App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Scopri come modellare timer SLA ed escalation con stati chiari, regole manutenibili e percorsi semplici per mantenere i workflow facili da modificare.
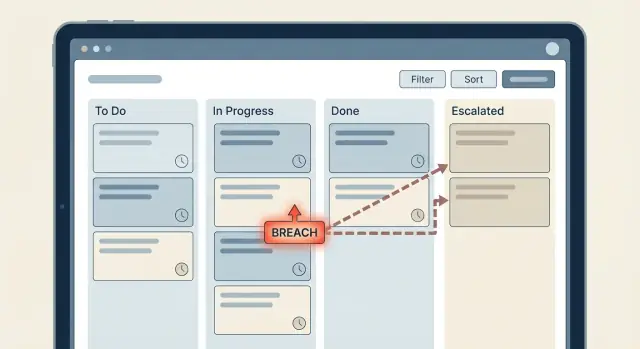
Le regole basate sul tempo di solito partono semplici: “Se un ticket non ha risposta in 2 ore, notifichiamo qualcuno.” Poi il workflow cresce, i team aggiungono eccezioni e all'improvviso nessuno è più sicuro di cosa succede. È così che i timer SLA e le escalation si trasformano in un labirinto.
Aiuta moltissimo dare nomi chiari alle parti in movimento.
Un timer è l'orologio che avvii (o programmi) dopo un evento, per esempio “ticket passato a Waiting for Agent.” Un'escalation è ciò che fai quando quell'orologio raggiunge una soglia, ad esempio notificare un lead, cambiare la priorità o riassegnare il lavoro. Un breach è il fatto registrato che dice “Abbiamo mancato l'SLA”, che usi per report, alert e follow-up.
I problemi emergono quando la logica temporale è dispersa nell'app: qualche controllo nel flusso di “update ticket”, altri controlli in un job notturno, e regole spot aggiunte più avanti per un cliente speciale. Ogni pezzo ha senso da solo, ma insieme creano sorprese.
Tipici sintomi:
L'obiettivo è un comportamento prevedibile che resti facile da cambiare in seguito: una fonte di verità per il tempo SLA, stati di breach espliciti su cui fare report, e step di escalation che puoi aggiustare senza cercare in tutta la logica visiva.
Prima di costruire timer, annota la promessa esatta che stai misurando. Gran parte della logica confusa nasce dal provare a coprire tutte le possibili regole temporali fin da subito.
Tipi comuni di SLA suonano simili ma misurano cose diverse:
Poi decidi cosa intendi per “tempo”. Calendar time conta 24/7. Working time conta solo le ore di lavoro definite (per esempio Lun-Ven, 9-18). Se non ti serve davvero il working time, evitane l'introduzione iniziale: aggiunge casi limite come festività, fusi orari e giornate parziali.
Sii specifico anche sulle pause. Una pausa non è solo “stato cambiato”. È una regola con un proprietario. Chi può mettere in pausa (solo l'agente, solo il sistema, azione del cliente)? Quali stati la mettono in pausa (Waiting on Customer, On Hold, Pending Approval)? Cosa la riattiva? Alla riattivazione si continua dal tempo rimanente o si riavvia il timer?
Infine, definisci cosa significa breach in termini di prodotto. Un breach dovrebbe essere una cosa concreta che puoi memorizzare e interrogare, per esempio:
breached_at (quando la scadenza è stata mancata)Esempio: “First response SLA breached” potrebbe significare che il ticket riceve lo stato Breached, un breached_at timestamp e escalation_level impostato a 1.
Se vuoi che i timer SLA e le escalation restino leggibili, tratta l'SLA come una piccola macchina a stati. Quando la “verità” è sparsa in tanti controlli (if now > due, se la priorità è alta, se l'ultimo reply è vuoto), la logica visiva diventa presto caotica e piccole modifiche rompono tutto.
Inizia con un set breve e concordato di stati SLA che ogni passo del workflow possa capire. Per molti team questi coprono la maggior parte dei casi:
Un singolo flag breached = true/false raramente è sufficiente. Serve ancora sapere quale SLA è breachato (first response vs resolution), se è attualmente in pausa e se hai già eseguito un'escalation. Senza quel contesto, la gente inizia a ri-derivare significato da commenti, timestamp e nomi di stato. Ed è lì che la logica diventa fragile.
Rendi lo stato esplicito e memorizza i timestamp che lo spiegano. Poi le decisioni restano semplici: il tuo evaluator legge il record, decide lo stato successivo e tutto il resto reagisce a quello stato.
