App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Impara a progettare un hub di integrazione per centralizzare credenziali, tracciare lo stato delle sincronizzazioni e gestire gli errori in modo coerente mentre il tuo stack SaaS cresce su molti servizi.
Uno stack SaaS spesso parte semplice: un CRM, uno strumento di fatturazione, una casella di supporto. Poi il team aggiunge automazione marketing, un data warehouse, un secondo canale di supporto e qualche tool di nicchia che ‘serve solo una sincronizzazione rapida’. Prima che te ne accorga, hai una rete di connessioni punto‑a‑punto che nessuno possiede completamente.
A rompersi per primi non è quasi mai i dati. È la colla che li tiene insieme.
Le credenziali finiscono sparse tra account personali, fogli condivisi e variabili d'ambiente a casaccio. I token scadono, le persone se ne vanno e all'improvviso ‘l'integrazione’ dipende da un accesso che nessuno trova più. Anche quando la sicurezza è ben gestita, ruotare i segreti diventa doloroso perché ogni connessione ha la sua procedura e il suo posto dove aggiornare.
Poi crolla la visibilità. Ogni integrazione segnala lo stato in modo diverso (o nulla). Uno strumento dice ‘connesso’ mentre fallisce silenziosamente la sincronizzazione. Un altro manda email vaghe che vengono ignorate. Quando un commerciale chiede perché un cliente non è stato provisionato, la risposta diventa una caccia tra log, dashboard e thread di chat.
Il carico di supporto cresce rapidamente perché i guasti sono difficili da diagnosticare e facili da ripetere. Problemi piccoli come limiti di velocità, cambi di schema e retry parziali si trasformano in incidenti lunghi quando nessuno vede il percorso completo da ‘evento avvenuto’ a ‘dati arrivati’.
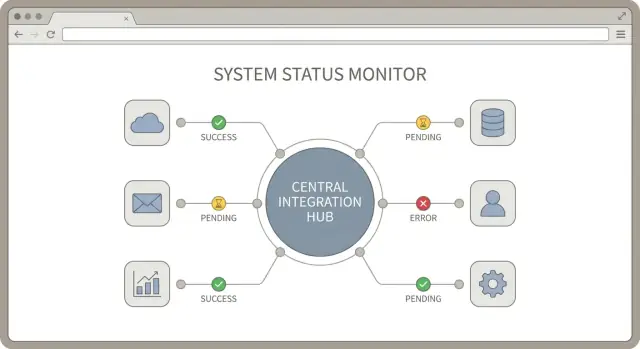
Un hub di integrazione è un'idea semplice: un luogo centrale dove le tue connessioni ai servizi terzi vengono gestite, monitorate e supportate. Un buon design dell'hub crea regole coerenti su come le integrazioni si autenticano, come riportano lo stato di sincronizzazione e come si gestiscono gli errori.
Un hub pratico mira a quattro risultati: meno guasti (pattern condivisi di retry e validazione), riparazioni più veloci (tracciamento semplice), accesso più sicuro (proprietà centrale delle credenziali) e minor impegno del supporto (alert e messaggi standard).
Se costruisci il tuo stack su una piattaforma come AppMaster, l'obiettivo è lo stesso: mantenere le operazioni di integrazione abbastanza semplici perché un non specialista capisca cosa succede e uno specialista possa risolvere rapidamente quando non va.
Prima di prendere decisioni importanti sulle integrazioni, ottieni un quadro chiaro di quello che già connetti (o pianifichi di connettere). È la parte che le persone saltano e che di solito crea sorprese dopo.
Inizia elencando ogni servizio di terze parti nel tuo stack, anche quelli ‘piccoli’. Includi chi lo possiede (persona o team) e se è live, pianificato o sperimentale.
Poi separa le integrazioni visibili ai clienti dalle automazioni di background. Un'integrazione a fronte utente potrebbe essere 'Collega il tuo account Salesforce'. Un'automazione interna potrebbe essere 'Quando una fattura è pagata in Stripe, segna il cliente come attivo nel database'. Queste hanno aspettative di affidabilità diverse e possono fallire in modi differenti.
