App voor apparatuurreserveringen: conflicten voorkomen en retouren volgen
Plan een app voor apparatuurreserveringen die dubbele boekingen voorkomt, retouren en schade registreert en defecte items in onderhoud zet.
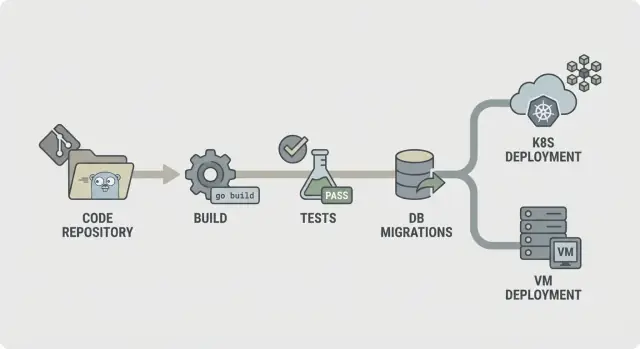
CI/CD voor Go-backends: praktische pijplijnstappen voor builds, tests, migraties en veilige deploys naar Kubernetes of VMs met voorspelbare omgevingen.
Handmatige uitrols falen op vervelende, herhaalbare manieren. Iemand bouwt op zijn laptop met een andere Go-versie, vergeet een environment-variabele, slaat een migratie over of herstart de verkeerde service. De release “werkt bij mij”, maar niet in productie — en dat ontdek je pas als gebruikers het merken.
Gegenereerde code haalt de noodzaak voor release-discipline niet weg. Wanneer je een backend regenereert na wijziging van requirements, kun je nieuwe endpoints, nieuwe datastructuren of nieuwe dependencies introduceren, zelfs als je de code nooit handmatig hebt aangeraakt. Juist dan wil je dat een pijplijn als vangrail werkt: elke wijziging doorloopt elke keer dezelfde checks.
Voorspelbare omgevingen betekenen dat je build- en deploy-stappen lopen onder omstandigheden die je kunt benoemen en herhalen. Een paar regels dekken het grootste deel:
Het doel van CI/CD voor Go-backends is niet automatisering omwille van automatisering. Het is herhaalbare releases met minder stress: regenereer, laat de pijplijn draaien en vertrouw erop dat wat eruitkomt inzetbaar is.
Als je een generator gebruikt zoals AppMaster die Go-backends produceert, wordt dit nog belangrijker. Regeneratie is een feature, maar voelt alleen veilig als het pad van wijziging naar productie consistent, getest en voorspelbaar is.
“Voorspelbaar” betekent dat dezelfde input hetzelfde resultaat oplevert, ongeacht waar je het draait. Voor CI/CD voor Go-backends begint dat met overeenstemming over wat identiek moet zijn tussen dev, staging en prod.
De gebruikelijke niet-onderhandelbare punten zijn de Go-versie, je basis-OS-image, build-flags en hoe configuratie wordt geladen. Als een van deze zaken per omgeving verschilt, krijg je verrassingen zoals ander TLS-gedrag, ontbrekende systeempakketten of bugs die alleen in productie optreden.
De meeste omgeving-drift verschijnt op dezelfde plekken:
Kiezen tussen Kubernetes en VMs gaat minder over wat “het beste” is en meer over wat je team rustig kan beheren.
Kubernetes past goed als je autoscaling, rolling updates en een gestandaardiseerde manier voor veel services nodig hebt. Het helpt ook consistentie af te dwingen omdat pods uit dezelfde images draaien. VMs kunnen de juiste keuze zijn wanneer je één of een paar services hebt, een klein team en je minder bewegende delen wilt.
Je kunt de pijplijn hetzelfde houden, zelfs als runtimes verschillen, door het artifact en het contract daaromheen te standaardiseren. Bijvoorbeeld: bouw altijd dezelfde containerimage in CI, voer dezelfde teststappen uit en publiceer dezelfde migratie-bundel. Alleen de deploystap verschilt dan: Kubernetes past een nieuw imagetag toe, terwijl VMs de image ophalen en een service herstarten.
Een praktisch voorbeeld: een team regenereert een Go-backend met AppMaster en deployed naar staging op Kubernetes maar gebruikt een VM in productie. Als beide exact dezelfde image trekken en config laden uit hetzelfde type secret store, wordt “verschillende runtime” een deployment-detail in plaats van een bron van bugs. Als je AppMaster gebruikt (appmaster.io), past dit model ook goed omdat je naar managed cloud targets kunt deployen of broncode kunt exporteren en dezelfde pijplijn op je eigen infra kunt draaien.