Campi utili da salvare insieme allo stato:
started_at e due_at (che orologio stiamo eseguendo e quando scade?)breached_at (quando ha effettivamente superato la soglia)paused_at e paused_reason (perché l'orologio si è fermato?)breach_reason (quale regola ha scatenato il breach, in parole semplici)last_escalation_level (così non notifichi lo stesso livello due volte)Esempio: un ticket va in “Waiting on customer”. Imposta lo stato SLA su Paused, registra paused_reason = "waiting_on_customer" e ferma il timer. Quando il cliente risponde, riprendi impostando un nuovo started_at (o rimuovendo la pausa e ricalcolando il due_at). Niente caccia tra molte condizioni sparse.
Una escalation ladder è un piano chiaro per cosa succede quando un timer SLA sta per scadere o è scaduto. L'errore comune è copiare l'organigramma nel workflow. Vuoi il set minimo di step che faccia ripartire un elemento fermo.
Una scala semplice usata da molti team: l'agente assegnato (Livello 0) riceve il primo sollecito, poi il team lead (Livello 1) viene coinvolto e solo dopo arriva il manager (Livello 2). Funziona perché parte da chi può effettivamente fare il lavoro ed aumenta l'autorità solo quando necessario.
Per mantenere le regole di escalation manutenibili, memorizza le soglie di escalation come dati, non come condizioni hardcoded. Mettile in una tabella o in un oggetto di impostazioni: “prima reminder dopo 30 minuti” o “escalate al lead dopo 2 ore”. Quando le policy cambiano, aggiorni un solo posto invece di modificare più workflow.
Mantenere le escalation utili, non rumorose
Le escalation diventano spam quando scattano troppo spesso. Aggiungi dei guardrail così ogni step abbia uno scopo:
Decidi chi è responsabile dopo l'escalation
Le sole notifiche non risolvono il lavoro fermo se la responsabilità resta vaga. Definisci le regole di ownership a priori: il ticket resta assegnato all'agente, viene riassegnato al lead o va in una coda condivisa?
Esempio: dopo l'escalation di Livello 1, riassegna al team lead e imposta l'agente originale come watcher. Così è chiaro chi deve agire e si evita che l'item rimbalzi tra le stesse persone.
Il modo più semplice per mantenere manutenibili timer SLA e escalation è trattarli come un piccolo sistema con tre parti: eventi, un evaluatore e azioni. Questo evita che la logica temporale si sparga in decine di controlli "if time > X".
Gli eventi sono fatti semplici che non dovrebbero contenere calcoli temporali. Rispondono a “cosa è cambiato?” non a “cosa dobbiamo farci?”. Eventi tipici includono ticket creato, agente ha risposto, cliente ha risposto, stato cambiato, o pausa/riavvio manuale.
Memorizza questi come timestamp e campi di stato (per esempio: created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
Crea un unico “SLA evaluator” che venga eseguito dopo ogni evento e con una pianificazione periodica. Questo evaluator è l'unico posto che calcola due_at e il tempo rimanente. Legge i fatti correnti, ricalcola le scadenze e scrive campi di stato SLA espliciti come sla_response_state e sla_resolution_state.
Qui è dove la modellazione dello stato di breach resta pulita: l'evaluatore imposta stati come OK, AtRisk, Breached, invece di nascondere la logica dentro le notifiche.
Notifiche, assegnazioni ed escalation dovrebbero scattare solo quando uno stato cambia (per esempio: OK -> AtRisk). Mantieni l'invio dei messaggi separato dall'aggiornamento dello stato SLA. Così puoi cambiare chi viene notificato senza toccare i calcoli.
Una configurazione manutenibile tipica somiglia a questa: pochi campi sul record, una piccola tabella di policy e un evaluator che decide cosa succede dopo.
Inizia con l'entità che possiede l'SLA (ticket, ordine, richiesta). Aggiungi timestamp espliciti e un singolo campo “stato SLA corrente”. Mantienilo semplice e prevedibile.
Poi aggiungi una piccola tabella di policy che descriva le regole invece di hardcodarle in molti flow. Una versione semplice è una riga per priorità (P1, P2, P3) con colonne per minuti target e soglie di escalation (per esempio: warn all'80%, breach al 100%). Questa è la differenza tra cambiare un record e dover editare cinque workflow.
Invece di creare timer separati ovunque, usa un singolo processo pianificato che controlla gli item periodicamente (ogni minuto per SLA stringenti, ogni 5 minuti per molti team). Lo schedule chiama un evaluator che:
sla_state e next_check_atQuesto rende i timer SLA ed escalation più facili da ragionare: si debugga un evaluator, non molti timer.