Mappa i flussi di dati ponendoti una domanda: chi ha bisogno di quei dati per svolgere il proprio lavoro? Product può aver bisogno di eventi di utilizzo per l'onboarding. Operations ha bisogno dello stato dell'account e del provisioning. Finance ha bisogno di fatture, rimborsi e campi fiscali. Support ha bisogno di ticket, cronologia delle conversazioni e corrispondenze di identità utente. Queste esigenze plasmano l'hub più delle API dei vendor.
Infine, definisci le aspettative temporali per ogni flusso:
Esempio: 'Fattura pagata' può necessitare near real time per il controllo accessi, ma giornaliero per i riepiloghi finanziari. Cattura questo fin da subito e monitoraggio e gestione errori saranno molto più facili da standardizzare.
Un buon design dell'hub comincia dai confini. Se l'hub prova a fare tutto, diventa il collo di bottiglia per ogni team. Se fa troppo poco, ti ritrovi con una dozzina di script ad hoc che si comportano in modo diverso.
Scrivi cosa possiede l'hub e cosa non possiede. Una separazione pratica è:
Scegli un punto d'ingresso unico per tutte le integrazioni e atteniti a quello. Può essere un'API (altri sistemi chiamano l'hub) o un job runner (l'hub esegue pull/push schedulati). Usare entrambi va bene, ma solo se condividono la stessa pipeline interna così retry, logging e alert si comportano allo stesso modo.
Alcune decisioni mantengono l'hub focalizzato: standardizza come si attivano le integrazioni (webhook, schedule, rilancio manuale), concorda una forma di payload di confine (anche se i partner differiscono), decidi cosa persistere (eventi raw, record normalizzati, entrambi o nessuno), definisci cosa significa 'fatto' (accettato, consegnato, confermato) e assegna la proprietà per le eccezioni specifiche del partner.
Decidi dove avvengono le trasformazioni. Se normalizzi i dati nell'hub, i servizi downstream restano più semplici, ma l'hub necessita di versioning e test più robusti. Se lasci l'hub sottile e passi payload raw, ogni servizio downstream deve imparare il formato di ogni partner. Molti team trovano un compromesso: normalizzare solo i campi condivisi (ID, timestamp, stato base) e lasciare le regole di dominio a valle.
Pianifica la multi-tenancy fin dal primo giorno. Decidi se l'unità di isolamento è il cliente, lo workspace o l'organizzazione. Questa scelta impatta rate limit, storage delle credenziali e backfill. Quando il token Salesforce di un cliente scade, dovresti mettere in pausa solo i job di quel tenant, non l'intera pipeline. Strumenti come AppMaster possono aiutare a modellare tenant e workflow visivamente, ma i confini devono essere espliciti prima di costruire.
Un vault di credenziali può calmare la vita o trasformarsi in un rischio permanente. L'obiettivo è semplice: un posto per conservare gli accessi senza dare a ogni sistema o collega più potere del necessario.
OAuth e chiavi API si presentano in modi diversi. OAuth è comune per app rivolte all'utente come Google, Slack, Microsoft e molti CRM. L'utente approva l'accesso e tu conservi un access token più un refresh token. Le chiavi API sono più comuni per tool server-to-server e API più datate. Possono essere a lunga durata, il che rende ancora più importante lo storage sicuro e la rotazione.
Memorizza tutto cifrato e scoprilo al tenant giusto. In un prodotto multi‑cliente, tratta le credenziali come dati del cliente. Mantieni un'isolazione rigorosa così il token del Tenant A non può mai essere usato per il Tenant B, nemmeno per errore. Conserva anche i metadati necessari: a quale connessione appartiene, quando scade e quali permessi sono stati concessi.
