App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Soft delete vs hard delete: impara come mantenere la storia, evitare riferimenti rotti e rispettare i requisiti di privacy con regole chiare.
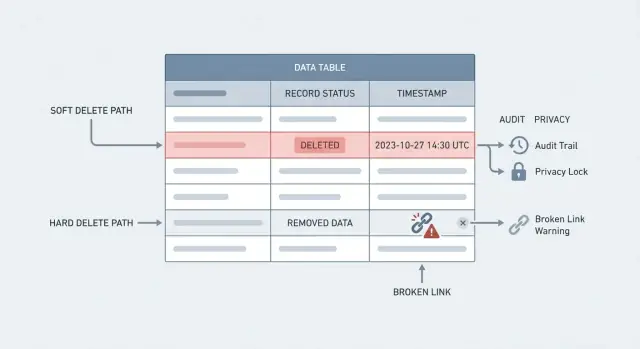
“Cancellare” può voler dire due cose molto diverse. Confonderle è il modo in cui i team perdono la storia o non riescono a soddisfare richieste di privacy.
Una hard delete è ciò che la maggior parte delle persone immagina: la riga viene rimossa dal database. Se la interroghi dopo non c’è più. È rimozione vera, ma può anche rompere riferimenti (per esempio un ordine che punta a un cliente eliminato) a meno che non progetti tutto intorno a questo comportamento.
Una soft delete mantiene la riga, ma la marca come eliminata, di solito con un campo come deleted_at o is_deleted. L’app la tratta come se non esistesse, ma i dati restano disponibili per report, supporto e audit.
Il compromesso dietro soft delete vs hard delete è semplice: storia vs rimozione effettiva. La soft delete protegge la storia e rende possibile l’annullamento. La hard delete riduce ciò che conservi, cosa importante per privacy, sicurezza e requisiti legali.
Le cancellazioni influenzano più dello storage. Cambiano ciò a cui il team può rispondere dopo: un operatore di supporto che cerca di capire un reclamo passato, la finanza che riconcilia fatture, o la compliance che verifica chi ha cambiato cosa e quando. Se i dati spariscono troppo presto, i report si spostano, i totali non combaciano e le indagini diventano congetture.
Un modello mentale utile:
In pratica potresti effettuare la soft delete di un account utente per impedirne il login e mantenere la cronologia ordini, poi eseguire una hard delete (o anonimizzazione) dei campi personali dopo un periodo di retention o dopo una richiesta verificata del diritto alla cancellazione (GDPR).
Nessuno strumento decide questo per te. Anche se costruisci con una piattaforma no-code come AppMaster, il lavoro reale è decidere, per ogni tabella, cosa significhi “eliminato” e assicurarsi che ogni schermata, report e API segua la stessa regola.
La maggior parte dei team se ne accorge solo quando qualcosa va storto. Una cancellazione “semplice” può cancellare contesto, storia e la capacità di spiegare cosa è successo.
Le hard delete sono rischiose perché sono difficili da annullare. Qualcuno preme il pulsante sbagliato, un job automatico ha un bug o un operatore segue una procedura errata. Senza backup puliti e un processo di restore chiaro, la perdita diventa permanente e l’impatto sul business emerge in fretta.
I riferimenti rotti sono la sorpresa successiva. Cancellando un cliente, i suoi ordini possono restare. Ora hai ordini che puntano al nulla, fatture che non possono mostrare un nome di fatturazione e un portale che va in errore quando prova a caricare dati correlati. Anche con vincoli di chiave esterna, la “correzione” può essere peggiore: le delete a cascata potrebbero cancellare molto più di quanto intendevi.
Analytics e reporting diventano complicati. Quando le vecchie righe spariscono, le metriche cambiano retroattivamente. Il tasso di conversione del mese scorso si sposta, il lifetime value cala e le curve temporali mostrano buchi che nessuno sa spiegare. Il team comincia a litigare sui numeri invece di prendere decisioni.
