App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
Langlopende workflows kunnen op ingewikkelde manieren falen. Leer duidelijke statusepatronen, retry-tellers, dead-letter-afhandeling en dashboards waarop operators kunnen vertrouwen.
Langlopende workflows falen anders dan korte verzoeken. Een korte API-aanroep slaagt of faalt meteen. Een workflow die uren of dagen draait kan 9 van de 10 stappen halen en toch een rommel achterlaten: half-aangemaakte records, verwarrende status en geen duidelijke volgende stap.
Daarom hoor je zo vaak “het werkte gisteren nog”. De workflow is niet veranderd, maar de omgeving wel. Langlopende workflows zijn afhankelijk van andere services die gezond blijven, inloggegevens die geldig blijven en data die in de verwachte vorm blijft.
De meest voorkomende faalpatronen zien er zo uit: timeouts en trage afhankelijkheden (een partner-API is beschikbaar maar doet er vandaag 40 seconden over), gedeeltelijke updates (record A gemaakt, record B niet, en je kunt niet veilig opnieuw draaien), uitval van afhankelijkheden (e-mail/SMS-providers, betaalpoorten, onderhoudsvensters), verloren callbacks en gemiste schema's (een webhook komt nooit aan, een timerjob werd niet uitgevoerd), en menselijke stappen die stagneren (een goedkeuring blijft dagen liggen en hervat daarna met verouderde aannames).
Het lastige is state. Een “kort verzoek” kan state in het geheugen houden totdat het klaar is. Een workflow kan dat niet. Hij moet state persistent bewaren tussen stappen en klaar zijn om verder te gaan na herstarts, deploys of crashes. Hij moet ook omgaan met dezelfde stap die tweemaal wordt geactiveerd (retries, dubbele webhooks, operator replays).
In de praktijk gaat “betrouwbaar” minder om nooit falen en meer om voorspelbaar, uitlegbaar, herstelbaar en duidelijk eigendom zijn.
Voorspelbaar betekent dat de workflow steeds hetzelfde doet als een afhankelijkheid faalt. Uitlegbaar betekent dat een operator binnen een minuut kan antwoorden: “Waar zit het vast en waarom?” Herstelbaar betekent dat je veilig kunt herhalen of doorgaan zonder schade aan te richten. Duidelijk eigenaarschap betekent dat elk vastgelopen item een voor de hand liggende volgende actie heeft: wachten, opnieuw proberen, data herstellen of overdragen aan een persoon.
Een simpel voorbeeld: een onboarding-automatisering maakt een klantrecord, regelt toegang en stuurt een welkomstbericht. Als het provisionen lukt maar het bericht sturen faalt omdat de e-mailprovider down is, registreert een betrouwbare workflow “Geprovisioneerd, bericht in afwachting” en plant een retry. Hij voert provisioning niet blind opnieuw uit.
Tools kunnen dit makkelijker maken door workflowlogica en persistente data dicht bij elkaar te houden. Bijvoorbeeld, AppMaster laat je workflowstate modelleren in je data (via de Data Designer) en bijwerken vanuit visuele Business Processes. Maar betrouwbaarheid komt van het patroon, niet van het gereedschap: behandel langlopende automatisering als een reeks duurzame staten die tijd, falen en menselijke tussenkomst kunnen overleven.
Langlopende workflows falen vaak op repeteerbare manieren: een externe API wordt traag, een mens heeft niet goedgekeurd of een taak wacht in een wachtrij. Duidelijke staten maken die situaties direct zichtbaar, zodat mensen “neemt tijd” niet met “kapot” verwarren.