Regole pratiche che evitano la maggior parte dei problemi:
Pianifica refresh e revoca senza rompere la sincronizzazione. Per OAuth, il refresh dovrebbe avvenire automaticamente in background e l'hub dovrebbe gestire 'token scaduto' provando a rinfrescare una volta e ritentare in sicurezza. Per la revoca (utente che disconnette, security team che disabilita un'app o cambio di scope), ferma la sincronizzazione, marca la connessione come necessita_auth e conserva una chiara traccia di audit di quello che è successo.
Se costruisci l'hub in AppMaster, tratta le credenziali come un modello di dati protetto, mantieni l'accesso in logica backend-only ed esponi solo lo stato connesso/disconnesso all'interfaccia. Gli operatori possono sistemare una connessione senza mai vedere il segreto.
Quando connetti molti strumenti, 'funziona?' diventa una domanda quotidiana. La soluzione non è più log. È un piccolo set coerente di segnali di sincronizzazione che appaiono allo stesso modo per ogni integrazione. Un buon design dell'hub tratta lo stato come una feature di prima classe.
Inizia definendo una lista breve di stati di connessione e usali ovunque: nell'admin UI, negli alert e nelle note di supporto. Mantieni i nomi semplici così un collega non tecnico può agire.
Traccia tre timestamp per connessione: inizio ultima sincronizzazione, ultimo successo di sincronizzazione e orario ultimo errore. Raccontano una storia rapida senza scavare nei log.
Una piccola vista per integrazione aiuta il supporto a muoversi velocemente. Ogni pagina di connessione dovrebbe mostrare lo stato corrente, quei timestamp e l'ultimo messaggio d'errore in formato pulito rivolto all'utente (no stack trace). Aggiungi una breve linea di azione raccomandata come 'Ri-autorizzazione richiesta' o 'Rate limit, ritentando.'
Aggiungi alcuni segnali di salute che prevedono problemi prima che gli utenti li notino: dimensione backlog, conteggio retry, colpi ai rate limit e throughput dell'ultimo successo (circa quanti elementi sono stati sincronizzati nell'ultima esecuzione).
Esempio: la sincronizzazione del CRM è connessa, ma il backlog cresce e i rate limit aumentano. Non è ancora un outage, ma è un segnale chiaro per ridurre la frequenza di sync o batchare le richieste. Se costruisci l'hub in AppMaster, questi campi di stato si mappano facilmente in un modello Data Designer e in una dashboard di supporto semplice che il team può usare ogni giorno.
Una sincronizzazione affidabile riguarda più i passi ripetibili che la logica complessa. Parti con un modello di esecuzione chiaro, poi aggiungi complessità solo dove serve.
La maggior parte dei team usa un mix, ma ogni connettore dovrebbe avere un trigger primario così è più facile ragionarci:
Se costruisci in AppMaster, questo spesso si mappa in un endpoint webhook, un processo background e un task schedulato, tutti che alimentano la stessa pipeline interna.
Diversi vendor chiamano la stessa cosa in modi diversi (customerId vs contact_id, stringhe di stato, formati di data). Convertili in un formato interno prima di applicare le regole di business. Mantiene il resto dell'hub più semplice e rende i cambi dei connettori meno dolorosi.
I retry sono normali. L'hub dovrebbe poter eseguire la stessa azione due volte senza creare duplicati. Un approccio comune è memorizzare un ID esterno e un 'last processed version' (timestamp, numero di sequenza o ID evento). Se vedi lo stesso elemento, lo salti o lo aggiorni in sicurezza.
Le API terze parti possono essere lente o bloccarsi. Metti i task normalizzati in una coda durevole e processali con timeout espliciti. Se una chiamata impiega troppo, falla fallire, registra il motivo e ritentala più tardi invece di bloccare tutto il resto.
Gestisci i limiti sia con backoff che con throttling per connettore. Fai backoff su 429/5xx con uno schedule di retry limitato, imposta limiti di concorrenza separati per connettore (il CRM non è il billing) e aggiungi jitter per evitare raffiche di retry.
