App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
Leer hoe je bewaarbeleid ontwerpt voor zakelijke apps met duidelijke vensters, archivering en verwijder- of anonimisatieflows die rapportage bruikbaar houden.
Een retentiebeleid is een duidelijke set regels die je app volgt over data: wat je bewaart, hoelang je het bewaart, waar het staat en wat er gebeurt als de tijd om is. Het doel is niet om "alles te verwijderen." Het is om te behouden wat je nodig hebt om het bedrijf te runnen en gebeurtenissen later te kunnen uitleggen, terwijl je verwijdert wat je niet meer nodig hebt.
Zonder een plan verschijnen er snel drie problemen. De opslag groeit stilletjes totdat het echte kosten worden. Privacy- en veiligheidsrisico neemt toe met elke extra kopie van persoonlijke data. En rapportage wordt onbetrouwbaar als oude records niet overeenkomen met de huidige logica, of wanneer mensen ad-hoc dingen verwijderen en dashboards plots veranderen.
Een praktisch retentiebeleid balanceert dagelijkse operatie, bewijsvoering en klantbescherming:
De meeste zakelijke apps hebben dezelfde brede data-gebieden, ook al gebruiken ze andere namen: gebruikersprofielen, transacties, audittrails, berichten en geüploade bestanden.
Een beleid is deels regels, deels workflow, deels tooling. De regel kan zeggen: “bewaar supporttickets 2 jaar.” De workflow definieert wat dat in de praktijk betekent: verplaats oudere tickets naar een archiefgebied, anonimiseer klantvelden en registreer wat er gebeurde. Tooling maakt het herhaalbaar en auditeerbaar.
Als je je app bouwt op AppMaster, behandel retentie dan als productgedrag, niet als een eenmalige cleanup. Geplande Business Processes kunnen data archiveren, verwijderen of anonimiseren op dezelfde manier elke keer, zodat rapportage consistent blijft en mensen de cijfers vertrouwen.
Voordat je datums instelt: wees duidelijk waarom je data überhaupt bewaart. Retentie-beslissingen worden meestal gevormd door privacywetten, klantcontracten en audit- of belastingregels. Sla deze stap over en je bewaart óf te veel (hoger risico en kosten), óf je verwijdert later iets wat je nodig blijkt te hebben.
Begin met “moet bewaard worden” scheiden van “fijn om te hebben.” Moet-behouden data omvat vaak facturen, boekhoudkundige posten en auditlogs die nodig zijn om te bewijzen wie wat wanneer deed. Fijn-om-te-hebben data kunnen oude chattranscripten, gedetailleerde klikgeschiedenis of ruwe eventlogs zijn die je alleen af en toe voor analyse gebruikt.
Vereisten veranderen ook per land en sector. Een supportportaal voor een zorgverlener heeft heel andere beperkingen dan een B2B-admintool. Zelfs binnen één bedrijf kunnen gebruikers in meerdere landen verschillende regels betekenen voor hetzelfde recordtype.
Schrijf beslissingen in gewone taal en wijs een eigenaar aan. “We bewaren tickets 24 maanden” is niet genoeg. Definieer wat inbegrepen is, wat is uitgesloten en wat er gebeurt als het venster eindigt (archiveren, anonimiseren, verwijderen). Zet een persoon of team verantwoordelijk zodat updates niet vastlopen als producten of wetten veranderen.
Haal goedkeuringen vroeg op, voordat engineering iets bouwt. Legal bevestigt minimums en verwijderingsverplichtingen. Security bevestigt risico, toegangscontrole en logging. Product bevestigt wat gebruikers nog moeten kunnen zien. Finance bevestigt welke registratie-eisen er zijn.
Voorbeeld: je kunt factuurgegevens 7 jaar bewaren, tickets 2 jaar bewaren en gebruikersprofielvelden na accountsluiting anonimiseren terwijl je geaggregeerde metrics bewaart. In AppMaster kunnen die geschreven regels netjes worden gekoppeld aan geplande processen en role-based access, met minder giswerk later.
Retentiebeleid faalt wanneer teams “bewaar 2 jaar” besluiten zonder te weten wat “het” omvat. Bouw een eenvoudige kaart van de data die je hebt. Streef niet naar perfectie. Streef naar iets dat een supportlead en een finance-lead allebei begrijpen.
Een praktisch startpunt:
Markeer daarna gevoeligheid in eenvoudige termen: persoonsgegevens (naam, e-mail), financieel (bankgegevens, betaaltokens), credentials (hashes van wachtwoorden, API-keys) of gereguleerde data (bijvoorbeeld gezondheidsinformatie). Als je het niet zeker weet, label het “mogelijk gevoelig” en behandel het voorzichtig totdat het bevestigd is.