Een voorspelbare pijplijn is makkelijk te beschrijven: controleer de code, bouw hem, bewijs dat het werkt, verzend precies datgene dat je getest hebt, en deploy het elke keer op dezelfde manier. Die duidelijkheid is nog belangrijker wanneer je backend wordt geregenereerd (bijvoorbeeld via AppMaster), omdat wijzigingen veel bestanden tegelijk kunnen raken en je snelle, consistente feedback wilt.
Een voor de hand liggende CI/CD-flow voor Go-backends ziet er zo uit:
Structureer het zo dat fouten vroeg stoppen. Als lint faalt, mag niets anders draaien. Als build faalt, moet je geen databases starten voor integratiechecks. Dat houdt kosten laag en maakt de pijplijn snel aanvoelen.
Niet elke stap moet bij elke commit draaien. Een gangbare splitsing is:
Bepaal wat je bewaart als artifacts. Meestal is dat de gecompileerde binary of containerimage (het deploybare ding), plus migratielogs en testrapporten. Dit bewaren maakt rollbacks en audits eenvoudiger omdat je precies kunt aanwijzen wat getest en gepromoveerd is.
Een build-stage moet één vraag beantwoorden: kunnen we dezelfde binary produceren vandaag, morgen en op een andere runner. Als dat niet waar is, wordt elke volgende stap (tests, migraties, deploy) moeilijker te vertrouwen.
Begin met het pinnen van de omgeving. Gebruik een vaste Go-versie (bijv. 1.22.x) en een vast runner-image (Linux-distro en pakketversies). Vermijd “latest” tags. Kleine veranderingen in libc, Git of de Go-toolchain kunnen leiden tot “werkt op mijn machine”-fouten die lastig te debuggen zijn.
Module-caching helpt, maar alleen als je het als snelheidsboost ziet, niet als bron van waarheid. Cache de Go build-cache en module-download-cache, maar key deze op go.sum (of clear het op main wanneer dependencies veranderen) zodat nieuwe dependencies altijd een schone download triggeren.
Voeg een snelle poortwachter toe vóór compilatie. Houd het snel zodat ontwikkelaars het niet omzeilen. Een typische set is gofmt-checks, go vet en (als het snel blijft) staticcheck. Faalt er een gegenereerd of verouderd bestand, faal dan ook: dit is een veelvoorkomend probleem in geregenereerde codebases.
Compileer op een reproduceerbare manier en embed versie-info. Flags zoals -trimpath helpen, en je kunt -ldflags gebruiken om commit-SHA en buildtijd te injecteren. Produceer één benoemd artifact per service. Dat maakt het makkelijk te traceren wat er draait in Kubernetes of op een VM, vooral wanneer je backend geregenereerd wordt.
Tests helpen alleen als ze elke keer op dezelfde manier draaien. Richt je eerst op snelle feedback en voeg daarna diepere checks toe die nog steeds binnen een voorspelbare tijd klaar zijn.
Begin met unit tests bij elke commit. Stel een harde timeout in zodat een vastgelopen test luid faalt in plaats van de hele pijplijn te blokkeren. Bepaal ook wat “genoeg” coverage betekent voor je team. Coverage is geen trofee, maar een minimumdrempel helpt kwaliteitsverlies te voorkomen.
Een stabiele test-stage bevat meestal:
go test ./... met een per-package timeout en een globale job-timeout.De race detector is waardevol, maar kan builds flink vertragen. Een goed compromis is hem op pull requests en nachtbuilds te draaien, of alleen op geselecteerde pakketten, in plaats van bij elke push.
Flaky tests moeten de build laten falen. Als je echt een test moet quarantaine zetten, houd het zichtbaar: verplaats het naar een aparte job die nog steeds draait en rood rapporteert, en eis een eigenaar en deadline om het te repareren.
Bewaar testoutput zodat debuggen niet vereist dat je alles opnieuw draait. Sla raw logs plus een eenvoudig rapport op (pass/fail, duur en traagste tests). Dat maakt het makkelijker regressies op te merken, vooral wanneer geregenereerde wijzigingen veel bestanden raken.
Unit tests vertellen je dat je code in isolatie werkt. Integratiechecks laten zien of de hele service zich correct gedraagt wanneer hij opstart, verbinding maakt met echte services en echte requests verwerkt. Dit is het vangnet dat problemen vangt die alleen ontstaan als alles samenkomt.