Esempio: un evento 'nuova fattura pagata' arriva dal billing via webhook, viene normalizzato e accodato, poi crea o aggiorna l'account corrispondente nel CRM. Se il CRM ti mette ai rate limit, quel connettore rallenta senza ritardare le sincronizzazioni dei ticket di supporto.
Un hub che 'a volte fallisce' è peggio di nessun hub. La soluzione è un modo condiviso per descrivere gli errori, decidere cosa succede dopo e dire agli amministratori non tecnici cosa fare.
Inizia con una forma d'errore standard che ogni connettore restituisce, anche se i payload di terze parti differiscono. Questo mantiene UI, alert e playbook di supporto coerenti.
RATE_LIMIT)Poi classifica i fallimenti in poche categorie (mantienile poche): auth, validation, timeout, rate limit e outage.
Assegna regole di retry chiare a ogni bucket. I rate limit hanno retry ritardati con backoff. I timeout possono ritentare rapidamente per poche volte. La validation è manuale finché i dati non vengono corretti. L'auth mette in pausa l'integrazione e chiede a un admin di riconnettere.
Conserva le risposte raw dei terzi, ma salvale in modo sicuro. Redigi i segreti (token, chiavi API, dati di carte completi) prima di salvare. Se può concedere accesso, non appartiene ai log.
Scrivi due messaggi per ogni errore: uno per gli admin e uno per gli ingegneri. Un messaggio per admin potrebbe essere: 'Connessione Salesforce scaduta. Riconnetti per riprendere la sync.' La vista ingegneri può includere la risposta sanificata, l'ID richiesta e il passo che ha fallito. Qui un hub coerente ripaga, sia che tu implementi i flussi in codice sia che tu usi uno strumento visuale come il Business Process Editor di AppMaster.
Molti progetti di integrazione falliscono per ragioni banali. L'hub funziona in demo, poi si rompe quando aggiungi più tenant, più tipi di dati e più edge case.
Una grande trappola è mescolare la logica di connessione con la logica di business. Quando 'come parlare all'API' sta nello stesso percorso di codice di 'cosa significa un record cliente', ogni nuova regola rischia di rompere il connettore. Mantieni gli adapter focalizzati su auth, paging, rate limit e mapping. Metti le regole di business in un layer separato che puoi testare senza chiamare API esterne.
Un altro problema comune è trattare lo stato tenant come globale. In un prodotto B2B, ogni tenant ha bisogno dei propri token, cursori e checkpoint di sync. Se memorizzi 'ultima sincronizzazione' in un posto condiviso, un cliente può sovrascrivere un altro e ottieni aggiornamenti mancanti o leak di dati tra tenant.
Cinque trappole ricorrenti e la semplice correzione:
I retry meritano attenzione speciale. Se una chiamata di create va in timeout, ritentare può creare duplicati a meno che non usi chiavi di idempotenza o una strategia di upsert robusta. Se l'API terza non supporta idempotenza, traccia un ledger locale di scritture per rilevare e prevenire scritture ripetute.
Non saltare i log di audit. Quando il supporto chiede perché manca un record, devi avere una risposta in pochi minuti, non un'ipotesi. Anche se costruisci l'hub con uno strumento visuale come AppMaster, rendi log e stato per tenant elementi di prima classe.
Un buon hub è noioso nel miglior modo possibile: si connette, riporta chiaramente la sua salute e fallisce in modi che il team capisce.
Controlla come si autentica ogni integrazione e cosa fai con quelle credenziali. Richiedi il minimo set di permessi necessario (read-only quando possibile). Conserva i segreti in uno store dedicato o in un vault cifrato e ruotali senza cambiare codice. Assicurati che log e messaggi d'errore non includano token, chiavi API, refresh token o header raw.
Una volta che le credenziali sono al sicuro, conferma che ogni connessione cliente abbia una singola fonte di verità chiara.