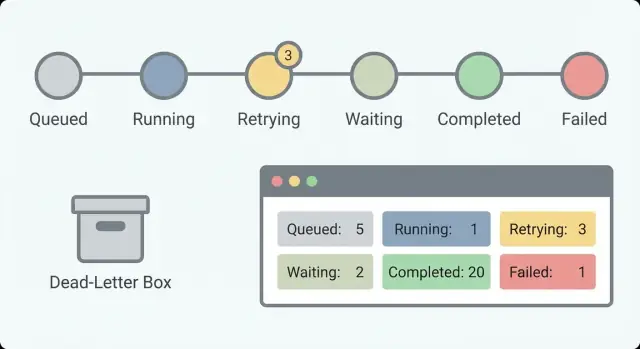
Begin met een kleine set staten die één vraag beantwoorden: wat gebeurt er nu? Als je 30 staten hebt, herinnert niemand ze zich. Met ongeveer 5 tot 8 kan een on-call persoon een lijst scannen en het begrijpen.
Een praktische set staten die voor veel workflows werkt:
Queued (aangemaakt maar nog niet gestart)Running (actief bezig)Waiting (gepauzeerd op een timer, callback of menselijke input)Succeeded (klaar)Failed (gestopt met een fout)Het scheiden van Waiting en Running is belangrijk. “Wachten op klantantwoord” is gezond. “Al 6 uur aan het draaien” kan vastlopen zijn. Zonder deze scheiding jaag je valse alarmen na en mis je echte.
Een statennaam alleen is niet genoeg. Voeg een paar velden toe die een status actiegericht maken:
Voorbeeld: een onboarding-flow kan “Waiting” tonen met de reden “In afwachting van managergoedkeuring” en laatst gewijzigd “2 dagen geleden.” Dat vertelt je dat het niet vastzit, maar mogelijk een herinnering nodig heeft.
Behandel staten als een API. Als je ze elke maand hernoemt, worden dashboards, alerts en support-playbooks snel misleidend. Als je nieuwe betekenis nodig hebt, overweeg dan een nieuwe staat in te voeren en laat de oude bestaan voor bestaande records.
In AppMaster kun je deze staten modelleren in de Data Designer en bijwerken vanuit Business Process-logica. Dat houdt status zichtbaar en consistent in je app in plaats van verstopt in logs.
Retries helpen tot ze het echte probleem verbergen. Het doel is niet “nooit falen.” Het doel is “falen op een manier die mensen kunnen begrijpen en repareren.” Dat begint met een duidelijke regel voor wat retrybaar is en wat niet.
Een regel waar de meeste teams mee kunnen leven: herhaal fouten die waarschijnlijk tijdelijk zijn (netwerktimeouts, rate limits, korte storingen bij derden). Herhaal geen fouten die duidelijk permanent zijn (ongeldige invoer, ontbrekende rechten, “account gesloten”, “kaart geweigerd”). Als je niet kunt bepalen in welke groep een fout valt, behandel het dan als niet-retrybaar totdat je meer weet.
Houd retry-tellers per stap (of per externe oproep) bij, niet slechts één teller voor de hele workflow. Een workflow kan tien stappen bevatten en slechts één kan onstabiel zijn. Stapniveau-tellers voorkomen dat een latere stap pogingen “steelt” van een eerdere.
Bijvoorbeeld: een “Upload document”-oproep kan een paar keer herhaald worden, terwijl “Stuur welkomstmail” niet eeuwig door moet blijven proberen omdat de upload eerder pogingen heeft opgebruikt.
Kies een backoff-patroon dat bij het risico past. Vaste vertragingen zijn prima voor eenvoudige, goedkope retries. Exponentiële backoff helpt wanneer je tegen rate limits aanloopt. Voeg een cap toe zodat wachttijden niet onbeperkt groeien, en een beetje jitter om retry-stormen te voorkomen.
Bepaal daarna wanneer te stoppen. Goede stopcondities zijn expliciet: maximaal aantal pogingen, maximale totale tijd of “opgeven voor bepaalde foutcodes.” Een betaalpoort die “ongeldige kaart” teruggeeft moet onmiddellijk stoppen, zelfs als je normaal vijf pogingen toestaat.
Operators moeten ook weten wat er daarna gebeurt. Registreer de volgende retry-tijd en de reden (bijvoorbeeld: “Retry 3/5 om 14:32 vanwege timeout”). In AppMaster kun je dat op het workflowrecord bewaren zodat een dashboard “wacht tot” kan tonen zonder te gissen.