Gebruik tijdelijke afhankelijkheden wanneer je code ze nodig heeft om te starten of om kernrequests te beantwoorden. Een tijdelijke PostgreSQL (en Redis als je het gebruikt) die alleen voor de job wordt gestart is meestal genoeg. Houd versies dicht bij productie, maar probeer niet elk productie-detail te kopiëren.
Een goede integratiestage is bewust klein:
Voor API-contractchecks richt je je op de endpoints waarvan een breuk het meest pijn doet. Je hebt geen volledige end-to-end-suite nodig. Een paar request/response-waarheden volstaan: verplichte velden worden afgewezen met 400, auth vereist geeft 401, en een happy-path request geeft 200 met de verwachte JSON-keys.
Om integratietests vaak genoeg te houden, beperk de scope en controleer de klok. Gebruik één database met een minimaal datasetje. Draai slechts een paar requests. Stel harde timeouts in zodat een vastgelopen opstart binnen seconden faalt, niet binnen minuten.
Als je je backend regenereert (bijv. met AppMaster), dragen deze checks extra gewicht: ze bevestigen dat de geregenereerde service nog steeds schoon opstart en de API spreekt die je web- of mobiele app verwacht.
Begin met kiezen waar migraties draaien. Ze in CI draaien is goed om fouten vroeg te vangen, maar CI zou meestal geen productie moeten aanraken. De meeste teams voeren migraties uit tijdens deploy (als een aparte stap) of als een aparte “migrate”-job die klaar moet zijn voordat de nieuwe versie start.
Een praktische regel is: bouw en test in CI, en voer migraties zo dicht mogelijk bij productie uit, met productiecredentials en productieachtige limieten. In Kubernetes is dat vaak een éénmalige Job. Op VMs kan het een gescripte opdracht in de release-stap zijn.
Volgorde is belangrijker dan mensen verwachten. Gebruik timestamped files (of sequentiële nummers) en dwing “apply in order, exactly once” af. Maak migraties idempotent waar mogelijk, zodat een retry geen duplicaten maakt of halverwege crasht.
Houd de migratiestrategie simpel:
Voeg een veiligheidspoortwachter toe voordat iets draait. Dit kan een database-lock zijn zodat slechts één migratie tegelijk draait, plus een beleid zoals “geen destructieve changes zonder goedkeuring”. Bijvoorbeeld: laat de pijplijn falen als een migratie DROP TABLE of DROP COLUMN bevat, tenzij een manuele goedkeuring is verleend.
Rollback is de harde waarheid: veel schema-wijzigingen zijn niet omkeerbaar. Als je een kolom dropt, kun je de data niet terughalen. Plan rollbacks rond forward fixes: bewaar een down-migratie alleen als het echt veilig is, en vertrouw anders op backups plus een forward-migratie.
Koppel elke migratie aan een recoveryplan: wat te doen als het halverwege faalt, en wat te doen als de app teruggedraaid moet worden. Als je Go-backends genereert (bijv. met AppMaster), behandel migraties als onderdeel van je release-contract zodat geregenereerde code en schema synchroon blijven.
Een pijplijn voelt pas voorspelbaar als het ding dat je deployt altijd hetzelfde is als wat je hebt getest. Dat draait om packaging en configuratie. Behandel de build-output als een verzegeld artifact en houd alle omgevingverschillen buiten dat artifact.
Packaging betekent meestal één van twee paden. Een containerimage is de standaard als je naar Kubernetes deployed, omdat het de OS-laag vastlegt en rollouts consistent maakt. Een VM-bundel kan net zo betrouwbaar zijn als je VMs nodig hebt, zolang het de gecompileerde binary en de kleine set bestanden bevat die runtime nodig heeft (bijv. CA-certificaten, templates of statische assets), en je het elke keer op dezelfde manier deployt.
Configuratie moet extern zijn, niet in de binary gebakken. Gebruik environment-variabelen voor de meeste instellingen (poorten, DB-host, feature flags). Gebruik een configbestand alleen als waarden lang of gestructureerd zijn, en houd het omgeving-specifiek. Als je een config-service gebruikt, behandel die als een dependency: vergrendelde permissies, auditlogs en een duidelijk fallback-plan.
Secrets zijn de lijn die je niet overschrijdt. Ze horen niet in de repo, in de image of in CI-logs. Vermijd het printen van connection strings bij startup. Bewaar secrets in de CI-secretstore en injecteer ze tijdens deploy.
Om artifacts traceerbaar te maken, bouw identiteit in elke build: tag artifacts met een versie plus commit-hash, voeg buildmetadata toe (versie, commit, buildtijd) in een info-endpoint en registreer het artifact-tag in je deploymentlog. Maak het makkelijk om met één commando of dashboard te antwoorden op “wat draait er?”.
