App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
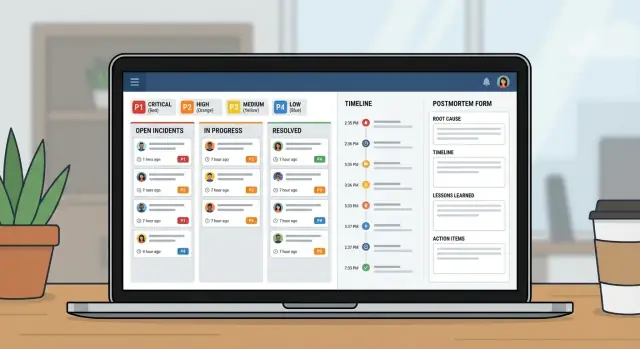
Plan en bouw een incidentbeheer-app voor IT-teams met severity-workflows, duidelijk eigenaarschap, tijdlijnen en postmortems in één interne tool.
Als er een uitval is, grijpen de meeste teams naar wat er op dat moment openstaat: een chatthread, een e-mailketen of een spreadsheet die iemand bijwerkt als hij tijd heeft. Onder druk gaat die aanpak steeds op dezelfde manier stuk: eigenaarschap wordt vaag, tijdstempels verdwijnen en beslissingen raken in de stroom verloren.
Een eenvoudige incident-app regelt de basis. Je hebt één plek waar het incident woont, met een duidelijke eigenaar, een severity-niveau waar iedereen het over eens is en een tijdlijn van wat er gebeurde en wanneer. Dat enkele record is belangrijk omdat dezelfde vragen bij elk incident terugkomen: wie leidt het? wanneer begon het? wat is de huidige status? wat is er al geprobeerd?
Zonder dat gedeelde register kosten overdrachten veel tijd. Support vertelt klanten het een terwijl engineering iets anders doet. Managers vragen om updates en halen responders weg van de oplossing. Achteraf kan niemand de tijdlijn met vertrouwen reconstrueren, dus wordt de postmortem giswerk.
Het doel is niet om je monitoring, chat of ticketing te vervangen. Alerts kunnen nog steeds elders starten. Het punt is om het beslissingsspoor vast te leggen en mensen op één lijn te houden.
IT-operations en on-call engineers gebruiken het om de respons te coördineren. Support gebruikt het om klanten snel nauwkeurige updates te geven. Managers zien voortgang zonder responders te onderbreken.
Om 09:12 geeft monitoring een piek in 500-fouten op de klantenportal aan. Een supportmedewerker meldt ook: “Inloggen faalt voor de meeste gebruikers.” De on-call IT-verantwoordelijke opent een P1-incident in de incident-app en voegt de eerste alert en een screenshot van support toe.
Bij een P1 verandert het gedrag snel. De incidenteigenaar roept de backend-eigenaar, de database-eigenaar en een supportliaison erbij. Niet-essentieel werk pauzeert. Geplande deploys stoppen. Het team stemt een update-cadans af (bijvoorbeeld elke 15 minuten). Een gedeelde call start, maar het incidentrecord blijft de bron van waarheid.
Om 09:18 vraagt iemand: “Wat is er veranderd?” De tijdlijn toont een deploy om 08:57, maar vermeldt niet wat er gedeployed is. De backend-eigenaar rolt toch terug. Fouten dalen en komen dan terug. Nu verdenkt het team de database.
De meeste vertragingen komen op een paar voorspelbare plekken: onduidelijke handoffs (“Ik dacht dat jij dat checkte”), ontbrekende context (recente wijzigingen, bekende risico’s, huidige eigenaar) en verspreide updates in chat, tickets en e-mail.
Om 09:41 vindt de database-eigenaar een runaway query die door een geplande job is gestart. Ze schakelen de job uit, herstarten de getroffen service en bevestigen herstel. De severity wordt teruggezet naar P2 voor monitoring.
Goede sluiting is niet alleen “het werkt weer.” Het is een schoon record: een minuten-tot-minuten tijdlijn, de uiteindelijke root cause, wie welke beslissing nam, wat gepauzeerd was en opvolgwerk met eigenaren en deadlines. Zo verandert een stressvolle P1 in leren in plaats van herhaalde pijn.