“Waar het staat” is meestal meer dan je hoofd-database. Noteer de exacte locatie: databasetabellen, bestandsopslag, e-mail/SMS-logs, analytics-tools of datawarehouses. Noteer ook wie op elke dataset vertrouwt (support, sales, finance, leiding) en hoe vaak. Dat vertelt wat er kapot gaat als je te agressief verwijdert.
Een nuttige gewoonte: documenteer het doel van elke dataset in één zin. Voorbeeld: “Supporttickets worden bewaard om geschillen op te lossen en response-time trends te volgen.”
Als je met AppMaster bouwt, kun je deze inventaris afstemmen op wat daadwerkelijk is gedeployed door je Data Designer-modellen, bestandsafhandeling en ingeschakelde integraties te bekijken.
Zodra de kaart bestaat, wordt retentie een reeks kleine, duidelijke keuzes in plaats van één grote gok.
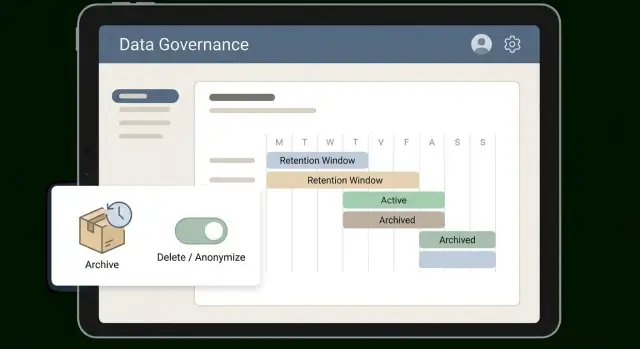
Een venster werkt alleen als het makkelijk uit te leggen is en nog makkelijker toe te passen. Veel teams doen het goed met eenvoudige tiers die overeenkomen met hoe data wordt gebruikt: hot (dagelijks gebruikt), warm (soms gebruikt), cold (bewaar voor bewijs), en dan verwijderen of anonimiseren. De tiers maken een abstract beleid tot een routine.
Stel vensters in per categorie, niet één globale waarde. Facturen en betalingsrecords hebben meestal een lange cold-periode nodig voor belastingen en audits. Supportchattranscripten verliezen vaak snel hun waarde.
Bepaal ook wat de klok start. “Bewaar 2 jaar” is zinloos tenzij je definieert: 2 jaar vanaf wat. Kies één trigger per categorie, zoals aanmaakdatum, laatste klantactiviteit, datum sluiten ticket of accountsluiting. Als triggers variëren zonder duidelijke regels, gaan mensen gokken en zal retentie verschuiven.
Schrijf uitzonderingen van tevoren op zodat teams later niet improviseren. Veelvoorkomende uitzonderingen zijn legal hold, chargebacks en fraudeonderzoeken. Deze moeten verwijdering pauzeren. Ze mogen niet leiden tot verborgen kopieën.
Houd de uiteindelijke regels kort en toetsbaar:
legal_hold=true: niet verwijderen totdat het is vrijgegevenEen archief is geen backup. Backups zijn voor herstel na fouten of storingen. Archieven zijn doelbewust: oudere data verlaat je hot-tabellen en gaat naar goedkopere opslag, maar blijft beschikbaar voor audits, geschillen en historische vragen.
De meeste apps hebben beide nodig. Backups zijn frequent en breed. Archieven zijn selectief en gecontroleerd, en je haalt meestal alleen op wat je nodig hebt.
Goedkopere opslag helpt alleen als mensen nog kunnen vinden wat ze nodig hebben. Veel teams gebruiken een aparte database of schema dat is geoptimaliseerd voor read-heavy queries, of exporteren naar bestanden plus een indextabel voor lookup. Als je app rondom PostgreSQL gemodelleerd is (zoals vaak in AppMaster), kan een “archive”-schema of aparte database productie-tabellen snel houden terwijl je toch toegestane rapportage over gearchiveerde data toestaat.
Definieer voordat je een formaat kiest wat “doorzoekbaar” betekent voor jouw business. Support heeft misschien lookup nodig op e-mail of ticket-ID. Finance heeft maandelijkse totalen nodig. Audits hebben een trace per order-ID nodig.
Volledige records bewaren details, maar kosten meer en verhogen privacyrisico. Samenvattingen (maandtotalen, tellingen, sleutelstatussen) zijn goedkoper en vaak voldoende voor rapportage.