L'evaluatore dovrebbe produrre sia il nuovo stato sia un'indicazione se lo stato è cambiato. Invoca messaggi o task solo quando lo stato si muove (per esempio ok -> warning, warning -> breached). Se il record resta breached per un'ora, non vuoi 12 notifiche ripetute.
Un pattern pratico: salva sla_state e last_escalation_level, confrontali con i valori appena calcolati e solo allora chiama il sistema di messaging (email/SMS/Telegram) o crea un task interno.
Le pause sono dove di solito la logica temporale si inceppa. Se non le modelli chiaramente, l'SLA o continua a scorrere quando non dovrebbe, o si resetta quando qualcuno clicca lo stato sbagliato.
Una regola semplice: solo uno stato (o un piccolo set) mette in pausa il clock. Una scelta comune è Waiting for customer. Quando un ticket entra in quello stato, salva un pause_started_at. Quando il cliente risponde e il ticket esce da quello stato, chiudi la pausa scrivendo un pause_ended_at e aggiungi la durata a paused_total_seconds.
Non tenere solo un contatore cumulativo. Registra ogni finestra di pausa (start, end, chi o cosa l'ha causata) così hai una traccia di audit. In seguito, quando qualcuno chiede perché un caso ha breachato, puoi dimostrare che ha passato 19 ore in attesa del cliente.
Riassegnazioni e cambi di stato normali non dovrebbero riavviare il clock. Tieni gli timestamp SLA separati dai campi di ownership. Per esempio, sla_started_at e sla_due_at dovrebbero essere impostati una volta (alla creazione, o quando cambia la policy SLA), mentre la riassegnazione aggiorna solo assignee_id. L'evaluatore può allora calcolare il tempo trascorso come: now minus sla_started_at minus paused_total_seconds.
Regole che mantengono prevedibili timer SLA ed escalation:
Un modo semplice per testare il tuo design è un ticket con due SLA: first response in 30 minuti e risoluzione completa in 8 ore. Qui la logica spesso si rompe se è distribuita tra schermate e bottoni.
Assumi che ogni ticket memorizzi: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), oltre a timestamp come created_at, first_agent_reply_at, e resolved_at.
Una timeline realistica:
Per le escalation, mantieni una sola catena chiara che si attiva sulle transizioni di stato. Per esempio, quando response diventa Warning, notifica l'agente assegnato. Quando diventa Breached, notifica il team lead e aggiorna la priorità.
Ad ogni passo, aggiorna lo stesso piccolo set di campi così resta semplice da analizzare:
response_status o resolution_status su Pending, Warning, Breached o Met.*_warning_at e *_breach_at una sola volta, poi non sovrascriverli.escalation_level (0, 1, 2) e imposta escalated_to (Agent, Lead, Manager).sla_events con il tipo di evento e chi è stato notificato.priority e due_at così UI e report riflettono l'escalation.La chiave è che Warning e Breached sono stati espliciti. Li vedi nei dati, li puoi auditare e cambiare la scala in seguito senza cercare controlli temporali nascosti.
La logica SLA diventa confusa quando si disperde. Un controllo temporale messo su un bottone qui, un alert condizionale lì, e presto nessuno spiega perché un ticket è stato escalato. Tieni timer SLA ed escalation come un pezzo di logica piccolo e centrale da cui ogni schermata e azione dipende.
Una trappola comune è incastonare controlli temporali in molti posti (UI, API handler, azioni manuali). La soluzione è calcolare lo stato SLA in un evaluator unico e memorizzare il risultato sul record. Le schermate dovrebbero leggere lo stato, non inventarlo.
Un'altra trappola è lasciare che i timer non concordino perché usano orologi diversi. Se il browser calcola “minuti da created” ma il backend usa il tempo del server, vedrai casi limite attorno a sleep, fusi orari e daylight. Preferisci il tempo server per tutto ciò che attiva un'escalation.
Le notifiche possono diventare rumorose rapidamente. Se “controlli ogni minuto e invii se overdue”, la gente potrebbe ricevere spam ogni minuto. Collega i messaggi a transizioni: “warning sent”, “escalated”, “breached”. Invia una volta per step e potrai auditare cosa è successo.
La logica di business hours è un'altra fonte di complessità accidentale. Se ogni regola ha la sua clausola “se weekend allora…”, gli aggiornamenti diventano dolorosi. Metti la matematica delle business hours in una funzione unica (o in un blocco condiviso) che restituisca “minuti SLA consumati finora” e riutilizzala.