Een goede incidenttool is vooral een goed datamodel. Als records vaag zijn, zullen mensen ruziën over wat het incident is, wanneer het begon en wat nog openstaat.
Houd de kernentiteiten dicht bij hoe IT-teams al praten:
Om verwarring later te voorkomen, geef het Incident een paar gestructureerde velden die altijd ingevuld moeten zijn. Vrije tekst helpt, maar het mag niet de enige bron van waarheid zijn. Een praktisch minimum is: een duidelijke titel, impact (wat gebruikers ervaren), getroffen services, starttijd, huidige status en severity.
Relaties zijn belangrijker dan extra velden. Eén incident zou veel updates en veel tasks moeten hebben, plus een many-to-many-koppeling naar services (omdat uitval vaak meerdere systemen raakt). Een postmortem hoort één-op-één aan een incident gekoppeld te zijn, zodat er één eindverhaal is.
Voorbeeld: een “Checkout errors”-incident linkt aan Services “Payments API” en “PostgreSQL”, heeft updates elke 15 minuten en taken zoals “Rollback deploy” en “Voeg retry-guard toe.” Later legt de postmortem de root cause vast en maakt langere termijntaken aan.
Als mensen gestrest zijn, hebben ze simpele labels nodig die voor iedereen hetzelfde betekenen. Definieer P1 tot P4 in gewone taal en toon de definitie direct naast het severity-veld.
Responstargets moeten voelen als toezeggingen. Een eenvoudig uitgangspunt (pas aan op je realiteit):
| Severity | Eerste reactie (ack) | Eerste update | Update-frequentie |
|---|---|---|---|
| P1 | 5 min | 15 min | elke 30 min |
| P2 | 15 min | 30 min | elk 60 min |
| P3 | 4 uur | 1 werkdag | dagelijks |
| P4 | 2 werkdagen | 1 week | wekelijks |
Houd escalatieregels mechanisch. Als een P2 zijn update-cadans mist of de impact groeit, moet het systeem om een severity-review vragen. Om thrash te vermijden, beperk wie de severity kan veranderen (vaak de incident-eigenaar of incident commander), maar laat iedereen een review kunnen aanvragen in een comment.
Een snelle impactmatrix helpt teams ook snel een severity te kiezen. Leg dit vast als een paar verplichte velden: getroffen gebruikers, omzetrisico, veiligheid, compliance/security en of er een workaround bestaat.
Tijdens een incident hebben mensen geen behoefte aan meer opties. Ze hebben een klein aantal staten nodig dat de volgende stap voor de hand legt.
Begin met de stappen die je op een goede dag al volgt en houd de lijst kort. Als je meer dan 6 of 7 statussen hebt, zullen teams discussiëren over woordkeuze in plaats van het probleem op te lossen.
Een praktische set:
Elke status heeft duidelijke entry- en exitregels. Bijvoorbeeld:
Gebruik overgangen om de velden af te dwingen die mensen vergeten. Een veelvoorkomende regel: je kunt een incident niet sluiten zonder een korte root-cause-samenvatting en ten minste één follow-upitem. Als “RCA: TBD” is toegestaan, blijft het vaak zo.
De incidentpagina moet drie vragen in één oogopslag beantwoorden: wie is eigenaar, wat is de volgende actie en wanneer is de laatste update geplaatst.
Als een incident rumoerig is, is vage eigenaarschap de snelste weg naar tijdverlies. Je app moet één persoon duidelijk verantwoordelijk maken, terwijl het makkelijk blijft voor anderen om te helpen.
Een simpel patroon dat werkt:
Toewijzing moet expliciet en controleerbaar zijn. Houd bij wie de eigenaar zette, wie het accepteerde en elke wijziging daarna. “Geaccepteerd” is belangrijk, omdat iemand toewijzen die slaapt of offline is geen echt eigenaarschap is.
On-call versus teamgebaseerde toewijzing hangt meestal af van severity. Voor P1/P2 kies je standaard voor on-call-rotatie zodat er altijd een benoemde eigenaar is. Voor lagere severities kan teamgebaseerde toewijzing werken, maar vereis nog steeds binnen een korte tijd een primaire eigenaar.
Plan vakantie en afwezigheid in je mensproces, niet alleen in systemen. Als de toegewezen persoon onbeschikbaar is gemarkeerd, router dan naar een secundaire on-call of teamlead. Houd het automatisch, maar zichtbaar zodat het snel gecorrigeerd kan worden.