Een praktische aanpak:
Plan indexvelden van tevoren. Gebruikelijk zijn primaire ID, gebruiker/klant ID, een datum-bucket (maand), regio en status. Zonder deze bestaat gearchiveerde data wel, maar is lastig te vinden.
Definieer ook restore-regels: wie kan een restore aanvragen, wie keurt het goed, waar komt herstelde data terecht en wat is de verwachte tijd. Restore kan bewust traag zijn als dat risico verlaagt, maar het moet voorspelbaar zijn.
Retentiebeleid dwingt meestal een keuze af: records fysiek verwijderen, of ze bewaren terwijl je persoonlijke details verwijdert. Beide kunnen juist zijn, maar lossen verschillende problemen op.
Een harde delete verwijdert het record fysiek. Dit past wanneer je geen juridische of zakelijke reden hebt om de data te bewaren en het bewaren risico geeft (bijvoorbeeld oude chattranscripten met gevoelige details).
Een soft delete behoudt de rij maar markeert deze als verwijderd (vaak met een deleted_at timestamp) en verbergt het voor normale schermen en API's. Soft delete is handig als gebruikers herstel verwachten of als downstream-systemen nog naar het record verwijzen. Het nadeel is dat soft-deleted data nog steeds bestaat, opslag gebruikt en kan lekken via exports als je niet oppast.
Anonimisering bewaart het event of de transactie maar verwijdert of vervangt alles wat een persoon kan identificeren. Correct gedaan is het niet omkeerbaar. Pseudonimisering is anders: je vervangt identifiers (zoals e-mail) met een token maar bewaart een aparte mapping die kan heridentificeren. Dat helpt bij fraudeonderzoek, maar is niet hetzelfde als anoniem zijn.
Wees expliciet over gerelateerde data, want hier breken beleid vaak. Het verwijderen van een record maar het laten staan van bijlagen, thumbnails, caches, zoekindexen of analytics-kopieën kan het hele punt stilletjes tenietdoen.
Je hebt ook bewijs nodig dat verwijdering heeft plaatsgevonden. Houd een eenvoudig verwijderbewijs: wat is verwijderd of geanonimiseerd, wanneer het draaide, welke workflow het uitvoerde en of het succesvol was. In AppMaster kan dat eenvoudig met een Business Process dat een audit-entry schrijft wanneer het job klaar is.
Rapporten breken als je records verwijdert of anonimiseert waar dashboards tijdreeksen over joinen. Schrijf vooraf op welke cijfers maand-op-maand vergelijkbaar moeten blijven. Anders zit je later te debuggen waarom de grafiek van vorig jaar is veranderd.
Begin met een korte lijst metrics die accuraat moeten blijven:
Ontwerp vervolgens wat je bewaart voor rapportage zodat het geen persoonlijke identifiers nodig heeft. De veiligste aanpak is aggregatie. In plaats van elke ruwe rij eeuwig te bewaren, bewaar dagelijkse totalen, wekelijkse cohorts en tellingen die niet meer traceerbaar zijn naar een persoon. Bijvoorbeeld: bewaar “tickets aangemaakt per dag per categorie” en “mediaan eerste responstijd per week” zelfs als je later originele ticketinhoud verwijdert.
Sommige rapporten hebben nog steeds een stabiele manier nodig om gedrag over tijd te groeperen. Gebruik een surrogate analytics-key die niet direct identificeerbaar is (bijvoorbeeld een willekeurige UUID alleen voor analytics), en verwijder of beveilig de mapping naar de echte gebruiker zodra het retentievenster eindigt.
Scheid ook operationele tabellen van reporting-tabellen wanneer mogelijk. Operationele data verandert en wordt verwijderd. Reporting-tabellen zouden append-only snapshots of aggregaten moeten zijn.
Anonimisering heeft consequenties. Documenteer wat verandert zodat teams niet verrast worden:
Als je in AppMaster bouwt, behandel anonimisering als een workflow: schrijf eerst aggregaten, verifieer rapportoutputs en anonimiseer daarna velden in de bronrecords.
Een retentiebeleid werkt alleen wanneer het normaal softwaregedrag wordt. Behandel het als elke andere feature: definieer inputs, definieer acties en maak resultaten zichtbaar.
Begin met één pagina matrix. Voor elk datatype noteer je het bewaartermijn, de trigger en wat er daarna gebeurt (bewaren, archiveren, verwijderen, anonimiseren). Als mensen het niet in één minuut kunnen uitleggen, wordt het niet gevolgd.
Voeg duidelijke lifecycle-states toe zodat records niet “mysterieuze verdwenen” zijn. De meeste apps redden zich met drie: active, archived en pending delete. Sla de state op het record zelf op, niet alleen in een spreadsheet.
