App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
I workflow a lunga esecuzione possono fallire in modi complessi. Scopri pattern di stato chiari, contatori di retry, gestione delle dead-letter e dashboard affidabili per gli operatori.
I workflow a lunga esecuzione falliscono in modo diverso rispetto alle richieste rapide. Una chiamata API breve o va a buon fine oppure fallisce subito. Un workflow che gira per ore o giorni può completare 9 passi su 10 e comunque lasciare un pasticcio: record creati a metà, stati confusi e nessuna azione chiara successiva.
Per questo “funzionava ieri” è una frase che si sente spesso. Il workflow non è cambiato, ma è cambiato il suo ambiente. I workflow a lunga esecuzione si basano sul fatto che altri servizi restino sani, che le credenziali rimangano valide e che i dati mantengano la forma che il workflow si aspetta.
I guasti più comuni sono questi: timeout e dipendenze lente (un'API partner è attiva ma oggi impiega 40 secondi), aggiornamenti parziali (record A creato, record B non creato e non puoi rilanciare in sicurezza), interruzioni di dipendenze (provider email/SMS, gateway di pagamento, finestre di manutenzione), callback persi e schedule mancati (un webhook non arriva mai, un job timer non si è attivato) e passi umani che si bloccano (un'approvazione resta in sospeso per giorni e poi riprende con assunzioni datate).
La parte difficile è lo stato. Una “richiesta rapida” può tenere lo stato in memoria finché non finisce. Un workflow no. Deve persistere lo stato tra i passi ed essere pronto a riprendere dopo restart, deploy o crash. Deve anche gestire lo stesso passo che viene eseguito due volte (retry, webhook duplicati, replay da parte di un operatore).
In pratica, “affidabile” significa meno il non fallire mai e più l'essere prevedibile, spiegabile, recuperabile e con una proprietà chiara.
Prevedibile significa che il workflow reagisce nello stesso modo ogni volta che una dipendenza fallisce. Spiegabile significa che un operatore può rispondere, in un minuto, “Dove è bloccato e perché?”. Recuperabile significa poter ritentare o continuare in sicurezza senza causare danni. Chiara proprietà significa che ogni elemento bloccato ha un'azione successiva ovvia: aspettare, ritentare, correggere i dati o passare a una persona.
Un esempio semplice: un'automazione di onboarding crea il record cliente, provisiona gli accessi e invia un messaggio di benvenuto. Se la provisioning riesce ma l'invio del messaggio fallisce perché il provider email è giù, un workflow affidabile registra “Provisioned, message pending” e programma un retry. Non rilancia a caso la provisioning.
Gli strumenti possono semplificare tenendo la logica di workflow e i dati persistenti vicini. Per esempio, AppMaster ti permette di modellare lo stato del workflow nei dati (tramite il Data Designer) e aggiornarlo da Business Processes visuali. Ma l'affidabilità viene dal pattern, non dallo strumento: tratta l'automazione a lunga esecuzione come una serie di stati duraturi che sopravvivono al tempo, ai guasti e all'intervento umano.
I workflow a lunga esecuzione tendono a fallire in modi ripetibili: un'API di terze parti rallenta, una persona non ha approvato qualcosa o un job è in coda. Stati chiari rendono queste situazioni ovvie, così la gente non confonde “ci sta mettendo tempo” con “è rotto”.
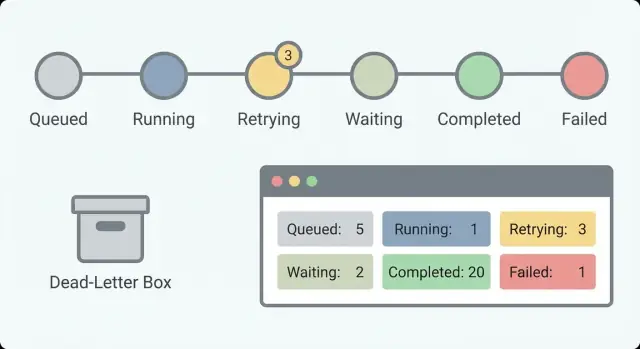
Inizia con un piccolo insieme di stati che rispondano a una domanda: cosa sta succedendo adesso? Se hai 30 stati, nessuno li ricorderà. Con circa 5–8 stati, una persona on-call può scansionare la lista e capirla.
Un set pratico di stati che funziona per molti workflow:
Queued (creato ma non avviato)Running (in esecuzione)Waiting (in pausa su timer, callback o input umano)Succeeded (completato)Failed (interrotto con errore)Separare Waiting da Running è importante. “Waiting for customer response” è sano. “Running da 6 ore” potrebbe essere un hang. Senza questa separazione, rincorrerai falsi allarmi e perderai quelli veri.