Een goed retry-beleid laat een spoor achter: wat faalde, hoe vaak geprobeerd, wanneer het opnieuw probeert en wanneer het stopt en wordt doorgestuurd naar dead-letter-afhandeling.
Bij workflows die uren of dagen draaien zijn retries normaal. Het risico is een stap herhalen die al succesvol was. Idempotentie is de regel die dit veilig maakt: een stap is idempotent als tweemaal uitvoeren hetzelfde effect heeft als eenmaal uitvoeren.
Een klassiek probleem: je regelt een betaling, maar de workflow crasht voordat “betaling geslaagd” is opgeslagen. Bij retry wordt er weer gechargeerd. Dat is een dubbel-schrijfprobleem: de buitenwereld veranderde, maar je workflowstate niet.
Het veiligste patroon is een stabiele idempotentiesleutel voor elke bijwerking stap te maken, deze mee te sturen met de externe oproep en het stapresultaat meteen op te slaan als je het terugkrijgt. Veel betaalproviders en webhook-ontvangers ondersteunen idempotentiesleutels (bijvoorbeeld een order via OrderID belasten). Als de stap herhaald wordt, levert de provider het originele resultaat terug in plaats van de actie opnieuw uit te voeren.
Binnen je workflow-engine moet je ervan uitgaan dat elke stap kan worden herhaald. In AppMaster betekent dat vaak het opslaan van stapoutputs in je databasemodel en deze controleren in je Business Process voordat je nogmaals een integratie aanroept. Als “Stuur welkomstmail” al een MessageID heeft, moet een retry dat record hergebruiken en verdergaan.
Een praktisch duplicaat-veilig aanpak:
Duplicaten blijven voorkomen, vooral bij inkomende webhooks of wanneer een gebruiker tweemaal op dezelfde knop drukt. Bepaal per gebeurtenistype: negeer exacte duplicaten (zelfde idempotentiesleutel), fuseer compatibele updates (zoals last-write-wins voor een profielveld) of markeer voor review wanneer geld of compliance-risico betrokken is.
Een dead-letter is een workflow-item dat faalde en uit het normale pad is verplaatst zodat het niet alles blokkeert. Je bewaart het met opzet. Het doel is het gemakkelijk te maken te begrijpen wat er gebeurde, beslissen of het repareerbaar is en het veilig opnieuw verwerken.
De grootste fout is alleen een foutmelding opslaan. Als iemand later naar het dead-letter kijkt, heeft diegene genoeg context nodig om het probleem te reproduceren zonder te gokken.
Een nuttige dead-letter entry bevat:
Classificatie maakt dead letters actiegericht. Een korte categorie helpt operators de juiste volgende stap te kiezen. Veelvoorkomende groepen zijn permanent error (logische regel, ongeldige staat), data-issue (ontbrekend veld, verkeerd formaat), dependency down (timeout, rate limit, outage) en auth/permission (verlopen token, geweigerde credentials).
Herverwerking moet gecontroleerd zijn. Het doel is herhaalde schade te vermijden, zoals dubbel incasseren of spam versturen. Definieer regels wie mag retryen, wanneer te retryen, wat mag worden aangepast (specifieke velden bewerken, ontbrekend document bijvoegen, token verversen) en wat vast moet blijven (request ID en downstream idempotentiesleutels).
Maak dead-letter items doorzoekbaar op stabiele identifiers. Als een operator “order 18422” kan typen en de exacte stap, inputs en pogingengeschiedenis ziet, worden fixes snel en consistent.
Als je dit in AppMaster bouwt, behandel het dead-letter als een eersteklas databasemodel en bewaar state, pogingen en identifiers als velden. Zo kan je interne dashboard query's, filters en gecontroleerde herverwerkingsacties triggeren.
Langlopende workflows kunnen op trage, verwarrende manieren falen: een stap wacht op een e-mailantwoord, een betaalprovider time-outt of een webhook komt twee keer aan. Als je niet kunt zien wat de workflow op dit moment doet, ga je gokken. Goede zichtbaarheid verandert “het is kapot” in een helder antwoord: welke workflow, welke stap, welke staat en wat je daarna kunt doen.