La chiarezza operativa è ciò che mantiene gestibili le integrazioni quando hai decine di clienti e molti servizi terzi.
Monitora lo stato di connessione per cliente (connesso, necessita_autorizzazione, in pausa, in errore) ed esponilo nell'admin UI. Registra un ultimo timestamp di sincronizzazione riuscita per oggetto o per job di sync, non solo 'abbiamo eseguito qualcosa ieri'. Rendi l'ultimo errore facile da trovare con contesto: quale cliente, quale integrazione, quale passo, quale richiesta esterna e cosa è successo dopo.
Limita i retry (tentativi massimi e finestra limite), e progetta le scritture per essere idempotenti così i re‑run non creano duplicati. Stabilisci un obiettivo di supporto: qualcuno del team deve poter localizzare l'ultimo errore e i dettagli in meno di due minuti senza leggere codice.
Se stai costruendo rapidamente UI e tracciamento di stato, una piattaforma come AppMaster può aiutarti a rilasciare una dashboard interna e la logica dei workflow velocemente, producendo comunque codice pronto per la produzione.
Immagina un prodotto SaaS che necessita tre integrazioni comuni: Stripe per eventi di fatturazione, HubSpot per il passaggio commerciale e Zendesk per i ticket di supporto. Invece di collegare ogni tool direttamente all'app, instradalì tramite un unico hub di integrazione.
L'onboarding parte dal pannello di amministrazione. Un admin clicca 'Connetti Stripe', 'Connetti HubSpot' e 'Connetti Zendesk'. Ogni connettore memorizza le credenziali nell'hub, non in script sparsi o laptop dei dipendenti. Poi l'hub esegue un import iniziale:
Dopo l'import, parte la prima sincronizzazione. L'hub scrive un record di sync per ogni connettore così tutti vedono la stessa storia. Una vista admin semplice risponde alla maggior parte delle domande: stato della connessione, ultimo successo di sync, job corrente (import, syncing, idle), riepilogo errore e codice, e prossima esecuzione schedulata.
Ora è un'ora intensa e Stripe ti applica rate limit. Invece di far fallire tutto, il connettore Stripe marca il job come in retry, salva il progresso parziale (per esempio, 'fatture fino alle 10:40') e applica backoff. HubSpot e Zendesk continuano a sincronizzare.
Il support riceve un ticket: 'I dati di billing sembrano obsoleti.' Aprono l'hub e vedono Stripe in stato in errore con un errore di rate limit. La risoluzione è procedurale:
Se costruisci su una piattaforma come AppMaster, questo flusso si mappa in logica visuale (stati job, retry, schermate admin) mantenendo codice backend reale per la produzione.
Un buon design dell'hub riguarda meno il costruire tutto subito e più il rendere ogni nuova connessione prevedibile. Parti con poche regole condivise che ogni connettore deve seguire, anche se la prima versione sembra 'troppo semplice'.
Inizia con la coerenza: stati standard per i job di sync (pending, running, succeeded, failed), un breve set di categorie di errore (auth, rate limit, validation, outage upstream, unknown) e log di audit che rispondono chi ha fatto cosa, quando e con quali record. Se non puoi fidarti di stato e log, dashboard e alert saranno solo rumore.
Aggiungi connettori uno alla volta usando gli stessi template e convenzioni. Ogni connettore dovrebbe riutilizzare lo stesso flusso di credenziali, le stesse regole di retry e lo stesso modo di scrivere gli aggiornamenti di stato. Questa ripetizione è ciò che mantiene l'hub manutenibile quando passi da tre a dieci integrazioni.
Un piano di rollout pratico:
Introduci dashboard e alert solo dopo che i dati di stato sottostanti sono corretti. Inizia con una schermata che mostra ultimo orario di sync, ultimo risultato, prossima esecuzione e l'ultimo messaggio d'errore con categoria.