Un nome di stato non basta. Aggiungi pochi campi che trasformino uno status in qualcosa di azionabile:
Esempio: un flow di onboarding potrebbe mostrare “Waiting” con la motivazione “Pending manager approval” e ultima modifica “2 giorni fa”. Questo segnala che non è bloccato, ma potrebbe servire un promemoria.
Tratta i nomi degli stati come un'API. Se li rinomini ogni mese, dashboard, alert e playbook di supporto diventano rapidamente fuorvianti. Se ti serve un nuovo significato, considera di introdurre un nuovo stato e lasciare il vecchio per i record esistenti.
In AppMaster puoi modellare questi stati nel Data Designer e aggiornarli dalla logica dei Business Process. Questo mantiene lo status visibile e coerente in tutta l'app invece che nascosto nei log.
I retry aiutano finché non nascondono il problema reale. L'obiettivo non è “non fallire mai”. L'obiettivo è “fallire in un modo che le persone possano capire e correggere”. Questo inizia con una regola chiara su cosa è retryabile e cosa no.
Una regola con cui la maggior parte dei team può convivere: ritenta errori probabilmente temporanei (timeout di rete, rate limit, brevi interruzioni di terze parti). Non ritentare errori chiaramente permanenti (input non valido, permessi mancanti, “account chiuso”, “carta rifiutata”). Se non sai a quale categoria appartiene un errore, trattalo come non retryabile finché non impari di più.
Tieni i contatori di retry per passo (o per chiamata esterna), non un unico contatore per l'intero workflow. Un workflow può avere dieci passi e solo uno può essere instabile. I contatori a livello di step evitano che un passo successivo “rubı” i tentativi a uno precedente.
Per esempio, una chiamata “Upload document” potrebbe essere ritentata qualche volta, mentre “Send welcome email” non dovrebbe continuare a provare all'infinito solo perché l'upload ha consumato tentativi precedenti.
Scegli un pattern di backoff che corrisponda al rischio. Ritardi fissi possono andare bene per retry semplici e a basso costo. L'exponential backoff aiuta quando si rischia di colpire rate limit. Aggiungi un cap così le attese non crescono senza limite e un po' di jitter per evitare storm di retry.
Poi decidi quando fermarti. Buone condizioni di stop sono esplicite: tentativi massimi, tempo totale massimo o “arrendersi per certi codici di errore”. Un gateway di pagamento che ritorna “invalid card” dovrebbe fermarsi subito anche se normalmente permetti cinque tentativi.
Gli operatori hanno anche bisogno di sapere cosa succederà dopo. Registra il prossimo orario di retry e la motivazione (per esempio: “Retry 3/5 alle 14:32 per timeout”). In AppMaster puoi memorizzarlo nel record del workflow così una dashboard può mostrare “in attesa fino a” senza indovinare.
Una buona politica di retry lascia una traccia: cosa è fallito, quante volte è stato provato, quando riproverà e quando si fermerà e passerà alla gestione dead-letter.
Nei workflow che durano ore o giorni, i retry sono normali. Il rischio è ripetere un passo che ha già funzionato. L'idempotenza è la regola che rende questo sicuro: un passo è idempotente se eseguirlo due volte ha lo stesso effetto che eseguirlo una volta.
Un fallimento classico: addebiti una carta e poi il workflow crasha prima di salvare “payment succeeded”. Al retry, addebiti di nuovo. Questo è un problema di doppia scrittura: il mondo esterno è cambiato, ma lo stato del workflow no.
Il pattern più sicuro è creare una chiave di idempotenza stabile per ogni passo con effetti collaterali, inviarla con la chiamata esterna e salvare subito il risultato del passo appena lo ricevi. Molti provider di pagamento e riceventi di webhook supportano chiavi di idempotenza (per esempio addebitare un ordine usando l'OrderID). Se il passo si ripete, il provider restituisce il risultato originale invece di ripetere l'azione.
All'interno del tuo motore di workflow, assumi che ogni passo possa essere riprodotto. In AppMaster questo spesso significa salvare gli output di passo nel modello di database e verificarli nel Business Process prima di chiamare di nuovo un'integrazione. Se “Send welcome email” ha già un MessageID registrato, un retry dovrebbe riutilizzare quel record e andare avanti.
Un approccio pratico sicuro contro i duplicati:
I duplicati comunque succedono, specialmente con webhook in ingresso o quando un utente preme due volte lo stesso pulsante. Decidi la politica per tipo di evento: ignora duplicati esatti (stessa chiave di idempotenza), unisci aggiornamenti compatibili (per esempio last-write-wins per un campo profilo) o segnala per revisione quando sono in gioco rischi monetari o di compliance.