Support e compliance sono le aree dove fa più male. I clienti chiedono: “Perché sono stato addebitato?” o “Chi ha modificato il mio piano?” Se il record non c’è più, non puoi ricostruire la timeline. Perdi la traccia di audit che risponderebbe a domande base come cosa è cambiato, quando e da chi.
Modalità di fallimento comuni dietro il dibattito soft delete vs hard delete:
La soft delete è spesso la scelta più sicura quando un record ha valore a lungo termine o è connesso ad altri dati. Invece di rimuovere la riga, la marchi come eliminata (per esempio deleted_at o is_deleted) e la nascondi dalle viste normali. In una decisione soft delete vs hard delete, questo default tende a ridurre sorprese future.
Brilla in tutti i casi in cui serve una tracciabilità nei database. I team operativi spesso devono rispondere a domande semplici come “Chi ha modificato questo ordine?” o “Perché è stata annullata questa fattura?” Se fai hard delete troppo presto, perdi evidenze importanti per finanza, supporto e report di compliance.
La soft delete rende anche possibile l’“undo”. Gli admin possono ripristinare un ticket chiuso per errore, riattivare un prodotto archiviato o recuperare contenuti generati dagli utenti dopo un falso rilevamento di spam. Offrire questo tipo di restore è difficile se i dati sono fisicamente spariti.
Le relazioni sono un altro grande motivo. Cancellare definitivamente una riga padre può rompere i vincoli o lasciare buchi nei report. Con la soft delete, le join rimangono stabili e i totali storici restano coerenti (fatturato giornaliero, ordini evasi, statistiche di tempo di risposta).
La soft delete è un buon default per record di business come ticket di supporto, messaggi, ordini, fatture, log di audit, cronologia attività e profili utente (almeno fino a confermare la cancellazione definitiva).
Esempio: un agente di supporto “elimina” una nota d’ordine contenente un errore. Con la soft delete, la nota sparisce dall’UI normale, ma i supervisori possono ancora esaminarla in caso di reclamo e i report finanziari rimangono spiegabili.
La soft delete è un ottimo default per molte app, ma ci sono momenti in cui conservare i dati (anche nascosti) è la scelta sbagliata. La hard delete rimuove il record in modo definitivo ed è talvolta l’unica opzione che soddisfa esigenze legali, di sicurezza o di costo.
Il caso più chiaro è rappresentato da obblighi di privacy e contrattuali. Se una persona esercita il diritto alla cancellazione (GDPR), o il tuo contratto promette la cancellazione dopo un periodo stabilito, il “contrassegnato come eliminato” spesso non è sufficiente. Potrebbe essere necessario rimuovere la riga, le copie correlate e qualsiasi identificatore che possa ricondurre alla persona.
La sicurezza è un altro motivo. Alcuni dati sono troppo sensibili per essere conservati: token di accesso in chiaro, codici di reset password, chiavi private, codici di verifica monouso o segreti non cifrati. Tenerli per storicità raramente vale il rischio.
La hard delete può anche essere la scelta giusta per la scalabilità. Se hai tabelle enormi di eventi vecchi, log o telemetria, la soft delete aumenta silenziosamente il database e rallenta le query. Una policy di purge pianificata mantiene il sistema reattivo e i costi prevedibili.
La hard delete è spesso appropriata per dati temporanei (cache, sessioni, import temporanei), artefatti di sicurezza di breve durata (token di reset, OTP, codici invito), account di test/demo e grandi dataset storici dove servono solo statistiche aggregate.
Un approccio pratico è separare la “storia di business” dai “dati personali”. Per esempio, conserva le fatture per la contabilità, ma elimina definitivamente (o anonimizza) i campi del profilo utente che identificano una persona.
Se il tuo team dibatte soft delete vs hard delete, usa un test semplice: se mantenere i dati crea rischio legale o di sicurezza, la hard delete (o l’anonimizzazione irreversibile) dovrebbe prevalere.