Een praktische implementatiereeks:
archived_at en delete_after) en werk schermen en API's bij om deze te respecteren.Voorbeeld: supporttickets blijven 90 dagen actief, gaan daarna 18 maanden naar gearchiveerd, en worden dan geanonimiseerd. De workflow markeert tickets als gearchiveerd, verplaatst grote attachments naar goedkopere opslag, houdt ticket-ID's en timestamps, en vervangt namen en e-mails door anonieme waarden.
In AppMaster kunnen lifecycle-states in de Data Designer leven en kan archive/purge-logica draaien als geplande Business Processes. Het doel is herhaalbare runs met duidelijke logs die makkelijk te auditen zijn.
De meeste retentiefouten gaan niet over het gekozen tijdsvenster. Ze gebeuren wanneer verwijdering de verkeerde tabellen raakt, gerelateerde bestanden mist of keys verandert waarop rapporten vertrouwen.
Een veelvoorkomend scenario: een supportteam verwijdert “oude tickets” maar vergeet bijlagen die in een aparte tabel of bestandsopslag staan. Later vraagt een auditor bewijs bij een refund. De tickettekst bestaat, maar de screenshots zijn weg.
Andere valkuilen:
user_id) zonder dashboards, joins en opgeslagen queries bij te werkenEen andere frequente breuk is rapportage gebouwd op persoonsgebaseerde keys. E-mail en naam overschrijven is meestal ok. Het interne user ID overschrijven kan stilletjes iemands geschiedenis in meerdere identiteiten splitsen, en maandelijkse actieve gebruikers of lifetime value zullen gaan afwijken.
Twee oplossingen helpen de meeste teams. Ten eerste, definieer rapportage-keys die nooit veranderen (bijvoorbeeld een interne account-ID) en houd die gescheiden van persoonlijke velden die geanonimiseerd of verwijderd worden. Ten tweede, implementeer verwijdering als een complete workflow die alle gerelateerde data doorloopt, inclusief bestanden en logs. In AppMaster vertaalt dit vaak goed naar een Business Process dat start bij een gebruiker of account, afhankelijkheden verzamelt en dan veilig verwijdert of anonimiseert.
Tot slot, beslis wie verwijdering kan pauzeren voor legal holds en hoe die pauze wordt vastgelegd. Als niemand uitzonderingen beheert, wordt beleid inconsistent toegepast.
Voordat je verwijder- of archiveerjobs draait, doe een realiteitscheck. De meeste fouten ontstaan omdat niemand weet wie data bezit, waar kopieën staan of hoe rapporten erop afhangen.
Een retentiebeleid heeft duidelijke verantwoordelijkheid en een toetsbaar plan nodig, niet alleen een document.
Een eenvoudige validatie is een dry run: neem een kleine batch (zoals één klant met oude cases), draai de workflow in een testomgeving en vergelijk belangrijke rapporten voor en na.
Bewaar bewijs op een manier die geen persoonlijke data herintroduceert:
Als je op AppMaster bouwt, map je deze checks direct naar implementatie: retentievelden in de Data Designer, geplande jobs in de Business Process Editor en duidelijke auditoutputs.
Stel je een klantportal voor die supporttickets, facturen en refunds en ruwe activiteitslogs (logins, pageviews, API-calls) opslaat. Het doel is risico en opslagkosten te verlagen zonder billing, audits of trendrapportage stuk te maken.
Begin met het scheiden van data die je moet bewaren van data die je alleen voor dagelijkse support gebruikt.
Een eenvoudig retentieschema kan zijn:
Voeg een archiveerstap toe voor oudere tickets. In plaats van elk bericht eeuwig in de hoofdtabel te houden, verplaats gesloten tickets ouder dan 18 maanden naar een archiefgebied met een kleine doorzoekbare samenvatting: ticket-ID, datums, productgebied, tags, resolutiecode en een korte excerpt van de laatste agentnotitie. Dat behoudt context zonder volledige persoonlijke details te bewaren.
Voor gesloten accounts kies je anonimisering boven verwijdering wanneer je nog trends nodig hebt. Vervang persoonlijke identifiers (naam, e-mail, adres) door willekeurige tokens, maar behoud niet-identificerende velden zoals plantype en maandelijkse totalen. Sla geaggregeerde gebruiksmetriek op (dagelijkse actieve gebruikers, tickets per maand, omzet per maand) in een aparte reporting-tabel die nooit persoonlijke data opslaat.
Maandelijkse rapportage zal veranderen, maar het hoeft niet slechter te worden als je ervoor plant:
In AppMaster kunnen archive- en anonimisatiestappen als geplande Business Processes draaien, zodat het beleid elke keer op dezelfde manier wordt uitgevoerd.