Als je Go-backends genereert (bijv. met AppMaster), is deze discipline nog belangrijker: regeneratie is veilig wanneer je artifact-naming en configregels elke release reproduceerbaar maken.
De meeste deploy-fouten zijn geen “slechte code”. Het zijn mismatches tussen omgevingen: verschillende config, ontbrekende secrets of een service die start maar niet echt klaar is. Het doel is simpel: deploy hetzelfde artifact overal en verander alleen configuratie.
Op Kubernetes mik je op een gecontroleerde rollout. Gebruik rolling updates zodat je pods geleidelijk vervangt en voeg readiness- en liveness-checks toe zodat het platform weet wanneer het verkeer gestuurd kan worden en wanneer een container herstart moet worden. Resource requests en limits zijn ook belangrijk, omdat een Go-service die op een grote CI-runner werkt op een kleine node OOM-killed kan worden.
Houd config en secrets uit de image. Bouw één image per commit en injecteer omgevingsspecifieke instellingen tijdens deploy (ConfigMaps, Secrets of je secret manager). Zo draaien staging en productie dezelfde bits.
Als je naar virtuele machines deployed, kan systemd fungeren als je “mini-orchestrator”. Maak een unit-file met een duidelijke working directory, environment-file en restart-policy. Maak logs voorspelbaar door stdout/stderr naar je logcollector of journald te sturen, zodat incidenten geen SSH-schatzoeken worden.
Je kunt nog steeds veilige rollouts doen zonder cluster. Een eenvoudige blue/green-opzet werkt: houd twee directories (of twee VMs), switch de load balancer en houd de vorige versie klaar voor snelle rollback. Canary is vergelijkbaar: stuur een klein deel van het verkeer naar de nieuwe versie voordat je commit.
Voordat je een deploy “klaar” noemt, voer overal dezelfde post-deploy smoke check uit:
Als je backends regenereert (bijv. een AppMaster Go-backend), blijft deze aanpak stabiel: bouw één keer, deploy het artifact en laat omgevingsconfiguratie de verschillen bepalen, niet ad-hoc-scripts.
De meeste gebroken releases worden niet veroorzaakt door “slechte code”. Ze gebeuren wanneer de pijplijn van run naar run anders gedraagt. Als je wilt dat CI/CD voor Go-backends rustig en voorspelbaar aanvoelt, let dan op deze patronen.
Het automatisch uitvoeren van database-migraties bij elke deploy zonder guardrails is klassiek. Een migratie die een tabel lockt kan een drukke service lamleggen. Zet migraties achter een expliciete stap, eis goedkeuring voor productie en zorg dat je ze veilig opnieuw kunt draaien.
Het gebruiken van latest tags of niet-gepinde basisimages is een andere makkelijke manier om mysterieuze fouten te introduceren. Pin Docker-images en Go-versies zodat je buildomgeving niet drift.
Het tijdelijk delen van één database tussen omgevingen wordt vaak permanent en is hoe testdata in staging terechtkomt en staging-scripts productie raken. Scheid databases (en credentials) per omgeving, ook als het schema hetzelfde is.
Ontbrekende health- en readiness-checks laten een deploy “slagen” terwijl de service kapot is, en verkeer wordt te vroeg gerouteerd. Voeg checks toe die echt gedrag reflecteren: kan de app starten, verbinding maken met de database en een request bedienen.
Tot slot zorgt onduidelijke ownership voor secrets, config en toegang ervoor dat releases giswerk worden. Iemand moet eigenaar zijn van hoe secrets aangemaakt, geroteerd en geïnjecteerd worden.
Een realistisch falend scenario: een team merged een wijziging, de pijplijn deployed en een automatische migratie draait eerst. Het voltooit in staging (kleine data), maar time-out in productie (grote data). Met gepinde images, omgevingsscheiding en een gated migratie-stap zou de deploy veilig zijn gestopt.
Als je Go-backends genereert (bijv. met AppMaster), zijn deze regels nog belangrijker omdat regeneratie veel bestanden tegelijk kan raken. Voorspelbare inputs en expliciete gates houden “grote” wijzigingen van risicovolle releases.
Gebruik dit als korte check voor CI/CD voor Go-backends. Als je elk punt met een duidelijk “ja” kunt beantwoorden, worden releases makkelijker.
Beperk productie-toegang en maak het auditbaar. CI zou moeten deployen met een dedicated service-account, secrets centraal beheren en elke handmatige productieactie moet een duidelijke spoor achterlaten (wie, wat, wanneer).