Una soft delete funziona meglio quando è noiosa e prevedibile. L’obiettivo è semplice: la riga resta nel database, ma le parti normali dell’app la trattano come se fosse sparita.
Vedrai tre pattern comuni: un timestamp deleted_at, un flag is_deleted o un enum di stato. Molti team preferiscono deleted_at perché risponde a due domande insieme: è eliminato e quando è successo.
Se hai già più stati di lifecycle (active, pending, suspended), un enum di stato può funzionare, ma tieni “deleted” separato da “archived” e “deactivated”. Sono cose diverse:
La discussione soft delete vs hard delete spesso si arena su campi unici come email, username o numero d’ordine. Se un utente è “eliminato” ma la sua email è ancora presente e unica, quella persona non potrà registrarsi di nuovo.
Due soluzioni comuni: rendere l’unicità valida solo per le righe non eliminate, o riscrivere il valore al momento della cancellazione (per esempio aggiungendo un suffisso casuale). La scelta dipende da privacy e necessità di audit.
Decidi cosa vedono i diversi pubblici. Una regola comune è: gli utenti normali non vedono mai i record eliminati, gli utenti support/admin li possono vedere con un’etichetta chiara, e export/report li includono solo quando richiesto.
Non contare sul fatto che “tutti si ricordino di aggiungere il filtro”. Metti la regola in un solo punto: viste, query predefinite o il tuo livello di accesso ai dati. Se usi AppMaster, questo di solito significa integrare il filtro in come gli endpoint e i Business Process recuperano i dati, così le righe eliminate non riappaiono per errore.
Scrivi il significato in una breve nota interna (o commenti di schema). Il te futuro ti ringrazierà quando “deleted”, “archived” e “deactivated” compaiono nella stessa riunione.
Le delete rompono le app più spesso attraverso le relazioni. Un record raramente è isolato: gli utenti hanno ordini, i ticket hanno commenti, i progetti hanno file. La parte complicata nel dibattito soft delete vs hard delete è mantenere i riferimenti coerenti lasciando al prodotto il comportamento di “scomparsa”.
Le foreign key ti proteggono dai riferimenti rotti, ma ogni opzione ha un significato diverso:
Se usi la soft delete, RESTRICT è spesso il default più sicuro. Mantieni la riga, così le chiavi restano valide ed eviti che i figli puntino al nulla.
La soft delete di solito non modifica le foreign key. Invece, filtri i genitori eliminati nell’app e nei report. Se un cliente è soft-deleted, le sue fatture devono comunque unire correttamente, ma le schermate non dovrebbero mostrare il cliente nei dropdown.
Per allegati, commenti e log di attività, decidi cosa significa “cancellare” per l’utente. Alcuni team mantengono lo shell ma rimuovono le parti rischiose: sostituire il contenuto dell’allegato con un placeholder se la privacy lo richiede, marcare i commenti come provenienti da un utente eliminato (o anonimizzare l’autore) e mantenere i log immutabili.
Join e reporting richiedono una regola chiara: le righe eliminate devono essere incluse? Molti team mantengono due query standard: una “solo attivi” e una “inclusi eliminati”, così support e report non nascondono per errore storia importante.
Una policy pratica spesso usa la soft delete per errori quotidiani e la hard delete per esigenze legali o di privacy. Se lo tratti come una singola scelta (soft delete vs hard delete) perdi il terreno di mezzo: conserva la storia per un periodo, poi elimina ciò che deve andare.
Comincia classificando i dati in alcuni gruppi. “Profilo utente” è personale, “transazioni” sono record finanziari e “log” sono cronologia di sistema. Ogni gruppo ha regole diverse.
Un piano breve che funziona nella maggior parte dei team:
Un cliente chiede di chiudere il proprio account. Fai subito la soft delete del record utente così non può più accedere e non rompi riferimenti. Poi anonimizza i campi personali che non devono rimanere (nome, email, telefono), mantenendo i fatti non personali delle transazioni necessari per la contabilità. Infine, un job schedulato rimuove definitivamente quanto resta di personale dopo il periodo di attesa.