Escalatie moet zowel op severity als op stilte triggeren. Een nuttig uitgangspunt:
Een goede tijdlijn is gedeeld geheugen. Tijdens een incident verdwijnt context snel. Als je de juiste momenten op één plek vastlegt, worden handoffs eenvoudiger en is de postmortem grotendeels geschreven voordat iemand een document opent.
Houd de tijdlijn sturend. Maak er geen chatlog van. De meeste teams vertrouwen op een klein aantal entries: detectie, bevestiging, belangrijke mitigatiestappen, herstel en sluiting.
Elke entry heeft een tijdstempel, een auteur en een korte platte omschrijving. Iemand die later binnenkomt moet vijf entries kunnen lezen en begrijpen wat er aan de hand is.
Verschillende updates bedienen verschillende doelgroepen. Het helpt als entries een type hebben, zoals interne notitie (ruwe details), klantgerichte update (veilige bewoording), beslissing (waarom optie A) en handoff (wat de volgende persoon moet weten).
Herinneringen moeten severity-gebaseerd zijn, niet persoonlijke voorkeur. Als de timer afgaat, ping dan eerst de huidige eigenaar en escaleer bij herhaalde missers.
Notificaties moeten gericht en voorspelbaar zijn. Een kleine regelset is meestal genoeg: notify bij creatie, severity-change, herstel en achterstallige updates. Vermijd het hele bedrijf te notificeren voor elke kleine wijziging.
Een postmortem heeft twee doelen: uitleggen wat er gebeurde in gewone taal en de kans op dezelfde storing verkleinen.
Houd het verslag kort en dwing acties af. Een praktisch format: samenvatting, klantimpact, root cause, aanpassingen tijdens mitigatie en follow-ups.
Follow-ups zijn het punt. Laat ze niet als een alinea aan het einde staan. Zet elke follow-up als een getraceerde taak met een eigenaar en een deadline, zelfs als de deadline “volgende sprint” is. Dat is het verschil tussen “we moeten monitoring verbeteren” en “Alex voegt vrijdag een DB-connection-saturation alert toe.”
Tags maken postmortems later nuttig. Voeg 1–3 thema’s toe aan elk incident (monitoring-gap, deployment, capaciteit, proces). Na een maand kun je eenvoudige vragen beantwoorden, zoals of de meeste P1s door releases of ontbrekende alerts kwamen.
Bewijsvoering (evidence) moet makkelijk toe te voegen zijn, niet verplicht. Ondersteun optionele velden voor screenshots, logfragmenten en verwijzingen naar externe systemen (ticket-IDs, chatthreads, vendor-case-nummers). Houd het lichtgewicht zodat mensen het ook echt invullen.
Behandel dit als een klein product, niet als een spreadsheet met extra kolommen. Een goede incident-app is drie views: wat er nu gebeurt, wat je nu moet doen en wat je daarna leert.
Begin met het schetsen van de schermen die mensen onder druk zullen openen:
Bouw het datamodel en de permissies samen. Als iedereen alles kan bewerken, wordt de geschiedenis rommelig. Een gangbare aanpak: brede leesrechten voor IT, gecontroleerde wijzigingen voor status/severity, responders kunnen updates toevoegen en een duidelijke eigenaar voor postmortem-goedkeuring.
Voeg dan workflowregels toe die half ingevulde incidenten voorkomen. Verplichte velden moeten afhankelijk zijn van de status. Je mag “New” toestaan met alleen titel en reporter, maar vereis bij “Mitigating” een impact-samenvatting en bij “Resolved” een root-cause-samenvatting plus minimaal één follow-uptaak.
Test door 2–3 eerdere incidenten te replayen. Laat één persoon incident commander zijn en één responder. Je ziet snel welke statussen onduidelijk zijn, welke velden mensen overslaan en waar je betere defaults nodig hebt.
De meeste incidentsystemen falen om simpele redenen: mensen herinneren de regels niet onder stress en de app legt de feiten die je later nodig hebt niet goed vast.
Als je zes severity-niveaus en tien statussen hebt, gaan mensen gokken. Houd het bij 3–4 severities en beperk statussen tot wat de volgende stap moet zijn.
