maakt drie reële beslissingen duidelijk:
Ze kiezen een mix: één extra agent op “How-to” tijdens piekuren, plus een standaardantwoord en een klein helpartikel.
De volgende dag checken ze opnieuw. Doorvoer is niet dramatisch hoger, maar de belangrijke signalen bewegen in de juiste richting. Backlog-aging stopt met stijgen en begint te dalen. De SLA-risicografiek daalt eerst, daarna nemen daadwerkelijke breaches later af. Binnenkomsten naar “How-to” beginnen te dalen, waarmee bevestigd wordt dat de oorzaakfix helpt.
Een dashboard moet je helpen beslissen wat je volgende stap is, niet gisteren mooier laten lijken. Veel teams eindigen met drukke grafieken die risico verbergen.
De klassieke is “tickets gesloten deze week” alleen getoond. Het kan stijgen terwijl het werk slechter wordt, omdat het binnenkomsten, heropeningen en veroudering negeert.
Let op deze patronen:
Een simpele fix: koppel elk outputnummer aan een vraagnummer en een tijdsnummer. Bijvoorbeeld gesloten versus aangemaakt, plus mediaan doorlooptijd.
Gemiddelde oplostijd is een snelle manier om klantpijn te missen. Eén vastzittende zaak van 20 dagen kan onzichtbaar blijven als het gemiddelde omlaag wordt getrokken door veel snelle oplossingen.
Gebruik medianen en percentielen (zoals p75 of p90) naast een aging-weergave. Als je maar één kunt kiezen, kies mediaan. Voeg dan een klein tabeltje “slechtste 10 open items op leeftijd” toe zodat de lange staart zichtbaar blijft.
Als Team A “klaar” telt als “eerste reactie verstuurd” en Team B “klaar” telt als “volledig opgelost”, ontstaan er discussies in plaats van beslissingen. Schrijf definities in eenvoudige woorden en houd ze consistent: wat start de klok, wat stopt hem en welke statussen pauzeren hem.
Een realistisch voorbeeld: support verandert een status van “Wacht op klant” naar “On hold”, maar engineering gebruikt die status nooit. SLA-tijd pauzeert voor de ene groep en niet voor de andere, zodat leiding “SLA verbetert” ziet terwijl klanten langzamer oplossingen krijgen.
Filters helpen, maar een dashboard met 12 filters en 20 grafieken wordt een choose-your-own-adventure. Kies een duidelijke standaardweergave (laatste 6-8 weken, alle klanten, alle kanalen) en maak uitzonderingen intentioneel.
Ontbrekende tijdstempels, nabewerkte statuswijzigingen en inconsistente statusnamen vergiftigen resultaten. Valideer eerst of sleutelvelden aanwezig en correct geordend zijn voordat je meer grafieken bouwt.
Voordat je het “klaar” noemt, controleer of het dashboard echte vragen beantwoordt op een drukke maandagmorgen. Goede operationele dashboard-metrics helpen risico vroeg te zien, verklaren wat veranderde en beslissen wat te doen.
Een korte one-screen check:
Als een antwoord “nee” is, doe dan eerst een kleine verbetering. Vaak is het zo simpel als het toevoegen van een vergelijking met vorige week, het splitsen van één view op prioriteit, of het tonen van een 7-daagse rollende weergave naast de wekelijkse totalen. Als je één verbetering moet kiezen, kies dan die welke verrassingen voorkomt: backlog-aging per prioriteit, of een SLA-countdown-weergave.
Zet de checklist om in een kort spec dat iemand kan implementeren zonder te gissen. Houd het compact en focus op definities en beslissingregels.
Als je snel wilt prototypen voor de volledige workflow (datamodel, businessregels en webdashboard-UI), is AppMaster (appmaster.io) gemaakt om complete applicaties te creëren zonder handmatig coderen, terwijl er toch echte broncode achter de schermen wordt gegenereerd. Het belangrijkste is klein te beginnen, uit te leveren en alleen metrics toe te voegen die hun plek verdienen doordat ze een beslissing veranderen.
Begin met de terugkerende beslissingen die je team neemt (bezetting, prioriteit, escalatie en procesverbeteringen) en kies dan de weinige maatregelen die die beslissingen direct ondersteunen. Als een metric niet verandert wat iemand daarna doet, laat hem dan weg.
Houd drie kernsignalen samen bij: doorvoer (wat echt ‘klaar’ is), backlog met aging (wat wacht en hoe lang) en SLA-prestaties (of beloften worden nagekomen). De meeste “we zijn ok” dashboards falen omdat ze activiteit tonen zonder risico zichtbaar te maken.
Definieer “klaar” als het moment waarop werk aan je acceptatie-eis voldoet, niet een tussenstatus zoals “ter beoordeling verzonden” of “wacht op iemand anders”. Als “klaar” niet consistent is, ziet doorvoer er beter uit dan de realiteit en mis je capaciteitsproblemen totdat SLA's verslechteren.
De grootte van de backlog alleen kan misleiden omdat nieuw werk en oud werk heel verschillend aanvoelen. Voeg minstens één leeftijdssignaal toe, zoals “hoeveel items ouder zijn dan X dagen”, zodat je kunt zien of het een tijdelijke piek of een groeiende blokkade is.
SLA is de tijdbelofte die je maakt, meestal gekoppeld aan eerste reactie, oplossing of tijd in belangrijke statussen. Kies één duidelijke klok per belofte en documenteer wanneer deze start, wanneer hij stopt en of hij pauzeert bij geblokkeerde of wachtende statussen.
Zet binnenkomsten (nieuwe items aangemaakt) naast doorvoer op dezelfde tijdsas. Een daling in doorvoer kan betekenen dat werk langzamer gaat, maar ook dat er minder binnenkomt; beide zien voorkomt verkeerde conclusies.
Gebruik medianen en percentielen (zoals p50 en p90) voor tijdsgebonden metrics omdat gemiddelden vervormd raken door enkele extreme gevallen. Dit houdt de lange staart zichtbaar, waar de meeste klantpijn en escalatie vandaan komt.
Bepaal vooraf of een heropend item hetzelfde werk blijft of als nieuw telt, en houd je daaraan. Een veelgebruikte standaard is het als hetzelfde item houden voor eerlijkheid, en tegelijkertijd het aantal heropeningen of herwerktijd bijhouden zodat kwaliteitsproblemen niet verdwijnen.
Aggregatie verbergt problemen wanneer je buckets niet passen bij de beslissingen of wanneer je teveel samenvat. Gebruik dagelijkse weergaven voor de controle van vandaag, wekelijks voor trendchecks en alleen maandelijks voor planning; controleer vervolgens resultaten aan de hand van een kleine steekproef van echte items.
Maak een korte specificatie met één pagina voor wat gebruikers zien en één pagina voor hoe metrics worden berekend, inclusief exacte status- en tijdstempelregels. Als je snel wilt prototypen kan AppMaster (appmaster.io) helpen modellen te bouwen, business rules te implementeren en een webdashboard-UI te maken zonder handmatig coderen, terwijl er toch echte broncode wordt gegenereerd.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