Begin met ervoor te zorgen dat elke stap hetzelfde kleine setje velden uitzendt zodat operators snel kunnen scannen:
Die velden ondersteunen basiscounters die in één oogopslag gezondheid tonen. Voor langlopende workflows tellen aantallen meer dan individuele fouten omdat je op trends let: werk stapelt zich op, retries pieken of wachttijden die nooit eindigen.
Volg gestart, voltooid, gefaald, aan het retryen en in afwachting in de tijd. Een kleine wachtende waarde kan normaal zijn (menselijke goedkeuringen). Een stijgend aantal in wacht wijst meestal op iets dat geblokkeerd is. Een stijgend retry-aantal duidt vaak op een providerprobleem of een bug die steeds dezelfde fout raakt.
Alerts moeten overeenkomen met wat operators ervaren. In plaats van “er trad een fout op”, alert op symptomen: een groeiende achterstand (gestart minus voltooid blijft stijgen), te veel workflows die langer dan verwacht in waiting zitten, hoge retry-rate voor een specifieke stap of een foutpiek direct na een release of config-wijziging.
Houd een gebeurtenis-trail voor elke workflow zodat “wat gebeurde er?” in één weergave beantwoord kan worden. Een nuttige trail bevat tijdstempels, statustransities, samenvattingen van inputs en outputs (geen volledige gevoelige payloads) en de reden voor retries of falen. Voorbeeld: “Charge card: retry 3/5, timeout van provider, volgende poging over 10m.”
Correlatie-ID's zijn de lijm. Als een klant zegt “mijn betaling is twee keer afgeschreven”, moet je je workflowevents koppelen aan de charge-ID van de betaalprovider en je interne order-ID. In AppMaster kun je dit standaardiseren in Business Process-logica door correlatie-ID's te genereren en mee te geven in API-oproepen en messaging-stappen zodat dashboard en logs overeenkomen.
Als een workflow uren of dagen draait, zijn fouten normaal. Wat normale fouten tot echte storingen maakt is een dashboard dat alleen “Failed” zegt en verder niets. Het doel is dat een operator snel drie vragen kan beantwoorden: wat gebeurt er, waarom gebeurt het en wat kunnen ze veilig doen als volgende stap.
Begin met een workflowlijst die het makkelijk maakt de paar items te vinden die er toe doen. Filters verminderen paniek en chat-ruis omdat iedereen snel het zicht kan vernauwen.
Nuttige filters zijn staat, leeftijd (starttijd en tijd in huidige staat), eigenaar (team/klant/verantwoordelijke operator), type (workflownaam/versie) en prioriteit als je klantgerichte stappen hebt.
Toon vervolgens de “waarom” naast de status in plaats van in logs te verbergen. Een status-pil helpt alleen als die gepaard gaat met de laatste foutmelding, een korte foutcategorie en wat het systeem daarna van plan is. Twee velden doen het meeste werk: laatste fout en volgende retry-tijd. Als volgende retry leeg is, maak dan duidelijk of de workflow op een mens wacht, gepauzeerd is of permanent gefaald.
Operatoracties moeten standaard veilig zijn. Leid mensen naar laag-risico acties eerst en maak risicovolle acties expliciet:
“Force continue” is waar de meeste schade gebeurt. Als je het aanbiedt, beschrijf het risico in eenvoudige taal: “Dit slaat betalingverificatie over en kan een onbetaalde bestelling creëren.” Laat ook zien welke data geschreven wordt als het doorgaat.
Log alles wat operators doen. Registreer wie het deed, wanneer, de voor/na staat en de redenopmerking. Als je interne tools in AppMaster bouwt, bewaar dit auditspoor als eersteklas tabel en toon het op de workflow-detailpagina zodat overdrachten netjes blijven.
Dit patroon houdt workflows voorspelbaar: elk item bevindt zich altijd in een duidelijke staat, elke fout heeft een plek om naartoe te gaan en operators kunnen veilig handelen zonder te gissen.