Una dead-letter è un elemento di workflow che ha fallito ed è stato spostato fuori dal percorso normale così non blocca tutto il resto. Lo conservi intenzionalmente. L'obiettivo è rendere semplice capire cosa è successo, decidere se è riparabile e riprocessarlo in sicurezza.
L'errore più grande è salvare solo un messaggio di errore. Quando qualcuno guarda la dead-letter dopo, ha bisogno di abbastanza contesto per riprodurre il problema senza indovinare.
Una voce di dead-letter utile cattura:
La classificazione rende le dead-letter azionabili. Una breve categoria aiuta gli operatori a scegliere la prossima azione giusta. Gruppi comuni includono errore permanente (regola di logica, stato non valido), problema di dati (campo mancante, formato errato), dipendenza giù (timeout, rate limit, interruzione) e auth/permission (token scaduto, credenziali rifiutate).
Il riprocessamento dovrebbe essere controllato. L'obiettivo è evitare danni ripetuti, come addebitare due volte o spam di email. Definisci regole su chi può ritentare, quando ritentare, cosa può cambiare (modificare campi specifici, allegare un documento mancante, rinfrescare un token) e cosa deve rimanere fisso (request ID e chiavi di idempotenza downstream).
Rendi le dead-letter ricercabili per identificatori stabili. Quando un operatore può digitare “order 18422” e vedere l'esatto passo, gli input e la cronologia dei tentativi, le correzioni diventano rapide e coerenti.
Se costruisci questo in AppMaster, tratta la dead-letter come un modello di database di prima classe e salva stato, tentativi e identificatori come campi. In questo modo la tua dashboard interna può interrogare, filtrare e attivare un'azione di reprocess controllata.
I workflow a lunga esecuzione possono fallire in modi lenti e confusi: un passo aspetta una risposta via email, un provider di pagamento va in timeout o arriva due volte un webhook. Se non vedi cosa il workflow sta facendo ora, finisci per indovinare. Una buona visibilità trasforma “è rotto” in una risposta chiara: quale workflow, quale passo, quale stato e cosa fare dopo.
Inizia facendo emettere a ogni passo lo stesso piccolo set di campi così gli operatori possono scansionare rapidamente:
Questi campi supportano contatori di base che mostrano la salute a colpo d'occhio. Per i workflow a lunga esecuzione, i conteggi sono più importanti dei singoli errori perché cerchi trend: lavoro che si accumula, spike di retry o attese che non finiscono mai.
Traccia avviati, completati, falliti, in retry e in attesa nel tempo. Un piccolo numero in waiting può essere normale (approvazioni umane). Un numero in crescita di elementi in waiting di solito indica un blocco. Un numero crescente di retry spesso punta a un provider o a un bug che continua a generare lo stesso errore.
Gli alert dovrebbero corrispondere a quello che gli operatori vivono. Invece di “si è verificato un errore”, allerta sui sintomi: backlog crescente (avviati meno completati continua a salire), troppi workflow bloccati in waiting oltre il tempo atteso, alto tasso di retry per un passo specifico o uno spike di errori subito dopo un rilascio o una modifica di configurazione.
Conserva una traccia di eventi per ogni workflow così “cos'è successo?” sia rispondibile in una sola vista. Una traccia utile include timestamp, transizioni di stato, sommari di input e output (non payload sensibili completi) e la motivazione dei retry o del fallimento. Esempio: “Charge card: retry 3/5, timeout dal provider, prossimo tentativo in 10m.”
I correlation ID sono la colla. Se un cliente dice “il mio pagamento è stato addebitato due volte”, devi collegare gli eventi del workflow all'ID di addebito del provider e al tuo ID ordine interno. In AppMaster puoi standardizzare questo nella logica dei Business Process generando e passando correlation ID attraverso chiamate API e passaggi di messaging così dashboard e log coincidono.
Quando un workflow gira per ore o giorni, i fallimenti sono normali. Quello che trasforma fallimenti normali in outage è un dashboard che dice solo “Failed” e nulla altro. L'obiettivo è aiutare un operatore a rispondere rapidamente a tre domande: cosa sta succedendo, perché succede e cosa può fare in sicurezza dopo.
Inizia con una lista di workflow che renda facile trovare i pochi elementi che contano. I filtri riducono il panico e i messaggi perché chiunque può restringere la vista rapidamente.
Filtri utili includono stato, età (ora di avvio e tempo nello stato corrente), owner (team/customer/operatore responsabile), tipo (nome/versione del workflow) e priorità se hai passi rivolti al cliente.