Infine, non fare affidamento sul ricalcolo del breach da zero. Memorizza il momento in cui è avvenuto:
breached_at la prima volta che rilevi un breach e non sovrascriverlo mai.escalation_level e last_escalated_at così le azioni sono idempotenti.notified_warning_at (o simili) per prevenire alert ripetuti.Esempio: un ticket breacha alle 10:07. Se ricalcoli solo su richiesta, un successivo bug di pausa/riavvio può far sembrare il breach avvenuto alle 10:42. Con breached_at = 10:07, report e postmortem restano coerenti.
Prima di aggiungere timer e alert, fai un giro con l'obiettivo di rendere le regole leggibili tra un mese.
Un test pratico: scegli un ticket vicino al breach e riproduci la sua timeline. Se non riesci a spiegare cosa succederà ad ogni cambio di stato senza leggere tutto il workflow, il modello è troppo sparpagliato.
Costruisci la fetta minima utile. Scegli un SLA (per esempio first response) e un livello di escalation (per esempio notificare il team lead). Imparerai più in una settimana di uso reale che da un design perfetto sulla carta.
Tieni soglie e destinatari come dati, non come logica. Metti minuti e ore, regole di business-hours, chi viene notificato e quale coda possiede il caso in tabelle o record di configurazione. Così il workflow resta stabile mentre il business aggiusta numeri e routing.
Pianifica presto una vista dashboard semplice. Non serve un grande sistema di analytics, solo un quadro condiviso di cosa succede ora: on track, warning, breached, escalated.
Se stai costruendo in uno strumento no-code, scegli una piattaforma che ti permetta di modellare dati, logiche e evaluator schedulati nello stesso posto. Per esempio, AppMaster supporta modellazione del database, processi business visuali e generazione di app pronte per la produzione, che si adatta bene al pattern “eventi, evaluator, azioni”.
Affina in sicurezza iterando con quest'ordine:
Quando sei pronto, costruisci prima una versione piccola e poi falla crescere con feedback reali e ticket reali.
Inizia definendo chiaramente la promessa che misuri, per esempio first response o resolution, e scrivi l'esatto evento di inizio, fine e le regole di pausa. Poi centralizza la matematica del tempo in un unico evaluatore che imposti stati SLA espliciti invece di spargere controlli del tipo “if now > X” in molti flussi.
Un timer è l'orologio che avvii o programmi dopo un evento, come lo spostamento di un ticket in un nuovo stato. Un'escalation è l'azione che intraprendi quando si raggiunge una soglia, ad esempio notificare un lead o cambiare priorità. Un breach è il fatto memorizzato che indica che l'SLA è stato mancato e che puoi usare per report e follow-up.
Sì. First response misura il tempo fino alla prima risposta umana significativa, mentre resolution misura il tempo fino alla chiusura effettiva del problema. Si comportano diversamente rispetto a pause e riaperture, quindi modellarle separatamente mantiene le regole più semplici e i report più accurati.
Usa il tempo calendario per default perché è più semplice e facile da debug. Introduci regole in orario lavorativo solo se sono davvero necessarie: le business hours aggiungono complessità come festività, fusi orari e giornate parziali.
Modella le pause come stati espliciti legati a stati specifici, per esempio Waiting on Customer, e registra quando la pausa è iniziata e quando è terminata. Al momento della ripresa, continua con il tempo rimanente o ricalcola il due_at in un unico punto, ma non lasciare che toggle di stato casuali resettino il timer.
Un singolo flag breached = true/false non basta perché nasconde contesto importante: quale SLA è breachato, se è in pausa, se si è già eseguita un'escalation. Stati espliciti come On track, Warning, Breached, Paused e Completed rendono il sistema prevedibile e più facile da auditare e modificare.
Registra timestamp che spiegano lo stato, ad esempio started_at, due_at, breached_at, e campi di pausa come paused_at e paused_reason. Memorizza anche tracciamento escalation come last_escalation_level così non notifichi lo stesso livello più volte.
Definisci una scala piccola che inizi dalla persona che può realmente agire, poi il lead e solo dopo il manager se necessario. Conserva soglie e destinatari come dati in una tabella di policy in modo che cambiare i tempi non richieda di modificare molte logiche.
Associare le notifiche ai cambi di stato evita lo spam. Invia un messaggio su transizioni come OK -> Warning o Warning -> Breached, aggiungi cooldown e condizioni di stop, e salva timestamp di notifica per evitare duplicati.
Usa il pattern eventi, evaluatore, azioni: gli eventi registrano fatti, l'evaluatore calcola scadenze e imposta lo stato SLA, e le azioni reagiscono solo ai cambi di stato. In questo modo puoi modellare tutto senza spargere la logica temporale. Su AppMaster puoi modellare i dati, costruire l'evaluatore come processo visivo e attivare notifiche o assegnazioni a partire dagli aggiornamenti di stato.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