Stap 1: Definieer staten en toegestane transities. Schrijf een kleine set staten op die een persoon kan begrijpen (bijv. Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter). Bepaal vervolgens welke bewegingen legaal zijn zodat werk niet in limbo raakt.
Stap 2: Breek werk op in kleine stappen met duidelijke inputs en outputs. Elke stap moet één goed gedefinieerde input accepteren en één output (of een duidelijke fout) produceren. Als je een menselijke beslissing of een externe API-aanroep nodig hebt, maak er dan een aparte stap van zodat die kan pauzeren en netjes hervatten.
Stap 3: Voeg een retrybeleid per stap toe. Kies een maximum aantal pogingen, een vertraging tussen pogingen en stopredenen die nooit moeten retryen (ongeldige data, toestemming geweigerd, ontbrekende verplichte velden). Bewaar een retry-teller per stap zodat operators precies zien wat vastzit.
Stap 4: Persistentie van voortgang na elke stap. Nadat een stap klaar is, sla je de nieuwe staat en kernoutputs op. Als het proces herstart, moet het doorgaan vanaf de laatst voltooide stap, niet opnieuw beginnen.
Stap 5: Routeer naar een dead-letter record en ondersteun herverwerking. Wanneer retries zijn uitgeput, zet je het item naar dead-letter en bewaar je volledige context: inputs, laatste fout, stapnaam, pogingenteller en tijdstempels. Herverwerking moet doelbewust zijn: repareer data of config eerst en herstart dan vanaf een specifieke stap.
Stap 6: Definieer dashboardvelden en operatoracties. Een goed dashboard antwoordt op “wat faalde, waar en wat kan ik nu doen?” In AppMaster kun je dit bouwen als een eenvoudige admin webapp die wordt gevoed door je workflowtabellen.
Belangrijke velden en acties om op te nemen:
Employee-onboarding is een goede stresstest. Het mengt goedkeuringen, externe systemen en mensen die offline zijn. Een eenvoudige flow kan zijn: HR vult een nieuw-aanstelling formulier in, de manager keurt goed, IT-accounts worden aangemaakt en de nieuwe medewerker krijgt een welkomstbericht.
Maak staten leesbaar. Als iemand het record opent, moet direct het verschil zichtbaar zijn tussen “Wachten op goedkeuring” en “Bezig met account provisioning en probeert opnieuw”. Eén heldere regel kan een uur aan giswerk besparen.
Een duidelijke set staten om in de UI te tonen:
Retries horen bij stappen die afhankelijk zijn van netwerk of externe API's. Accountprovisioning (e-mail, SSO, Slack), het versturen van e-mail/SMS en interne API-calls zijn goede retry-kandidaten. Houd de retry-teller zichtbaar en cap het (bijv. tot vijf pogingen met oplopende vertragingen, daarna stoppen).
Dead-letter afhandeling is voor problemen die zichzelf niet herstellen: geen manager op het formulier, ongeldig e-mailadres of een toegangsaanvraag die conflicteert met beleid. Als je een run dead-letter zet, bewaar context: welk veld faalde validatie, de laatste API-respons en wie een override kan goedkeuren.
Operators moeten een klein setje eenvoudige acties hebben: repareer de data (manager toevoegen, e-mail corrigeren), voer één foutieve stap opnieuw uit (niet de hele workflow), of annuleer netjes (en maak gedeeltelijke setup ongedaan indien nodig).
Met AppMaster kun je dit in de Business Process Editor modelleren, retry-tellers in data bewaren en een operator-scherm bouwen in de web UI builder dat staat, laatste fout en een knop om de gefaalde stap opnieuw te proberen toont.
De meeste betrouwbaarheidsproblemen zijn voorspelbaar: een stap draait twee keer, retries draaien om 02:00, of een “vast” item heeft geen idee wat er de laatste keer gebeurde. Een checklist voorkomt dat het giswerk wordt.
Snelle controles die de meeste problemen vroeg vangen:
Als je maar één ding kunt verbeteren, verbeter dan zichtbaarheid. Veel “workflowbugs” zijn eigenlijk “we kunnen niet zien wat het doet”-problemen. Je dashboard moet tonen wat er laatst gebeurde, wat er daarna gebeurt en wanneer.