Poi mostra il “perché” accanto allo stato invece di nasconderlo nei log. Una pillola di stato aiuta solo se è affiancata dall'ultimo messaggio di errore, una breve categoria di errore e cosa il sistema intende fare dopo. Due campi fanno la maggior parte del lavoro: ultimo errore e prossimo retry. Se il prossimo retry è vuoto, rendi evidente se il workflow sta aspettando un umano, è in pausa o è definitivamente fallito.
Le azioni per l'operatore dovrebbero essere sicure di default. Guida le persone verso azioni a basso rischio e rendi esplicite quelle rischiose:
È nel “Force continue” che succedono la maggior parte dei danni. Se lo offri, indica chiaramente il rischio in linguaggio semplice: “Questo salta la verifica di pagamento e può creare un ordine non pagato.” Mostra anche quali dati verranno scritti se si prosegue.
Audita tutto ciò che fanno gli operatori. Registra chi ha fatto cosa, quando, lo stato prima/dopo e la nota di motivazione. Se costruisci strumenti interni in AppMaster, salva questa traccia di audit come una tabella di prima classe e mostrala nella pagina di dettaglio del workflow così i passaggi restano puliti.
Questo pattern mantiene i workflow prevedibili: ogni elemento è sempre in uno stato chiaro, ogni fallimento ha un posto dove andare e gli operatori possono agire senza indovinare.
Passo 1: Definisci stati e transizioni consentite. Scrivi un piccolo insieme di stati che una persona possa capire (per esempio: Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter). Poi decidi quali mosse sono legali così il lavoro non vaga nel limbo.
Passo 2: Suddividi il lavoro in passi piccoli con input e output chiari. Ogni passo dovrebbe accettare un input ben definito e produrre un output (o un errore chiaro). Se ti serve una decisione umana o una chiamata a un'API esterna, falla diventare un passo a sé così può mettere in pausa e riprendere senza problemi.
Passo 3: Aggiungi una politica di retry per passo. Scegli un limite di tentativi, un ritardo tra i tentativi e motivi di stop che non devono mai ritentare (dati non validi, permesso negato, campi richiesti mancanti). Memorizza un contatore di retry per passo così gli operatori vedono esattamente cosa è bloccato.
Passo 4: Persisti il progresso dopo ogni passo. Dopo che un passo finisce, salva il nuovo stato e gli output chiave. Se il processo si riavvia, deve continuare dall'ultimo passo completato, non ricominciare dall'inizio.
Passo 5: Instrada verso una dead-letter e supporta il reprocessing. Quando i retry sono esauriti, sposta l'elemento in uno stato dead-letter e conserva il contesto completo: input, ultimo errore, nome del passo, conteggio tentativi e timestamp. Il reprocess dovrebbe essere deliberato: correggi dati o configurazione prima e poi rimetti in coda dal passo specifico.
Passo 6: Definisci campi di dashboard e azioni per l'operatore. Un buon dashboard risponde a “cosa è fallito, dove e cosa posso fare dopo?” In AppMaster puoi costruirlo come una semplice app admin supportata dalle tue tabelle di workflow.
Campi e azioni chiave da includere:
L'onboarding dei dipendenti è un buon banco di prova. Mescola approvazioni, sistemi esterni e persone non sempre disponibili. Un flow semplice potrebbe essere: HR invia un modulo nuovo assunto, il manager approva, IT crea gli account e il nuovo assunto riceve un messaggio di benvenuto.
Rendi gli stati leggibili. Quando qualcuno apre il record dovrebbe vedere subito la differenza tra “Waiting for approval” e “Retrying account setup.” Una riga di chiarezza può salvare un'ora di indagini.
Un set chiaro di stati da mostrare nell'UI:
I retry appartengono ai passi che dipendono da rete o API di terze parti. Provisioning account (email, SSO, Slack), invio email/SMS e chiamate a API interne sono tutti candidati a retry. Mantieni visibile il contatore retry e imponi un limite (per esempio ritenta fino a cinque volte con ritardi crescenti, poi fermati).
La gestione dead-letter serve per problemi che non si risolvono da soli: nessun manager nel modulo, indirizzo email non valido o richiesta di accesso in conflitto con policy. Quando metti una run in dead-letter, salva il contesto: quale campo ha fallito la validazione, l'ultima risposta API e chi può approvare un override.
Gli operatori dovrebbero avere poche azioni semplici: correggere i dati (aggiungere il manager, correggere l'email), rilanciare un singolo passo fallito (non tutto il workflow) o cancellare pulitamente (e annullare la configurazione parziale se necessario).