Se preferisci un approccio no‑code, puoi modellare i dati, costruire la logica di sync ed esporre schermate di stato in AppMaster, poi distribuire sul tuo cloud o esportare il codice sorgente. Mantieni la prima versione noiosa e osservabile, poi migliora performance ed edge case una volta che le operazioni sono stabili.
Inizia con un inventario semplice: ogni tool di terze parti, chi lo possiede e se è in produzione o pianificato. Poi annota i dati che si muovono tra i sistemi e perché sono importanti per un team (supporto, finanza, operations). Questa mappa ti dirà cosa deve essere in tempo reale, cosa può essere giornaliero e cosa richiede il monitoraggio più rigoroso.
Fai occupare al hub le tubature condivise: setup delle connessioni, memorizzazione delle credenziali, scheduling/trigger, reporting coerente degli stati e gestione uniforme degli errori. Mantieni le decisioni di business fuori dall'hub, così non dovrai cambiare il codice dei connettori ogni volta che cambiano le regole di prodotto. Questo confine mantiene l'hub utile senza trasformarlo in un collo di bottiglia.
Assegna un punto d'ingresso primario per ogni connettore così è più facile capire i failure. I webhook sono ottimi per aggiornamenti near real time, i pull schedulati funzionano quando i provider non possono pushare eventi, e i workflow a job sono utili quando devi eseguire passi in ordine. Qualunque scelta fai, mantieni retry, logging e aggiornamenti di stato coerenti tra tutti i trigger.
Tratta le credenziali come dati del cliente e memorizzale cifrate con stretta isolazione per tenant. Non esporre token nei log, nelle schermate UI o negli screenshot di supporto, e non riutilizzare segreti di produzione in staging. Memorizza anche i metadati operativi utili, come scadenza, scope e a quale tenant/connessione appartiene il token.
OAuth è ideale quando i clienti devono collegare i propri account e vuoi accesso revocabile con permessi a scopo limitato. Le chiavi API possono essere più semplici per integrazioni server-to-server ma tendono a essere long‑lived, quindi rotazione e controllo degli accessi diventano più importanti. Se puoi scegliere, preferisci OAuth per connessioni lato utente e tieni le chiavi strettamente limitate e ruotate regolarmente.
Mantieni separato lo stato per ogni tenant: token, cursori, checkpoint, contatori di retry e progresso dei backfill. Un problema per un tenant dovrebbe mettere in pausa solo i job di quel tenant, non l'intero connettore. Questa isolazione evita leak di dati tra tenant e rende più semplice confinare i problemi di supporto.
Usa un piccolo insieme di stati chiari per ogni connettore, ad esempio: connesso, necessita_autorizzazione, in pausa, in errore. Registra tre timestamp per connessione: inizio ultima sincronizzazione, ultima sincronizzazione riuscita e orario dell'ultimo errore. Con questi segnali, la maggior parte delle domande “funziona?” si può rispondere senza leggere i log.
Rendi ogni scrittura idempotente in modo che i retry non generino duplicati. Di solito significa memorizzare un ID esterno più un marcatore di “ultimo processato” e usare upsert invece di create cieche. Se il provider non supporta idempotenza, mantieni un ledger locale di scritture per rilevare tentativi ripetuti prima di scrivere di nuovo.
Gestisci i rate limit deliberatamente: limita la velocità per connettore, applica backoff su 429 ed errori transitori e aggiungi jitter per evitare che i retry si accumulino tutti insieme. Metti il lavoro in una coda durevole con timeout in modo che chiamate lente non blocchino altre integrazioni. L'obiettivo è rallentare un connettore senza fermare tutto l'hub.
Se vuoi un approccio no-code, modella connessioni, tenant e campi di stato nel Data Designer di AppMaster, poi implementa i workflow di sincronizzazione nel Business Process Editor. Tieni le credenziali nella logica backend e mostra nell'interfaccia solo stato e azioni sicure. Puoi rilasciare rapidamente una dashboard operativa interna e comunque ottenere codice generato pronto per la produzione.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