Een retentiebeleid werkt als mensen het kunnen volgen en het systeem het consequent afdwingt. Begin met een eenvoudige retentiematrix: elke dataset, eigenaar, venster, trigger, volgende actie (archiveren, verwijderen, anonimiseren) en handtekening. Review dit met legal, security, finance en het team dat klanttickets behandelt.
Automatiseer niet alles in één keer. Kies één dataset end-to-end, bij voorkeur iets gangbaars zoals supporttickets of login-logs. Maak de workflow echt, draai het een week en bevestig dat rapportage overeenkomt met wat het bedrijf verwacht. Breid daarna uit naar de volgende dataset met hetzelfde patroon.
Maak automatisering observeerbaar. Basismonitoring dekt meestal:
Plan ook de gebruikerskant. Bepaal wat gebruikers kunnen aanvragen (export, verwijdering, correctie), wie het goedkeurt en wat het systeem doet. Geef support een kort intern script: welke data is betroffen, hoe lang het duurt en wat na verwijdering niet meer terugkomt.
Als je dit wilt implementeren zonder custom code, is AppMaster (appmaster.io) een praktische fit voor retentie-automatisering omdat je lifecycle-velden in de Data Designer kunt modelleren en geplande archive- en anonimisatie Business Processes met audit-logging kunt draaien. Begin met één dataset, maak het saai en betrouwbaar, en herhaal het patroon over de rest van de app.
Een retentiebeleid voorkomt ongecontroleerde datagroei en het 'houd maar alles' patroon. Het stelt voorspelbare regels vast over wat je bewaart, hoe lang en wat er gebeurt aan het einde, zodat kosten, privacyrisico en verrassingen in rapportage niet ongemerkt oplopen.
Begin met de reden waarvoor de data bestaat en wie het nodig heeft: operatie, audits/belastingen en klantbescherming. Kies eenvoudige termijnen per datacategorie (facturen, tickets, logs, bestanden) en zorg voor vroege goedkeuring van legal, security, finance en product, zodat je geen workflows bouwt die later weer teruggedraaid moeten worden.
Definieer één duidelijk triggerpunt per categorie, zoals de datum van het sluiten van een ticket, de laatste activiteit of het sluiten van een account. Als de trigger vaag is, interpreteren verschillende teams het anders en zal retentie gaan afwijken — zo ontstaat ‘2 jaar’ die in de praktijk vijf verschillende betekenissen krijgt.
Gebruik een legal-hold-vlag of state die archivering/anonimisering/verwijdering pauzeert voor specifieke records, en maak die hold zichtbaar en auditeerbaar. Het doel is de normale workflow te pauzeren zonder verborgen kopieën te creëren die later niet te vinden zijn.
Een backup is bedoeld voor disaster recovery en onbedoelde fouten — dus breed en frequent. Een archive is een bewuste verplaatsing van oudere data uit de hot-tabellen naar goedkopere, gecontroleerde opslag die nog wel opgehaald kan worden voor audits, geschillen en historische vragen.
Verwijder als je echt geen reden meer hebt om de data te bewaren en het bestaan ervan risico verhoogt. Anonimiseer wanneer je het event of de transactie nog nodig hebt voor trends of bewijs, maar persoonlijke velden permanent wilt verwijderen zodat het niet meer aan een individu valt te koppelen.
Soft delete is handig voor herstel en om referenties niet te breken, maar het is geen echte verwijdering. Soft-deleted rijen nemen nog steeds ruimte in en kunnen in exports, analytics of admin-views lekken tenzij elke query en workflow ze consequent uitsluit.
Bescherm rapportage door langetermijnmetrics als aggregaten of snapshots op te slaan die niet afhangen van persoonlijke identifiers. Als dashboards joins gebruiken op velden die je van plan bent te overschrijven (zoals e-mail), herontwerp dan eerst het rapportagemodel zodat historische grafieken niet veranderen nadat retentie is uitgevoerd.
Behandel retentie als een productfeature: lifecycle-velden op records, geplande jobs om te archiveren en daarna te purgen/anonimiseren, en audit-entries die aantonen wat er gebeurd is. In AppMaster map je dit met Data Designer-velden en geplande Business Processes die elke keer op dezelfde manier lopen.
Doe een kleine dry run in een test- of productieachtige kopie en vergelijk belangrijke totalen vóór en ná. Zorg er ook voor dat je een record overal kunt traceren (tabellen, bestandsopslag, exports, logs) en leg een verwijder-/anonimisatiebewijs vast met timestamps, regelnaam en aantallen.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