Con AppMaster puoi modellare questo nell'Editor dei Business Process, tenere i contatori di retry nei dati e costruire una schermata operatore nel web UI builder che mostri stato, ultimo errore e un pulsante per ritentare il passo fallito.
La maggior parte dei problemi di affidabilità è prevedibile: un passo viene eseguito due volte, i retry girano alle 2:00, o un elemento “bloccato” non ha indicazioni su cosa sia successo. Una checklist evita che diventi indovinare.
Controlli rapidi che catturano i problemi più comuni:
Se puoi migliorare una sola cosa, migliora la visibilità. Molti “bug di workflow” sono in realtà problemi di “non riusciamo a vedere cosa sta facendo”. La tua dashboard dovrebbe mostrare cosa è successo per ultimo, cosa succederà dopo e quando.
Una vista operatore pratica include stato corrente, ultimo messaggio d'errore, conteggio tentativi, prossimo orario di retry e un'azione chiara (retry now, mark as resolved o inviare a revisione manuale). Mantieni le azioni di default sicure: rilancia un singolo passo, non tutto il workflow.
Prossimi passi:
Trattalo come una checklist vivente. Ogni volta che aggiungi un nuovo passo, esegui questi controlli prima che arrivi in produzione.
I workflow a lunga esecuzione possono andare avanti per ore e poi fallire verso la fine, lasciando cambiamenti parziali. Inoltre dipendono da elementi che possono cambiare mentre sono in esecuzione, come la disponibilità di terze parti, le credenziali, la forma dei dati e i tempi di risposta delle persone.
Mantieni l'insieme di stati piccolo e leggibile in modo che un operatore lo capisca a colpo d'occhio. Un default solido è qualcosa come queued, running, waiting, succeeded e failed, con “waiting” separato da “running” in modo da distinguere pause sane da blocchi.
Salva abbastanza informazioni da rendere lo stato azionabile: lo stato corrente, quando è cambiato l'ultima volta, qual era lo stato precedente e una breve motivazione quando è in attesa o è fallito. Se usi ritentativi, memorizza anche il conteggio dei tentativi e il prossimo orario di retry pianificato così le persone non devono indovinare cosa accadrà.
Serve per evitare falsi allarmi e per non perdere incidenti veri. “In attesa di approvazione” o “in attesa di un webhook” possono essere perfettamente normali, mentre “in esecuzione da sei ore” potrebbe indicare un passo bloccato. Trattarli come stati differenti migliora sia gli alert che le decisioni degli operatori.
Ritenta errori che sono probabilmente temporanei, come timeout, limiti di velocità e brevi interruzioni. Non ritentare errori chiaramente permanenti, come input non valido, permessi mancanti o pagamento rifiutato, perché tentativi ripetuti sprecano tempo e possono causare effetti collaterali ripetuti.
I ritentativi a livello di step impediscono a un'integrazione instabile di consumare tutti i tentativi dell'intero workflow. Rendono anche più semplice la diagnosi perché si vede quale passo fallisce, quante volte è stato provato e se gli altri passi sono intatti.
Usa un backoff semplice che corrisponda al rischio e imponi sempre un tetto in modo che le attese non crescano all'infinito. Definisci regole di interruzione esplicite, come un numero massimo di tentativi o un tempo massimo totale, e registra sia il motivo del fallimento sia il prossimo retry pianificato così che la proprietà sia chiara.
Assumi che qualsiasi passo possa essere eseguito due volte a causa di retry, replay o webhook duplicati, e progetta il passo in modo che la ripetizione non causi danni. Un approccio comune è usare una chiave di idempotenza stabile per ogni passo che modifica lo stato esterno, salvare “step started” prima della chiamata esterna e registrare il risultato non appena ritorna.
Un elemento dead-letter è un'istanza che sposti fuori dal flusso normale dopo che i retry sono esauriti per evitare che blocchi tutto il resto. Salva abbastanza contesto da poterlo correggere e riprocessare in sicurezza più tardi: identificatori, input (o uno snapshot sicuro), dove è fallito, la cronologia dei tentativi e la risposta dell'errore del servizio esterno, non solo un messaggio vago.
I dashboard più utili mostrano dove si trova l'istanza, perché è lì e cosa succederà dopo, usando campi coerenti come workflow ID, passo corrente, stato, tempo nello stato, ultimo errore e correlation ID. Gli operatori dovrebbero avere azioni sicure per impostazione predefinita, come ritentare un singolo passo o mettere in pausa/riprendere, e le azioni rischiose devono essere chiaramente etichettate per evitare di peggiorare l'incidente.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