Een praktische operator-weergave bevat de huidige staat, laatste foutmelding, pogingenteller, volgende retry-tijd en één duidelijke actie (nu opnieuw proberen, markeer opgelost of stuur naar handmatige review). Houd acties standaard veilig: voer één stap opnieuw uit, niet de hele workflow.
Volgende stappen:
Behandel dit als een levendige checklist. Elke keer dat je een nieuwe stap toevoegt, loop deze controles door voordat het in productie gaat.
Langlopende workflows kunnen uren goed lopen en pas tegen het einde falen, waarbij ze gedeeltelijke wijzigingen achterlaten. Ze zijn bovendien afhankelijk van zaken die kunnen veranderen tijdens hun uitvoering, zoals de beschikbaarheid van derden, geldigheid van inloggegevens, de vorm van data en reactietijden van mensen.
Houd de set staten klein en leesbaar zodat een operator het direct kan begrijpen. Een solide standaard is iets als queued, running, waiting, succeeded en failed, waarbij “waiting” duidelijk gescheiden is van “running” zodat je gezonde pauzes kunt onderscheiden van vastlopen.
Sla genoeg op om de status actiegericht te maken: de huidige staat, wanneer die voor het laatst veranderde, wat de vorige staat was en een korte reden wanneer het wachten of falen is. Als je retries gebruikt, bewaar dan ook een pogingteller en de volgende geplande retry-tijd zodat mensen niet hoeven te raden wat er gaat gebeuren.
Het voorkomt valse alarmen en gemiste incidenten. “Wachten op goedkeuring” of “wachten op een webhook” kan volkomen gezond zijn, terwijl “draait al zes uur” kan duiden op vastlopen. Door ze apart te houden verbeter je zowel alerts als operatorbeslissingen.
Herhaal fouten die waarschijnlijk tijdelijk zijn, zoals timeouts, rate limits en korte storingen. Herhaal geen fouten die duidelijk permanent zijn, zoals ongeldige invoer, ontbrekende rechten of geweigerde betalingen — herhaalde pogingen verspillen tijd en kunnen bijwerkingen veroorzaken.
Retry's per stap voorkomen dat één onstabiele integratie alle pogingen van de hele workflow opslokt. Ze maken diagnose ook eenvoudiger, omdat je precies ziet welke stap faalt, hoe vaak die is geprobeerd en of andere stappen onaangetast zijn.
Gebruik een eenvoudige backoff die bij het risico past en cap het altijd zodat wachttijden niet onbeperkt groeien. Maak stopregels expliciet, zoals een maximaal aantal pogingen of een maximale totale tijd, en registreer zowel de faalreden als de volgende geplande retry zodat eigenaarschap helder is.
Ga ervan uit dat elke stap twee keer kan draaien door retries, herhalingen of dubbele webhooks, en ontwerp hem zo dat herhalen geen schade toebrengt. Een gangbare aanpak is een stabiele idempotentiesleutel per zij-effect stap te gebruiken, “stap gestart” te schrijven vóór de externe oproep en het externe resultaat meteen op te slaan zodat herhalingen dat kunnen hergebruiken.
Een dead-letter-item is iets dat je na uitgeputte retries uit het normale pad haalt zodat het de rest niet blokkeert. Bewaar genoeg context om het later te repareren en veilig opnieuw te verwerken, inclusief identifiers, inputs (of een veilige snapshot), waar het faalde, pogingengeschiedenis en de foutrespons van de afhankelijkheid — niet alleen een vage foutmelding.
De meest bruikbare dashboards laten zien waar het staat, waarom het daar is en wat er daarna gebeurt, met consistente velden zoals workflow-ID, huidige stap, staat, tijd in staat, laatste fout en correlatie-ID's. Operators moeten standaard veilige acties krijgen, zoals het opnieuw proberen van één stap of pauzeren/hervatten, en risicovolle acties duidelijk gelabeld zodat je geen extra schade aanricht tijdens het oplossen.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