I team sbagliano non perché scelgono l’approccio sbagliato, ma perché lo applicano in modo incoerente. Un pattern comune è “soft delete vs hard delete” sulla carta, ma “nascondilo in una schermata e dimenticatene il resto” nella pratica.
Un errore facile: nascondi i record eliminati nell’UI, ma appaiono comunque tramite API, export CSV, strumenti admin o job di sync. Gli utenti notano in fretta quando un cliente “eliminato” ricompare in una mailing list o in una ricerca mobile.
Report e ricerca sono un’altra trappola. Se le query dei report non filtrano coerentemente le righe eliminate, i totali si spostano e le dashboard perdono affidabilità. I casi peggiori sono job in background che re-indicizzano o rinviano elementi eliminati perché non hanno applicato le stesse regole.
Le hard delete possono anche esagerare. Una singola delete a cascata può cancellare ordini, fatture, messaggi e log di cui avevi invece bisogno per un audit. Se devi fare hard delete, sii esplicito su ciò che può scomparire e cosa invece va mantenuto o anonimizzato.
I vincoli di unicità creano dolore sottile con la soft delete. Se un utente elimina il proprio account e poi tenta di ri-registrarsi con la stessa email, l’iscrizione può fallire se la vecchia riga mantiene l’email univoca. Pianifica questo aspetto presto.
I team di compliance chiederanno: puoi dimostrare che la cancellazione è avvenuta e quando? “Pensiamo sia stata cancellata” non passerà molte revisioni. Conserva un timestamp di cancellazione, chi/che cosa l’ha attivata e una voce di log immutabile.
Prima di mandare in produzione, controlla tutta la superficie: API, export, ricerca, report e job in background. Riesamina anche le regole di cascade tabella per tabella e conferma che gli utenti possano ricreare dati “unici” come email o username quando questo fa parte della promessa del prodotto.
Prima di scegliere soft delete vs hard delete, verifica il comportamento reale della tua app, non solo lo schema.
Poi testa il percorso privacy end-to-end. Riesci a soddisfare una richiesta di cancellazione GDPR attraverso copie, export, indici di ricerca, tabelle analitiche e integrazioni, non solo il database principale?
Un modo pratico per convalidare è fare una simulazione di “elimina utente” in staging e seguire la traccia dei dati.
Un cliente scrive: “Per favore elimina il mio account.” Hai anche fatture che devono restare per la contabilità e per verifiche di chargeback. Qui la decisione tra soft delete vs hard delete diventa pratica: puoi rimuovere l’accesso e i dettagli personali mantenendo i record finanziari che il business deve conservare.
Separa “l’account” dal “record di fatturazione”. L’account riguarda login e identità. Il record di fatturazione riguarda una transazione già avvenuta.
Un approccio pulito:
Ticket di supporto e messaggi spesso stanno nel mezzo. Se il contenuto del messaggio include dati personali, potresti dover redigere parti del testo, rimuovere allegati e mantenere lo shell del ticket (timestamp, categoria, risoluzione) per il tracciamento qualità. Se il prodotto invia messaggi (email/SMS, Telegram), rimuovi anche gli identificatori outbound in modo che la persona non venga contattata di nuovo.
Cosa può vedere ancora il support? Di solito numeri di fattura, date, importi, stato e una nota che l’utente è stato eliminato e quando. Non può vedere nulla che identifichi la persona: email di login, nome completo, indirizzi, dettagli di pagamento salvati o sessioni attive.
Le decisioni sulle cancellazioni restano solo quando sono scritte e implementate in modo uniforme nel prodotto. Tratta soft delete vs hard delete prima come una questione di policy, non come un trucco di codice.
Inizia con una semplice politica di conservazione dei dati che chiunque del team possa leggere. Deve spiegare cosa conservi, per quanto tempo e perché. Il “perché” è importante perché stabilisce ciò che prevale quando due obiettivi confliggono (per esempio storia di supporto vs richieste di privacy).