Als iedereen “meekijkt”, doet niemand het werk. Vereis één benoemde eigenaar voordat het incident verder mag gaan en maak handoffs expliciet.
Als “wat gebeurde wanneer” van chat afhangt, worden postmortems argumenten. Leg automatisch timestamps vast voor geopend, bevestigd, gemitigeerd en opgelost en houd tijdlijninvoer kort.
Vermijd ook vage root-cause-notities bij sluiting zoals “network issue.” Vereis één duidelijke root-cause-statement en minstens één concreet vervolgstap.
Voordat je dit in de hele IT-organisatie uitrolt, stress-test je de basis. Als mensen de juiste knop in de eerste twee minuten niet kunnen vinden, vallen ze terug op chatthreads en spreadsheets.
Richt je op een korte set launch-checks: rollen en permissies, duidelijke severity-definities, afgedwongen eigenaarschap, herinneringsregels en een escalatiepad als responstargets gemist worden.
Pilot met één team en een paar services die veel alerts genereren. Gebruik het twee weken en pas aan op basis van echte incidenten.
Als je dit als één interne tool wilt bouwen zonder spreadsheets en losse apps te koppelen, is AppMaster (appmaster.io) één optie. Het laat je een datamodel, workflowregels en web-/mobiele interfaces in één plek maken, wat goed past bij een incidentqueue, incidentpagina en postmortem-tracking.
Het vervangt verspreide updates door één gedeeld register dat de basisvragen snel beantwoordt: wie is eigenaar van het incident, wat zien gebruikers, wat is al geprobeerd en wat gebeurt er hierna. Daardoor raak je minder tijd kwijt aan overdrachten, tegenstrijdige berichten en het steeds moeten samenvatten.
Open het incident zodra je denkt dat er echte klant- of bedrijfsimpact is, ook als de root cause nog onduidelijk is. Je kunt het met een concepttitel en “impact onbekend” openen en de details aanscherpen terwijl je de omvang bevestigt.
Houd het klein en gestructureerd: een duidelijke titel, impact-samenvatting, getroffen service(s), starttijd, huidige status, severity en één eigenaar. Voeg updates en taken toe naarmate de situatie zich ontwikkelt, maar vertrouw niet alleen op vrije tekst voor de kernfeiten.
Gebruik 3 tot 4 niveaus met simpele betekenissen die geen discussie opleveren. Een goed uitgangspunt: P1 voor kernuitval of risico op dataverlies, P2 voor grote functiestoring met workaround of beperkte impact, P3 voor kleinere problemen en P4 voor cosmetische of kleine bugs.
Maak doelen die als toezeggingen voelen: tijd tot bevestiging, tijd tot eerste update en de update-cadans. Activeer herinneringen en escalatie als de cadans wordt gemist, want ‘stilte’ is vaak de echte fout tijdens incidenten.
Streef naar zo'n zes staten: New, Acknowledged, Investigating, Mitigating, Monitoring en Resolved. Elke status moet de volgende stap duidelijk maken en overgangen moeten afdwingen wat mensen onder stress vergeten, zoals een eigenaar vóór Acknowledged of een root cause-samenvatting vóór sluiting.
Vereis één primaire eigenaar die verantwoordelijk is voor de response en het posten van updates. Leg acceptatie vast zodat je niemand kunt toewijzen die offline is, en maak handoffs tot een geregistreerde gebeurtenis zodat de volgende persoon niet opnieuw vanaf nul begint.
Leg alleen de momenten vast die ertoe doen: detectie, bevestiging, belangrijke beslissingen, mitigatiestappen, herstel en sluiting, elk met een tijdstempel en auteur. Behandel het als gedeeld geheugen, geen chatlog, zodat iemand die later binnenkomt in enkele minuten kan bijlezen.
Houd het kort en actiegericht: wat gebeurde, klantimpact, root cause, wat je tijdens mitigatie hebt veranderd en follow-ups met eigenaren en deadlines. Het verslag is nuttig, maar de toegewezen en gevolgde taken zijn wat dezelfde fout voorkomt.
Ja. Als je incidents, updates, taken, services en postmortems als echte data modelleert en workflowregels afdwingt in de app, kun je voorkomen dat teams terugvallen op spreadsheets. AppMaster (appmaster.io) laat teams dat datamodel, web-/mobiele schermen en statusvalidaties in één plek bouwen.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