Een klein ops-team van vier mensen shipt eens per week. Ze regenereren vaak hun Go-backend omdat het productteam workflows blijft verfijnen. Hun doel is simpel: minder nachtdiensten en releases die niemand verrassen.
Een typische vrijdagwijziging: ze voegen een nieuw veld toe aan customers (schemawijziging) en updaten de API die het schrijft (codewijziging). De pijplijn behandelt dit als één release. Hij bouwt één artifact, draait tests tegen dat exacte artifact en past pas daarna migraties toe en deployed. Zo is de database nooit vóór de code die het verwacht, en wordt code nooit gedeployed zonder het bijbehorende schema.
Als een schemawijziging is inbegrepen, voegt de pijplijn een veiligheidspoort toe. Hij controleert of de migratie additief is (zoals het toevoegen van een nullable kolom) en markeert risicovolle acties (zoals het droppen van een kolom of het herschrijven van een enorme tabel). Als de migratie risicovol is, stopt de release vóór productie. Het team herschrijft de migratie veiliger of plant een venster.
Als tests falen, gaat niets verder. Hetzelfde geldt als migraties falen in een pre-productieomgeving. De pijplijn probeert geen wijzigingen “even deze keer” door te duwen.
Een eenvoudige set volgende stappen die voor de meeste teams werkt:
Als je backends genereert met AppMaster, houd regeneratie binnen dezelfde pijplijnstappen: regenerate, build, test, migrate in een veilige omgeving en daarna deploy. Behandel de gegenereerde source als elke andere source. Elke release moet reproduceerbaar zijn vanaf een getagde versie, met elke keer dezelfde stappen.
Pin je Go-versie en je buildomgeving zodat dezelfde inputs altijd dezelfde binary of image opleveren. Dat verwijdert “werkt op mijn machine”-verschillen en maakt fouten makkelijker reproduceerbaar en op te lossen.
Regeneratie kan endpoints, datamodellen en dependencies veranderen, zelfs als niemand handmatig code heeft aangepast. Een pipeline laat die wijzigingen altijd door dezelfde checks gaan, waardoor regeneratie veilig blijft in plaats van risicovol.
Bouw één keer en promoot exact hetzelfde artifact naar dev, staging en prod. Als je per omgeving opnieuw bouwt, kun je per ongeluk iets uitrollen dat je nooit hebt getest, zelfs als de commit hetzelfde is.
Draai snelle gates op elke pull request: formattering, basis static checks, build en unit tests met timeouts. Houd het snel genoeg zodat mensen het niet omzeilen, en streng genoeg dat kapotte wijzigingen vroeg stoppen.
Gebruik een kleine integratiestap die de service opstart met productie-achtige configuratie en praat met echte afhankelijkheden zoals PostgreSQL. Het doel is te ontdekken dat het compileert maar niet start, en duidelijke contractbreuken te vangen zonder CI urenlang te laten lopen.
Behandel migraties als een gecontroleerde releasestap, niet iets dat impliciet bij elke deploy draait. Laat ze lopen met duidelijke logs en een single-run lock, en wees eerlijk over rollback: veel schema-wijzigingen vereisen forward fixes of backups, geen simpele undo.
Gebruik readiness checks zodat verkeer pas naar nieuwe pods gaat als de service echt klaar is, en liveness checks om vastgelopen containers te herstarten. Stel ook realistische resource requests en limits in zodat iets dat in CI slaagt niet in productie wordt gekilled vanwege te veel geheugenverbruik.
Een simpele systemd-unit plus een consistente release-script is vaak genoeg voor rustige deploys op VMs. Gebruik hetzelfde artifact-model als bij containers waar mogelijk en voeg een kleine post-deploy smoke check toe zodat een “succesvolle restart” geen gebroken service verbergt.
Stop nooit geheimen in de repo, het build-artifact of CI-logs. Injecteer geheimen tijdens deploy vanuit een beheerde secret store, beperk wie ze kan lezen en maak rotatie een routine-activiteit in plaats van een noodsituatie.
Plaats regeneratie in dezelfde pipeline-fasen als elke andere wijziging: regenerate, build, test, package, en dan migrate en deploy met gates. Als je AppMaster gebruikt om je Go-backend te genereren, kun je zo snel veranderen zonder te raden wat er is gewijzigd en veiliger regenereren en uitrollen.



Experimenteer met AppMaster met gratis abonnement.
Als je er klaar voor bent, kun je het juiste abonnement kiezen.