Un buon default è spesso: soft delete per i record di business quotidiani (ordini, ticket, progetti), hard delete per i dati veramente sensibili (token, segreti) e tutto ciò che non dovresti conservare.
Una volta che la policy è chiara, costruisci i flussi che la applicano: una vista “cestino” per il restore, una “coda di purge” per le eliminazioni irreversibili dopo i controlli e una vista di audit che mostra chi ha fatto cosa e quando. Rendi il “purge” più difficile del “delete” in modo che non venga usato per errore.
Se lo stai implementando in AppMaster (appmaster.io), aiuta modellare i campi di soft-delete nel Data Designer e centralizzare la logica di delete, restore e purge in un Business Process, così le stesse regole si applicano a schermate e endpoint API.
Una hard delete rimuove fisicamente la riga dal database, quindi le query future non la troveranno più. Una soft delete mantiene la riga ma la marca come eliminata (spesso con deleted_at), così l'app la nasconde nelle schermate normali preservando la storia per supporto, audit e reportistica.
Usa la soft delete come comportamento predefinito per i record di business che potresti dover spiegare in futuro, come ordini, fatture, ticket, messaggi e attività account. Riduce la perdita accidentale di dati, mantiene intatte le relazioni e permette un “undo” sicuro senza dover ripristinare backup.
La hard delete è preferibile quando conservare i dati comporta rischi di privacy o sicurezza, o quando regole di retention richiedono la rimozione effettiva. Esempi tipici: token di reset password, codici monouso, sessioni, API token e dati personali che devono essere cancellati dopo una richiesta verificata o al termine del periodo di retention.
Un campo deleted_at con timestamp è una scelta comune perché risponde a due domande: il record è eliminato e quando è avvenuto. Supporta flussi pratici come le finestre di retention (es. purge dopo 30 giorni) e permette di rispondere a domande di audit senza un log separato per i tempi.
I campi univoci come email o username spesso bloccano la ri-registrazione se la riga “eliminata” mantiene il valore univoco. Due soluzioni comuni: applicare unicità solo alle righe non eliminate, oppure riscrivere il valore durante la cancellazione (per esempio aggiungere un suffisso casuale). La scelta dipende da esigenze di privacy e audit.
La cancellazione di un record padre può lasciare figli orfani (come ordini) o innescare cascade che rimuovono molto più di quanto previsto. La soft delete di solito evita riferimenti interrotti perché le chiavi restano valide, ma serve comunque un filtraggio coerente così che i genitori eliminati non compaiano in dropdown o join user-facing.
Se si cancellano righe storiche, i totali passati possono cambiare, le serie storiche possono avere buchi e i numeri finanziari possono non corrispondere più a quelli visti in precedenza. La soft delete preserva la storia, ma solo se report e query analitiche definiscono chiaramente se includere o meno le righe eliminate e mantengono quella regola in modo coerente.
La "soft delete" spesso non è sufficiente per il diritto alla cancellazione perché i dati personali potrebbero comunque esistere nel database e nei backup. Un approccio pratico è revocare l'accesso subito, poi cancellare definitivamente o anonimizzare in modo irreversibile gli identificatori personali lasciando i fatti non personali delle transazioni necessari per contabilità e contestazioni.
Il restore dovrebbe riportare il record in uno stato sicuro e valido senza riattivare elementi sensibili che devono rimanere eliminati, come sessioni o token di reset. Serve anche una regola chiara per i dati correlati, così non si ripristina un account lasciandolo privo di relazioni o permessi necessari.
Centralizza il comportamento di delete, restore e purge in modo che ogni API, schermata, export e job di background applichi lo stesso filtro. In AppMaster, questo si ottiene tipicamente aggiungendo campi di soft-delete nel Data Designer e implementando la logica una sola volta in un Business Process, così i nuovi endpoint non espongono dati eliminati per errore.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


